机器学习在数据安全感知系统的应用
我们生活在一个信息泛滥的世界,越来越难去跟踪信息,或者手动为他人策划信息;幸运的是,现代数据科学可以对大量的信息进行分类,并将与我们相关的信息呈现出来。
机器学习算法依靠在数据中观察到的用户知识和模式,对我们可能喜欢或感兴趣的内容做出推断和建议。随着机器学习技术越来越容易被开发人员使用,有一股力量促使公司利用这些算法来改进他们的产品和用户的体验。
在全息网御研发实践中,我们以安全视角深入分析流动数据在各个行业的业务共性,抽象出以流动数据为核心的OnFire数据安全风险感知系统平台,通过结合运用AI智能机器学习,实时构建“ 用户-设备-应用-数据 ”四个维度的关联分析,实现了为流动数据建立评估监测、预警/告警、溯源审计的联动机制提供依据,从而感知数据安全风险,并形成可视、可控、可追溯的数字空间安全态势感知和防护体系。
用户和实体行为的分析方法(User and Entity Behavior Analysis, UEBA)是基于实体行为的网络风险分析,是利用统计和机器学习等算法的自适应分析,是基于大数据安全分析的网络异常行为检测与安全态势感知 。以下我们从算法和架构两个方面描述这些算法在OnFire系统中的应用。
一、概述
OnFire系统是由三部分组成:网络流量采集系统(HoloFlow),实体行为分析系统(HoloML)和管理系统(HoloVision)。网络流量采集器会从网络关键设备节点,通常从汇聚交换机处,接受并处理网络原始流量,生成网络中设备、应用、数据(文件和网页)以及用户的网络行为日志,并保存于数据仓库。
分析平台将这些日志映射为四类实体行为,分别是:用户实体、设备实体、应用实体和数据实体。然后根据实体间的行为逻辑关系、时序关系以及地理位置关系等,生成动态关联的网络全息图。同时,利用数理统计、机器学习等算法为每个实体画像构建正常行为基线。最后再通过实体的正常行为画像识别比对出异常行为,并提醒管理员及时对异常行为追踪溯源。
OnFire系统的层级结构共分为5层,如图-1:
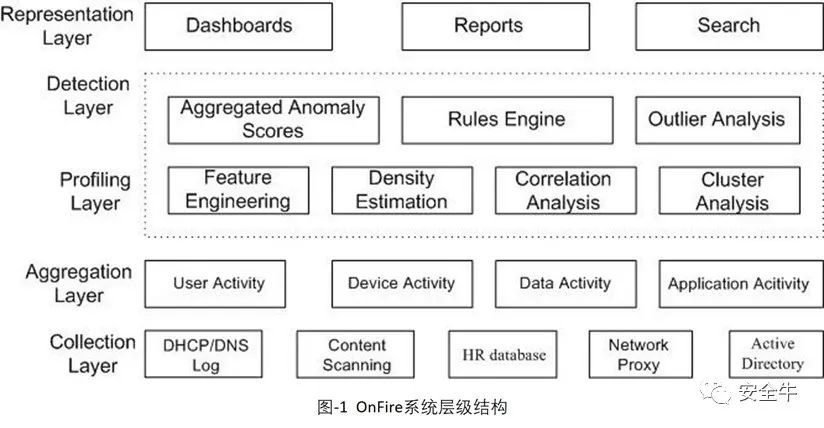
日志收集层:收集多种网络协议数据,支持第三方日志信息的导入。
汇聚层:完成数据清洗,数据转换,数据聚合工作,并提取用户、设备、应用和数据实体信息。
画像层:根据实体的历史信息,利用数理统计、机器学习等算法为每个实体画像,建立正常行为基线,并将其可视化展现。
异常行为检测层:计算实体每个行为与正常行为画像的差别,从而识别异常行为,并将其可视化展示。
展示层:为安全系统分析员提供友好、可用的人机接口,便于事后的追踪溯源。
二、实体行为分析
1. 行为画像
在画像层中,我们按用户、数据、应用和设备四个维度分析和挖掘实体行为以掌握实体间的相互关系,识别出正常行为模式并建立实体间的正常行为基线,运用到的是无监督的机器学习算法。在随后的检测层中,系统将计算正常行为基线与当前行为之间的差异,从而判断此行为是否异常。
通常,特征工程(feature engineering)会从实体行为中提取特征,将这些特征作为学习算法的输入来识别实体行为的模式。平台使用多种算法来识别正常行为的模式,下面简要介绍两种:
(1)核密度估算
核密度估计(Kernel Density Estimation)为实体行为特征构建密度的估算函数。在我们的UEBA解决方案中,我们使用非参数密度估计算法(nonparametric estimation),因为这不需要那么严格的假设条件,而核密度估算是常用方法之一。
在计算数据密度分布估算函数时,算法使用高斯核来创建数据的直方图,而不是用矩形对数据进行分箱。也就是说在每个分箱的中心绘制高斯分布,这种方法可以平滑直方图,并得到对特征空间中每个点的数据密度的连续估计。对于异常检测通常方法是估算每个数据点的密度,并将密度最小点称之为异常。
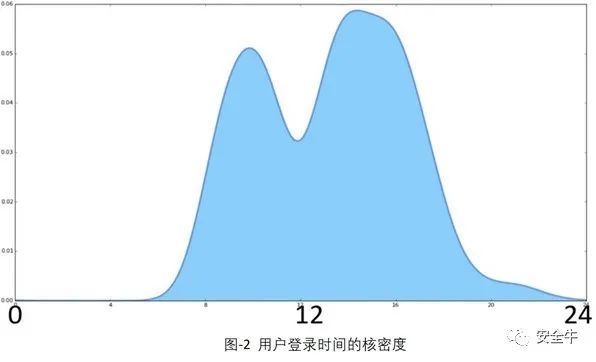
如图-2显示一天中的登录行为:X轴是时间,y轴是登录概率,从该图可以看出高密度时段为6到20。如果有人在0到6之间登录,则表现为行为异常。
(2)特征工程
在OnFire系统中,大多数活动是时间依赖性的。对于时序数据,我们从三个方向提取数据特征:时间、统计和频谱。时间类特征包括:不同的时间粒度、自相关性、离峰值距离、正负转向点等。统计类特征包括:移动均值、标准差、趋势量度、季节性、周期性、序列相关性、偏度、峰度和自相似性等。频谱类特征包括:FFT平均系数、 最大频率、中位数频率、频谱中心以及频谱延展度等。
2. 行为异常分析
OnFire 系统的行为异常分析包括两类:基于静态规则以及基于统计和机器学习算法,下面将重点对系统使用的统计类算法和机器学习类算法进行介绍。
(1)统计类算法
统计类算法常用于一维或二维的数据,计算成本低,无需人工设置门限。适用于对重要指标的行为异常报警。比如用户的商业文件下载量,服务器文件下载量等。
指数加权移动平均法 (EWMA) 是一种常用统计方法,对用户和实体行为的某个维度数据,对其每天的聚合值分别给予不同的权数,按不同权数求得移动平均值,并以最后的移动平均值为基础,确定预测值的方法 。在EWMA中,各数值的加权系数随时间呈指数式递减,越靠近当前时刻的数值加权系数就越大。
EWMA 的表达式如下:
(1)〖EWMA〗_t= 〖λY〗_t+ (1-λ)EWMA_(t-1) for t=1,2,…,n
(2) s_ewma^2= λ/(2-λ) s^2
(3) UCL=〖EWMA〗_0+〖ks〗_ewma
其中:
〖EWMA〗_t :为t时的指数加权移动平均值。
Y_t:t时刻的实际数据。
k, λ 均为常量,其中0<λ≤1 决定历史数据对当前数据影响程度。
s:EWMA 统计值的方差
UCL:控制图的上限值
在实体行为分析系统中,指数加权移动平均法被用于单一维度的行为数据异常检测。比如用户每天下载文件量,根据工作性质不同,会有较平稳的基线和浮动区间。如果某天下载量远远大于UCL,则可视为下载文件行为异常。
(2)机器学习类算法
实体行为分析系统使用孤独森林算法(iForest)和聚类算法(Clustering Algorithm)实现用户组内外的行为异常分析。从而可以完成账号失陷分析和主机失陷分析功能。其基于的假设:同组用户的行为方式具有更高相似性。其实现原理:通过比较管理员提供的用户群组信息,并基于聚类分析模块依据用户行为数据计算出的群组信息,从而找出那些偏离群组的用户。
针对管理员输入个群组个数不同,聚类分析系统选择使用异常检测算法或者聚类算法。如果管理员输入一个群组,那么系统选择异常检测算法,计算离群用户。如果管理员输入两个或两个以上群组,系统将使用聚类算法对用户进行分组(群组数等于管理员输入的群组数);然后将计算得到的群组关系与管理员输入的群组关系进行对比,从而得到离群用户。
① 数据
用户网络行为信息以天为计算单位,根据全息的特殊能力,这里的用户包括了同一个用户使用的所有设备,所有应用及所有文件/数据的综合信息,而不是仅根据一个用户的某一个应用或用户的某一台设备所收集的信息。
A. 全局网络流量信息
a)用户访问网络的流量
b)用户访问应用个数
B.内部服务应用信息
a)用户访问某个应用服务的流量数
b)用户访问某个应用服务的网页数
C.文件类型及敏感类型信息
a)对于所有文件类型,用户使用的每种类型的文件个数
b)对于所有文件敏感类型,用户使用每种敏感类型的文件个数
②异常检测算法
当管理员选择一个群组或网段时,使用异常检测算法计算出离群行为,目前应用孤独森林算法。
孤独森林算法适用于发现分布稀疏且离密度高的群体较远的离群点。在特征空间里,分布稀疏的区域表示事件发生在该区域的概率很低,因而可以认为落在这些区域里的数据是异常的。
③聚类算法
当管理员选择N(N>=2)个的群组或网段时,根据用户行为数据使用聚类算法计算出N个新的群组。目前应用了K-Mean,分层聚类,混合高斯算法,系统默认选择K-Mean算法。
④群组关系比较算法
将聚类算法计算出的群组关系,与管理员选择的群组关系进行对比,从而得到哪些用户的行为偏离原来的群组关系。
三、系统架构
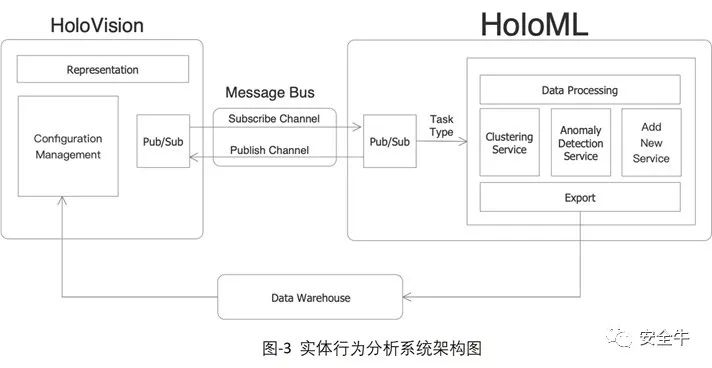
实体行为分析系统(HoloML系统)采用Event-Driven架构,如图-3所示。管理员通过HoloVision创建并管理分析任务。HoloML接受来自HoloVision的分析请求事件,启动智能分析任务,并将分析结果保存在数据仓库里。在通过Pub/Sub通道通知HoloVision任务执行情况,HoloVision读取数据仓库中的分析结果,并展现给管理员。
