基于可学习的高通滤波器和选择通道的轻量级隐写分析算法
目前已有恶意分子利用隐写术并结合恶意代码等信息安全技术获取到用户本身的隐私信息,如果任其发展,甚至会危害客户的人身安全。基于此,本文提出了一个轻量级的隐写分析算法,它应用了可被优化的高通滤波器和选择通道的知识获取到丰富的隐写特征信息,从而更有利于隐写检测,实验结果表明本算法具有很好的隐写性能,具有很好的参考意义。
算法详解
本隐写分析算法的网络总体架构如下图所示。该网络包含预处理层,特征提取层和分类层。在预处理层中,应用高通滤波器从图像中提取出残差特征信息,然后将残差特征与选择信道处理后的特征图相结合作为输出。特征提取层由五个卷积层和五个平均池化层组成。最终的分类层由两个全连接层,两个Dropout层组成。下面将描述每个层的具体处理。
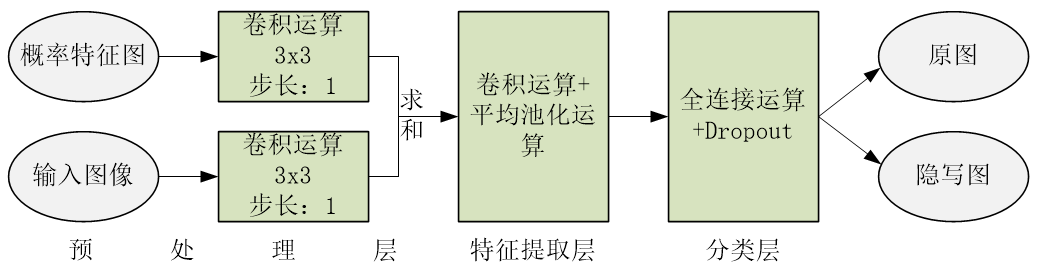
预处理层
隐写可被视为向原图像中加入轻微幅度的噪声信息,人眼几乎不能识别隐写图像和原图像之间的差异。噪声信息改变了相邻像素之间的依赖性,因此,依据像素间的依赖性可以有效地检测图像中是否存在隐写噪声信息。现有空域富模型中的高通滤波器可通过计算图像中的残差信息来捕获捕获隐写术的噪声痕迹,因此,在预处理层中应用高通滤波器提取出可表征隐写信息的残差特征图。同时应用选择通道的知识,有效地计算出不同像素被嵌入隐写信息的概率,获取到对应的概率特征图。最终将这两种特征图做求和运算获取到可信的隐写信息。
残差特征图的获取
在卷积神经网络中,残差信息的提取操作可以通过卷积运算来完成,此时,在卷积运算中选取高通滤波器来初始化卷积核。通常,选择大小为3×3 或5×5的高通滤波器作为预处理层的卷积核。从空域富模型的五种类别高通滤波器“ 1st”、“ 2nd”、“ 3rd”、“ SQUARE 3 × 3”和“ SQUARE 5 × 5”中选择五个滤波器分别初始化卷积核。应用“ 1st”、“ 2nd”和“SQUARE 3 × 3”中的高通过滤器初始化后的卷积核的大小3 × 3,应用其余两种滤波器初始化后的卷积核的大小为5 × 5。由于手工设计的卷积核不一定具有最佳的性能,因此将卷积核加入到卷积神经网络的学习中,从而使预处理层的卷积核随着网络的学习而不断被优化。
在初始化预处理层的卷积核之前,本文对选定的高通滤波器做归一化处理进行适当的约束。以SQUARE 3× 3 的滤波器为例,在如下等式中,添加因子将高通滤波器的中心元素更改为-1,同时所有元素值 的 和保持为0。注意,卷积核在训练过程中会不断被优化和调整,因此卷积核并不是处于绝对的约束状态。
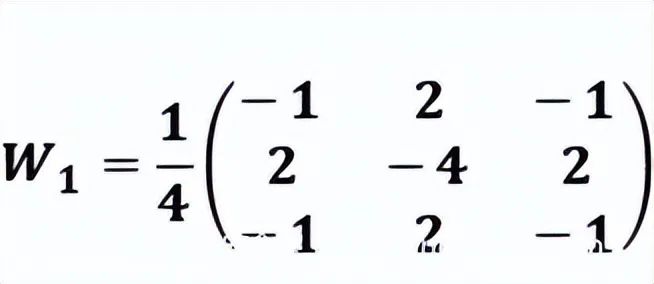
以自适应隐写算法WOW、嵌入率0.4为例,应用五种不同的高通滤波器初始化预处理层的卷积核后,隐写分析算法的检测准确率如下表所示。

分析可知,应用SQUARE 3×3高通滤波器初始化后的网络的检测准确率高于其他四种,这说明SQUARE 3×3高通滤波器提取的残差信息更能表征隐写信息,更有利于隐写分析。同时,与大小为5×5的卷积核相比,大小为3×3 的卷积核具有较少的训练参数。因此,选择空域富模型中的SQUARE 3 × 3 高通滤波器来初始化本文隐写分析算法网络的预处理层。
概率特征图的获取
为了提升算法隐写分析的性能,本文应用了选择通道的知识到卷积神经网络中。通过选择通道的理论技术计算出每个像素点的隐写信息的嵌入概率,以此提升高隐写概率像素区域的残差值。
根据已有研究成果,本文应用L1残差失真范数期望的上界作为选择通道的计算公式,如下公式所示。
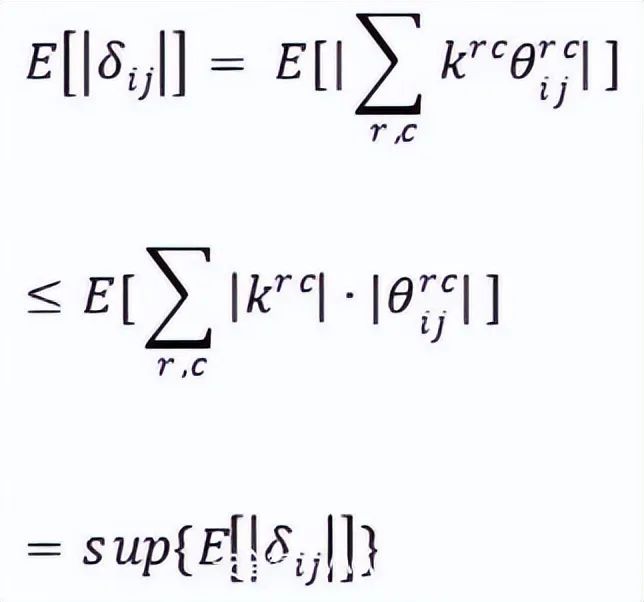


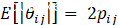

特征图的汇合操作
根据已有研究知识,已知概率特征和残差特征图的汇合方式主要有两种。第一种方式是使用残差特征图乘以经过一定缩放后的概率特征图,第二种方式将残差特征图与概率特征图直接相加。第二个方式更有利于网络的汇聚,其提取出的残差特征可表征更丰富的隐写特征,因此应用第二种方式作为概率图的汇合方式,如下公式所示,其中,R表示残差特征图,R后面的那个符号表示概率特征图。
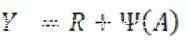
为了更好地查看选择通道的性能,本文在自适应隐写算法WOW的三个嵌入率0.2、0.4和1.0下查看应用选择通道和未应用选择通道的隐写分析算法准确率,结果如下表所示。

根据实验结果可知,应用选择通道之后,隐写分析算法的准确率提升了3%-8%,说明选择通道技术很好地放大了表征隐写信息的残差特征,增强了算法的隐写识别性能。
特征提取层
经过预处理层后,本文算法的网络生成了一个特征图,它包含原始的残差特征图和概率特征图。为了更长远地获取到隐写特征信息,并应用它做更好的隐写检测分类工作,在特征提取层中,本文应用了五个卷积层来从特征图中提取隐写信息。其中,在前个卷积网络层中,应用了16个大小为3×3的卷积核,在最后一个卷积层中应用了16个大小为5×5的卷积核,同时在每个卷积层后面均添加了一个平均池化操作,以适当地减少网络的计算量。
分类层
在经过前述网络层之后,本隐写分析网络获取到了充足的隐写特征信息,这些特征信息主要包含两部分,第一部分是直接从图像中提取出的残差特征信息,第二部分是通过选择通道获取到的隐写信息嵌入的概率信息。在分类层中,根据这些特征信息计算当前图像为隐写图像或原始图像的可能性。为了很好地实现上述的功能,本文在分类层中添加了两部分组件:全连接层和Dropout,将提取出的隐写特征作为输入,并输出分类的结果。
一般来说,卷积神经网络中绝大部分的参数集中在全连接层中,这些参数能降低网络的训练效率,导致网络过拟合现象的出现。为了降低参数的规模,本文在特征提取层中,设置平均池化的步长为2,以此减小输出特征图的尺寸,并且设置卷积核的数量为16。同时,在全连接层中,本文仅仅添加了两个全连接层,以最大限度地降低了网络的参数规模。
此外,为了减少过拟合现象的出现,本文在两个全连接层后添加了Dropout的操作,设置其参数为0.5,这样即将全连接层输出的神经元以0.5的概率激活,从而加强了网络的稀疏性,增强了网络的泛化能力。
模拟与分析
实验环境
本文的数据集来自于Bossbase,它包含1万张大小为512×512的灰度原始图像,考虑到GPU有限的计算能力,在本文中,缩放原始图像的大小为256×256。预先生成这些图像对应于不同自适应隐写算法的隐写信息嵌入概率特征图。在实验中,本文随机地将1万对隐写图和原始图划分为8000对、1000对和1000对图像,它们分别属于训练集、验证集和测试集。对于卷积神经网络,应用Xavier初始化器来初始化特征提取层中的卷积核,对应的偏置值被初始化为零,应用Adadelta梯度下降算法来优化网络的训练过程,每批次输入的样本量为100,其中包含50张原始图像和50张隐写图像。
结果分析
将本文的隐写分析模型与传统的空域富模型SRM、基于深度学习的隐写分析模型GNCNN作比较,三种隐写算法的嵌入率均为0.4,隐写检测准确率如下图所示。
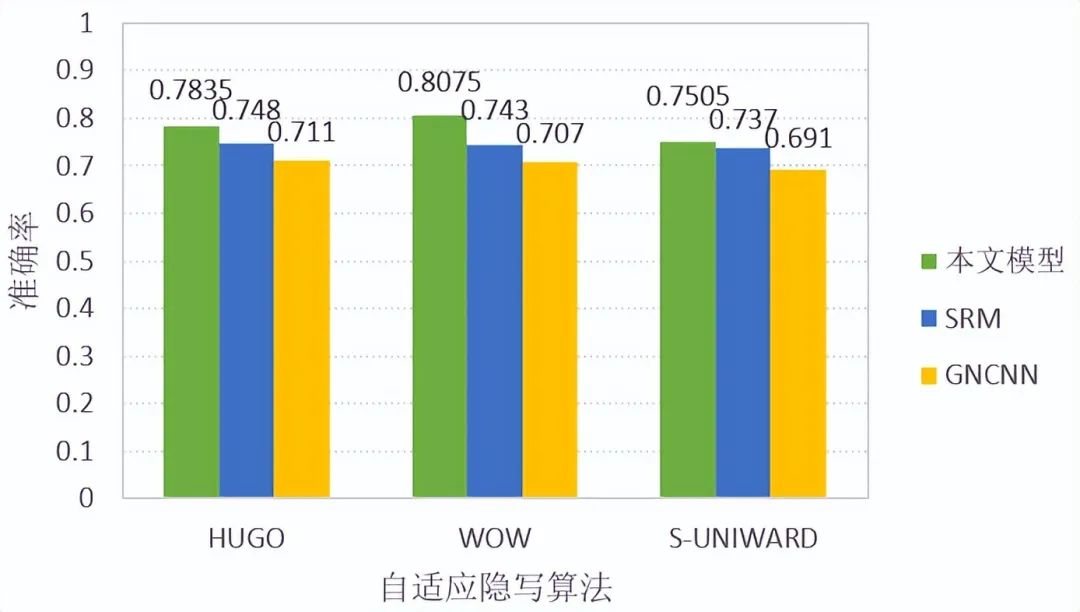
根据实验结果可知,在HUGO、WOW、S-UNIWARD这三种自适应隐写算法下,本文模型的隐写分析准确率均远远高于基于深度学习的影响分析模型GNCNN,略高于传统的空域富模型SRM。且在WOW隐写算法下本文模型的性能最佳,其隐写检测准确率高于SRM约6%,但在S-UNIWARD隐写算法下仅高于SRM约2%。
