一、 引言
语言处理器的主要作用是将高级语言程序翻译为硬件可执行的机器代码语言,其对于软件开发至关重要,错误的语言处理器可以将正确的程序翻译成故障代码,从而导致安全漏洞,像解释器中的漏洞可以使得攻击者能够实现拒绝服务。但是由于语言处理器对于输入的测试代码的语法和语义有效性具有很严格的要求,语法或者语义错误会导致无法检测到语言处理器更深层次的逻辑,因此对语言处理器的测试存在一定困难。目前的模糊测试技术尝试在抽象语法树(AST)或者中间表示(IR)上对测试用例进行突变来保留其语法结构,或针对一种语言进行特定的约束来保证语义的正确性。然而当针对一种语言进行特定的语义约束会使测试不能普遍适用于通用的语言处理器。
因此,针对于上述问题,作者提出PolyGlot,使用语义验证的一个通用的语言处理器模糊测试引擎,并提出如下方法:
01
为提高普遍性,本文设计一种中间表示语言(immediate representation,IR)。各种编程语言会首先根据其BNF语法和相关语义注释,转换为IRs进行变异等操作,经语义验证有效后再转换为源代码形式在Fuzz引擎运行;
02
为提高语法有效性,对转换后的IRs使用约束变异和语义验证两种方法用于测试用例的生成;
二、 概述
PolyGlot的基本框架如下图所示,主要由两部分组成:
01
用户输入:对应语言的BNF语法,语义注释,种子(可选输入);
02
PolyGlot:前段生成器、IR转换器、约束突变、语义验证;
其基本流程为:首先,前端生成器(Bison&Flex)根据用户输入的BNF语法和语义注释生成相关的解析方法,各个解析方法构成IR转换器。然后,对于每一轮模糊,我们从语料库中选择一个输入。这个输入会被载入到IR转换器中,转换为IR程序。转换后的IR程序进行约束变异、语义验证等操作后,转换为源码形式进入fuzz引擎运行,查看是否产生崩溃。Fuzz过程中如果有新的路径发现,则将该测试用例保存至语料库。

图1 PolyGlot流程概述图
三、 IR
01 基本形式
IR基本形式为IR。type对应于BNF语法中的每个标签;left、right表示该IR的左右IR;op、val则用来存储部分源代码信息,像函数名称、参数值等;semantic_property则对应于语义注释中的相关语义属性。如下图所示为一个C程序对应的IR程序(图a)、BNF语法(图b)和语义注释(图c)。

图2 示例IR及对应BNF语法和语义注释
以ir2为例,其type为FunctionName对应于BNF语法中的标签,val处则存储函数名“main”,语义属性处对应于语义注释中对于标签的注释“FunctimeName”。通过设计这样一种IR,就可以将各种编程语言转换为统一的中间表示,并且包含相关语义属性,可用于后续提高语义的有效性。
02 相关属性
IR程序同时具有语法属性和语义属性。语法属性一方面体现在部分IR可以存储源代码,另一方面IR通过左、右IR的定向连接,可以形成源程序的树状视图,如下图所示为IR程序即对应的树状图,通过对树状图的遍历可还原源代码。
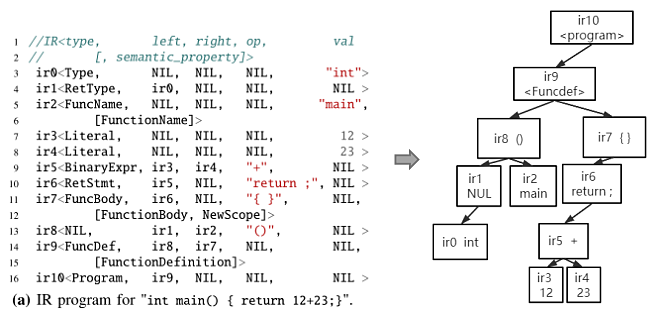
图3 示例IR及对应树状图
语义属性则捕获有关定义范围和类型的语义。对于类型,它可以判断哪些IRs属于变量定义,变量基础类型和类型间转换规则,操作数类型和运算符输出类型等。对于范围,它可以判断哪些IRs创建了新的作用域,以此确定变量的的可用范围。
四、 约束变异
约束变异的基本原则是保证测试用例的语法有效性和尽量保持未变异部分的语义有效性。
它使用基于类型的变异来保证测试用例的语法有效性。在该变异阶段有3种突变策略:插入、删除和替换。在该部分中为了保证语法的有效性,通常在同类型间进行IR的替换,或者是在一些条件语句(if,else等)进行插入和删除,以此来降低变异对语法结构的破坏。
它使用一种局部变异的方式来保证未变异部分的语义有效性。基本原则是选择不包含定义的IR或者创建了新的范围的IR进行变异。
01
不包含定义的IR主要是指仅对变量进行赋值或者调用,没有对变量进行声明定义,如下图4第7行,仅对变量arr[1]进行赋值,这时如果执行删除或者替换操作,程序语义仍然正确。
02
创建新的范围IR:一般指函数;虽然在新范围的IR内仍然存在变量定义,但是该变量的作用域仅在该IR范围内,这时如果对IR整体进行变异则不会影响其他部分的语义。如下图4第9行,for函数中定义了新的变量idx,但其仅在for函数作用域内调用,这时我们需要对每个idx同时进行变异或者直接对for函数进行变异。

图4 示例JS程序
五、 语义验证
由于约束变异阶段可能会产生无效变量,从而导致语义错误,因此在该阶段的主要目的是寻找有效变量来代替无效变量,从而完成语义有效性的验证。该步骤实现的相关组件有:类型系统、范围系统和符号表。
01 类型系统
类型系统的目的是收集变量类型信息,并使用Type map结构记录变量基本类型和用户自定义类型,便于根据类型查找有效变量。
(1) Type map 构建
变量的类型可以分为基本类型和复合类型。基本类型指的是编程语言中预定义的类型,像int、short等,基本类型是有限的,可以在语义注释中进行完全描述。复合类型在这里主要是指结构体、函数和指针。复合类型的构建需要遍历所有的IRs,再通过语义属性查找满足上述三个符合类型的IRs,搜索其组件,并用组件创建新类型。由于复合类型是特定于某个程序的,因此每完成一个测试用例,都需要删除其存储的复合类型。
基本类型和复合类型均存储至Type map中,映射的键是类型的唯一ID,值是类型的结构。如下图所示为某突变程序及其对应的Type map。

图5 变异程序及对应Type map
(2) 变量类型推断
根据上述构建的Type map我们就可以对程序中变量类型进行推断,从而进行正常使用。对于变量定义,当变量为显性类型,即直接声明变量类型,如:int a,c等,直接再type map中查找变量类型名称,返回索引TID。当变量为隐式类型,如:let y=1.0时,这时根据其赋值来对其进行类型判断。对于已定义的变量调用,则直接根据变量名称返回匹配类型的TID。对于表达式类型,如果表达式中仅包含一个变量或者一个常量,则视为变量调用处理或根据常量类型进行匹配。对于包含操作符的表达式,则根据语义注释中包含的操作符输出类型和左右操作数类型进行匹配。对于在动态执行中,变量类型不是固定不变的,则赋为AnyType。
02 范围系统
范围系统的目的是收集变量可适用的范围信息,该过程中使用Scope Tree对IR程序进行作用域划分。首先选取全局作用域作为根节点。然后当语义属性中声明有新的作用域时,会创建叶节点,并为每个节点分配唯一的ID。在这里使用代码行数来可视化作用域。如下图所示为某突变程序及其对应的Scope Tree。

图6 变异程序及对应Scope Tree
03 符号表
符号表的目的是集成变量的类型信息和作用域信息,用于查找有效变量来组成表达式来替换无效变量。Scope tree的每个叶节点都有一个符号表,符号表中包含了该节点作用域内的所有变量名称,并使用TID和OID标记变量类型和作用行数。TID对应于Type map中的ID。OID则使用所在行数标识变量的作用范围。如果一个变量位于当前节点的祖先节点中,并且该变量在该节点作用域之前被定义,则该变量可以被当前节点所调用。
如下图所示为某变异程序及其对应符号表。

图7 变异程序及对应符号表
以图7中的变异程序和符号表为例,语义校验的过程如下:
(1)
首先将无效变量替换为特殊字符串FIXME,即if语句中的变量x,y;
(2)
删除在变异过程中产生的没有详细定义的变量,即11行中的结构体X,它仅对变量进行声明,并没有具体定义;
(3)
查找符号表生成有效表达式替换FIXME:
(a)
推断变量FIXME的类型,首先将类型赋为AnyType,然后根据类型推断步骤逐步向上推断出具体类型,像如图所示示例,因为其包含操作符“>=”,所以初步认定FIXME为数据类型,如:short\int等;
(b)
在符号表中查找在该语句作用域之前定义的变量,在该节点的祖父节点中,且OID在该节点作用域之前的变量均复合要求,像s、a、c、main()、e、b;
(c)
根据查找得到的变量列举所有可能的表达式,并进行分类。在这里构成的表达式主要有两个类型:int类型(a,c,s.d,b[0],b[1])、struct类型(s);
(d)
按照所需的类型,随机选择表达式替换FIXME,至不产生语义错误;
六、 实验设计及结果
01 具体实现
本方法中的前端生成器是由Bison和Flex构成,BNF语法来源于各编程语言的官方文档或者开源库ANTLR[1],语义注释则是本文作者提供了一个json模板,用户根据需求进行输入。Bison和Flex针对于BNF语法中各个标签和语义注释的解析方法构成IR转换器。
本方法是基于AFL 2.52b进行构建的,保留了其fork-server机制和队列调度算法,并将其测试用例生成模块替换为POLYGLOT。
02 实验设置
本实验的测试目标为9种流行编程语言的21中解析器和编译器;如:解析C语言的GCC/clang、解析JS代码的JsCore等。
实验比较的Fuzz引擎为:三个通用的模糊器 (AFL[2],混合QSYM[3],基于语法的Nautilus[4])、针对于C解析器的CSmith[5]和针对于JavaScript解析器的DIE[6]。
03 具体实验
类型系统的目的是收集变量类型信息,并使用Type map结构记录变量基本类型和用户自定义类型,便于根据类型查找有效变量。
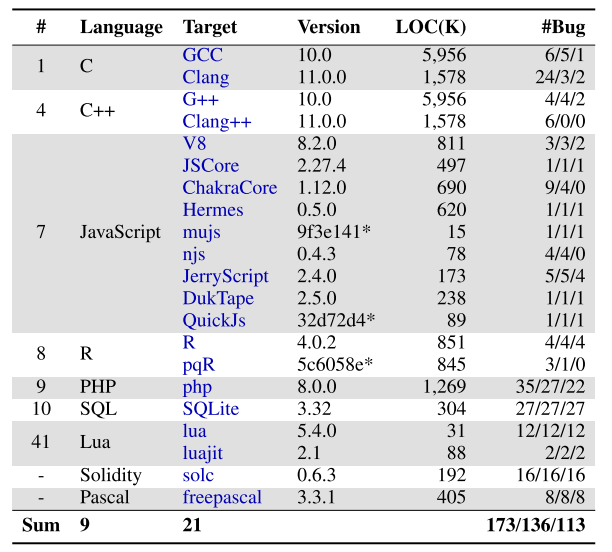
(1)实验一:测试发现bug数量
该实验室将POLYGLOT应用在9种编程语言的21个代表性处理器上,总计发现报告173个漏洞,已经确认136个,已经修复113个,并分配了18个CVEs。具体结果如下表所示。
通过结果可知,POLYGLOT可以在多种编程语言的处理器中发现真实漏洞,证明POLYGLOT具有普遍适用性。
表1 POLYGLOT发现bug数量实验结果
(2)实验二:验证语义校验的有效性
该实验的比较对象为POLYGLOT和POLYGLOT-syntax(本工具删除语义验证部分)。比较指标为:发现唯一崩溃的数量、语言的有效性和边覆盖率。
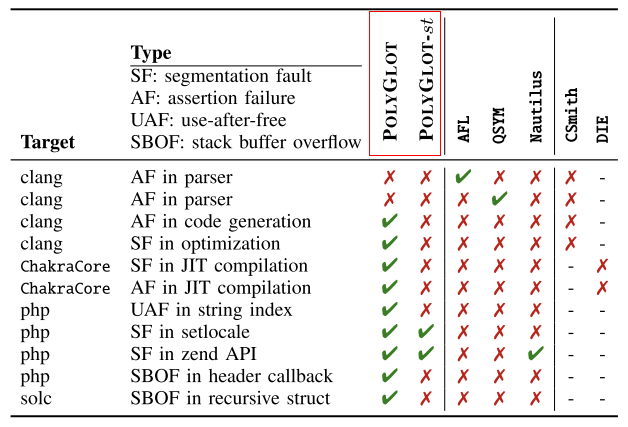
发现唯一崩溃数量的实验结果如下表2所示。结果显示完整工具可以发现9个错误,包括php,clang,ChakraCore;缺少语义验证的工具只能发现php中的两个错误。且经过对这两个php bug分析,触发该错误的代码位于执行的第一行,所以没有语义验证的POLYGLOT只能发现php浅层次的漏洞。
表2 POLYGLOT&其他fuzzer发现bug数量实验结果
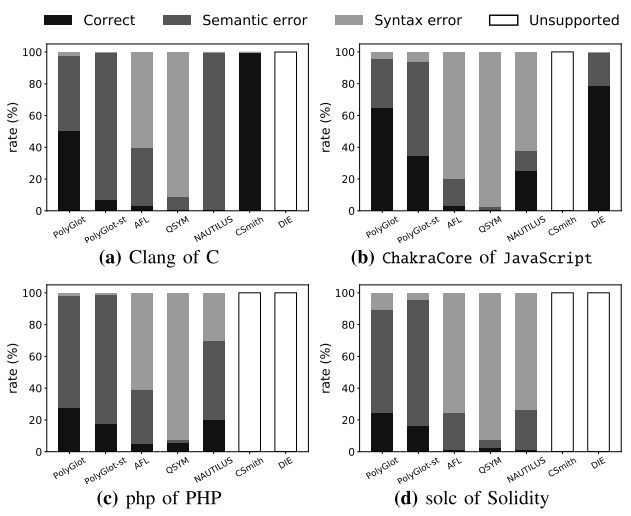
二者语言有效性的实验结果如下表3所示。结果显示,与POLYGLOT-syntax相比,针对于Clang、ChakraCore、php 和solc,POLYGLOT均提高了测试用例的语言有效性,表明语义验证可以明显提高测试用例的语义正确性。
表3 POLYGLOT&其他fuzzer语言有效性实验结果
二者边覆盖率的实验结果如下表4所示。结果显示,针对于四种处理器,POLYGLOT的边覆盖率均高于POLYGLOT-syntax,说明POLYGLOT中的语义验证机制可以使得测试用例探索到更深的层次,从而发现更多bug。
表4 POLYGLOT&其他fuzzer边覆盖率实验结果
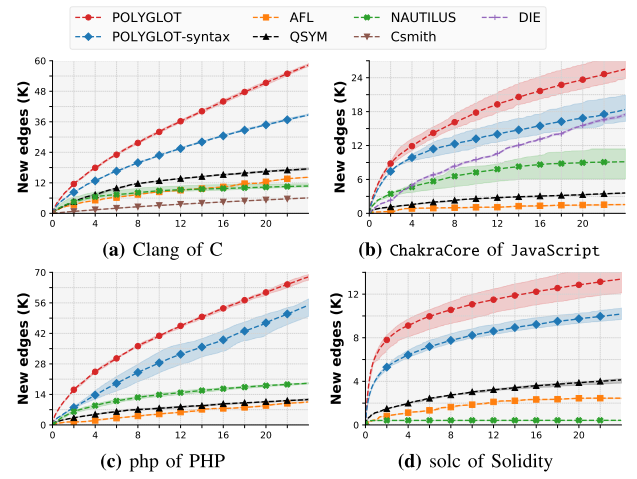
(3)实验三:与其他fuzzer比较
该实验的比较对象为POLYGLOT和三个通用的模糊器 (AFL,混合QSYM,基于语法的Nautilus)、针对于C解析器的CSmith和针对于JavaScript解析器的DIE。比较指标为:发现唯一崩溃的数量、语言的有效性和边覆盖率。实验结果如上表2、3、4所示。
根据表2实验结果可知,POLYGLOT发现了四种处理器上的9个bug,其他fuzzer引擎中只有AFL和QSYM各发现一个位于clang中的解析错误,这是POLYGLOT不曾发现的,但是仍然可以说明,POLYGLOT可以发现更多语言处理器中的bug。
表3结果表示,对于通用的模糊器,POLYGLOT生成的测试用例的语言有效性均高于其他3种fuzzer,但是对于两种针对于特定语言的模糊器CSmith和DIE,POLYGLOT的有效性均低于二者,但是POLYGLOT具有普遍性,可以适用于多种语言处理器。
表4结果显示,对于通用的模糊器,POLYGLOT的边覆盖率均高于其他3种fuzzer,这是由于其语言的有效性导致其可以执行到更深层次。但是对于两种针对于特定语言的模糊器CSmith和DIE,POLYGLOT的边覆盖率仍然高于二者,这可能是由于其他机制导致的,像覆盖引导机制、代码结构等。经实验验证,当POLYGLOT删除覆盖引导机制时,其边覆盖率会低于CSmith。
七、 局限及不足
POLYGLOT的局限性以及可能的解决方法如下所示。
01 类型系统、范围系统的局限:
POLYGLOT的语义验证过程中所使用的类型系统比较适用于静态作用域,动态作用域下会导致类型定义不准确。该缺陷可以利用动态执行在模糊之前收集种子输入的运行时信息,进而可以准确收集变量信息。
02 BNF语法的局限
BNF语法并不能精准描述语言的语法,其通常是真实语法的超集,仍会导致语法错误。该缺陷的解决思路是在动态执行中推断语法或者使用深度学习方法学习语法。
03 语义的局限
POLYGLOT目前校验的语义为:变量的类型和范围。后续可以继续添加编程语言共享的更多语义问题进行校验,以进一步提高语义正确性。
八、 总结
本文主要针对语言处理器模糊测试领域中语义有效性和普适性问题,提出POLYGLOT工具。这是一个通用的模糊框架,可生成用于测试不同编程语言的处理器的高质量输入。经实验验证,POLYGLOT成功在9种语言的21个处理器上识别了173个新错误,且相较于其他fuzz引擎,本工具的代码覆盖率更高,说明POLYGLOT在测试语言处理器方面比现有的模糊器更有效。
参考文献
1.
Grammars written for ANTLR v4. https://github.com/antlr/grammars-v4,2020.
2.
Michal Zalewski. American Fuzzy Lop (2.52b). http://lcamtuf.coredump.cx/afl, 2019.
3.
Insu Yun, Sangho Lee, Meng Xu, Yeongjin Jang, and Taesoo Kim. Qsym: A practical concolic execution engine tailored for hybrid fuzzing. In Proceedings of the 27th USENIX Conference on Security Symposium,USA, 2018.
4.
Cornelius Aschermann, Tommaso Frassetto, Thorsten Holz, Patrick Jauernig, Ahmad-Reza Sadeghi, and Daniel Teuchert. Nautilus: Fishing for deep bugs with grammars. In NDSS, 2019.
5.
Xuejun Yang, Yang Chen, Eric Eide, and John Regehr. Finding and understanding bugs in c compilers. In Proceedings of the 32nd ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI’11, New York, NY, USA, 2011.
6.
S. Park, W. Xu, I. Yun, D. Jang and T. Kim, "Fuzzing JavaScript Engines with Aspect-preserving Mutation," 2020 IEEE Symposium on Security and Privacy (SP), 2020, pp. 1629-1642, doi: 10.1109/SP40000.2020.00067.
 Anna艳娜
Anna艳娜
 X0_0X
X0_0X
 安全圈
安全圈
 安全侠
安全侠
 FreeBuf
FreeBuf
 007bug
007bug
 虹科网络安全
虹科网络安全
 安全侠
安全侠
 RacentYY
RacentYY
 FreeBuf
FreeBuf
 Coremail邮件安全
Coremail邮件安全
 X0_0X
X0_0X
