背景:现如今,空前且大规模的人类行为数据的可用性正在深刻地改变着我们所处的世界,经济学、公共卫生学、医学、生物学、城市科学等在这一趋势中都受到影响。各个组织、公民个人正在积极尝试、创新和改编算法决策工具以了解全球人类行为模式,并为解决社会重要性问题提供决策支持。
在这篇文章中,作者提出要在大数据背景下积极利用人类行为数据,通过分析人类行为数据,为公共卫生、灾害管理、安全、经济发展和国家统计等政策提供信息,解决社会重要问题。但作者也指明数据驱动的公共产品算法决策具有风险性,包括对隐私的侵犯,缺乏透明度,信息不对称,社会排斥和歧视,如果不加重视会导致“数据暴政”的出现。因此作者在这篇文章中提出了三点建议,希望加强决策的民主化,发挥数据驱动型决策的积极作用而减小其负面影响。
作者将这篇文章分成四部分,首先指明数据驱动决策的意义和存在的问题,第二部分通过案例说明数据驱动算法有利于决策的优化,第三部分说明其存在缺陷,最后提出改善建议,希望发挥数据驱动算法的优势以解决社会重要问题。
第一部分 数据驱动决策的重要性和存在的问题
人类行为数据已经从稀缺的资源发展成为大规模的实时流,作者强调了通过数据驱动的算法决策创造的积极机会:例如推断社会经济国家和个人的状况和犯罪预测,测绘疾病的传播,或了解自然灾害的影响;同时也提醒从业者应该意识和解决的潜在负面后果,防止“数据暴政”的出现。作者在这篇文章中多次提到了黑匣子决策,即只能看到结果无法看到过程,黑匣子决策缺乏透明度和问责性,可能牺牲公民的个人权利,造成数据暴政,例如威廉•伊斯特利表示全球经济发展和扶贫项目受到“专家专制”的支配,这些“专家”将诸如贫困或正义等多层面的社会现象缩减为一套技术解决方案,这些技术解决方案没有公民参与,没有对“专家”的问责,缺乏公平,易导致数据暴政。作者希望通过确保数据决策的透明度,实行问责制和保障公民参与,从而实现数据驱动的民主化决策。
第二部分,数据驱动算法有利于决策优化
 作者建议利用大规模的相关数据流来挖掘和训练算法,可以提高分析和技术能力,用基于机器学习的算法来处理人为决策极限的复杂问题。人类决策有明显的局限性,例如腐败、低效或不公正,向数据驱动算法的转变反映了对客观性,以证据为基础的决策以及对资源和行为的更好理解的探索。
作者建议利用大规模的相关数据流来挖掘和训练算法,可以提高分析和技术能力,用基于机器学习的算法来处理人为决策极限的复杂问题。人类决策有明显的局限性,例如腐败、低效或不公正,向数据驱动算法的转变反映了对客观性,以证据为基础的决策以及对资源和行为的更好理解的探索。
Diakopoulos 将算法的功能分为四大类:(1)分类,根据信息的特征将信息分类为单独的“类” (2)确定优先次序,强调和排列特定信息或结果的排名,以牺牲他人为基础的预定义标准; (3)关联性,确定实体之间的相关关系;和(4)基于预定标准过滤,包含或排除信息。
功能 类型 示例 分类 声誉系统,新闻评分,信用评分,社交评分 Ebay, Uber, Airbnb; Reddit, Digg; CreditKarma; Klout 优先级 一般搜索引擎,元搜索引擎,语义搜索引擎,问答服务 Google, Bing, Baidu; image search; social media; Quora; Ask.com 关联性 预测发展和趋势 ScoreAhit, Music Xray, Google Flu Trends 过滤 垃圾邮件过滤器,儿童保护过滤器,推荐系统,新闻聚合器 Norton; Net Nanny; Spotify, Netflix; Facebook Newsfeed |
根据以上算法进行功能分析,可以计算出何为社会有益算法,即最能使公共产品决策和资源优化的算法,这些算法旨在分析来自各种来源的大量人类行为数据,然后根据预先确定的标准选择与其预期目的最相关的信息。作者通过分析下列具体案例,强调了数据算法的积极作用:
第一,犯罪行为动态分析和预测性警务
首先,作者介绍了犯罪行为动态分析的两种模式:1、是以人行为数据为中心的模式,主要用于个人或集体犯罪分析。Wang等人提出了一种名为“系列发现者”的机器学习方法,用于检测同一罪犯或罪犯群体所犯罪行的具体模式;2、以地方为中心的警务实践模式,对犯罪热点检测、分析和解释。Toole等人提出了数学、物理和信号处理的定量工具的新颖应用,分析刑事犯罪记录中的空间和时间模式。
其次是预测性警务的运用方法正从学术领域转向警察部门。总的来说,目前正在使用四种主要的预测性警务方法:(1)预测犯罪地点和时间的方法;(2)检测罪犯和标记将来有犯罪风险的人的方法;(3)确定犯罪者的方法;(4)确定群体或在某些情况下可能成为犯罪受害者的个人的方法。
第二,推断国家和个人的社会经济状况
准确地衡量和监测关键的社会人口和经济指标对于设计和实施公共政策至关重要。如今一些研究人员开始使用手机数据、社交媒体和卫星图像来推断个人用户的贫困程度和财富状况,以创建高分辨率的地图财富和贫困的地理分布,这为政府用来决定如何分配稀缺资源,研究经济增长的决定因素提供了基础。
第三,数据驱动算法对公共卫生的意义
数据算法有利于研究流行病学、分析环境和紧急情况,以支持政府决策或评估政府措施,并能更加精准评估精神健康。例如Tizzoni和Wesolowski等将传统的流动性调查与手机数据(呼叫详细记录或CDR)提供的信息进行了比较,对疾病的传播进行建模,特别是在调查可用性非常有限的低收入经济体中,能持续监测流动模式,以支持决策或评估政府措施的影响;且在心理健康领域,一些研究表明通过手机和社交媒体收集的行为数据可以被用来识别躁郁症,情绪,人格和压力,这些新的行为数据来源可以在临床环境之外监测心理健康相关的行为和症状,而不必依靠自我报告的信息,提升决策准确性。
表格总结了本节回顾的文献的主要观点
关键区域 解决问题 参考 预测性警务 犯罪行为分析 Ratcliffe [67], Short et al. [72], Wang et al. [90] 犯罪热点预测 Bogomolov et al. [10, 11], Ferguson [32], Traunmueller et al. [85] 行为人/受害人身份证明 Perry et al. [64] 金融与经济 财富与贫困的映射 Blumenstock et al. [8], Louail [49], Jean et al. [39], Soto et al. [76], Venerandi et al. [88] 消费行为分析 Singh et al. [73] 信用评分 San Pedro et al. [71], Singh et al. [74] 公共卫生 流行病学研究 Frias-Martinez et al. [35], Tizzoni et al. [82], Wesolowski et al. [94] 环境和紧急情况映射 Bengtsson et al. [4], Liu et al. [48], Lu et al. [50] 精神健康 Bogomolov et al. [9], De Choudhury [20], de Oliveira et al. [25], Faurholt-Jepsena et al. [30], Lepri et al. [46], LiKamWa et al. [47], Matic and Oliver [52], Osmaniet al. [59] |
第三部分,数据驱动算法的负面影响

大数据和机器学习方法对决策的潜在积极影响是巨大的,但作者也强调了数据驱动型决策的黑暗面。
第一,侵犯隐私
计算机滥用用户披露的个人数据,以及作为数据代理的实体对来自不同来源的数据进行汇总,直接影响隐私。例如作者介绍的Kosinski等人最近的一项研究表明, 结合Facebook上的“喜欢”数据和有限的调查信息,能准确预测男性用户的性取向,族裔出身,宗教和政治偏好,以及酒精,药物和香烟的使用情况。
第二,信息不对称,缺乏透明度
大规模积累和操纵客户、公民的行为数据的能力,可能会使大公司或威权政府使用有力手段通过有针对性的营销努力和社会控制策略来操纵人群中的部分人群。这会造成信息不对称,在这种情况下,强大的少数人获得和使用大多数人无法获得的知识,从而导致或者加剧了国家或大公司与其他人之间现有的权力不对称。此外,各种数据驱动的社会福利算法的性质和使用,缺乏公民参与,使得算法缺乏透明度,难以评估问责。
第三,社会排斥与歧视
算法决策程序可以再现现有的歧视模式,继承先前决策者的偏见,或者简单地反映社会上普遍存在的偏见,造成识别不公。识别不公平造成歧视性的结果不断增长,但用于协助决策过程的黑匣子模型将呈指数级的复杂性。作者特别强调了需要透明和问责的机器学习模式,否则在机器驱动的决策严重影响人们的生活的情况下采用黑匣子方法可能导致形式上的算法污名,特别令人毛骨悚然的是那些被污名化的人可能永远不会意识到这一点。
第四部分,提出建议以减小数据驱动算法的消极面

作者希望能够发挥数据驱动型算法的积极作用,避免走向数据暴政,使算法功能强大并使其成为创造价值的工具,为此提出了三点建议:
第一,以用户为中心的数据所有权和管理
作者提出建立以用户为中心的个人数据管理模型,以使个人能够更好地控制自己的数据。于是Enigma平台基于个人数据生态系统(个人数据生态系统由个人数据的安全保管库组成,完全由其所有者控制),利用最新的分散化技术,在密码学和分散的计算机网络创造了一种称为区块链的新技术,它以中间人的作用减少我们作为社会最重要的角色的影响 ,允许人们以安全、可靠和不可改变的方式将独特的数字财产或数据传输给其他人,这种技术可以创建数字货币(比特币),这些数字货币不受任何政府机构的支持。
第二,增加算法的透明度和责任
许多最先进的基于机器学习的模型(例如神经网络)一旦部署就充当黑匣子,当这些模型被用于决策时,对于为什么以及如何做出决定缺乏解释。为了解决这个局限性,最近在机器学习领域的研究工作已经提出了不同的方法来使算法更易于事前和事后检查。例如,一些研究试图通过引入识别的工具来解决算法中的歧视问题并纠正不必要的偏见。
第三,创建生活实验室进行试验
作者建议建立生活实验室以便在现实生活中测试想法和假设。例如移动领土实验室(MTL),一个意大利电信基金会,MIT媒体实验室和西班牙电信发起的生活实验室,通过多种渠道观察了超过三年的100个家庭的生活,已经收集了来自多个来源的数据,包括智能手机,问卷调查,经验抽样调查等,并用于创建研究参与者生活的多层次视图。尤其是,社交互动(例如,通话和短信通信),流动程序和消费模式等已被捕获。 MTL的目标之一是设计个人数据存储(PDS)技术共享个人数据的新方式,以促进更多的公民参与。
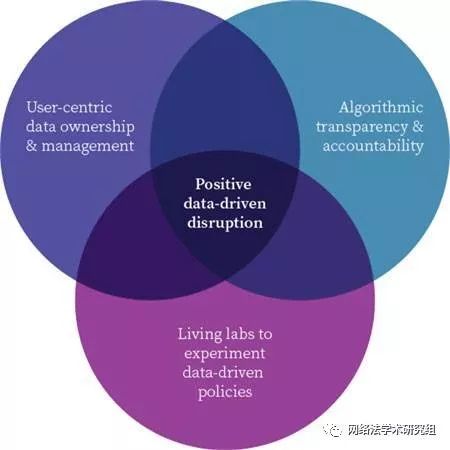
综上所述,在人工智能时代,我们不可避免的要接触到各种数据,借助这篇文章我们对数据算法有了一个基本了解,并意识到数据分析对现实生活和公共事务决策的重要性,但是数据算法的负面影响也不容忽视,只有不断减小甚至消除数据算法的负面影响,才能避免数据暴政,走向依据数据算法的民主治理,这也需要我们法律人的共同努力
 Anna艳娜
Anna艳娜
 X0_0X
X0_0X
 Andrew
Andrew
 Coremail邮件安全
Coremail邮件安全
 RacentYY
RacentYY
 Anna艳娜
Anna艳娜
 Andrew
Andrew
 Andrew
Andrew
 安全侠
安全侠
 Andrew
Andrew
 X0_0X
X0_0X
