基于深度学习的目标检测算法研究进展
摘 要:
目标检测是指在视频或图片序列中把感兴趣的目标与背景区分,是在图像中确定目标是否存在且确定目标位置的过程,是计算机视觉领域中的主要研究方向。目标检测主要应用于人脸识别、无人驾驶、指控和安防等领域,起到人工智能赋能传统应用的作用。目标检测的核心是算法。目前,目标检测算法主要分为两大类,第一类是基于手工设计特征的传统算法,第二类是基于深度学习的目标检测算法。近年来,基于深度学习的目标检测算法成为发展的主流,算法性能也远超手工设计特征的传统算法。该研究进展主要聚焦基于深度学习的主流目标检测算法,分析基于锚点(Anchor-based)类模型中的单阶段、二阶段等主流算法,阐述算法的主要特点和存在问题,介绍基于无锚点(Anchor-free)类型中的关键点和密集预测类算法研究进展,并对基于深度学习的目标检测算法进行了分析和展望。
内容目录:
0 引 言
1 基于锚点的目标检测算法
1.1 二阶段目标检测
1.1.1 R-CNN
1.1.2 SPP-Net
1.1.3 Fast R-CNN
1.1.4 Faster R-CNN
1.1.5 R-FCN
1.1.6 FPN
1.1.7 二阶段方法的相关改进工作
1.2 单阶段目标检测
1.2.1 YOLOv1算法
1.2.2 SSD算法
1.2.3 YOLOv2算法
1.2.4 YOLOv3算法
1.2.5 YOLOv4算法
1.2.6 RetinaNet 算法
1.2.7 单阶段方法的相关改进工作
2 基于锚点的目标检测算法
2.1 基于关键点的目标检测算法
2.2 基于密集预测的目标检测算法
3 不同目标检测算法的性能比较
4 目标检测算法的主要挑战
5 结 语
0引 言
目标检测(Object Dection,OD)是一种从视频或者图片中找到感兴趣的区域并标记出来的行为动作,可以通过算法提取特征来识别定位特定类别的对象。目标检测主要应用在人脸识别、无人驾驶、指挥以及安防等领域。目标检测功能的核心不在于硬件设备,而在于算法设计的优劣。不同算法性能的优劣将直接导致目标检测在不同场景下的检测效果。
自1998年美国工程师提出目标检测概念以来,产生了大量基于手工设计特征的传统算法。这些算法大多是借鉴穷举的思想,在基于滑动窗口生成的候选框内提取特征,并将特征交给分类器去识别。常见方法包括Hear特征+Adaboost算法、Hog特征+SVM算法等。因为早期很多的目标检测算法缺乏有效的特征表示,所以设计了许多复杂的特征表示和在有限资源情况下处理特征加速的技巧。然而,传统的目标检测算法仍存在问题:为生成足够的候选区域,计算机的逻辑运算开销巨大;在提取特征时由于特征较多,筛选过程过于缓慢,分类速度和精度达不到实际应用的标准。Girshick等率先提出了将具有卷积神经网络的区域应用于目标检测,从而打破了传统目标检测算法性能趋于饱和的僵局。
近15年来,基于深度学习的目标检测算法研究有了长足的进步。基于深度学习的目标检测算法主要分为基于锚点类模型和基于无锚点类模型两种。基于锚点类模型又分为单阶段方法和二阶段方法。单阶段方法只需要提取特征、分类和定位回归即可。二阶段方法比单阶段方法多一个生成候选框的步骤,即提取特征后生成候选框再分类定位回归。基于无锚点类模型主流算法分为基于关键点和密集预测两类。因为基于深度学习的目标检测算法各有优势,所以本文综合分析了各类算法的主要特点和存在的问题,以期能够帮助读者理解目标检测算法的原理和内涵。
本文系统分析了基于深度学习的目标检测算法,从单阶段、二阶段两方面出发,对基于锚点类的目标检测模型做出了深入分析,且总结了模型的主要特点和存在的问题,并从关键点和密集预测类模型来分析基于无锚点类模型的研究进展。
1 基于锚点的目标检测算法
基于锚点的目标检测算法是由预先定义的锚点生成候选框,然后使用候选框进行分类和定位。卷积神经网络发展于2012年,近年来逐渐成熟。由于卷积神经网络能够对数字图像有较好的特征表示,因此如何将卷积神经网络应用于目标检测是研究的重点。2014年,Girshick等首先提出了将这种网络结构应用在目标检测场景中,并命名为RCNN算法。从那时起,目标检测算法进入基于锚点的时代,同时迎来了快速发展。目标检测开始进入单阶段和二阶段交替发展阶段。目前,主流的基于锚点类算法按照出现时间和发展顺序可分为二阶段方法和单阶段方法。二阶段方法基于回归,而单阶段方法是在二阶段方法的基础上少一个生成候选框的步骤,相比于二阶段方法检测速度更快,更适合部署移动平台。二阶段方法检测精度更高,更适合精准检测的应用场景。图1给出了近年来优秀的目标检测算法。

图1 2013年11月至2020年10月目标检测算法总览
1.1 二阶段目标检测
二阶段目标检测算法是基于回归的算法,由两个阶段组成。先通过策略生成锚点框,后将锚点框通过处理后进行回归定位。二阶段的经典主流算法主要有R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN、R-FCN以及FPN等。
1.1.1 R-CNN
R-CNN是Girshick等提出的第一个工业级精度的二阶段目标检测算法,将PASCAL VOC 2007测试集的平均精度均值(mean Average Precision,mAP)从之前最好的35.1%提高到了66%。R-CNN的实现过程如图2所示。R-CNN算法首先通过选择性搜索生成约2 000个建议框,将每个建议框调整为同一尺寸即227 pixel×227 pixel,后将其放入AlexNet中提取特征得到特征图。SVM算法对提取的特征进行处理,然后每个类别都会形成一个对应向量,同时也会出现一个分值,最后使用非极大值抑制的技巧进行比对处理。同时,使用基于回归的方法调整生成的矩形框,使之对目标的包围更加精确。R-CNN算法使目标检测的精度得到了质的改变,是将深度学习应用到目标检测领域的里程碑之作,也奠定了基于深度学习的二阶段目标检测算法的基础。
R-CNN的主要特点是将大规模的卷积神经网络应用于候选框来提取特征,但也存在一些问题。第一,每个候选框需要单独计算,且有的候选框重叠在一起,导致所需计算资源巨大;第二,训练过程的4个步骤单独完成,缓存数据独立保存,导致训练过程复杂;第三,前两个缺点导致运行速度相对较慢,无法满足实时性需求;第四,对图像的输入大小有约束,要求图像的尺寸为227 pixel×227 pixel,对图像要进行缩放操作会破坏图像的信息,降低检测器的检测精度。

图2 R-CNN算法实现流程
1.1.2 SPP-Net
针对卷积神经网络的候选框的重复计算和缩放图像造成的信息损失问题,He等基于卷积神经网络于2015年提出SPP-Net算法。SPP-Net在R-CNN的基础上去掉了在输入图像上生成候选框并将其统一成同一尺寸的操作。将SPP层放入全连接层和倒数第一个卷积层之间,将获得特征向量的方式设置在卷积操作之后,减少了操作,降低了复杂度。SPP-Net具体实现流程如图3所示。
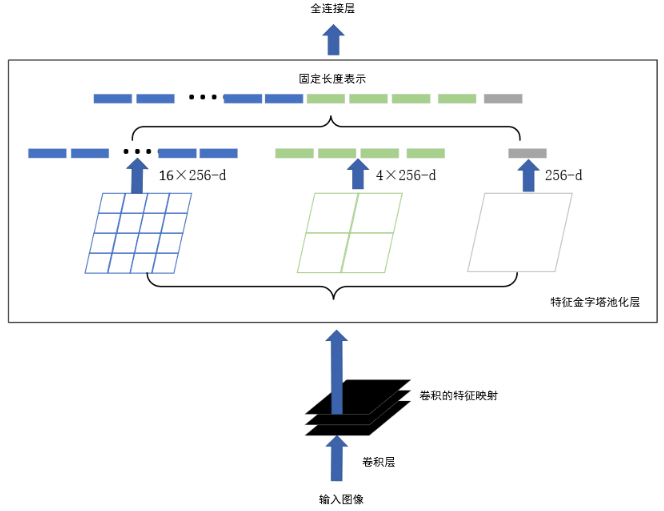
图3 空间金字塔池化层结构
SPP-Net创新使用了空间金字塔结构,只提取一次特征,大大减少了计算量,相对提高了运行速率。但是,SPP-Net也存在一些问题。第一,它仍然保留了R-CNN的生成候选框、提取特征、SVM分类和定位回归4个步骤,中间数据依旧保存,时间消耗仍然巨大;第二,分类网络的初始参数被直接接入骨干网,没有针对具体的检测问题做调整;第三,由于输入图像不需要缩放成统一尺寸,增加了感兴趣区域的感受野,导致权重不能及时更新;第四,SPP的调整只能调节全连接层,当网络足够深的时候无法起作用。
1.1.3 Fast R-CNN
针在2015年Girshick等继承R-CNN的同时吸收了SPP-Net的特点,提出Fast R-CNN算法,将感兴趣区域池化层(ROI Pooling Layer)放在倒数第一个卷积层后,用来将ROI特征生成固定比例的特征图,并将其与全连接层连接。同时,Fast RCNN网络具有双层分支输出——第一个输出通过SoftMax函数来计算类别上的概率分布,第二个输出矩形框的精准调校信息。具体实现流程如图4所示。
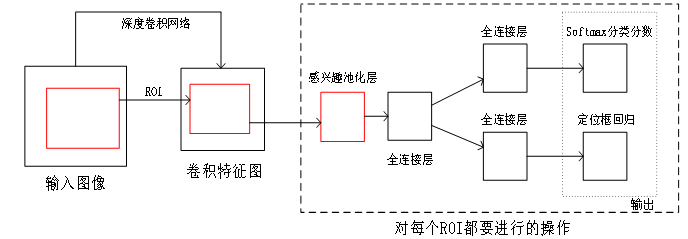
图4 Fast R-CNN算法实现流程
Fast R-CNN使用了和金字塔池化层类似的感兴趣区域池化层,但是感兴趣区域池化层更简单,可以直接将导数结果传回骨干网络。此外,Fast R-CNN将提取特征后的分类步骤和边界框回归步骤添加到深度网络中进行同步训练,其中训练速度和测试速度较R-CNN有较大提升。Fast R-CNN存在两个问题:一是生成候选框仍然是使用选择性搜索,虽然速度较R-CNN有较大提升,但仍然无法满足实时性需求;二是仍然保留了SPP-Net的各模块单独运算,计算量仍然巨大。
1.1.4 Faster R-CNN
针对SPP-Net和Fast R-CNN都使用了选择性搜索的算法模块,造成计算量巨大的问题。为了解决这个问题,Ren等提出了Faster R-CNN算法。在Fast R-CNN的基础上添加区域建议网络,替代了传统的特征提取方法,提高了网络的训练速度。通过神经网络的权值共享实现了端到端的训练。Faster R-CNN的具体实现方式如图5所示。
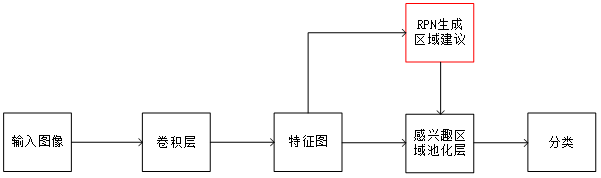
图5 Faster R-CNN算法实现流程
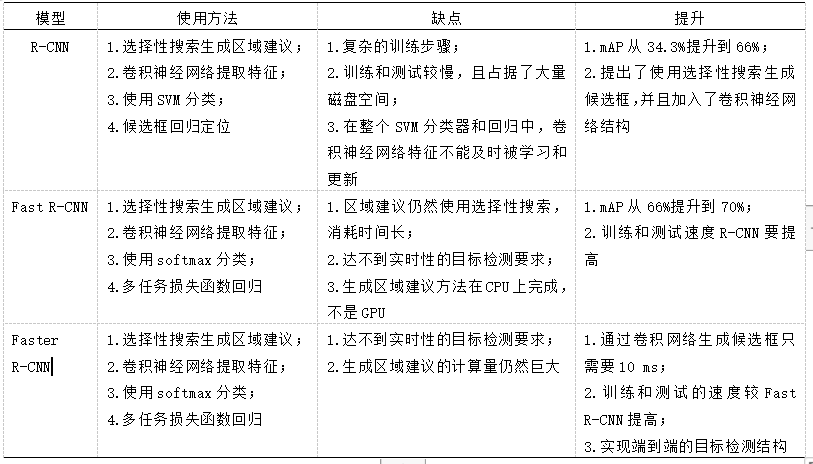
R-CNN、Fast R-CNN、Faster R-CNN属于同一体系的不断优化。表1列出了3个模型的使用方法、缺点和改进程度。
表1 R-CNN、Fast R-CNN、Faster R-CNN对比
1.1.5 R-FCN
针对Faster R-CNN对每个ROI进行大量的重复计算问题,2016年Dai等提出R-FCN方法,引入了位置敏感分数图,以解决在图像分类中图片自身的变化不会更改图片属性的矛盾问题,从而达到将几乎所有的计算权值都在整幅图像上共享的目的。位置敏感分数图使用感兴趣区域池化层来完成信息采样,融合分类与位置信息。R-FCN在PASCAL VOC 2007数据集上取得了mAP值为83.6%的成绩。具体实现方式如图6所示。
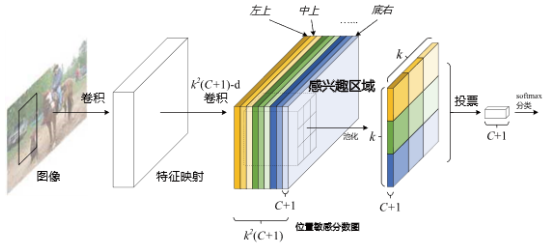
图6 R-FCN算法实现流程
R-FCN提出了位置敏感分数图,提高了CNN的建模几何变换能力,但缺乏对候选区域全局信息和语义信息的利用。
1.1.6 FPN
2017年,Lin等在Faster R-CNN的RPN层的基础上进一步提出了特征金字塔网络(Feature Pyramid Networks,FPN)算法。该设计结构可以使不同分辨率的信息特征融合,使得特征图具有较强的语义。FPN的网络结构如图7所示。
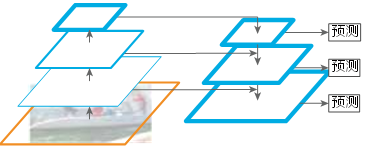
图7 FPN算法实现流程
FPN采用自顶向下的结构,在过程中通过最近邻插值的上采样方法进行特征图放大,可以最大程度地保留特征图的语义信息,但是内存占用巨大,导致速度执行过慢。
1.1.7 二阶段方法的相关改进工作
R-CNN解决了不用卷积神经网络进行分类的问题,但是需要进行边界框定位回归且利用SVM分类器分类。Fast R-CNN解决了边界框和标签不能共同输出的问题,但是生成候选框仍是采用选择性搜索方法,消耗时间过长。Faster R-CNN解决了选择性搜索问题。Mask R-CNN是一个灵活的模型,可应用于检测、分割以及识别等多种任务。之后大量的二阶段方法在网络结构的改进方面都围绕着R-CNN框架,而MRCNN、HyperNe、CRAFT等方法都是在围绕RCNN的特征层和分类器做调整。A-Fast R-CNN加入对抗学习,增加识别的泛化能力。Light Head R-CNN针对检测速度慢设计了一种全新的结构。针对小目标检测问题,SNIP利用金字塔结构在训练期间减少尺寸差异。Cao通过引入注意力机制来解决高分辨率下的特征图与感受野的平衡问题。TridentNet提出了参数共享策略。之前大量的研究都是改进网络结构,Peng提出了一种大的minibatch的目标检测模型MegDet,提高了精度。此外,为了平衡质量与数量的关系,加入级联检测提出了Cascade R-CNN。
1.2 单阶段目标检测
二阶段单阶段目标检测算法是直接进行定位回归的算法,比二阶段方法减少了分阶段步骤,所以检测速度更快。基于深度学习技术的单阶段目标检测主流算法主要包括REDMON等提出的YOLO算法及其系列和Liu等提出的SSD算法及其系列。两种算法系列均是对原始图像直接进行特征提取,计算出目标物体的类别概率和位置坐标值。
1.2.1 YOLOv1算法
2015年,Redmon等提出了YOLO方法,最大特点提升检测速度达到45张/秒,开始了端到端的目标检测技术的发展。YOLOv1先对图像进行预处理,将图片调整为指定大小,然后类似于回归处理来进行卷积提取检测。具体网络结构如图8所示。YOLOv1相对于Faster R-CNN,牺牲了检测准度和定位精度,但是检测速度提高了近7倍。
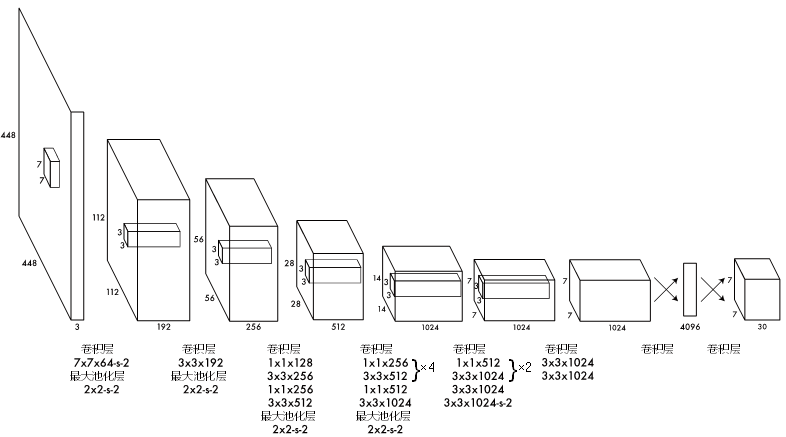
图8 YOLOv1结构
1.2.2 SSD算法
针对YOLOv1算法精度差的问题,Liu等提出了结合YOLO V1和Faster R-CNN的算法SSD。如图9所示,SSD算法使用VGG16作为基础网络。由于不同卷积层所包含特征的尺寸不同,SSD使用了特征金字塔预测的方式,通过多层模型参考模式来实现不同大小的检测。在PASCAL VOC 2007数据集测试300 pixel×300 pixel的图像,实时速率达到59张/秒,mAP值达到76.8%。
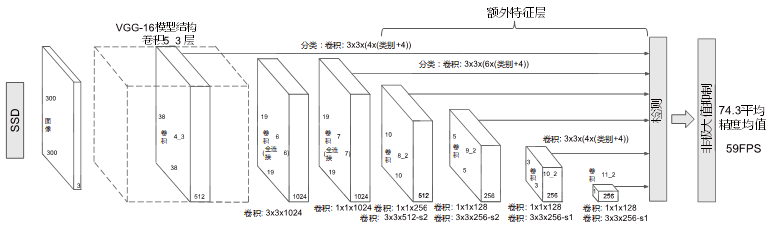
图9 SSD结构
SSD使用多层预测来替代单层预测,但还存在一些问题。第一,采用多层递进,使最后一层的感受野接收信息量增多,导致对小目标物体检测精度不够。第二,存在回归模型的通病,即可能无法收敛。
1.2.3 YOLOv2算法
Redmon针对YOLOv1的不足和存在的问题提出了一种进阶结构YOLOv2。YOLOv2在所有的卷积层上都添加了批标准化操作,省略了dropout操作,使得mAP有了2%的提升。YOLOv1预测矩形框的位置可通过全连接来实现,而Faster R-CNN中通过计算边界框相对于锚点的偏移量,并非直接预测边界框的坐标。于是,YOLOv2引入了锚点框的概念来预测边界框,并去掉了全连接层。YOLOv2的基础网络也进行了调整,使用了DarkNet19分类网络。该网络有19个卷积层和5个最大池化层。YOLOv2具体的网络结构,如图10所示。YOLOv2在PASCAL VOC 2007数据集上的检测精度从66.4%提升到78.6%。
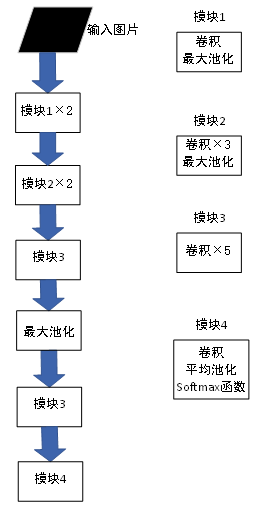
图10 YOLOv2主干网络结构
1.2.4 YOLOv3算法
在YOLOv2的基础上,在2018年提出了更快、更好的YOLOv3方法。YOLOv3在整体结构上有较大改动,在基础网络上使用DarkNet53,其网络结构如图11所示。它的模型有106层网络,精度与ResNet101相同速度下更快。YOLOv3使用类似FPN的方法进行多尺度预测,在网络中3个不同位置的3种不同尺度的特征图上进行检测任务,使小目标检测精度有明显提升。对同一边界框进行多个类别的预测,使用多个独立的逻辑分类器代替softmax函数。这些改变使得YOLOv3在MS COCO数据集上的准确率提高到了33.0%。
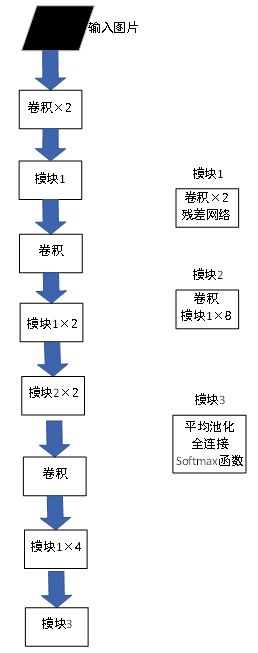
图11 YOLOv3主干网络结构
1.2.5 YOLOv4算法
2020年,Bochkovskiy等人提出了YOLOv4。该模型是集所有优秀的目标检测算法的调参技巧于一体的目标检测模型。它结合了加权残差连接、跨阶段部分连接、跨小批量规范化、自对抗训练、Mish激活函数、CIoU损失函数和DropBlock规范化等方法。主干网络为CSPDarknet53,添加特征金字塔模块来增加感受野,使用PANet来替代FPN做特征融合。在MSCOCO数据集上,它达到43.5%的平均精度(Average Precision,AP),同时在TeslaV100上达到实时速度65张/秒的最新成果。YOLOv4网络结构,见图12。
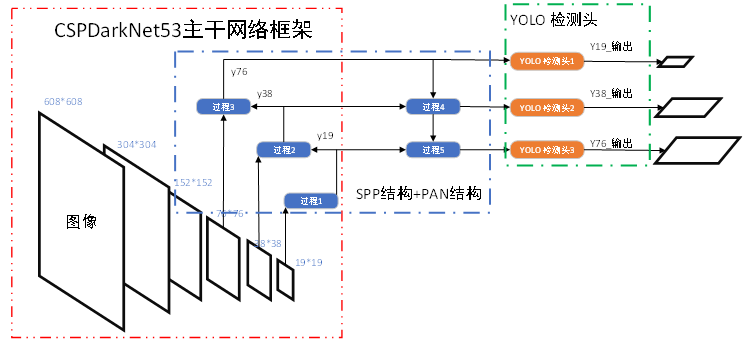
图12 YOLOv4结构
1.2.6 RetinaNet 算法
针对样本类别不均衡的问题,Lin等提出了RetinaNet算法。该算法采用一种新的损失函数focal loss来替代交叉熵损失函数。RetinaNet算法可以使单阶段方法的精度媲美一部分二阶段方法,在MS COCO数据集中mAP值可以达到40.8%。虽然检测速度仍比单阶段方法慢,但仍然超过部分二阶段方法。
1.2.7 单阶段方法的相关改进工作
YOLO系列和SSD系列是单阶段目标检测算法的中流砥柱,几乎奠定了目标检测算法的发展模型。R-SSD、DSOD是基于SSD的改进,解决小目标信息缺失的问题。RON更加关注负例样本。STDN 、PFPNet解决了检测速度与精度平衡的问题。M2Det采用多层金字塔结构,使得精度更高。
2 基于锚点的目标检测算法
基于锚点的模型是指在原图上铺设好大小一定的矩形包围框。然而,基于锚点的模型仍存在问题:预先设定的锚点框数量太多,当目标较少时会浪费大量资源;预设的锚点框大多为负样本,训练时会造成正、负样本失衡;预设的锚点框大多是凭人为经验设计的,其尺寸对数据集敏感,可能会影响检测精度;对于不同的场景,需要修改大量的超参数。为了解决上述问题,提出了基于无锚点的检测模型。以下从基于关键点和基于密集预测类模型两个方面来梳理基于无锚点的主流目标检测算法。
2.1 基于关键点的目标检测算法
在2018年,Law等人提出了CornerNet算法,通过角点来检测边界框。在此基础上,Zhou等人提出了ExtremeNet算法,是一种新的目标检测方向。它选取上下左右4个极值和1个中心点作为关键点。Duan等人发现CornerNet只使用角点会出现精度不准的问题。为了解决这个问题,提出了CenterNet算法。它添加了中间结构,不仅能够检测物体的角点,也可以使物体的中心点进行检测匹配。
2.2 基于密集预测的目标检测算法
Tian等人提出了基于单阶段的全部由卷积层构成的FCOS算法,没有锚点计算,同时增加多种结构来预测多尺度图像。为了特征层与图像进行自适应匹配,FSAF算法不设置锚点来实现基于无锚点的模型。FASF解决了基于锚点的两种限制问题:一是特征的选择问题;二是锚点的采样问题。
3 不同目标检测算法的性能比较
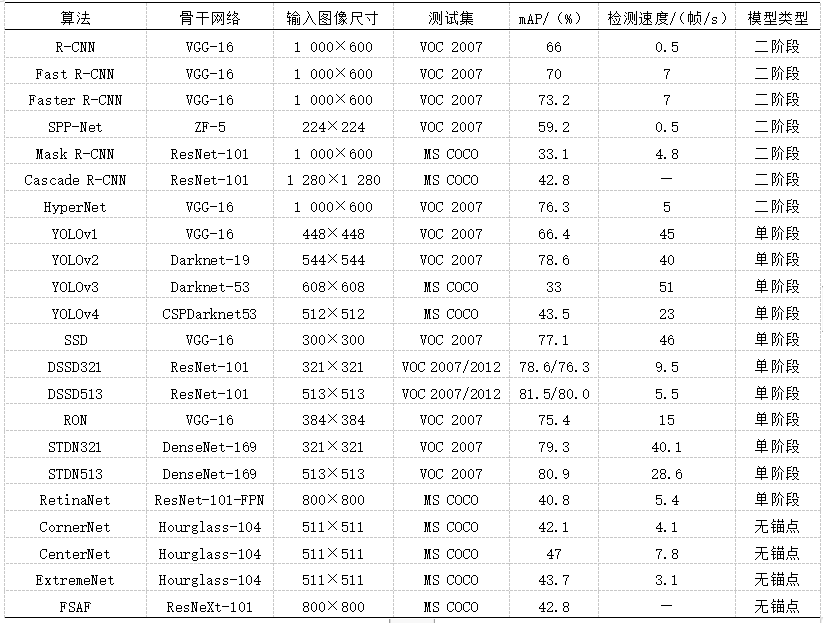
在目标检测领域中,在业界承认的ImageNet、COCO等公开数据集进行算法性能验证是检测模型的最好方法。本文采用所有类别平均准确率(mean Average Precision,mPA)做为评价模型准确率性能的优劣,用每秒内可以处理的图片数量即帧率做为评价模型检测速度性能的优劣。相同环境下,帧率越大,检测速度越快。表2是对基于锚点类模型和基于无锚点类模型中的主流算法进行性能指标参数的比较。可以看出,Faster R-CNN在VOC 2007数据集的mAP值有73.2%,检测速度有7帧/s。但因为Faster R-CNN可修改性很强,所以修改后的Faster R-CNN算法可广泛应用于工业检测。总体来说,二阶段方法更适用于具有对生产的安全性、高效性、完整性要求高的自动化生产的工业场景。YOLOv4在MS COCO数据集的mAP值为43.5%,对小目标物体有较强的泛化能力,检测速度达到了23 帧/s。最新的单阶段目标检测算法的检测精度已达到工业应用标准,且检测速度达到了近实时水平,适用于对实时性有较高要求的应用场景。而CenterNet在MS COCO数据集上,虽然mAP值达到了47%,但是检测速度只有7.8帧/s。总体来说,单阶段方法比无锚点类算法更适合有实时检测需求的应用场景。随着算法结构的复杂设计,未来一定是在精度提升的同时保证较快的检测速度,且部署量级需足够小。
表2 不同目标检测算法的性能
4 目标检测算法的主要挑战
现在仍然有以下问题有待突破。第一,小目标问题。由于小目标尺寸小,仅占整个图像的部分区域,包含的特征信息较少,难以消除复杂特征背景的干扰。目前,很多目标检测算法通过融合多尺度的特征信息感知目标的上下文信息,以解决小目标的特征信息少的问题,但是仍然会造成误检和漏检等问题。第二,光照问题。可见光的目标检测已经趋于成熟,在逆光条件下甚至是在黑夜场景中对目标进行检测识别存在一定挑战。第三,传输时的恶劣信道问题。当数据图像经过网络传输造成损伤丢帧时,需要目标检测算法仍然可以识别。未来,在复杂的背景环境中要消除复杂特征的干扰,提升对目标检测的准确性和实时性。
5 结 语
过去的10年中,基于深度学习的目标检测在算法识别精度和检测速度上取得了显著成就。本文深入系统地分析了基于锚点的目标检测算法,从基于关键点和基于密集预测类模型两个方面梳理了基于无锚点的目标检测算法。结合目标检测的评价指标讨论模型的主要特点、存在的问题以及进一步扩展和改进这些目标检测模型的相关工作。本文的分析结果能够帮助读者理解主流的目标检测算法,了解目标检测算法对传统应用的支撑作用。
