3 月 31 日,正如马斯克一再承诺的那样,Twitter 已将其部分源代码正式开源,其中包括在用户时间线中推荐推文的算法。目前,该项目在 GitHub 已收获 10k+ 个 Star。
马斯克在 Twitter 上表示此次发布的是“大部分推荐算法”,其余的算法也将陆续开放。他还提到,希望“独立的第三方能够以合理的准确性确定 Twitter 可能向用户展示的内容”。在关于算法发布的 Space 讨论中,他说此次开源计划是想让 Twitter 成为“互联网上最透明的系统”,并让它像最知名也最成功的开源项目 Linux 一样健壮。“总体目标,就是让继续支持 Twitter 的用户们最大程度享受这里。”

Twitter 官网博客详细介绍了算法在确定 For You 时间线所显示的推文时,会具体参考哪些内容并如何对其进行排名和过滤。
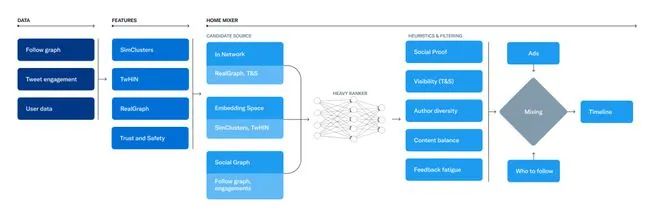
用于构建时间线的主要组件
从博文来看,推荐管线由三个主要阶段组成。
首先,它会收集“来自不同推来源的最佳推文”,之后使用“机器学习模型”对各推文进行排名。最后,它会过滤掉来自已屏蔽用户的推文、已经看过的推文或者在工作时间不宜观看的内容,最后将结果显示在时间线上。
文中还进一步对过程中的具体步骤做出解释。
例如,第一步大约会查看 1500 条推文,目标是让 For You 时间线中约 50% 的推文来自已关注的用户(即「人际网络内」),50% 的推文来自“尚未关注的「人际网络外」账户”。排名则“参与积极性进行优化(例如点赞、转发和回复)”,最后一步则努力保证用户不会看到同一个人的过多推文。
诚然,代码透明(用户能够看到系统到底在以怎样的机制为时间线选择推文)和代码开源(允许社区提交自己的代码作为备选,也可在其他项目中使用 Twitter 算法)并不完全是一码事。
虽然马斯克反复提到要开源,但如果 Twitter 想要言而有信,就必须满足后者的标准。换言之,Twitter 需要建立新的治理系统,决定批准哪些 PR、关注哪些用户提出的问题,以及如何阻止恶意人士出于个人目的而破坏代码。
目前来看,Twitter 正在为此而努力。GitHub 上的自述文件提到,“我们邀请社区在 GitHub 上提交问题和 PR,为推荐算法的改进提出建议。”但文件还写道,Twitter 仍在构建“用于建议管理并将变更同步至内部代码仓库的工具”。马斯克领导下的 Twitter 曾经做出过不少承诺,但并没能坚持下来,所以恐怕要到其实际接收社区代码之后才能确定这是否属实。
马斯克的开源承诺
此前,马斯克曾多次表示将开源 Twitter 算法。
2022 年 3 月,马斯克曾在 Twitter 发起一项调查,询问用户对该平台算法开源的看法。他写到:“我担心 Twitter 算法中实际存在的偏见会产生重大影响,我们怎么知道背后到底发生了什么?”马斯克认为,我们对 Twitter 这个公共平台的信任程度越高,文明的风险就越小。
2022 年 5 月,马斯克曾与 Twitter 联合创始人兼前 CEO Jack Dorsey 就该平台的算法问题发生过争执。马斯克表示,“算法正在以你们意识不到的方式操纵你们……我不是说算法有恶意,但它的确在猜测你想看什么内容,这样就会无意间操纵 / 放大你的观点,而你却完全没有意识到正在发生什么。”
2022 年 10 月接管 Twitter 后,马斯克关于开源 Twitter 算法的想法也没有发生改变。
2023 年 2 月 21 日,马斯克称将于下周对 Twitter 算法进行开源。当时一位 Twitter 用户表示,如果 Twitter 能够开源算法,他们将会“真心折服”。马斯克回应道:“当我们下周开源算法时,一开始请做好失望的准备,但之后将会快速改善。”
不过遗憾的是,马斯克并未兑现“下周开源”的承诺。直到 3 月 18 日,马斯克再次发声:“Twitter 将于 3 月 31 日开源所有用于推文推荐的代码。”
马斯克表示:“我们的‘算法’过于复杂且内部未完全理解。人们会发现很多愚蠢的事情,但我们会在发现问题后立即修补。我们正在开发一种简化的方法来提供更具吸引力的推文,但这项工作仍在进行中,这也将是开源的。提供代码透明度一开始可能会令人尴尬,但它应该会让推荐质量快速提高。最重要的是,我们希望赢得您的信任。”

不过尴尬的是,据美联社当地时间 3 月 26 日报道,一份法律文件显示,推特公司的部分源代码遭泄露,被发布在开源编程及代码托管网站 GitHub 上。为防止该事件对其服务产生潜在的破坏性损失,Twitter 已经采取了法律行动,GitHub 遵从通知并删除了被泄露的代码。
现在,马斯克终于如愿开源 Twitter 算法,但他的决断也面临着强烈的反对之声。用户们对自己 For You 页面中经常显示马斯克的推文表示不满,而马斯克的支持者们则担心自己在社区中的参与度正在降低。他辩解称,新的推荐算法希望“最大限度削减”负面和仇恨内容,但之前无法访问这些代码的外部分析师对这种说法并不买账。
此外,Twitter 还可能面临来自开源社区的竞争压力。Mastodon 是一个去中心化社交网络,目前在特定圈子里正越来越受欢迎。Twitte r 公司联合创始人 Jack Dorsey 则正在支持另一个名为 Bluesky 的类似开源项目。
Twitter 推荐算法的底层工作机制
像 Twitter 这样复杂的系统,开源算法并非易事。开源作者 Travis Fischer 曾在一篇文章中分析道,Twitter 的推荐算法是由一个个性化推荐系统提供的,用于预测用户最有可能与哪些推文和用户互动。关于这个推荐系统,最重要的两部分是:
用来训练 ML 模型的基础数据,即 Twitter 的大规模专有网络图;
在确定相关性时考虑的排名信息。
大规模专有网络图
像 Twitter 这样的社交网络就是超大图的实例,节点是用户和推文的模型,边则是回复、转发和喜欢等互动的模型。
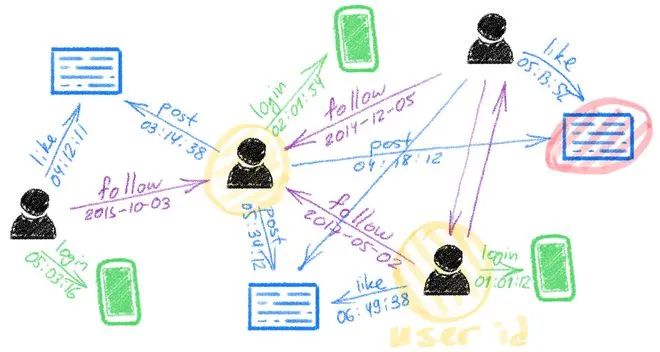
Twitter 动态网络图的可视化,作者是 Michael Bronstein,来自 Twitter 的 Graph ML 部门(2020)。
Twitter 的核心商业价值有很大一部分来自于这个庞大的由用户、推文和互动构成的基础数据集。用户登录、查看推文、点击推文、查看用户资料、发布推文、回复推文等,在 Twitter 上的每一次互动都会被记录到内部数据库。
从 Twitter 的公共 API 获得的数据只是 Twitter 内部跟踪数据中的一小部分。这一点很重要,因为 Twitter 的内部推荐算法可以获得所有这些丰富的互动数据,而任何开源工作都可能仅能使用一个有限的数据集。
排名信息
2017 年,Twitter 的研究人员曾在一篇名为《在 Twitter 时间线上使用大规模深度学习》的文章中提到,为了预测某条推文是否会吸引用户,Twitter 的模型考虑了以下几个要点:
推文本身:它的新近度,存在的媒体卡(图像或视频),总互动数(如转发和喜欢的数量)。
推文作者:用户过去与这个作者的互动,用户与他们联系的强度,用户关系的起源。
用户:用户在过去觉得有吸引力的推文,用户使用推特的频率和程度。研究人员表示,“我们考虑的特征及其各种互动的清单在不断增加,为我们的模型提供了更多存在细微差别的行为模式。”
这些 2017 年的排名信息描述可能有点过时,但这些核心信息在今天仍然与 Twitter 高度相关。因为这份清单很可能已经推广到几十甚至几百个重点机器学习模型,它们支撑着 Twitter 的算法。
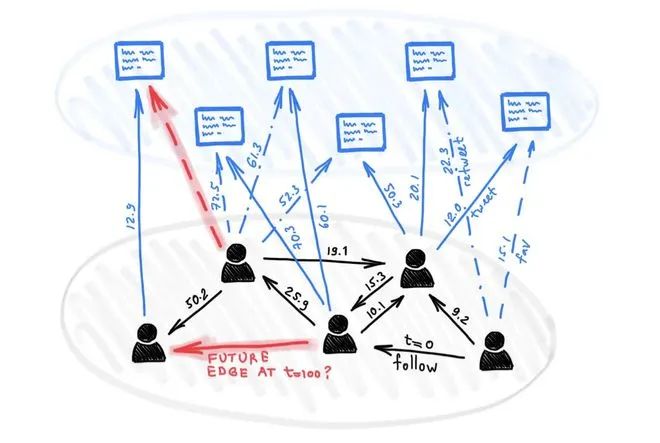
一个深度学习模型的可视化,用于确定一个用户在未来关注另一个用户的可能性。这个模型代表了 Twitter 内部各种推荐系统的一小部分。
Travis Fischer 认为,将 Twitter 推荐算法开源难免会遇到一些重大的工程挑战。
比如,Twitter 的网络图非常庞大,包含数以亿计的节点和数十亿的边。Twitter 的实时性带来了另一个独特的挑战:用户希望 Twitter 尽可能地接近实时,这意味着底层网络图是高度动态的,延迟成为一个真实的用户体验问题。此外,还有可靠性、安全与隐私方面的挑战。
但无论如何,马斯克还是兑现了他的开源承诺,Twitter 推荐算法开源也标志着,这类平台的透明度正在迈出关键一步。
 RacentYY
RacentYY
 X0_0X
X0_0X
 RacentYY
RacentYY
 Anna艳娜
Anna艳娜
 Anna艳娜
Anna艳娜
 安全侠
安全侠
 Anna艳娜
Anna艳娜
 Andrew
Andrew
 X0_0X
X0_0X
 RacentYY
RacentYY
 FreeBuf
FreeBuf
