联邦学习(Federated Learning, FL)使多个用户能够协作训练高精度全局模型,同时保护用户的数据隐私。然而,联邦学习容易受到恶意参与者发起的拜占庭攻击。尽管该问题已引起广泛关注,但现有的防御算法存在一些缺陷:即使在前几轮检测到恶意用户后,服务器仍会非理性地选择恶意用户进行聚合;防御算法在数据异构场景无法有效抵御女巫攻击。为此,我们提出了联邦学习鲁棒性聚合算法MAB-RFL。通过将用户选择建模为扩展的多臂老虎机(Multi-Armed Bandit, MAB)问题,我们提出了一种自适应用户选择策略,以选择更有可能提供高质量更新的诚实用户。然后,我们提出了两种方法来识别来自女巫和非女巫攻击的恶意更新,基于这些方法可以准确评估每个用户选择决策的奖励以阻止恶意行为。MAB-RFL在对潜在良性用户的探索和利用之间取得了令人满意的平衡。大量的实验结果表明,MAB-RFL在各种攻击以及攻击者比例下均优于现有防御。
该成果“Shielding Federated Learning: Robust Aggregation with Adaptive Client Selection”被CCF列表A类国际会议International Joint Conference on Artificial Intelligence (IJCAI 2022)录用为Long Oral Presentation。IJCAI是人工智能领域国际顶级会议,2022年Long Oral Presentation的录用率仅有3.75%。

- 论文链接:https://www.ijcai.org/proceedings/2022/0106.pdf
背景与动机
联邦学习是近年来兴起的分布式架构,其旨在保护用户数据隐私的前提下实现分布式数据的联合训练。由于训练过程中用户和中心服务器仅需交换模型参数,而用户的源数据始终保持在本地,因此用户隐私得到了较好的保护。然而联邦学习极易遭受拜占庭攻击,即攻击者可以上传恶意模型参数使得最终的聚合结果偏离正常模型甚至留下后门。
为了抵御拜占庭攻击,研究人员提出了一系列防御算法。它们的核心思想包括:根据相似性剔除离整体分布较远的参数;利用统计特性剔除或者绕开恶意参数;对模型参数进行裁剪从而降低恶意参数对聚合结果的影响;使用干净数据集对模型参数的性能进行检验。
虽然现有防御种类丰富、数量庞大,但它们普遍存在以下的短板,导致其很难部署到实际应用中。第一,它们忽略了用户选择的重要性。现有防御要么选择所有用户,要么随机选择一部分用户参与训练,前者会带来巨大的通信开销,而后者则会造成模型收敛速度慢、准确率低;第二,它们无法有效应对女巫攻击,在女巫攻击场景下所有恶意参数极度相似或者完全相同,而现有防御的倾向于剔除离整体分布较远的参数,这会造成正常参数被剔除;第三,现有防御在数据异构场景表现不佳,因为数据异构会导致正常参数之间也存在巨大差异,给检测带来极大困难;第四,现有防御效果较好的方案往往依赖于与用户数据分布相同的验证数据集,这明显违背了联邦学习保护用户隐私的初衷。
为了解决这些问题,我们提出了首个基于多臂老虎机的联邦学习鲁棒性算法MAB-RFL。该算法将联邦学习中的用户选择问题建模为扩展版的多臂老虎机问题,使得中心服务器能够自适应地选择那些有较高概率贡献良性参数的用户。在应用现有的多臂老虎机问题解决方案到联邦学习场景之前,我们需要解决两个挑战。第一,在标准的多臂老虎机问题中,每轮只有一个臂被选中,然而在联邦学习场景,每轮需要选择多个用户来保证模型的高精度以及收敛速度。受汤普森采样算法的启发,我们将用户的期望奖励视为该用户被选择的概率,中心服务器基于概率动态地选择当前轮次的参与者;第二,在标准的多臂老虎机问题中,一旦玩家选择一个臂,老虎机会自动反馈相应的奖励,然而在联邦学习中,服务器需要对每一次用户选择进行评估并完成奖励分配。为此我们提出了两个检测算法分别检测女巫攻击和非女巫攻击,并基于检测结果为用户分配奖励。
方案设计
我们提出的MAB-RFL主要包含自适应用户选择、女巫攻击检测、非女巫攻击检测、奖励分配四个关键步骤。
自适应用户选择:在标准的汤普森采样算法中,每次只会选择平均奖励(由Beta分布估计)最大的臂。将其扩展到联邦学习的一种直觉想法是选择平均奖励排名前m(m为良性用户数量)的用户。然而,这依赖于一个假设,即良性用户的数量是固定并且被服务器所知。这个假设是不现实的,因为联邦学习是一个动态分布式网络,其中诚实和恶意的用户可以随意退出。
为了摆脱对m的依赖,我们提出以动态变化的概率选择用户(即,概率随着每个用户过去的表现而变化,而不是使用固定的概率)。具体而言,用户k被选择概率为pk←Beta(Bk,Mk),其中Bk和Mk分别表示用户k过去表现正常和恶意的轮次(由下面的女巫攻击检测和非女巫攻击检测模块判断)。
该算法可以达到利用(Exploitation)和探索(Exploration)的良好平衡。具体来说,如果一个用户总是持续贡献良性更新(即Bk大而Mk小),则该用户会从Beta(Bk,Mk)获得一个较大被选概率pk(利用);如果一个用户每次参与联邦学习都贡献恶意更新(即Mk大而Bk小),则该用户会得到较小的pk(利用);如果一个用户很少被选择(Bk和Mk都很小),该用户依然有可能获得较大的pk(探索),因为当参数Bk和Mk均很小时,Beta分布的方差较大。
女巫攻击检测:女巫攻击的主要特性为恶意更新两两之间非常相似,甚至比正常更新之间的相似度更高,因此现有基于离群值检测的防御算法容易出现误识别。基于这一特性,我们提出使用最大连通子图策略来检测女巫攻击。具体而言,我们将每个上传到服务器的本地更新视为一个节点(vertex),并根据如下规则构造一个无向图:若更新 和
和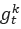 满足
满足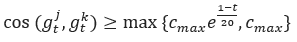 ,则在节点j和k之间添加一条边。上式中cos表示余弦相似度,超参数cmax和cmin分别为预估的最大和最小的正常更新相似度,t表示当前轮次。可以看到,随着迭代的进行,可容忍余弦相似度(不等式右边)越来越小,这也意味着攻击者越来越难发起隐蔽的女巫攻击。
,则在节点j和k之间添加一条边。上式中cos表示余弦相似度,超参数cmax和cmin分别为预估的最大和最小的正常更新相似度,t表示当前轮次。可以看到,随着迭代的进行,可容忍余弦相似度(不等式右边)越来越小,这也意味着攻击者越来越难发起隐蔽的女巫攻击。
在构造好无向图后,该图的最大连通子图中的节点(本地更新)将被识别为恶意更新并被剔除。女巫攻击检测过程如图1所示。
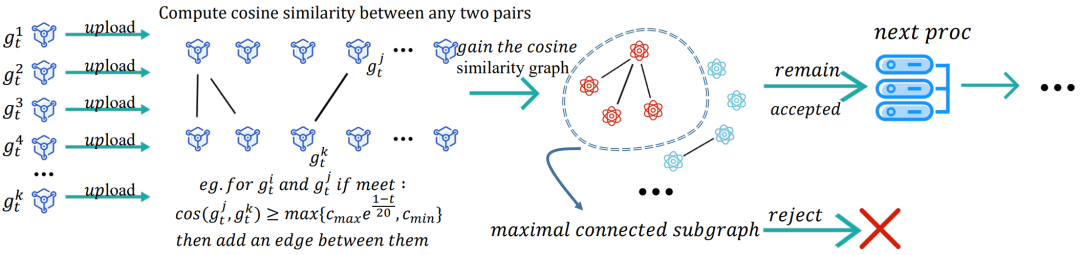
图1 女巫攻击检测
非女巫攻击检测:在非女巫攻击场景,恶意更新彼此之间差异较大,检测它们极其困难。其关键原因在于本地更新的维度极高,其中既包含关键性的特征,同时也包含掩盖正常与恶意更新之间差异的冗余信息。此外,联邦学习固有的数据异构特性导致正常更新之间的差异也较大,因此发现恶意更新变得更加困难。鉴于此,我们的主要想法是提取关键特征,在易于区分的低维特征空间剔除恶意更新。另外,我们引入动量机制,来降低本地更新之间的方差,从而构造一个类似于同构的分布。具体而言,我们的算法包含如下三个步骤:
- 计算动量向量:
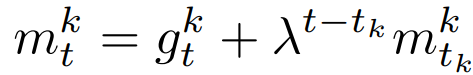 ,其中λ∈(0,1)表示历史信息的重要程度,tk表示用户k上一次被选的轮次;
,其中λ∈(0,1)表示历史信息的重要程度,tk表示用户k上一次被选的轮次; - 使用主成分分析法(PCA)提取每个动量向量的关键特征;
- 对关键特征使用层次聚类算法将动量向量分为两个簇,并将较小簇中的更新视为恶意更新并剔除,然后聚合较大簇中的动量向量用于更新全局模型。
奖励分配:一个合理的奖励分配机制对于MAB-RFL降低恶意用户被选概率极为关键。在女巫攻击和非女巫攻击识别出恶意更新后,我们将对应用户的奖励设为0,即Mk←Mk+1。对于通过这两个检测模块的更新,我们将对应用户的奖励设为1,即Bk←Bk+1。
实验评估

图2 LF攻击下性能对比
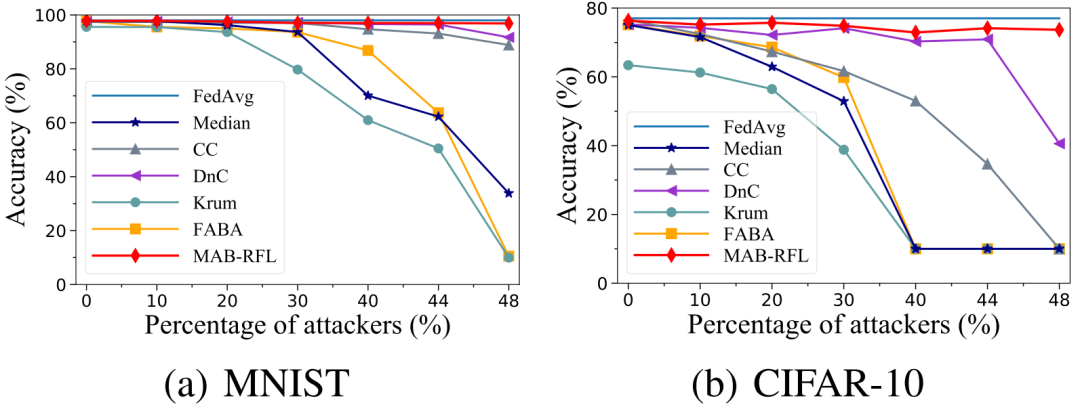
图3 LIE攻击下性能对比
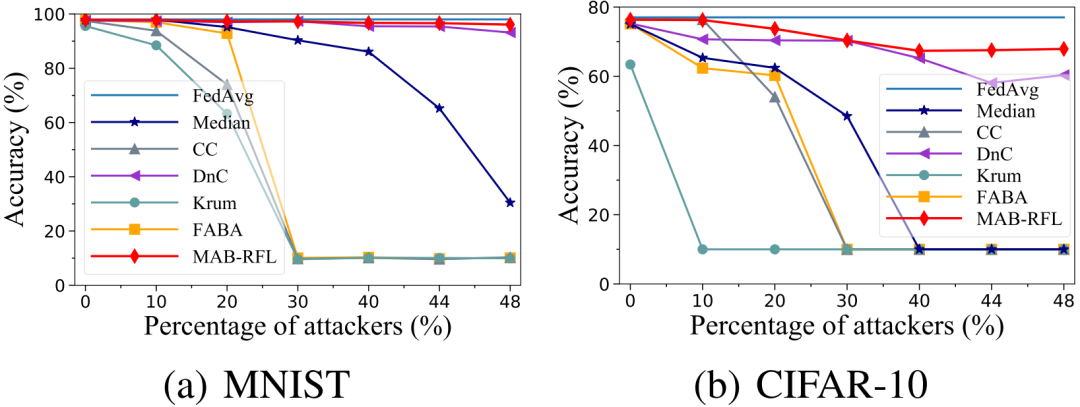
图4 AGRT攻击下性能对比
我们使用多个鲁棒性聚合算法作为基线,在MNIST和CIFAR-10数据集上,对MAB-RFL的有效性进行评估。我们考虑了三种不同知识强度的攻击,即LF攻击、LIE攻击和AGRT攻击。其中LF为零知识攻击(攻击者不知道正常用户的更新和服务器部署的聚合算法),LIE为部分知识攻击(攻击者只知道正常用户的更新但不知道服务器部署的聚合算法),AGRT为全知识攻击(攻击者同时知道正常用户的更新和服务器部署的聚合算法)。如图2、图3、图4所示,在各种攻击以及攻击者比例下,MAB-RFL的模型精度均高于现有防御策略,且攻击者比例越高其优越性越明显。相对于现有最先进的DnC防御,我们的准确率最多可提升33%。
详细内容请参见:
Wei Wan, Shengshan Hu, Jianrong Lu, Leo Yu Zhang, Hai Jin, Yuanyuan He, “Shielding Federated Learning: Robust Aggregation with Adaptive Client Selection”, in Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI), 2022, pp. 753-760.
https://www.ijcai.org/proceedings/2022/0106.pdf
 RacentYY
RacentYY
 安全侠
安全侠
 Anna艳娜
Anna艳娜
 Andrew
Andrew
 Andrew
Andrew
 Anna艳娜
Anna艳娜
 ManageEngine卓豪
ManageEngine卓豪
 安全侠
安全侠
 Andrew
Andrew
 安全侠
安全侠
 Andrew
Andrew
 数缘信安社区
数缘信安社区
