IEEE TNNLS'22:基于图神经网络的多视角多任务学习
网络数据挖掘中的任务通常是多种多样的,主要的任务包括节点层面的分类以及边层面的预测。已有的方法通常单独讨论这两个任务,而忽视了这两个任务之间的相关性。事实上,节点分类和链接预测这两个任务存在着紧密的联系,而多任务学习可以利用任务之间的相关性使得不同任务联合优化之后的性能均得到提升。此外,网络中的信息通常是异质的,使得网络中存在多个不同的视图,不同的任务对于不同视图的信息的利用也存在差异。鉴于此,本文提出了一种多任务-多视图的表示学习方法,首次将多任务学习,多视图学习在图表示学习领域联合起来,并且取得了更好的性能。通过在多个现实世界的数据集上的实验证明了多任务学习以及多视图学习均可以提升每个任务的表现,并且可以极大地降低资源的开销。
该成果“Multi-Task Representation Learning with Multi-View Graph Convolutional Networks” 发表在IEEE Transactions on Neural Networks and Learning Systems (TNNLS) 2022上,TNNLS是中科院SCI一区期刊,CCF B类,该期刊每年出版12期,每年发表文章约300篇。

- 论文链接:
- https://ieeexplore.ieee.org/abstract/document/9274508
简介
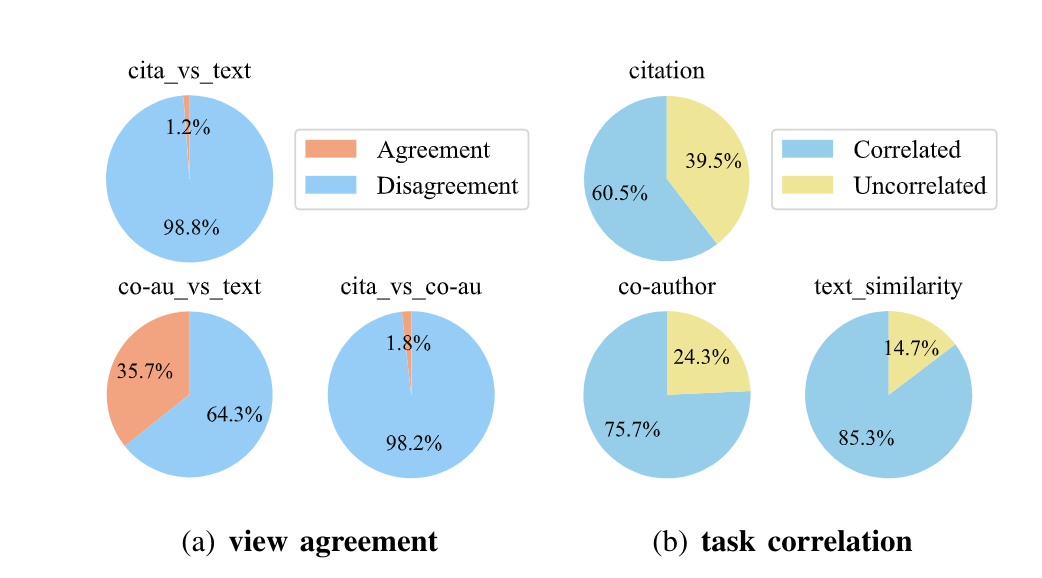
图表1 多视图与多任务的关系
网络分析是数据挖掘领域中广泛关注的热点,网络表示学习 (network representation learning) 尝试用低维稠密的矩阵最大化保留网络的原始信息,进而执行后续的网络分析任务。
链接预测与节点分类是网络表示学习中两个重要的后续任务,链接预测任务目的是预测网络中节点之间是否存在边,而节点分类则是判断节点所属的类别。传统的工作通常是将这两个任务分别进行,这不仅仅造成了一些重复工作的浪费也忽略了两个任务之间的关联。因为,从本质上看,链接预测与节点分类都可以归属为分类的问题,分别是针对边的层面以及节点的层面。因此,链接预测与节点分类这两个任务可以被同时优化。除此之外,目前已有的图卷积神经网络(GCN)无法利用网络中丰富的异质信息,因此对于不同的任务难以抽取到有用的信息来增强模型的学习能力。如图表1(a)所示,网络中存在的多个视图,通常两两之间是存在着agreement的信息,同时也可能存在disagreement的信息。因此,为了更好地学习网络的向量表示,考虑多个视图之间的复杂关系是很有必要的。除此之外,经过我们的分析,如图表1(b)所示,在不同的视图中,链接预测任务与节点分类任务之间存在着密切的联系,并且两者之间可以在底层共享信息,这使得网络表示学习中的多任务学习具备可行性。
为了采用图神经网络来抽取多个视图之间的信息以及对多个视图之间的关系进行建模,需要对现有的图神经网络进行改进。除此之外,目前的图神经网络是针对下游的特定任务进行优化,这往往带来了很低的效率以及难以利用广泛的标签信息进行监督学习。多任务学习是最近很热门的研究方向,这在图神经网络领域却并没有被深入的探究,这促使我们对网络中的多任务学习进行了研究。
有鉴于上述的问题,我们提出了一个基于多任务、多视角学习的图神经网络模型,首次将链接预测与节点分类任务同时进行,两者之间可以相互提升,通过实验验证表明本文提出的模型取得了比基线模型更好的效果。
模型设计
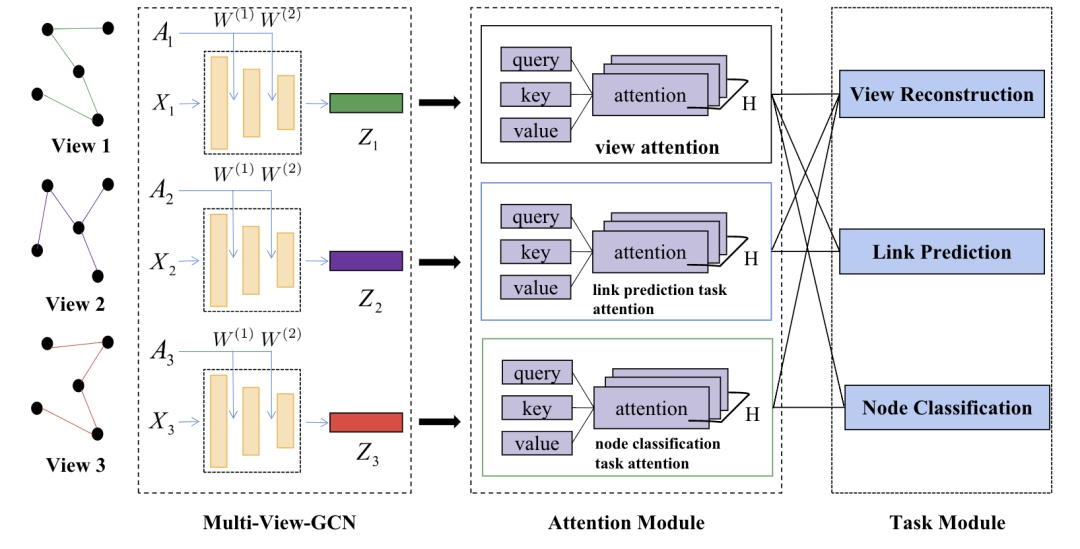
图表2 MT-MVGCN模型示意图
我们提出了一个名为MT-MVGCN的模型来同时处理图上的多任务、多视角学习问题,如图表2所示。首先我们通过一个Multi-View GCN来对网络的结构特性以及节点本身的特征进行抽取,接着为了考虑不同任务之间、不同视角之间、任务与视角之间复杂的关系,我们提出了View attention以及Task attention两种机制来学习不同视角之间的重要性,进而对多个视角的信息进行融合得到统一的节点向量表示。最后,节点的向量表示会作为特征用于节点分类任务以及链接预测任务。值得注意的是,我们还增加了一个View Construction任务作为辅助任务来增强模型的表达能力。
- Multi-View GCN模块
为了抽取多个视角的信息,我们选择GCN来学习网络的结构信息,同时为了兼顾可扩展性以及多视角之间的联系,我们设计了如下的传播规则:
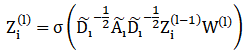
在每一层,相较于原始的GCN,模型的参数W是被多个视角共享的,这有以下三点优势:(1) 满足了模型的可扩展性,不会随着网络中视角数目的变化而受到影响,进而降低了模型的复杂度;(2) 多个视角之间可以通过W建立隐式的关联,进而实现相互协作;(3) 将多个视角投影到相同的低维空间中,进而为后续的多视角融合提供基础。
- Attention机制
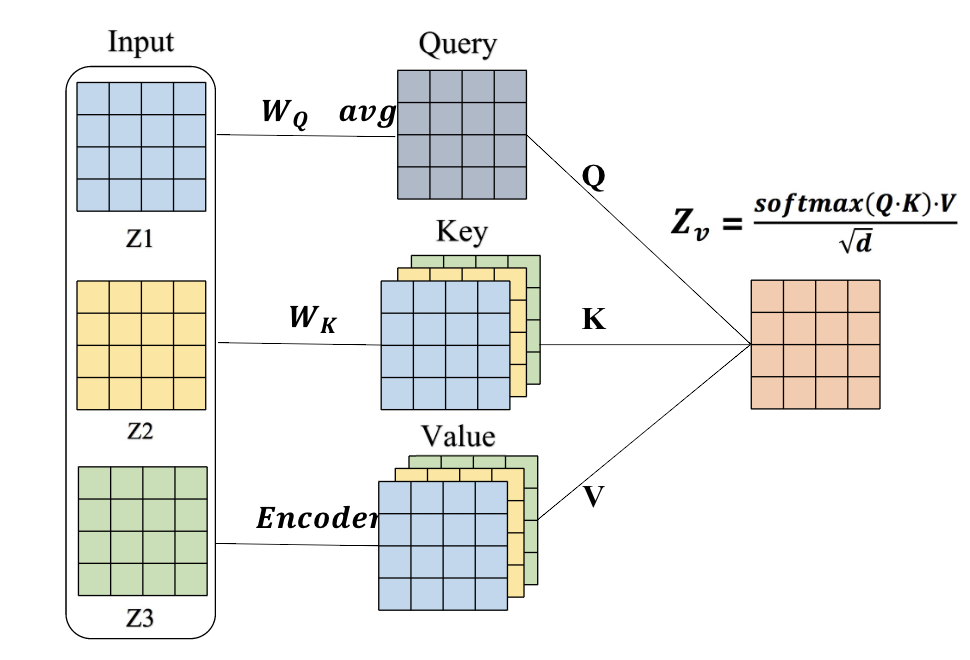
图表3 Attention机制示意图
注意力机制被认为可以学习到不同视角的重要性,因此我们利用注意力机制学习网络中各个视角的重要性,并以此为依据对多视角的信息进行融合。如图表3所示,我们首先考虑的是多个视角之间的关系,设计了一种类似于self-attention的模式,让多个视角共同投票决定每个视角的重要性,因此我们以3个视角为例,将attention机制抽象为query-key-value的模式,进而定义了如下的注意力机制:
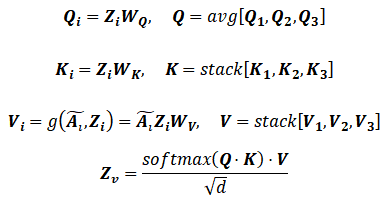
最终的融合过程可以理解为一个查询的过程,首先计算query矩阵Q来表示所有视角的一致性,然后对于每个视角计算key矩阵K作为索引,最后确定每个视角的value矩阵V,并将V矩阵根据Q和K的点积得到的系数进行加权,作为最终的结果。值得注意的是,我们仿照Transformer的思路将注意力机制扩展为多头注意力(multi-head attention)来提高计算效率以及表达能力。
由于不同的任务所需要的信息是有差异的,相比于view attention,我们还提出了task attention来建立任务与视角之间的联系。Task attention整体的形式与view attention十分类似,区别在于对于每个任务我们将Q,K矩阵随机初始化,因此Q,K将只会根据特定的任务被优化,进而可以帮助每个任务学习到对自身有益的信息。
- 多任务学习
为了同时处理多个任务,我们将所有任务的目标函数联合优化,得到了如下的目标函数:
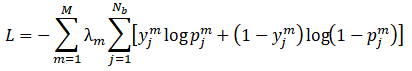
其中M为任务的数目,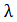 是衡量每个任务的权重的超参数,由于链接预测本质上是对边进行二分类,与节点分类一致,均可以被视为分类问题,因此我们均采用交叉熵作为损失函数。
是衡量每个任务的权重的超参数,由于链接预测本质上是对边进行二分类,与节点分类一致,均可以被视为分类问题,因此我们均采用交叉熵作为损失函数。
同时,我们还引入了view construction作为辅助任务来帮助模型学习,由于最终的融合结果包含了多个视角的信息,因此我们可以通过融合的结果来重构每个视角的信息,进而引入了reconstruction loss:
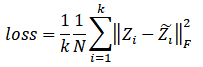
我们将view construction任务与链接预测、节点分类共同优化,取得了显著的性能提升。
实验结果
我们在多个真实的数据集上进行了广泛的实验,针对多视角多任务学习的特征,选择了四个类别的基线算法进行对比,分别为STSV(单任务单视角)、STMV(单任务多视角)、MTSV(多任务单视角)以及MTMV(多任务多视角)四个不同的类别。实验结果为下表所示:
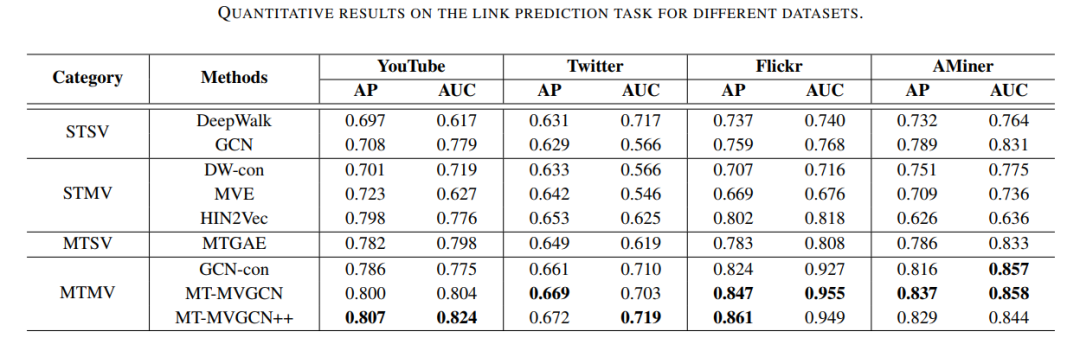
图表4 链接预测实验结果
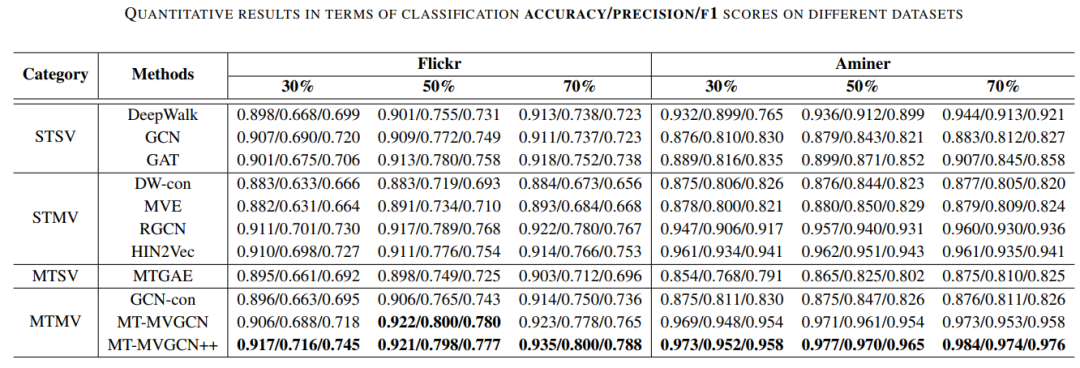
图表5 节点分类实验结果
我们的模型在多个数据集上均取得了最优的效果,证明了我们方法的优越性。实验的结论可以归结为如下几点:
- 对于节点分类任务,在不同的训练集比例下,我们的模型均可以取得最优的效果。
- 在链接预测任务中,我们的方法也可以取得更好的准确率以及AUC分数,这说明了我们的方法是行之有效的。
- 我们发现加入了辅助任务之后,将模型改进为MT-MVGCN++之后,模型的效果进一步提升。
- 相较于单任务学习,多任务学习通常可以取得更好的效果;相对于单视图学习,多视图学习也可以取得性能的提升。综合而言,多任务多视图学习可以取得最佳的实验结果。
结论
这篇论文提出了一个多任务多视图图表示学习的框架,首先分析了在图数据上进行多任务多视图学习的重要性以及必要性,然后详细地阐述了模型的设计理念:对于图神经网络进行改进使得图卷积操作可以在多视图数据上进行信息的抽取,对于多个视图抽取得到不同的视图之间的信息之后,两种注意力机制分别考虑了不同视图之间的关系以及视图与任务之间的关系进行信息的整合,从而学习得到多个视图的联合表示并用于特定的任务。除此之外,本文还提出了视图重构任务可以作为一个辅助任务对模型进行约束,从而使得模型的融合更加具有鲁棒性。实验结果表明,本文提出的模型可以有效地抽取多个视图的信息以及利用多个任务之间的相关性进行互相提升,进而可以取得相较于单任务,单视图表示学习的更佳的效果。
详细内容请参见:
Hong Huang, Yu Song, Yao Wu, Jia Shi, Xia Xie and Hai Jin. Multitask Representation Learning With Multiview Graph Convolutional Networks[J]. IEEE Transactions on Neural Networks and Learning Systems (TNNLS). 2022 March. 33(3): 983-995.
https://ieeexplore.ieee.org/abstract/document/9274508
