一.摘要
深度学习已在恶意软件分类任务中表现出良好的结果。然而:
- 人工分析效率低:对于未知恶意软件的binary,分析人员仍要花大量时间来利用静态分析工具逆向整个binary,从而识别关键的恶意行为
- 监督学习开销大:尽管机器学习可用来帮助识别二进制的重要部分,但由于获取足够大的标记数据集开销很大,因此监督学习方法是不切实际的
为了提高静态(或手动)逆向工程的生产力,我们提出了DeepReflect:一种用于定位(localize)和识别(identify)恶意二进制文件中恶意软件组件的工具。
- 为了定位恶意软件组件,我们以一种新型(novel)方式,即首先使用一个无监督的深度神经网络l来定位恶意软件中恶意组件(函数)的位置
- 其次,通过半监督聚类分析对恶意组件进行分类,根据恶意行为分类确定恶意函数的行为
- ,其中分析人员在他们的日常工作流程中逐步提供标签
- 该工具是实用的,因为它不需要数据标记(require no data labeling)来训练定位模型,也不需要最小/非侵入性标记来增量地训练分类器
我们通过5个恶意软件分析人员对超过26k个恶意软件样本进行评估。实验发现,DeepReflect让每个分析人员需要逆向工程的函数数量平均减少了85%。本文方法还可以检测到80%的恶意软件组件,而当使用基于签名的工具CAPA时,该值仅为43%。
- 企业界对比:CAPA
此外,DeepReflect提出的自动编码器(autoencoder)比Shap(一种人工智能解释工具)表现得更好。这一点很重要,因为Shap是一种最先进(state-of-the-art)的方法,需要一个标记的数据集,而我们的自动编码器不需要。
- 学术界对比:Shap

二.引言
由于每篇论文的引言都非常重要,因此该部分作者会全文翻译,后续章节则介绍重点内容。
1.背景引出挑战
静态逆向工程恶意软件可能是一个手动且乏味的过程。公司每周可以收到多达 500 万个PE样本。虽然大多数组织提前对这些样本进行分类(triage),以减少要分析的恶意软件数量(即,检查 VirusTotal来获取反病毒 (AV) 引擎结果、在受控沙箱中执行样本、提取静态和动态签名等) ,但最终仍然需要静态逆向工程的恶意软件样本。这是因为总会有新的恶意软件样本,没有被反病毒公司分析过,或者缺乏签名来识别这些新样本。最终,该样本有可能会拒绝在分析人员的动态沙箱(sandbox)中执行。
- Reverse engineering malware statically can be a manual and tedious process.
- checking VirusTotal [12] for antivirus (AV) engine results, executing the sample in a controlled sandbox, extracting static and dynamic signatures, etc.
当前的解决方案以为恶意软件样本创建签名、分类和聚类的形式存在。然而,这些解决方案只能预测样本的类别(例如,良性与恶意,或特定的恶意软件家族)。他们无法定位或解释恶意软件样本本身内部的行为(定位恶意函数位置、解释恶意函数行为),而分析师需要执行(perform)这些行为来生成报告并改进他们公司的恶意软件检测产品。事实上,由于工作量过大,该领域已呈现了倦怠。
- Current solutions exist in the form of creating signatures [33,45,72], classification [14,30,36,41], and clustering [18,25,52] for malware samples.
为了确定他们的需求,我们咨询了四名逆向工程恶意软件分析师(一名来自AV公司,三名来自政府部门)。本文发现,如果恶意软件分析师有一个工具可以:
- (1) 识别恶意软件中恶意函数的位置
- identify where malicious functionalities are in a malware
- (2) 标记这些恶意函数的行为
- label those functionalities
那么,他们的工作将更有效率。开发这样一种工具的挑战在于:
- (1) 需要能够区分什么是良性的(benign),什么是恶意的(malicious)
- (2) 理解识别出的恶意行为的语义
对于第一个挑战,区分良性和恶意是困难的,因为恶意软件和良性软件的行为通常在高层次上重叠。对于第二个挑战,自动标记和验证这些行为是很困难的,因为没有单独标记的恶意软件函数的数据集(与使用反病毒标签的开放数据集的恶意软件检测和分类系统不同)。
2.如何解决挑战
为了解决这些挑战,我们开发了DEEPREFLECT,它使用:
- (1) 一个无监督的深度学习模型来定位二进制中的恶意函数
- (2) 一个半监督聚类模型,它使用从分析人员的日常工作流程中获得的少量标签对识别的函数进行分类
为了定位(locate)二进制文件中的恶意软件组件,我们使用自动编码器(autoencoder,AE)。AE是一种基于神经网络的机器学习模型,其任务是将其输入重构为输出(编码还原)。由于网络内层存在压缩,AE被迫学习训练分布中的关键概念。我们的直觉是,如果在良性二进制文件上训练AE,它将很难重建恶意二进制文件(即我们没有训练它的样本)。自然地,AE将无法重建(reconstruct)包含恶意行为的二进制数据区域(在良性样本中是不可见或罕见的)。因此(Thus),重构错误可以用来识别恶意软件中的恶意组件。此外,由于AE是以无监督的方式训练的,我们不需要数百万标记的样本,公司可以利用自己的恶意软件二进制数据集。
该约束读者需要理解,本文使用恶意样本进行学习和识别。
为了对定位的恶意软件组件进行分类,我们:
- (1) 对恶意软件样本中所有已识别的函数进行聚类
- (2) 使用分析人员在日常工作流程中所做的注释(即少量人工分析的函数行为标签)来标记聚类结果
这种方法是半监督的,因为每个类簇(cluster)只需要少数函数的行为标签(如三个)即可将大多数标签分配给整个集群。随着时间推移,我们可以将AE识别的函数映射到聚类模型来预测函数的类别(如,C&C、特权升级等),即认为函数和最接近的类簇有相同的行为标签。这反过来又节省了分析人员的时间,因为他们不必一次又一次地对相同的代码进行逆向工程。
注意,无监督 AE 为恶意软件分析人员提供了即时实用程序,无需训练或使用半监督聚类模型。这是因为它:
- (1) 通过对最相关的函数进行排序(重构误差)来吸引分析师的注意力
- (2) 过滤掉可能需要花费分析师数小时或数天时间来解释的函数
DEEPREFLECT根据我们是为恶意软件分析人员的反馈进行设计和修改的,并评估其有效性和实用性。
我们评估了DEEPREFLECT的性能,包括五个工作:
- (1) 识别恶意软件中的恶意活动
- (2) 聚类相关的恶意软件组件
- (3) 将分析人员的注意力集中在重要事情上
- (4) 揭示不同恶意软件家族之间的共享行为
- (5) 处理涉及混淆的对抗性攻击
3.创新(Contribution)
我们的贡献如下:
- 提出了一个新颖的工具,它可以帮助恶意软件分析师:(1) 在静态恶意软件样本中自动定位和识别恶意行为,(2) 洞察分析不同恶意软件家族之间的功能关系。
- 提出一种在静态分析中使用机器学习的新颖实用方法:(1) AE训练是在一种无监督方式下进行的,无需为系统标注任何样本,就可以产生突出显示恶意软件组件的实用程序,(2) 分类是以半监督方式完成,具有最小的干预:分析人员的常规工作流的注释用作标签,群集中的大多数标签用于对相关的恶意软件组件进行分类。
- 本文提出了一种解释框架(如我们提出的 AE 或 SHAP)定位恶意软件重要部分的方法,该方法可以映射回原始二进制或控制流图的特征。
三.Scope & Overview
1.Motivation
图1展示了一个典型的恶意软件分析师Molly的工作流程。当给定一个恶意软件样本,Molly的任务是了解该样本在做什么,以便她写一份技术报告并改进公司的检测系统,从而在未来识别该类样本。
- (1) 首先查询VT(virtotul)和其他组织,以确定他们以前是否见过这个特定的样本,然而并没有
- (2) 在一个自定义的沙箱中执行样本以了解其动态行为,然而没有显示任何恶意行为或拒绝执行;运行一些内部工具,诱使恶意软件执行其隐藏的行为,但仍无效时
- (3) 尝试脱壳(unpacking)和静态逆向分析恶意样本,以了解其潜在行为
- (4) 在反汇编程序(IDA Pro 或 BinaryNinja)中打开脱壳后的样本,被数千个函数淹没,接着运行各种静态签名检测工具来识别恶意软件的某些特定恶意组件,但仍无效
- (5) 逐个查看每个函数(可能通过 API 调用和字符串过滤)以尝试了解它们的行为
- (6) 在分析样本的行为后,撰写分析报告(包含基本信息、IOC、静态签名等)
然而,当新的样本出现时,Molly需要重复同样的任务。由于这种重复的体力劳动,这项工作对Molly来说变得单调乏味和耗时。

DEEPREFLECT旨在减轻恶意分析师的分析工作,能逆向一个未知的恶意软件样本,从而减轻他们繁重的任务,并为相似的函数标注行为标签。
2.Proposed Solution
我们提出了DEEPREFLECT,该工具能:
- (1) 定位恶意软件binary中的恶意函数
- locates malicious functions within a malware binary
- (2) 描述这些函数的行为
- describes the behaviors of those functions
虽然分析人员可能首先尝试通过搜索特定的字符串和API调用来静态地识别行为,但这些行为很容易被分析人员混淆或隐藏( obfuscated or hidden)。DEEPREFLECT没有做出这样的假设,并试图通过控制流图(control-flow graph,CFG)特性和API调用(API calls)的组合来识别这些相同的行为。
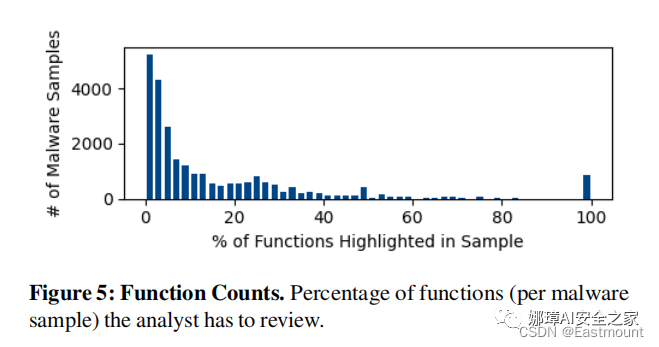
DEEPREFLECT通过学习正常情况下良性的二进制函数来工作。因此,任何异常都表明这些函数不会出现在良性二进制文件中,而可能被用于恶意行为中。这些异常函数更可能是恶意函数,分析师可以只分析它们,从而缩小工作范围。如图5所示,DEEPREFLECT将分析师必须分析的函数数量平均减少了 85%。此外,实验表明我们的方法优于旨在实现相同目标的基于签名的技术。
3.Research Goals
本文有四个主要目标:
- G1:准确地识别恶意软件样本中的恶意活动
- G2:帮助分析人员在静态分析恶意软件样本时集中注意力
- G3:处理新的(不可见的)恶意软件家族
- G4:深入了解恶意软件家族的关系和趋势
四.模型设计
1.总体框架
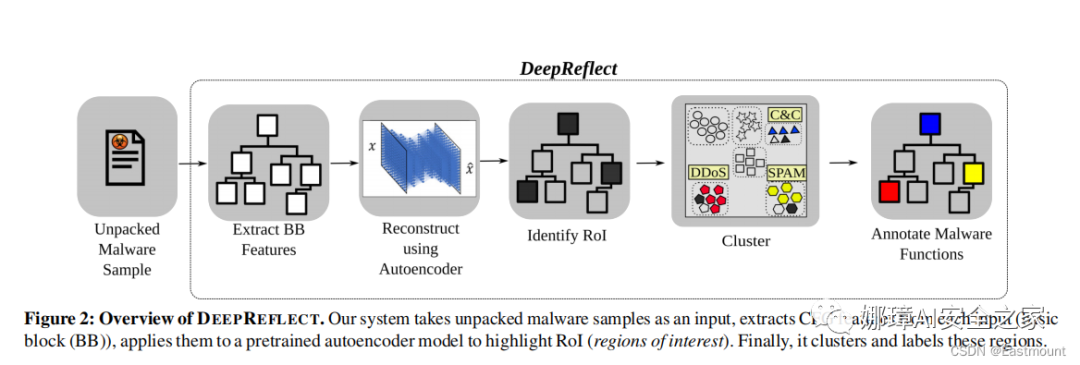
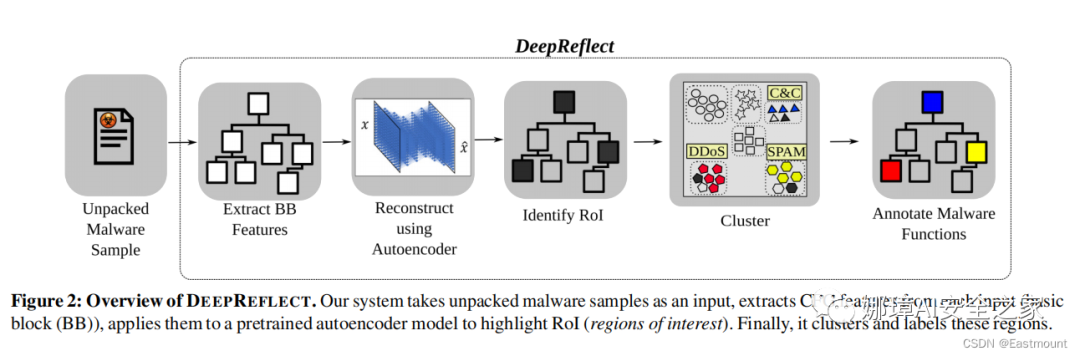
DEEPREFLECT的目标是识别恶意软件二进制中的恶意函数。在实践中,它通过定位异常基本块(感兴趣区域 regions of interest,RoI)来识别可能是恶意的函数。然后,分析人员必须确定这些函数是恶意行为还是良性行为。DEEPREFLECT有两个主要步骤,如图2所示:
- RoI检测(RoI detection):通过AE(AutoEncoder)来执行的
- RoI注释(RoI annotation):通过对每个函数的所有RoI聚类,并将标记聚类结果来执行注释。注意,一个函数可能有多个ROI,用每个函数自己的ROI的均值表示该函数,然后对函数聚类
(1) 术语 Terminology
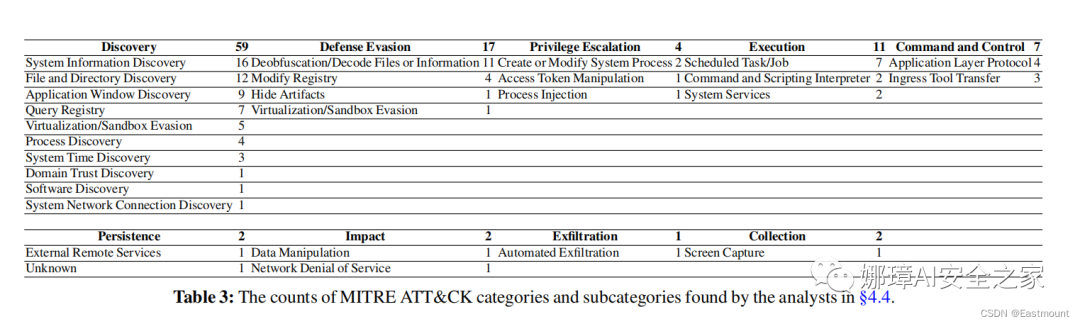
首先定义恶意行为(malicious behaviors)的含义。我们根据识别恶意软件源代码的核心组件(例如,拒绝服务功能、垃圾邮件功能、键盘记录器功能、命令和控制C&C功能、利用远程服务等)来生成真实情况(ground-truth)。通过MITRE ATT&CK框架描述,如表3所示。
然而,当静态逆向工程评估恶意软件二进制文件时(即在野恶意软件二进制 in-the-wild malware binaries),我们有时无法肯定地将观察到的低级函数归因于更高级别的描述。
例如,恶意软件可能会因为许多不同的原因修改注册表项,但有时确定哪个注册表项因什么原因而被修改是很困难的,因此只能粗略地标记为“防御逃避:修改注册表(Defense Evasion: Modify Registry)”。即使是像CAPA这样的现代工具,也能识别出这些类型的模糊标签。因此,在我们的评估中,我们将“恶意行为”表示为可由MITRE ATT&CK框架描述的函数。
(2) RoI Detection
检测的目标是自动识别恶意软件二进制文件中的恶意区域。例如,我们希望检测C&C逻辑的位置,而不是检测该逻辑的特定组件(例如,网络API调用connect()、send() 和 recv())。RoI检测的优点是分析人员可以快速定位启动和操作恶意行为的特定代码区域。先前的工作只关注于创建临时签名,简单地将二进制文件标识为恶意软件或仅基于API调用的某些函数。这对于分析人员扩大他们的工作特别有用(即不仅仅依赖手动逆向工程和领域专业知识)。
(3) RoI Annotation
注释的目标是自动标记包含RoI的函数的行为,即识别恶意函数在做什么。由于分析人员为标记集群所执行的初始工作是一个长尾分布。也就是说,只需要前期做比较重要的工作,随着时间推移,工作量会减少。这个过程的优点很简单:它为分析人员提供了一种自动生成未知样本的报告及见解的方法。例如,如果恶意软件示例的变体包含与之前的恶意软件示例相似的逻辑(但对于分析人员来说看起来不同以至于不熟悉),我们的工具为他们提供了一种更快实现这一点的方法。
2.RoI Detection
首先介绍了AutoEncode(AE)神经网络。此外,先前的工作已经证明,当自动编码器在良性分布上进行训练时,AE可以检测到恶意(异常)行为。我们的假设是,与良性二进制文件相比,恶意软件二进制文件将包含相似但独特的功能。
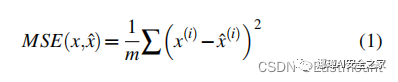
当使用大量良性样本训练AE后,给定一个随机的样本,可以利用公式(2)计算,超过MSE的即认为是恶意区域,突出显示ROI异常基本块。与先前识别整个样本为恶意区域的工作相比,我们识别了每个样本中的恶意区域。具体而言,我们计算的 localized MSE 定义如下:
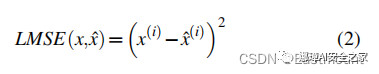
We denote the mapped set of RoIs identified in sample x as the set
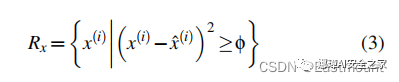
(1) Features
我们特征(c)的灵感来自于先前工作中发现的特征,即属性控制流图(attributed control flow graph,ACFG)特征[23,75]。在这些工作中,ACFG特征被选择来执行二进制相似性,因为它们假设这些特征(由结构和数字CFG特征组成)将在多个平台和编译器上是一致的。
- Genius
- Gemini
为了在二进制样本中定位恶意行为的位置,编码使用的特征必须一对一的映射回原样本。因此,作者将每个二进制文件表示为一个 m×c 的矩阵,该矩阵使用c个静态特征捕获前m个基本块以总结样本的behavior。m设置为20k个基本块,是因为95%的数据集样本具有20k或者更少的基本块, c设置为18个特征。
Our features consist of counts of instruction types within each basic block (a more detailed form of those extracted for ACFG features), structural features of the CFG, and categories of API calls (which have been used to summarize malware program behaviors).
(a) Structural Characteristics
结构特征2个,每个基本块的后代(offspring)数量和betweenness score,可以描述不同功能的控制流结构,比如网络通信(connect, send, recv)或文件加密(findfile, open, read, encrypt, write, close)。如图6所示。

(b) Arithmetic Instructions
算术指令3个,每个基本块基本数学、逻辑运算、位移指令的数量(“basic math”, “logic operation”, and “bit shifting”)。这些算术指令特征可以用来表示如何对更高层次的行为执行数学运算,以及数字如何与函数交互。例如,加密函数可能包含大量的xor指令,混淆函数可能包含逻辑和位移操作的组合等。

(c) Transfer Instructions转移指令3个,每个基本块内堆栈操作,寄存器操作和端口操作的数量(“stack operation”, “register operation”, and “port operation”)。这些底层特征可描述更高级别函数的传输操作,比如函数的参数和返回值是如何与函数内其余数据交互的,从而描述更复杂的逻辑和数据操作。例如去混淆、解密函数可能设计更多move-related指令,C&C逻辑设计更多堆栈相关指令。

(d) API Call CategoriesAPI类别10个, 包括"filesystem", “registry”, “network”, “DLL”,“object”, “process”, “service”, “synchronization”, “system information”, and "time"相关的API调用数量。调用不同类型API可执行不同类型功能,直接的表示了高层的函数行为,是很关键的特征。

本文工作API特征的选择受到先前恶意软件检测工作[18]的启发。本文使用的ACFG特征比Genius和Gemini更细致。本文没有用字符串特征,因为容易被混淆、隐藏。
(2) Model
Autoencoder使用U-Net模型,U-Net的优点是其在编码器和解码器之间有跳过连接(skip connections),对样本x可以跳过某些特征的压缩以在重构的x’中保持更高的保真度。
首先收集大量的良性样本,对每个binary抽取上述18个静态特征用于表示该binary。设有用feature表示的样本x,AE重构后得到x’,训练的目标是最小化重构损失,即输入x和输出x’之间的损失。
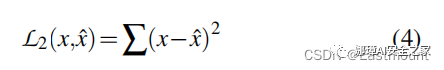
RoI Detection会在m个基本块中检测出一些异常基本块。这些基本块分别属于不同的函数,使用例如BinaryNinja的工具就可以确定ROI属于哪些函数,即认为这些函数可能是恶意函数,也就完成了恶意函数定位的任务。后续RoI Annotation就是对这些函数聚类,完成恶意函数行为标记(分类)的任务。
3.RoI Annotation
给定一个新样本x,我们希望识别其每个函数的行为(类别),并将其报告给Molly。由于标记所有的函数都是不实用的,所以我们只注释了少量的函数,并使用聚类分析来传播结果。
(1) Clustering Features
假设一组脱壳恶意软件,按上述特征提取方式(18种特征)得到每个binary的特征表示,其中一个binary为x。

(2) Clustering Model
使用PCA将特征数从18降维至5,然后使用HDBSCAN算法对5维特征聚类。

4.Deployment
接下来,我们将描述如何部署和使用它。
(1) Initialization
- 首先对良性和恶意binaries脱壳
- 提取binary静态特征,形成20×18的矩阵
- 用良性样本训练AutoEncoder
- 使用训练好的AE从恶意样本中提取ROIs,即恶意基本块位置
- 计算恶意二进制中恶意函数的行为表示,加入聚类的训练集D
- PCA降维并聚类生成C
人工分析恶意软件手动打标,这些label注释到聚类训练集中,从而评估实验结果。换句话说,每个cluster只需要其中几个函数的label,就可确定整个cluster的label,即确定整个cluster中函数的恶意行为。
(2) Execution
当Molly收到一个新的样本x,DeepReflect会自动定位恶意函数并标注恶意行为。
- 对样本x执行脱壳(unpack)
- 通过AutoEncoder获取ROIs
- 使用BinaryNinja以及ROIs确定恶意函数集合,然后计算恶意函数的行为表示
- PCA模型降维
- 计算每个恶意函数最相近的集群,通过计算和聚类中心的距离实现
- 分配大数据集群注释给函数
接下来,Molly分析highlighted functions,从而实现:
- obtains a better perspective on what the malware is doing
- annotates any function labeled “unknown” with the corresponding MITRE category (dynamically updating D)
- observe shared relationships between other malware samples and families by their shared clusters(共享关系,分析恶意软件家族的相关性)
五.实验评估
1.Dataset
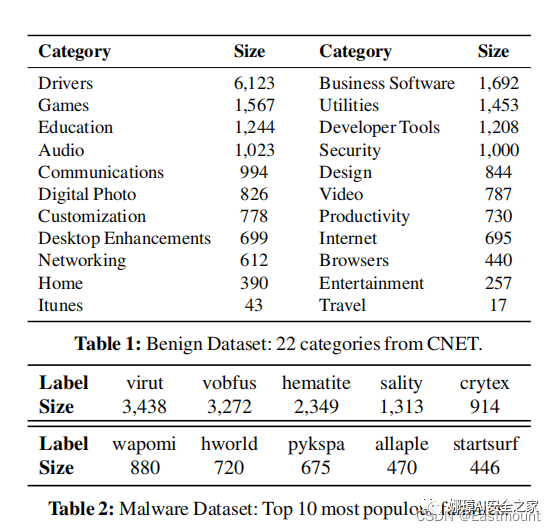
根据CNET爬取PE文件,然后经过脱壳、过滤得到23307个良性样本。根据VirusTotal ,脱壳、过滤,在沙箱中执行获取家族标签。得到36396个恶意样本,4407个家族。
特征18个:

2.Evaluation 1 – Reliability
为了评估DeepReflect自动编码器的定位能力,我们与一般方法和领域特定方法进行比较:
- SHAP(a classification model explanation tool)
- Scott M. Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems, pages 4765–4774, 2017.
- CAPA (a signature-based tool by FireEye for identifying malicious behaviors within binaries)
- https://github.com/fireeye/capa
- FunctionSimSearch(a function similarity tool by Google)
- https://github.com/googleprojectzero/functionsimsearch.
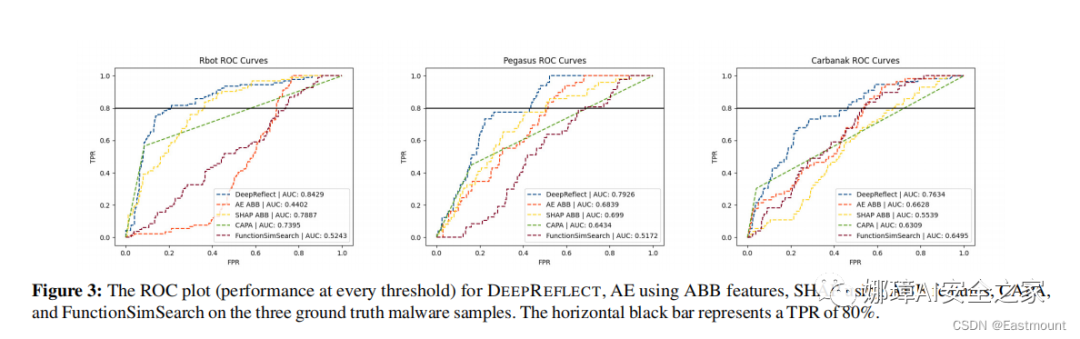
静态的分析了三个恶意软件的源代码(rbot, pegasus, carbanak),分析了其中恶意组件的位置。结果如Figure 3,横线为80% True Positive Rate。
3.Evaluation 2 – Cohesiveness
测试DeepReflect聚类的凝聚性,对恶意函数行为分类的能力。生成了22469个类簇,最大的簇包含6321个函数,最小的簇包含5个,如图10所示。在图10中,我们展示了类簇大小上的分布。图中显示,存在一个长尾分布(这在基于密度的聚类中很常见),其中最多的前10个集群占函数的5%。

在聚类质量分析中,89.7%的分析人员手工聚类功能与DeepReflect创建的功能相匹配。
此外,聚类质量存在问题,相同功能却被聚集在不同类簇中,分析了3个案例,主要因为小地方存在差异,聚类算法过于敏感。
4.Evaluation 3 – Focus
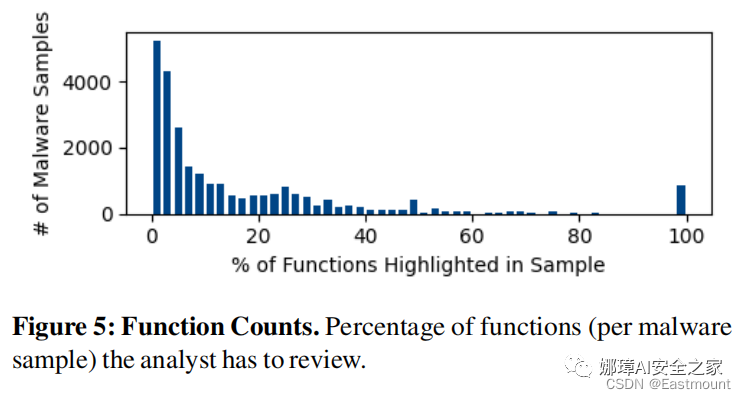
DeepReflect缩小需要人工分析的函数的范围的能力。如图5所示,很多样本需要分析的函数数量降低了90%以上。平均降低85%。
5.Evaluation 4 – Insight
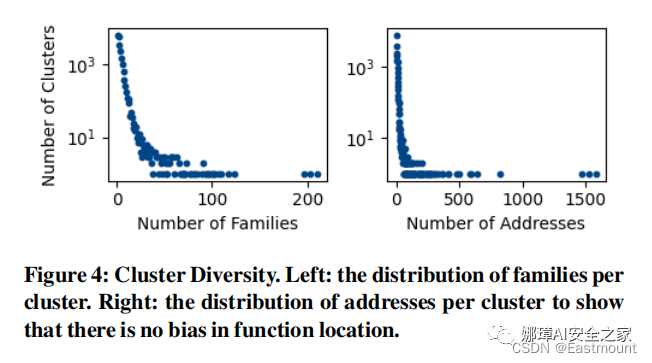
为了评估DeepReflect是否为恶意软件家族间的关系及其行为提供了有意义的见解,我们探索了集群多样性。图4的左侧绘制了C中每个类簇中不同家族的数量。由图可知,在家族之间有许多共享的恶意软件技术和变体,部分恶意软件家族间分享了相同的函数,新的恶意软件家族的样本也可以被成功的分类。
6.Evaluation 5 – Robustness
使用LLVM混淆,继续测试模型的鲁棒性;同时使用对抗样本攻击,将包含本文使用的特征的良性样本的代码插入到恶意样本中,但均未对结果产生显著影响。
六.限制和相关工作
Every system has weaknesses and ours is no exception.
- Adversarial Attacks.
- Training Data Quality.
- Human Error.
Related Works
- Deep Learning and Malware
- Autoencoders and Security
七.Conclusion
结论直接给出原文,同时再让我们回顾一遍框架图。

八.个人感受
写到这里,这篇文章就分享结束了,再次感谢论文作者及引文的老师们。接下来是作者的感受,由于是在线论文读书笔记,仅代表个人观点,写得不好的地方,还请各位老师和博友批评指正,感恩遇见,读博路漫漫,一起加油~
 FreeBuf
FreeBuf
 Andrew
Andrew
 安全牛
安全牛
 Anna艳娜
Anna艳娜
 Anna艳娜
Anna艳娜
 ManageEngine卓豪
ManageEngine卓豪
 安全侠
安全侠
 FreeBuf
FreeBuf
 安全牛
安全牛
 Andrew
Andrew
 Anna艳娜
Anna艳娜
 Anna艳娜
Anna艳娜
