1. 漏洞:数据泄露的重要源头
近年来,数据泄露事件屡屡发生,数据泄露数量不断增加,波及众多行业,给企业和用户带来了不可估量的严重后果。据金雅拓(Gemalto)发布的数据泄露水平指数(Breach Level Index)调查报告,2018年上半年,全球共发生了945起数据泄露事件,导致共计45亿条数据被泄露,过去5年有近100亿条记录被泄露,平均每天泄露的记录超过500万条。
系统漏洞正是造成数据泄露的罪魁祸首之一。2018年,Facebook遭遇自创立以来的至暗时刻,全年3次被曝发生数据泄露事件,其中2次都与系统漏洞直接相关,涉及约1亿用户。2018年9月,Facebook在泄露5000万条用户信息后再次卷入数据泄露旋涡,其系统因安全漏洞遭黑客攻击,导致3000万条用户信息泄露,包括1400万条用户的姓名、联系方式、搜索记录、登录位置等敏感信息。12月,Facebook再次被曝因软件漏洞可能导致6800万用户的私人照片泄露。
2018年3月,美国运动品牌安德玛旗下的健身应用MyFitnessPal因存在系统漏洞遭到黑客攻击,导致1.5亿条用户数据被泄露,涉及用户名、电子邮件地址和密码等信息。美国票务巨头Ticketfly、面包连锁店Panerabread以及谷歌等企业均曾因系统漏洞导致数据泄露。
由系统漏洞引发的数据泄露事件不一而足,那什么是漏洞呢?在计算机领域,漏洞特指系统存在的弱点或缺陷,一般被定义为硬件、软件、协议的具体实现或系统安全策略上存在的缺陷。
1947年9月9日,美国海军对Mark II型计算机进行测试时,计算机突然发生了故障。经过几个小时的检查,当时的美国海军中尉、电脑专家格蕾丝·霍波(Grace Hopper)发现,一只被夹扁的小飞蛾卡在了Mark II型计算机的继电器触点之间,导致电路中断。将飞蛾取出后,计算机恢复正常。霍波在工作日志上写道“:就是这个Bug(虫子)害我们今天的工作无法完成。”自此,“Bug”一词被当作计算机系统缺陷和问题的专业术语一直沿用至今。在日常生活中,人们也通常将Bug与漏洞画上等号。
漏洞伴随着系统的诞生而持续存在。目前,大型信息系统的代码动辄数百、上千万行,Windows 7操作系统有5000万行代码,Windows 8有上亿行代码,其中潜藏着成千上万的漏洞。更可怕的是随着信息系统运行、检测、迭代升级,尽管绝大部分漏洞被发现并及时清除,但仍有部分漏洞如附骨之疽一样难以被发现,更不会被修复,成为持续影响系统安全、造成系统持续不安全的重要源头。例如,2018年1月发现的能影响几乎所有Intel CPU、AMD CPU和部分ARM CPU的Meltdown(熔断)和Spectre(幽灵)漏洞,其产生时间可追溯至1995年,当时CPU刚刚开始使用乱序执行和预测执行等硬件设计特性。微软自动认证漏洞、BadTunnel漏洞、Windows打印机漏洞、Shellshock漏洞等在被发现并修复之前,潜藏时间均超过20年。
2. 黑客:游走在漏洞边缘的逐利者
黑客攻击是导致数据泄露的最主要原因。根据金雅拓统计,56%的数据泄露事件是由“恶意的外部入侵者”引发的。IBM的研究报告显示,犯罪攻击导致了48%的数据泄露事件,漏洞攻击、病毒利用、“撞库”等是主要的数据获取方式。
2018年8月28日,华住酒店集团旗下酒店共计5亿条用户信息在暗网被售卖,涉及用户姓名、身份证号、手机号、邮箱、家庭住址、生日、入住时间、离开时间、酒店ID号、房间号及消费金额等敏感信息。根据调查,该事件是由疑似华住程序员在GitHub(面向开源及私有软件项目的托管平台)上传的名为CMS的项目被黑客攻击所致。
2018年1月,印度的10亿公民身份数据库Aadhaar被曝遭网络攻击,姓名、电话号码、邮箱地址、指纹、虹膜记录等极度敏感的用户信息被泄露。根据调查, Aadhaar数据库的登录和e-Aadhaar的下载存在风险,允许第三方通过白名单IP地址登录Aadhaar数据库,访问相关数据。
2017年10月3日,雅虎的母公司——美国电信巨头威瑞森表示,雅虎所有30亿用户的个人信息均于2013年被黑客窃取,涉及用户姓名、联系方式、密码以及安全问答等敏感信息。
人为因素是数据泄露的重要原因。据IBM统计,25%的数据泄露事件由人为因素导致。人为因素分为两种情况:一种是企业内部人员或承包商因设备配置不当、工作疏忽,导致数据暴露在公开的互联网上;另一种是企业内部人员或承包商实施恶意的内部攻击,导致数据泄露。
2018年6月,美国Exactis公司因服务器没有防火墙保护,使2TB数据库直接暴露在公共互联网上,导致上亿条美国成年人的个人信息和数百万条公司的信息被泄露,这些敏感信息包括电话号码、家庭住址、电子邮箱,以及宗教信仰、是否吸烟、兴趣爱好、个人习惯等,几乎可以构建一个人的完整“社会肖像”。
2018年6月发生的事件还有10亿条圆通快递数据在暗网被兜售。根据卖家描述,售卖数据包括寄(收)件人姓名、电话、地址等信息,是由圆通内部人士批量出售的2014年下旬的数据。经网友验证,姓名、电话、住址等信息均属实。考虑到泄露数量之大、准确率之高,外界普遍认为数据来源为圆通内部较高级别的工作人员。
由于用户数据涉及大量个人隐私,其重要性对用户不言而喻。然而,作为数据的生产者、拥有者,用户难以掌握自身数据的流转轨迹,数据泄露后难以第一时间获知,甚至在泄露数据多次转手,被用于精准营销、诈骗时,都不清楚到底是哪里出了问题。
为什么会出现这样的情况呢?有以下几方面的原因。
第一,企业和用户一样“无知”。当前,大部分企业对数据泄露等数据安全问题的认识不到位,总以为不会得到黑客的“眷顾”,并且没有建立相应的监测预警、应急响应机制和手段,不仅发现不了数据泄露,而且难以及时应对和补救。根据IBM统计,企业发现数据泄露的平均时间是197天,控制数据泄露造成的后果还额外需要平均69天。当然,发现数据泄露的时间越长,控制数据泄露的时间越久,企业和用户的损失也就越大。国内外企业大规模数据泄露事件举例如表1所示。
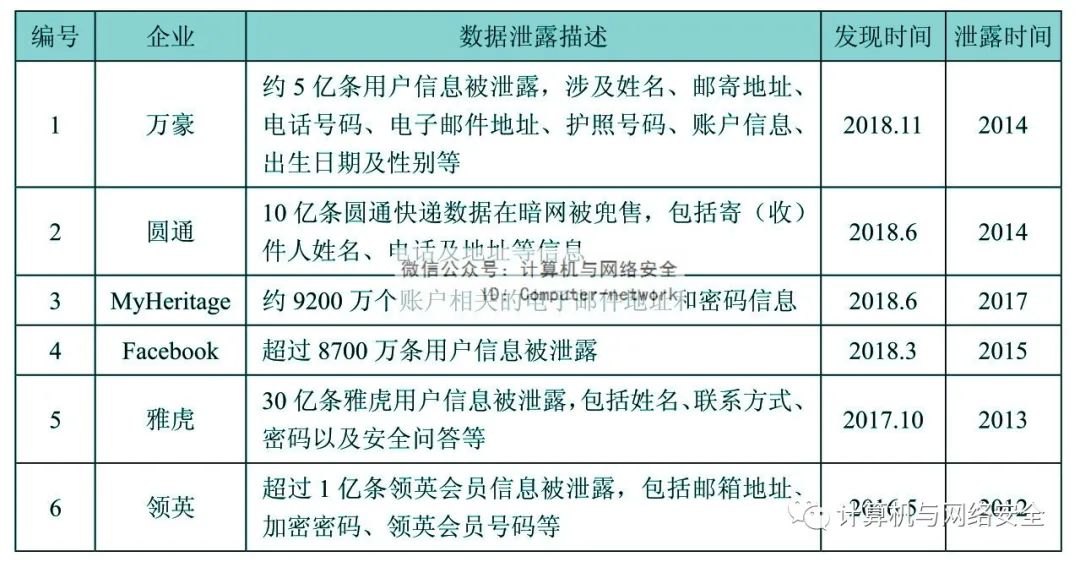
表1 国内外企业大规模数据泄露事件
从表1中可以看出,不仅酒店、快递等行业企业,Facebook、雅虎等互联网巨头对数据泄露的感知能力都很差,数据泄露发生与发现的时间间隔普遍较长,对企业和用户造成的损失自然也更大。
第二,企业比用户更“先知”。如果企业受限于自身能力难以发现数据泄露,未能及时向用户预警,还能说是情有可原,那么发现数据泄露却知情不报就另有意味。
2017年11月,Uber发布声明,承认其在2016年曾遭黑客攻击并导致数据大规模泄露。当时,黑客窃取了5700万条用户数据,包括用户姓名、邮箱和手机号等敏感信息。然而,据彭博社报道,Uber在得知数据被窃取后没有第一时间向政府机构报告,也没有及时通知用户采取防范措施,而是向黑客支付了10万美元,试图销毁被盗数据以隐瞒泄露事件。
2017年9月,美国发生了历史上最大规模和影响的数据安全事件。征信机构Equifax的1.45亿条美国公民的信用记录被泄露,包括姓名、社会保障号、出生日期、地址以及一些驾驶证号码等。美国约20.9万名消费者的信用卡详情和涉及18.2万人的争议文件也可能遭到泄露,Equifax在英国和加拿大的数千万名顾客也受到影响。根据调查,Equifax在数据泄露事件发生前忽略了国家安全部、安全专家发来的大量关于隐私数据威胁的警告;事件发生后,Equifax也是在确认数据泄露的第40天才向客户、投资者和管理者发送通告,导致数据泄露的影响进一步扩大。
3. 网络爬虫:数据泄露的新渠道
大数据时代,企业收集数据的方式多种多样。除了直接通过用户采集之外,还包括传感器采集、网络爬虫采集等方式。其中,利用网络爬虫采集公开信息是企业数据的重要来源。相关数据显示,50%以上的互联网流量其实都是爬虫贡献的;对于某些热门网页,爬虫的访问量甚至占据了总访问量的90%以上。
所谓网络爬虫又称网页蜘蛛、网络机器人,是一种按照一定规则自动从互联网上提取网络信息的程序或脚本。本质上,网络爬虫是通过代码实现对人工访问操作的自动化。但是,网络爬虫具备的代码解析能力使其可能访问到人工不会访问或者无法访问的内容。技术都具有两面性,虽然网络爬虫已广泛应用,但绝不能无限制使用。过度使用网络爬虫,可能引发一些问题:过于野蛮的数据爬取操作可能加大网站负荷,导致网站瘫痪,等等;用爬取技术获取数据,可能导致数据所有者失去对数据的唯一拥有权。如果爬取数据中的企业信息和个人信息未经授权或被不正当地使用,可能引发商业纠纷,侵犯个人的合法权益。
为了规范网络爬虫行为,荷兰软件工程师马蒂恩·科斯特(Martijn Koster)于1994年2月起草了网络爬虫的规范——Robots协议。Robots协议全称网络爬虫排除标准(Robots Exclusion Protocol),又称爬虫协议、机器人协议,实质上是为了解决爬取方和被爬取方之间通过计算机程序完成关于爬取的意愿沟通而产生的一种机制。Robots协议存在于网站中,负责告诉网络爬虫哪些页面可以抓取,哪些页面不能抓取。Robots协议是行业广泛遵守的规范,但它只是一个未经标准组织备案的非官方标准,也不属于任何商业组织,不具有强制性,相当于一个“君子约定”。
无视Robots协议抓取数据存法律风险。近两年,因抓取数据而遭遇诉讼被处罚金,甚至锒铛入狱的案例逐步增多;是否遵从Robots协议,也逐步从行业规范上升为量刑的重要依据。2017年,今日头条起诉上海晟品网络科技有限公司采用技术手段非法抓取视频数据。经审理,上海晟品被判定构成非法获取计算机信息系统数据罪。根据判决书,上海晟品使用伪造device_id绕过服务器的身份校验、使用伪造UA及IP绕过服务器的访问频率限制等破解防抓取措施的行为,成了获罪的重要依据。根据《中华人民共和国刑法》第285条规定,非法获取计算机信息系统数据、非法控制计算机信息系统罪,是指违反国家规定,侵入国家事务、国防建设、尖端科学技术领域以外的计算机信息系统或者采用其他技术手段,获取该计算机信息系统中存储、处理或者传输的数据,情节严重的行为。结合上述案例,企业和个人在使用爬虫技术抓取数据时切勿突破、绕开反爬虫策略及协议,切勿破解客户端、加密算法。
近年来,由恶意网络爬虫引发的数据泄露事件也逐步增多。2017年,58同城的全国简历数据泄露引发轩然大波。有淘宝电商出售“58同城简历数据”:一次购买2万份以上,0.3元一条;一次性购买10万份以上,0.2元一条;同时,支付700元即可购买爬取软件。安全专家分析,出售的数据爬取软件本质上是一个恶意爬虫工具,利用58同城系统的漏洞爬取相关信息。根据正常的商业模式,58同城、智联招聘、前程无忧等招聘网站允许企业和个人访问简历信息,网络爬虫自然也在许可范围之内。但是,无论企业、个人还是网络爬虫,都只能看到部分的简历内容,个人联系方式等敏感的简历内容需要付费才可以查看。然而,58同城系统的多个安全技术漏洞的组合使网络爬虫一步步获取到了用户的全部简历信息。具体地说,第一个漏洞允许爬虫批量获取用户的简历ID,第二个漏洞会导致用户姓名等真实信息泄露,第三个漏洞允许爬虫通过用户ID抓取用户的电话号码。在多个漏洞的叠加影响下,用户的简历信息也就没有秘密可言了。
那么,企业和个人应该如何使用网络爬虫这把双刃剑呢?有专家指出,爬取数据前,首先识别数据性质,严格禁止侵入内部系统数据;爬取数据时,避免获取个人信息、明确的著作权作品、商业秘密等;爬取数据后,严格限定数据应用场景,切忌不劳而获、“搭便车”地利用他人数据,侵害他人的商业利益。
4. 数据黑产:分工明确的数据利益链条
大数据时代,信息的高速流转和运营创造了空前的价值,随之而来的信息数据倒卖猖獗,企业大规模数据泄露事件频发,数据安全如临深渊。
根据南方都市报联合阿里巴巴发布的《2018网络黑灰产治理研究报告》, 2017年我国网络黑产已达近千亿元规模,全年因垃圾短信、诈骗信息、个人信息泄露等造成的经济损失估算达915亿元,电信诈骗案每年以20%~30%的速度增长。据不完全统计,2015年,我国网络黑产从业人员就已经超过40万人;截至2017年中,我国网络黑产从业人员已超过150万人。据阿里安全归零实验室统计,2017年4月至12月共监测到电信诈骗案件数十万起,涉及受害人员数万人,损失资金超过亿元。2018年,活跃的专业技术黑灰产平台多达数百个。
在网络黑产早期,数据是网络黑产的重要基础,贯穿网络黑产的上中下游,支持攻击者实施诈骗、骚扰、劫持流量等定向或非定向攻击。近年来,随着数据价值的提升,以数据交易、数据清洗、数据分析为核心的数据黑色产业链逐渐完善,网络黑产迎来了以数据黑产为代表的新时代。
目前,庞大的数据黑产已经相当完整。根据产业链内各角色分工的不同,数据黑产大致可分为上游、中游、下游三部分,如图1所示。
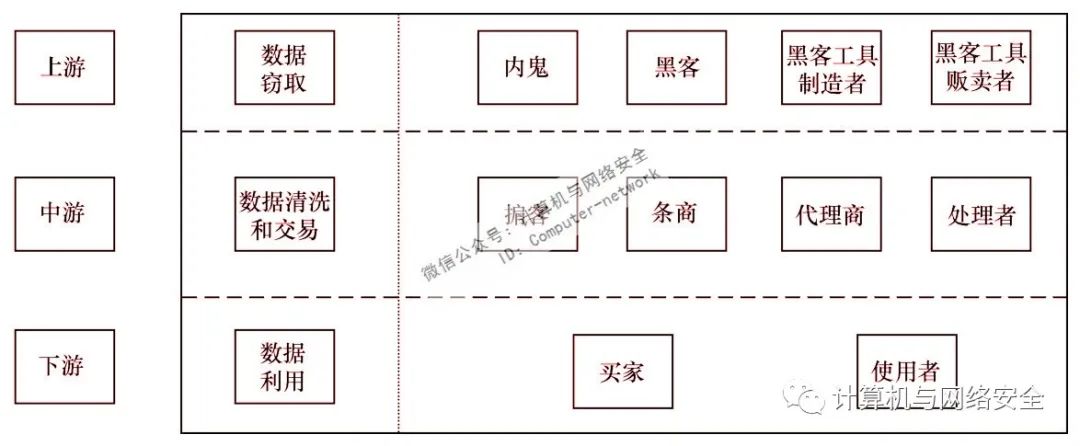
图1 数据黑产上中下游示意图
数据黑产的上游以内鬼、黑客为主,他们通过访问特权或非法入侵企业信息系统获取数据;为黑客实施攻击提供工具支撑的工具制造者、贩卖者等,也属于数据黑产的上游。数据黑产的中游以掮客、条商、代理商及处理者为主,他们负责数据的交易和流转。数据黑产的下游主要是各类数据买家和使用者,这些购买的数据往往用于精准营销、身份认证及电信诈骗等。
数据泄露是数据黑产的源头。根据360互联网安全中心发布的《2016年网站泄露个人信息形势分析报告》,2016年遭到泄露的个人信息约为60.5亿条,平均每人就有4条相关的个人信息被泄露。这些信息最终的命运是在黑市中被反复倒手,直至被榨干价值。
我们总以为黑客、网络攻击及病毒等是造成数据泄露的主要原因。然而,追究数据泄露源,事实不免让人悲哀。相关调查显示,80%的数据泄露是企业内部人员所为,黑客和其他方式仅占20%。根据一份FBI和犯罪现场调查(CSI)等机构联合发布的调查报告,超过85%的网络安全威胁来自内部,危害程度远远超过黑客攻击和病毒造成的损失。根据世界通信技术行业巨头威瑞森发布的《2018年数据泄露调查报告》,超过1/4的数据泄露是由内部人员造成的。我们常常把泄露组织机密信息的人称为“内鬼”或“细作”,而内鬼越来越成为数据泄露的罪魁祸首。
2018年9月,亚马逊被曝其部分员工通过中间人向亚马逊的商家出售内部数据和其他有关客户的机密信息,使购买数据的商家在竞争中获得优势。2018年6月,特斯拉起诉一名前员工盗取公司的商业机密并向第三方泄露了大量公司内部数据,这些数据包括数十份有关特斯拉生产制造系统的机密照片和视频等。2018年5月,江苏常州警方破获“6· 18”特大侵犯公民个人信息案,涉及内鬼多达48名,涵盖银行、卫生、教育、社保、快递、保险及网购等多个行业,包括个人征信、开房住宿及收货地址等数十种实时信息。2017年初,央视曝光了一起涉及50亿条公民信息的数据泄露事件,嫌犯是京东网络安全部的内部网络工程师。根据调查,嫌犯利用京东网络安全部员工的身份,为黑客提供大量在京东、QQ上的物流信息、交易信息及个人身份等数据;嫌犯还曾通过相似手段入侵多家互联网公司的服务器,从中窃取并倒卖公民个人信息,实施盗刷银行卡等违法犯罪活动。
随着产业链上中下游分工的逐步明确和细化,第三方服务机构成为数据泄露的新主体。2018年8月,浙江警方破获了一起上市公司非法窃取用户数据案,堪称“史上最大规模数据窃取案”。据悉,上市公司瑞智华胜借助为国内电信运营商提供精准广告投放系统的开发、维护的机会,将自主编写的恶意程序部署到运营商内部的服务器上,非法从运营商流量池中窃取搜索记录、出行记录、开房记录及交易记录等30亿条用户数据,导致百度、腾讯、阿里巴巴、今日头条等全国96家互联网公司的用户数据被窃取,国内几乎所有的大型互联网公司均被“雁过拔毛”。
数据清洗是数据黑产的关键步骤。“撞库”是数据清洗的第一步。在介绍“撞库”的概念之前,我们先了解一下“撞库”的兄弟“拖库”。“拖库”是指黑客入侵有价值的网站和信息系统,以TXT、XLS等格式从数据库中导出数据的行为。2017年3月,迅雷就曾遭到“拖库”,500万用户的密码全部泄露。通常,“拖库”窃取到的邮箱、社交软件等账号及密码信息大多是单一、无效的,或者有些数据库中存储的密码是经过加密的,难以直接使用。这时就需要使用“撞库”的办法对获得的数据进行清洗。
“撞库”是指黑客通过收集整理互联网上已泄露的用户名、密码等信息生产对应的字典标准,尝试对其他网站进行批量登录,以得到可登录的有效用户名和密码等信息的过程。用户为图省事,经常在多个网站设置同样的用户名和密码,一旦其中一个网站的信息遭到泄露,就很容易被黑客通过“撞库”攻击的方式顺藤摸瓜,获取手机号、身份证号、家庭住址及银行账户等敏感信息。2016年10月,网易遭遇“撞库”攻击,导致网易163、126邮箱过亿条数据被泄露,包括用户名、密码、密码保护信息、登录IP以及用户生日等。
经过“撞库”清洗后,账号、密码的有效性更强,可以精准获取用户多平台的相关注册信息,数据内容更丰富。这在犯罪分子眼中极具价值,价格也水涨船高。
“拖库”“撞库”的流程示意如图2所示。

图2 “拖库”“撞库”的示意图
在数据黑产中,数据交易是数据变现的重要方式之一。根据腾讯安全发布的《信息泄露:2018企业信息安全头号威胁报告》,账号/邮箱类数据、个人信息、网购/物流数据是黑客交易最受欢迎的产品,交易量占比分别为19.78%、12.19%、9.69%。360企业安全发布的《2018年暗网非法数据交易总结》显示,金融行业、互联网行业和生活服务行业涉及的交易数据最多,占比分别达23.1%、16.3%、6.1%。近年来,我国非法数据交易现象日益猖獗。2016年6月—2018年8月,我国发生十余起涉及过亿条个人信息非法交易的案件,并逐步呈现出产业链作案特征。
数据交易在具备变现属性的同时,也是数据清洗的关键一环。据地下数据产业资深人士透露,随着数据需求的持续放大,非法数据交易等数据黑产有公开化的趋势。部分大数据初创企业通过购买各种渠道的数据,其中不乏黑客、内鬼甚至暗网出售的数据,整合数据资源,降低数据成本,提供更全面的数据服务。在这样的业务模式下,不同出身的各种数据实现了合法流通,无疑更刺激了数据非法交易。
经过数据交易、数据清洗等环节的复杂运作,泄露的涉及姓名、电话、身份证、银行卡及家庭住址等真实信息的各种数据最终流入各类数据买家和使用者手中,充分展现了数据的“价值”。电信诈骗、精准营销是数据变现的最终环节。当前,很多企业纷纷整合自有和外部数据资源,在用户画像的基础上针对行业客户提供精准广告投放服务,推销电话、短信骚扰、垃圾邮件和广告弹窗等成为我们最常遇到的骚扰情况。个人信息泄露后,上门推销、诈骗电话、垃圾邮件不请自来。调查显示,中新网PC端与微信端均有超过70%的网友表示,诈骗电话、短信是自己信息被泄露后最困扰自己的事情。银联数据显示,90%的电信诈骗案、盗窃银行卡、非法套现、冒用他人银行卡及网络消费诈骗等都是由于个人数据泄露引发的。2016年8月21日,山东女大学生徐玉玉被诈骗分子以发放助学金的名义骗走全部学费9900元,在报警回家的路上猝死。究其原因,就在于徐玉玉准确的录取信息、手机号码等个人信息被窃取、贩卖,进而引发了精准的电信诈骗。
 RacentYY
RacentYY
 Anna艳娜
Anna艳娜
 安全侠
安全侠
 尚思卓越
尚思卓越
 RacentYY
RacentYY
 Anna艳娜
Anna艳娜
 RacentYY
RacentYY
 Anna艳娜
Anna艳娜
 Andrew
Andrew
 X0_0X
X0_0X
 ManageEngine卓豪
ManageEngine卓豪
 Coremail邮件安全
Coremail邮件安全
