 一颗小胡椒
一颗小胡椒
工作来源
Botconf 2023
工作背景
Yara 是非常流行的分析工具,因为其简单易用性深受分析人员的喜爱。简单的例子如下所示,包含元数据、字符串与匹配条件。该规则匹配非字母数字字符分割的文本字符串或者在起始位置匹配正则表达式或者十六进制字符串。

最常见的用例就是使用 Yara 来检测特定的恶意软件家族,但创建此类规则非常复杂。Yara 本身存在多种方法来检测潜在的慢速扫描,告警如下所示:

这些告警基于启发式方法来评估规则质量,但并没有给出提高性能的建议。更糟糕的是,存在告警的规则是不允许在 VirusTotal Hunting 中使用的。
匹配的过程一共四个步骤:字符串原子化、Aho-Corasick 自动机、字节码引擎与条件评估。
字符串原子化
原子是长度从零到四个字节的子串,Yara 提供了多种启发式方法选择独一无二的、最有效的原子。例如 Yara 会从正则表达式 /abcd[x-z]/ 中选择字符串 abcd。
Aho-Corasick 自动机
基于所有的原子构建 Aho-Corasick 自动机前缀树:

字节码引擎
字节码引擎获取潜在匹配列表,根据字符串的完整定义(包括各种修饰符)验证哪些是匹配命中。
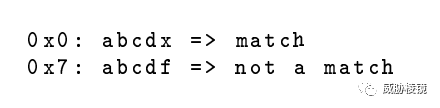
条件评估
条件评估是在字符串匹配后进行的,例如文件大小的限制仍然会在字符串匹配之后进行。值得注意的是短路评估,可以通过改变条件的顺序来提高匹配性能。
工作准备
使用 4.2.3 版本的 Yara,主机运行在 CentOS 系统上且使用 AMD EPYC 7502 32 核处理器。
使用数据集:
- 一共 8.2GB,包含 31220 个良性文件与恶意样本的数据集(https://figshare.com/authors/Eduardo_de_O_Andrade/4923649)
- 一共 14GB 的样本文件(Avast-CTU Public CAPE
- Dataset)
- 正则性能测试(https://github.com/rust-leipzig/regex-performance)
工作评估
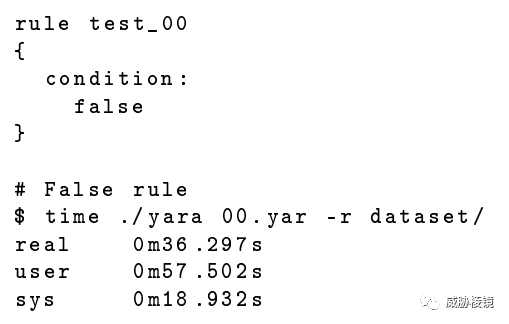
一共 22GB 左右的样本文件,最简单的规则扫描需要 36 秒:
字符串 vs 条件

优化后的规则如下所示,这是小端序匹配,而大端序可以使用 intXYbe() 或者 uintXYbe()。

不再扫描整个文件,而是扫描指定的位置。并且,文件大小还需要满足条件限制。

提升性能大约 10%,在大规模数据集中差异会很明显。
不一定存在
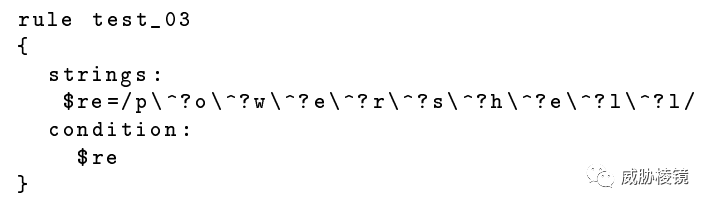
优化后的规则如下所示:

创建两个字符串,一个是在前两个字符之间插入符号,另一个没有。这会让 Yara 选择子字符串 p^o 与 po 作为原子。这相比只使用一个字符 p,效率会更高。

性能提升大约 14%,优化后的规则使 Yara 在匹配过程中进行更多优化。
交替字符串

优化后规则如下所示。尽管连接起来的字符串更长,但 Yara 不会主动连接。所以要匹配很短的字符串,尤其是互相交叉的字符串,尽量不要合并在一起。

提供的信息越多,Yara 选择的原子越长,扫描也就越快。

性能提升大约 19%。
范围太大

优化后的规则如下所示。如果使用太多通配符,则会提示字符串过于笼统,建议缩小范围。

尽量避免使用通配符,否则性能会极剧下降。

性能提升大约 40%。
IPv6 地址

优化后的规则如下所示。

只匹配了以 2001 为前缀的全球单播地址,并且限制了十六进制符号的范围。

性能提升大约 50%,且没有误报。
工作思考
Yara 应该是属于是入门容易精通难的那一类技术了,使用不当的情况下在大数据集下会为系统带来极大的性能负担。VirusTotal 等头部玩家都不想纯靠机器的性能硬抗,也在版本迭代中积极地优化 Yara 匹配的效率。研究人员也应该进一步学习,写出更“好”的规则来更高效地进行威胁狩猎。
 RacentYY
RacentYY
 RacentYY
RacentYY
 Anna艳娜
Anna艳娜
 X0_0X
X0_0X
 安全侠
安全侠
 Anna艳娜
Anna艳娜
 Anna艳娜
Anna艳娜
 Anna艳娜
Anna艳娜
 FreeBuf
FreeBuf
 Anna艳娜
Anna艳娜
 RacentYY
RacentYY
 FreeBuf
FreeBuf
