KDD'22:能屈能伸大不同——自放缩图神经网络及其应用
社交推荐(Friend Recommendation)逐渐成为许多线上社交平台的一项重要业务。近年来,相较于浅层的图嵌入模型,图神经网络(Graph Neural Networks, GNNs)在社交推荐中表现出了优秀的性能,这主要归功于GNN显式聚合邻居节点信息的操作。然而,现有的许多GNN在邻居聚合时使用了静态的、事先手工设定的归一化权重,这将导致模型难以对嵌入向量的尺度做出适应性的调整,从而产生“尺度扭曲”问题。
为了克服这一问题,我们提出了一种简单而有效的GNN嵌入向量尺度自适应调整方法。该方法通过一个自放缩网络(self-rescaling network,SSNet)来为GNN模型输出的每个嵌入向量生成一个对应的标量放缩系数,进而对嵌入向量的尺度进行放缩调整。SSNet非常轻量,仅由一个两层的感知机构成,同时,SSNet也与模型无关,可以施加在现有的多种GNN模型上进行端到端的训练。实验中,我们在七种现有GNN模型和三个大规模社交网络数据集上验证了SSNet的有效性。此外,我们在Xbox社交推荐平台进行了为期一个月的在线A/B测试,并观察到SSNet模型在“添加推荐朋友”这一用户行为统计上带来了24%的性能提升。
为了促进社交推荐领域研究与应用的发展,我们还对社交推荐中的一些关键问题进行了观察分析。我们观察到,基于网络规则的模型与图嵌入模型能够分别从不同的角度进行目标召回;相较于基于网络规则的模型,图嵌入模型能够显著改善过滤气泡问题(Filter Bubble)和回声室效应(Echo Chamber);将两类模型的特征输入决策树模型进行集成,能够形成一个更加完备的线上预测方法--这一策略目前已被应用在Xbox游戏社交平台的社交推荐中。
该成果“Friend Recommendations with Self-Rescaling Graph Neural Networks”发表于第28届ACM SIGKDD知识发现与数据挖掘大会上(KDD’22),KDD是数据挖掘领域的顶级会议之一,是中国计算机学会(CCF)推荐的A类会议。

- 论文链接:
- https://dl.acm.org/doi/10.1145/3534678.3539192
背景与动机
线上社交平台正在逐渐融入并充实着我们的日常生活。例如,我们通过Facebook或TikTok与朋友分享个人生活;我们在LinkedIn上建立自己的职业网络;我们在Xbox上和朋友一起享受游戏。随着线上社交网络(Online Social Network)规模的不断增长,社交推荐(Friend Recommendation)逐渐成为许多平台的一项重要业务。传统的社交推荐方法主要基于手工设计的规则来表征社交网络中两个节点的接近度,例如Common Neighbors (CN)、Local Naive Bayes based Common Neighbors (BCN), 和Personalized PageRank (PPR)。这些方法的主要缺点有:(1)手工设计的规则只能刻画社交网络中有限的特征,并不全面;(2)一些规则,如BCN和PPR,需要一对节点的高阶网络信息,难以拓展到实时的推荐业务中;(3)推荐节点通常集中在源节点的较近邻域,这些邻域高度同质化,加剧了过滤气泡问题(Filter Bubble)和回声室效应(Echo Chamber)。
近年来,相较于浅层的图嵌入模型,图神经网络(Graph Neural Networks, GNNs)在社交推荐中表现出了优秀的性能,这主要归功于GNN显式聚合邻居节点信息的操作。然而,我们观察到现有的许多GNN在邻居聚合时使用了静态的、事先手工设定的归一化权重。例如,LightGCN使用了一种加权求和的邻居聚合操作: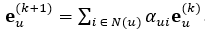 。其中的权重固定为
。其中的权重固定为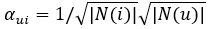 ,基于节点的度计算得到。PPRGo的邻居聚合基于节点的PPR得分:
,基于节点的度计算得到。PPRGo的邻居聚合基于节点的PPR得分: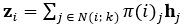 ,其中
,其中 是PPR得分向量。这种静态的、基于手工设定的方式难以对嵌入向量的尺度做出适应性的调整,将产生“尺度扭曲”问题(我们以LightGCN为例分析了两个具体的尺度扭曲案例,详情参见论文2.3节)。
是PPR得分向量。这种静态的、基于手工设定的方式难以对嵌入向量的尺度做出适应性的调整,将产生“尺度扭曲”问题(我们以LightGCN为例分析了两个具体的尺度扭曲案例,详情参见论文2.3节)。
模型设计
为了克服这一问题,我们提出了一种简单有效的GNN嵌入向量尺度自适应调整框架,可以施加在现有的多种GNN模型上进行端到端的训练。该方法通过一个自放缩网络(self-rescaling network,SSNet)来为GNN模型输出的每个嵌入向量生成一个对应的标量放缩系数,进而对嵌入向量的尺度进行放缩调整,如图1(a)所示。具体地,给定GNN模型输出的嵌入向量z,SSNet通过一个轻量的两层感知机生成一个标量放缩系数: 。该系数G(z)将用于调整嵌入向量z的尺度,生成调整后的嵌入向量:
。该系数G(z)将用于调整嵌入向量z的尺度,生成调整后的嵌入向量: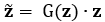 。
。
我们考虑了三种SSNet结构上的变体,如图1(b-d)所示,分别为:L2归一化(L2 Normalization)、前馈网络(Feed-Forward Net)和加性网络(Additive Network)。实验结果表明,这些变体的性能均无法超过SSNet。除了端到端(End-to-End Training)的训练方式外,我们还设计了其它两种SSNet训练方式,分别为:预训练加微调(Pretrain-then-Finetune)和对抗训练(Adversarial Training)。在预训练加微调的方式中,我们首先训练得到一个GNN模型,再固定该模型的参数并训练SSNet网络。在对抗训练的方式中,我们使用一个鉴别器尝试根据嵌入向量推测节点的度,而GNN和SSNet不仅要优化社交推荐的损失函数,还要设法降低鉴别器的准确性,从而弱化节点的度对嵌入向量尺度的影响。实验表明,三种训练方式的效果相近,简单的端到端训练就能得到最佳的性能。
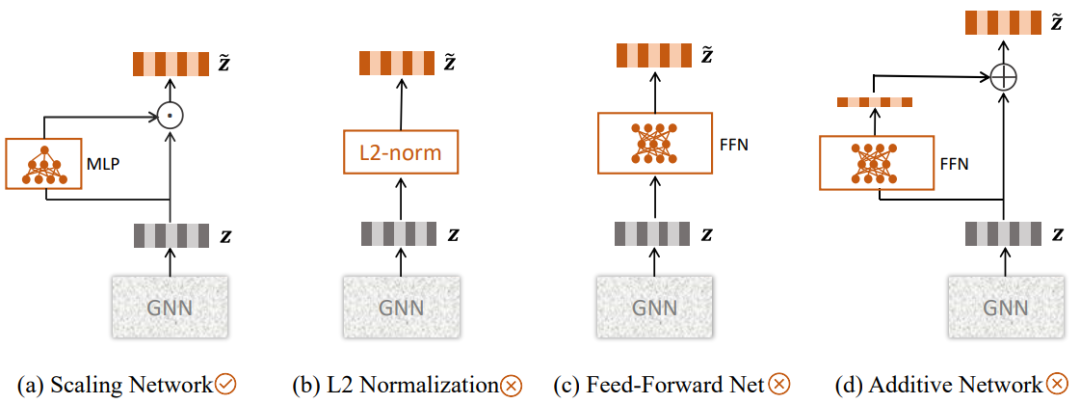
图1 SSNet模型(a)与其它三种变体(b-d)
理论方面,我们从谱分析和图同构两个视角进行了讨论。谱分析视角下,从卷积核参数数量来看,SpectralCNN倾向于使用了过多的参数,LightGCN则倾向于使用了过少的参数,SSNet则是一种介于两者之间的适中的参数化方式。从图同构的角度来看,GIN提出在卷积层中使用MLP来学得一个和Weisfeiler-Lehman图同构测试能力相当的GNN模型。然而在我们的社交推荐场景下,简化的卷积层(如LighGCN和PPRGo)往往表现出更好的性能。SSNet则在模型的输出端增加一个自放缩网络,能够结合GIN模型与诸如LightGCN等简化GNN模型各自的优势。
实验结果
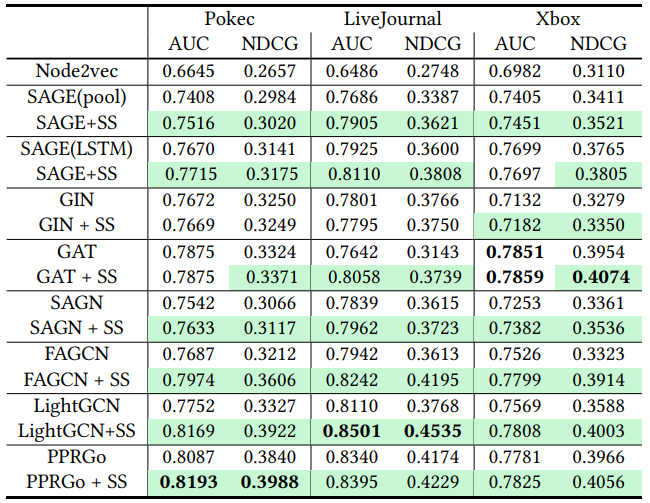
实验中,我们在七种现有GNN模型(GraphSAGE、GIN、GAT、SAGN、FAGCN、LightGCN和PPRGo),三个大规模社交网络数据集(Pokec、LiveJournal和Xbox),以及两大推荐任务(目标召回和目标排序)上进行了模型性能评估。如表1和表2所示,我们观察到SSNet能显著提升多种GNN模型的性能。
我们在Xbox社交推荐平台进行了为期一个月的在线A/B测试,覆盖了美国市场上约10%的主要流量。我们观察到SSNet模型在“添加推荐朋友”这一用户行为统计上带来了24%的性能提升。此外,在高质量朋友推荐的推动下,我们观察到了一些连锁反应,包括“浏览用户资料”行为的267%的提升,“搜索玩家”行为的89%的提升等。
表1 SSNet在目标召回任务上的实验结果(“SS”表示施加了SSNet)。表格中标亮了SSNet获得提升的情形。
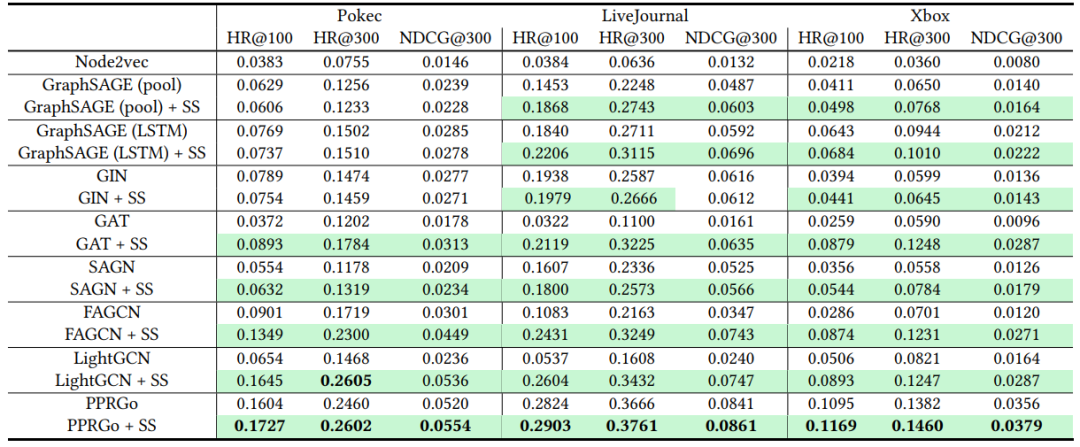
表2 SSNet在目标排序任务上的实验结果(“SS”表示施加了SSNet)。表格中标亮了SSNet获得提升的情形。
为了进一步推动社交推荐领域研究与应用的发展,我们还对其中的一些关键问题进行了经验结果的分享:
1、稠密检索(Dense Retrieval)与基于规则的检索(Rule-based Retrieval)。作为一种稠密检索方法,结合ANN算法的嵌入模型已被广泛地应用于目标召回任务中。尽管有着诸如自动编码图结构信息的优越性,我们发现在目标召回阶段,图嵌入是基于规则的方法的一种补充,而不是其替代品。从图2(a)可以看出,图嵌入的得分差于CN和PPR。然而图2(b)表明,不同的召回方法捕捉了不同方面的候选者。例如,PPR和PPRGo(SSNet)的top-100推荐里仅有8%重叠。从这个意义上说,各种不同的检索方法可以相互补充,从而共同构成一个全面和多样的检索机制。

图2 Xbox数据集上不同召回方法的比较
2、过滤气泡问题(Filter Bubble)与回声室效应(Echo Chamber)。研究表明,基于规则的方法可能造成过滤气泡问题或回音室效应,这意味着用户的社交圈变得越来越同质化和狭窄,不利于社交网络的长期发展。图3比较了PPR和PPRGo(SSNet)的top-k推荐相对于源节点的距离分布。可见PPR的大部分推荐节点都位于源节点的自我中心网络(Ego Network)附近,如1跳距离和2跳距离的邻居。相比之下,图嵌入方法的推荐结果对网络有更广泛的覆盖。
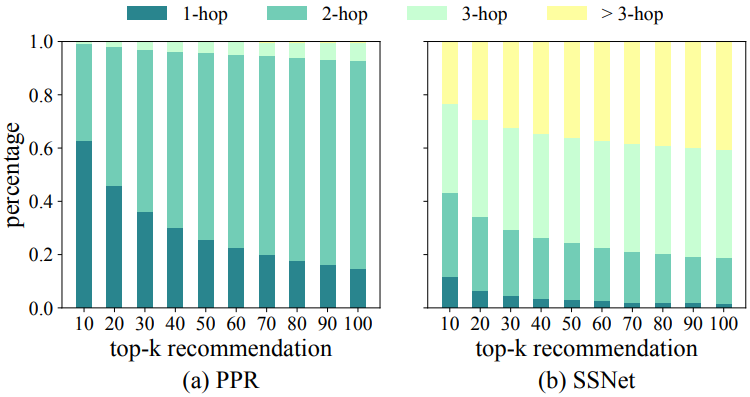
图3 Xbox数据集上top-k推荐相对于源节点的距离分布
3、线上推荐模型。Xbox游戏社交平台的线上推荐方法基于决策树(Decision Tree)模型。输入决策树的特征包括:(1)若干简单的网络特征,例如节点的度和CN;(2)图嵌入特征,即源节点与目标节点的图嵌入向量的点乘得分。决策树能够结合不同的检索方法,从而形成一个更加全面的推荐模型。并且决策树具有良好的可解释性,可以量化输出不同特征的重要程度。我们的实验表明,在所有输入特征中,图嵌入特征贡献了65%的重要程度,并且能够带来20.7%的NDCG指标提升。
详细内容请参见:
Xiran Song, Jianxun Lian, Hong Huang, Mingqi Wu, Hai Jin, and Xing Xie. 2022. Friend Recommendations with Self-Rescaling Graph Neural Networks. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD '22). Association for Computing Machinery, New York, NY, USA, 3909–3919. https://doi.org/10.1145/3534678.3539192
