殊途同归的CVE-2012-0774 TrueType字体整数溢出漏洞分析
介绍
官方的漏洞通报中,关于这个漏洞的信息其实很少:
Integer overflow in Adobe Reader and Acrobat 9.x before 9.5.1 and 10.x before 10.1.3 allows attackers to execute arbitrary code via a crafted TrueType font.
只有几个关键点:构造的TTF文件,Adobe Reader版本,整数溢出漏洞。
因为这是一个很老的漏洞,网上能搜到的很多分析文章都是基于《漏洞战争》这本书完成的,并且其中的大多数只是在进行书中内容的复述。在阅读书中内容的过程中,作者提到使用TrueType Font Analyzer对ttf文件进行解析时出错,由此判断问题出现在glyf表中。虽然我找到了这个工具,但实在是太小众了,是一个日本博客中提供的,而用010editor对TTF文件进行解析的过程中没有得到什么有用的输出信息。所以漏洞分析的一开始,最困扰我的就是,如果没有《漏洞战争》这本书,我要如何确定异常数据的位置。
以下的分析内容有些做的其实是无用功,但是体现了针对该漏洞我的整个思考思路以及分析流程,因此全部保留下来。
文件格式分析理解
2.1 利用010editor初步分析TTF文件结构
如果不看书,我能想到的就是用010editor打开TTF文件。
使用PdfStreamDumper将poc.pdf中的TTF文件提取出来(之前分析过一次Adobe Reader中的字体漏洞,所以知道该怎么做),命名为poc.ttf,用010editor打开。软件自动用Template进行解析,Output中显示:
Executing template 'C:\Users\test\Documents\SweetScape\010 Templates\Repository\TTF.bt' on 'D:\Myfiles\vul_study\ldzz\2012-0774\poc.ttf'...*WARNING Line 158: Variable 'glyphIdArray' not generated since array size is zero.
双击这个警告信息,会直接打开用于解析TTF文件的bt文件,定位到出现问题的结构体中:
typedef struct tcmap_format4 { cmap_subtable = FTell(); USHORT format; // Format number is set to 4. USHORT length; // This is the length in bytes of the subtable. USHORT language; // Please see "Note on the language field in 'cmap' subtables" in this document. USHORT segCountX2; // 2 x segCount. USHORT searchRange; // 2 x (2**floor(log2(segCount))) USHORT entrySelector; // log2(searchRange/2) USHORT rangeShift; // 2 x segCount - searchRange USHORT endCount[segCountX2 / 2]; // End characterCode for each segment, last=0xFFFF. USHORT reservedPad; // Set to 0. USHORT startCount[segCountX2 / 2]; // Start character code for each segment. SHORT idDelta[segCountX2 / 2]; // Delta for all character codes in segment. USHORT idRangeOffset[segCountX2 / 2]; // Offsets into glyphIdArray or 0 USHORT glyphIdArray[(length-(FTell()-cmap_subtable))/2 ]; // Glyph index array (arbitrary length) !!!就是这里出现了问题!!!};
那么为什么会出现这个警告信息呢?
搜索tcmap_format4字段会定位到tcmap结构体,也就是TTF文件中的cmap表。在010editor中找到cmap表,其中包含了两个子表,第二个子表中就包含了出现问题的tcmap_format4,点开之后可以发现它的length字段是64,如果你选中整个tcmap_format4结构,会发现它的长度也是64,所以计算(length-(FTell()-cmap_subtable))/2得到的值是0。因此出现了警告信息。
不过我也不知道警告信息有什么用,但是既然这里出现了警告,那么至少说明这个文件中的结构是有一些问题的,再加上template的解析结果其实比较乱,我将结果导出到文档中,并进行了整理:
根据之前的漏洞分析经验,已经知道TTF文件中都是由一个个表组成的,这里汇总的就是不同表的位置以及大小数据,其中用(head)标注的数据指的是文件开头的Table Directory中记录的各个表的偏移及大小,而没有使用(head)标注的数据则是template整理出来的实际的位置和大小。
注意到Table Directory中记录的表的大小信息有3处与实际不符,但是由于对表的具体功能不了解,所以还要继续查资料。
2.2 通过文档详细了解TTF文件格式
通过TTF中template的输出结果,已经对poc.ttf文件有了一个初步的了解,但是由于对于每个表的具体功能并不了解,因此仍旧是一头雾水,所以接下来开始直接阅读文档。
注:以下内容之所以会注意到那么多细节的内容是因为后面调试阶段遇到了相关问题,所以又回过头来补充的。所以可以先看下面的调试,再回过头来看这里的文件格式分析。
2.2.1 name表
name表中包含的是一些关于字体的可读信息,可以被其他表引用,从而向用户提供有用的信息。它的结构是这样的:
注意到其中的char name[35]了吗?它的Start数据是0xFBE,这里其实就是上面统计的数据中,name表Size中未包含的部分。准确的说010editor的template并没有把这部分数据包含在name表的Size中,因此出现了和Table Directory中不符的情况,但是实际上没有任何问题。
2.2.2 cmap表
所谓cmap,其实就是character mapping的缩写,它用来将字符编码映射成实际的字形。由于存在多种平台环境,多种编码形式,因此就对应了多种编码表,因此cmap表中也就可能包含多个子表,每个子表对应一个编码形式。在实际使用的时候会根据情况选择使用哪个子表。
根据文档中的描述,对poc.ttf文件中的cmap进行解释:
其中没有展开的两个tcmap_format结构就是具体的映射表了,注意它们的Start信息,会发现这两个映射表其实就占据了上面tamplate总结的Size信息未包含的那部分。因此虽然和Table Directory中的记录不符,但是也没有问题。
不过在2.1小节中,我们提到了Variable 'glyphIdArray' not generated的警告信息,这个警告信息就是tcmap_format4中产生的,因此再具体的看一下tcmap_format4结构:
format 4格式针对的是2字节编码格式,当字体编码位于多个连续区间之内的时候使用这种格式。上图中的segCount表示的就是连续区间的个数,startCount和endCount可以用于确定编码落在哪个区间范围内,针对上图,六个区间分别是[32, 34]、[77, 77]、[100, 101]、[114, 116]、[160, 160]、[-1, -1],其中最后一个区间不对应任何有效编码。
idDelta和idRangeOffset用于确认编码对应的glyph索引值,针对上图,由于idRangeOffset为0,因此索引值的计算方法为:glyphIndex = idDelta[i] + c。
索引值最后用于在glyphIndexArray中索引,但是在此例中缺少了glyphIndexArray。
看到现在,还是不确定glyphIndexArray这个结构怎么对应到实际的字形上,先看下一个表。
2.2.3 maxp表
maxp表中的数据说明了字体的内存需求,这里只关注一个数值:numGlyphs,保存了glyph的个数。在此例中,这个数值是271。
2.2.4 loca表
loca表中保存了字形数据相对于glyf表起始部位的偏移位置,这个表主要是为了对字形数据能够快速索引。里面就是一个USHORT的数组,一共由numGlyhs+1项(还包括一个表示字符不存在的字形)。
在此例中,数组中有多项是重复的,因为下面分析glyf表时要用到,所以这里做一个整理:
2.2.5 glyf表
glyf表中保存了定义字体字形的数据信息,其中既包括定义字形轮廓的点信息,也包括填充字形的指令信息:
在检查这个表的时候,没有发现和name以及cmap表类似的数据索引的情况,因此需要搞清楚为什么glyf表后面会空余出一大块数据。
这里就要回头看一下loca表中的数据了,如果你将loca表中保存的偏移量*2,再加上glyf表的起始位置0x600,就会得到各个SimpleGlyph的Start值了。
注:关于为什么要2,head表中定义了一个indexToLocFormat数值,如果该值为0,代表short,单位就是2个字节,所以要2。
注意到loca表中重复的数据所对应的SimpleGlyph的Start值也是相同的,虽然它们在template的结果中表示成了不同的项。
但是template的结果中只显示到偏移为0x156的字形数据,之后偏移的字形数据没有解析出来。
现在我们把后面的数据复制出来,然后手工按照SimpleGlyph的结果进行简单的解析:

后面的compressedFlags和contours有点复杂所以我没有进一步处理。
漏洞调试
操作系统:Win7 sp1 32位
Adobe Reader 9.4 英文版
3.1 确定异常成因
打开poc.pdf文件之后,由于发生异常,windbg自动打开,程序中断:
(158.f9c): Access violation - code c0000005 (!!! second chance !!!)eax=632c622c ebx=00000214 ecx=632d0000 edx=3fffd88a esi=632d0004 edi=00004141eip=630979ce esp=0030cdf0 ebp=0030ce84 iopl=0 nv up ei pl nz na po nccs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00010202*** ERROR: Symbol file could not be found. Defaulted to export symbols for C:\Program Files\Adobe\Reader 9.0\Reader\CoolType.dll -CoolType+0x79ce:630979ce 8919 mov dword ptr [ecx],ebx ds:0023:632d0000=00001000
看一下这个地址:
0:000> !address 632d0000 Failed to map Heaps (error 80004005)Usage: ImageAllocation Base: 63090000Base Address: 632d0000End Address: 632ef000Region Size: 0001f000Type: 01000000 MEM_IMAGEState: 00001000 MEM_COMMITProtect: 00000002 PAGE_READONLYMore info: lmv m CoolTypeMore info: !lmi CoolTypeMore info: ln 0x632d0000
发现这是一个具有只读权限的地址,而现在程序在尝试写入,因此出现异常。
由于CoolType.dll每次加载的基地址都不一样,所以为了方便在IDA中定位,直接将CoolType.dll在IDA中的基地址修改成0,然后根据偏移定位到发生漏洞的位置,并将其函数命名为vulFunc。
先看一下IDA中的伪代码分析:
int __cdecl vulFunc(int a1) { if ( (a - 4) < *b || (high = *(b + 0x154), a - 4 >= high) || (end = (a - 4), len = *(a - 4), start = (a - 4 - 4 * len), start < *b) || start >= high ) { result = dword_232438; dword_232434 = 0x1110; } else { v5 = *start; if ( len > 0 ) { do { --len; *start = start[1]; // 异常发生位置 ++start; } while ( len ); --end; } *end = v5; a = (end + 1); result = a1; } return result;}
我对变量名进行了一些修改以使过程更加清晰,整个函数是在对一个范围的数据进行循环前移操作。a-4是范围的终点,终点位置保存了整个范围的长度。函数一开始对整个范围的地址进行了一个上下界的判断,符合要求后才会进行下一步循环前移操作。
确定了函数功能之后,重新加载调试,在vulFunc的起始位置设置断点,然后单步调试,跟踪到计算start的语句start = (a - 4 - 4 * len)的时候发现了问题:
0:000> peax=6426622c ebx=00000000 ecx=03ec2e04 edx=6426622c esi=64266220 edi=64266344eip=640379af esp=0031cd90 ebp=0031ce24 iopl=0 nv up ei pl nz na po cycs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000203CoolType+0x79af:640379af 8b10 mov edx,dword ptr [eax] ds:0023:6426622c=40000001 // 长度是400000010:000> peax=6426622c ebx=00000000 ecx=03ec2e04 edx=40000001 esi=64266220 edi=64266344eip=640379b1 esp=0031cd90 ebp=0031ce24 iopl=0 nv up ei pl nz na po cycs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000203CoolType+0x79b1:640379b1 8bda mov ebx,edx0:000> peax=6426622c ebx=40000001 ecx=03ec2e04 edx=40000001 esi=64266220 edi=64266344eip=640379b3 esp=0031cd90 ebp=0031ce24 iopl=0 nv up ei pl nz na po cycs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000203CoolType+0x79b3:640379b3 c1e302 shl ebx,2 // 长度*40:000> peax=6426622c ebx=00000004 ecx=03ec2e04 edx=40000001 esi=64266220 edi=64266344eip=640379b6 esp=0031cd90 ebp=0031ce24 iopl=0 ov up ei pl nz na po cycs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000a03CoolType+0x79b6:640379b6 8bc8 mov ecx,eax
注意一开始读取到的长度是0x40000001,执行完*4操作之后的ebx的值是00000004,这里发生了溢出。画成图来看比较清晰:
由于范围判断的不严谨,程序没有发现发生了整数溢出,导致了异常的发生。
3.2 确定数据来源
3.2.1 TrueType指令系统分析
既然是长度信息有误,一开始自然会想到要确定这个长度信息来自哪里,扩展一点说,这里的循环前移操作想要操作的是什么数据。
根据windbg的输出确定长度信息来自于地址6426622c,看一下这个地址前面的数据是什么(因为长度信息位于整个数据的末尾):
0:000> dd 64266200 lc64266200 00000000 00000000 00000000 0000000064266210 00000000 00000000 00000000 0000000064266220 00004141 00004141 00004141 40000001
其中的4141吸引了我的注意力,这样的数据不太自然,有很大的可能性是人为设置的。目前已知是TTF文件有问题,所以到TTF文件中搜索一下0x4141出现的位置:
只有这一个位置出现了连续的6个0x41。
如果和2.2.5小节最后对于数据的解析结果来看,这部分数据位于glyf表中最后一个SimpleGlyph的指令部分:

如果查找TrueType文档中关于指令的介绍,可以看到指令0x41是NPUSHW操作,0x06表示入栈个数,说明要入栈6个WORD,同时将其扩展为DWORD,这也就是内存中三个0x00004141出现的原因,但是现在最关键的是要知道0x40000001出现的原因。
我最初根据TrueType文档中的指令介绍,对glyf表中最后一个SimpleGlyph中的指令进行了解释:
// NPUSHW操作,入栈6个WORD,同时扩展为DWORD41, 06, 41 41, 41 41, 41 41, 00 03, 00 00, 00 40// Write Store操作,弹出两个DWORD42 // NPUSHW操作,入栈2个WORD,同时扩展为DWORD41, 02, 7F FF, 7F FF // MULtiply操作,弹出两个DWORD,入栈乘法结果63// ADD操作,弹出两个DWORD,入栈加法结果60 // NPUSHW操作,入栈4个WORD,同时扩展为DWORD41, 04, FF E8, 00 00, 00 00, 00 00 // Read Store操作,弹出一个读取位置DWORD,入栈一个读取结果DWORD43 // PUSHB操作,入栈1个BYTE,同时扩展为DWORDB0, 01 // SUBtract操作,弹出2两个DWORD,入栈减法结果61// Write Store操作,弹出两个DWORD42 // Read Store操作,弹出一个读取位置DWORD,入栈一个读取结果DWORD43// Jump Relative On True操作,弹出两个DWORD,并根据第一个DWORD决定指令要不要跳转78// NPUSHW操作,入栈2个WORD,同时扩展为DWORD41, 02, 7F FF, 7F FF// ADD操作,弹出两个DWORD,入栈加法结果60// ADD操作,弹出两个DWORD,入栈加法结果60//Move the INDEXed element to the top of the stack 从栈顶弹出一个元素k,循环移动栈中接下来的k个元素26 // 注意这里就是vulFunc在执行的操作,所以不再向下分析
然后画出如下图的栈中数据变化情况,结果发现不太对劲:
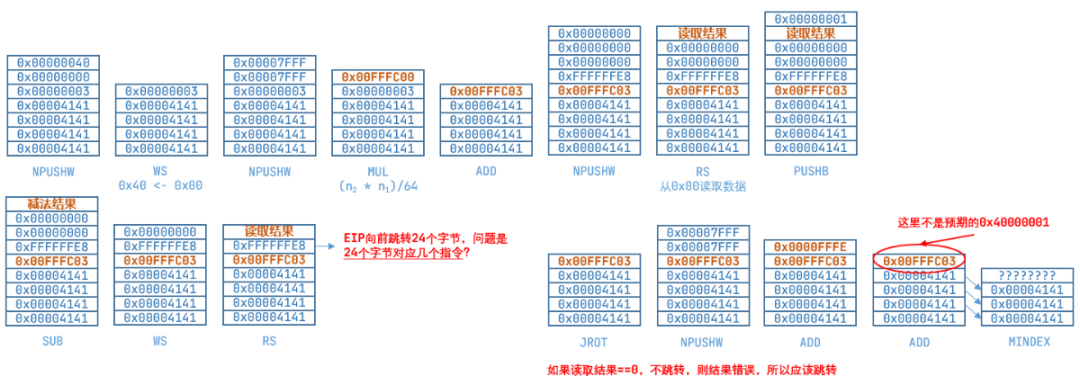
执行到MINDEX这个指令的时候就是在做vulFunc中的循环移位操作,但是得到的长度并不是0x40000001,如上图中所示,应该是执行到JROT指令的时候做了跳转,EIP向前跳转24个字节,现在不知道24个字节对应于多少指令,再手工分析就有点丧心病狂了。
鉴于现在对于TrueType文件结构以及其中的指令系统有了更加深入的了解,我决定回到IDA和Windbg,通过动态调试的方法最终确定0x40000001的数据来源。
3.2.2 代码分析及动态调试
还是回到IDA中vulFunc的位置,在IDA中发现了两个交叉引用,分别位于偏移690E和偏移6C605,重新打开Adobe Reader,在这两个偏移位置下断点,然后加载POC文件,程序中断在了690E的位置,说明异常发生在调用690E之后,在IDA中看一下调用到了vulFunc的那个语句:
.text:00006955.text:00006955 loc_6955:.text:00006955 51 push ecx.text:00006956 50 push eax.text:00006957 FF 14 8D D0 BE 21 00 call funcs_6409C64D[ecx*4].text:0000695E 59 pop ecx.text:0000695F 59 pop ecx .data:0021BED0 6A 6C 00 00 C5 6C 00 00 20 6D+funcs_6409C64D dd offset sub_6C6A, offset sub_6CC5, offset sub_6D20, offset sub_6D6D.data:0021BED0 00 00 6D 6D 00 00 BA 6D 00 00+ ; DATA XREF: sub_690E+49↑r.data:0021BED0 F3 6D 00 00 2C 6E 00 00 2C 6E+ ; sub_6C605+48↑r.data:0021BED0 00 00 6B 70 00 00 6B 70 00 00+ dd offset sub_6DBA, offset sub_6DF3, offset sub_6E2C, offset sub_6E2C.data:0021BED0 52 71 00 00 5F C6 06 00 CA 71+ dd offset sub_706B, offset sub_706B, offset sub_7152, offset sub_6C65F.data:0021BED0 00 00 1F 72 00 00 74 72 00 00+ dd offset sub_71CA, offset sub_721F, offset sub_7274, offset sub_729E.data:0021BED0 9E 72 00 00 95 75 00 00 D5 75+ dd offset sub_7595, offset sub_75D5, offset sub_7615, offset sub_76CC.data:0021BED0 00 00 15 76 00 00 CC 76 00 00+ dd offset sub_76CC, offset sub_76CC, offset sub_76CC, offset sub_7655.data:0021BED0 CC 76 00 00 CC 76 00 00 CC 76+ dd offset sub_7756, offset sub_7767, offset sub_751B, offset sub_995C.data:0021BED0 00 00 55 76 00 00 56 77 00 00+ dd offset sub_999F, offset sub_7558, offset sub_6C6C8.data:0021BED0 67 77 00 00 1B 75 00 00 5C 99+ dd offset sub_6C70D, offset sub_78A2, offset sub_7696.data:0021BED0 00 00 9F 99 00 00 58 75 00 00+ dd offset sub_6C815, offset sub_78FB, offset sub_6C826.data:0021BED0 C8 C6 06 00 0D C7 06 00 A2 78+ dd offset sub_7939, offset vulFunc, offset sub_6CBDA, offset sub_6C7A0...
发现这里在通过ecx寄存器索引一个函数数组。
根据上面对指令系统的分析,已经知道vulFunc是在执行MINDEX指令,那么很自然的会想到这些函数对应于TrueType中的不同指令。vulFunc在整个数组的偏移38的位置,对应于十六进制就是0x26,就是MINDEX的指令码,b( ̄▽ ̄)d。
所以程序应该就是在偏移690E的函数中调用不同的函数来处理不同的指令,我完全可以在.text:00006957 call funcs_6409C64D[ecx*4]这里设置一个断点,然后通过查看ecx寄存器的值来确定每次执行的指令都是什么。
Breakpoint 0 hiteax=00000000 ebx=00000000 ecx=00000000 edx=00000000 esi=03ec2e04 edi=03ec2c54eip=6403690e esp=0031cf08 ebp=0031cf80 iopl=0 nv up ei pl zr na pe nccs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00000246CoolType+0x690e:6403690e 8b442404 mov eax,dword ptr [esp+4] ss:0023:0031cf0c=03ec2f6c0:000> bc *0:000> bp CoolType+0x6957 "r ecx;g"
最后得到了657条输出结果……但是不要着急,如果仔细检查,会发现其中0x78指令起了很大的作用,一共出现了64次,也就是进行了63次指令跳转,直到最后一次没有跳转,继续往下执行,才到达了0x26指令处。
重复的指令序列如下:
ecx=00000078ecx=00000041ecx=00000063ecx=00000060ecx=00000041ecx=00000043ecx=000000b0ecx=00000061ecx=00000042ecx=00000043
如果和上面3.2.1中的图相对应,就会发现程序已知在循环执行这部分指令:

相当于已知在0x00000003的上面递增0x00FFFC00,计算一下0x00000003 + 0x00FFFC00 * 0x40 = 0x3FFF0003。
最后一次的读取结果是0,所以不再进行跳转,而是继续往下执行:
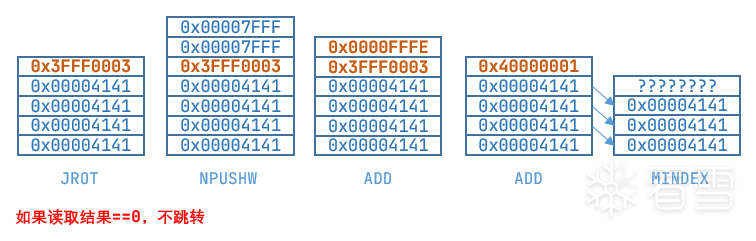
这次得到的长度结果正好就是之前调试看到的数值0x40000001。
总结
在此次的漏洞分析过程中,由于无法说服自己接受“通过TrueType Font Analyzer对于TTF文件的解析结果确定漏洞位于glyf表”中这一因果关系(因为这个工具过于小众,且信息太少),因此我完全放弃根据书中的步骤对漏洞进行分析,转而去查看TrueType的文档。在本文中花费了大量篇幅对TTF文件格式进行了介绍,正是通过对文件格式的理解,我确定了问题处在glyf表中,并进一步确定了问题数据0x40000001的来源。
在我完成漏洞分析转而看书中的介绍时,发现两者殊途同归,最后竟然都对poc文件中的指令进行了分析,只不过我是从文件格式手工解析出发,转而通过调试验证,而书中是先通过调试确定了指令执行顺序,进而解析文件中的部分指令。
从我个人的角度来说,通过对文件格式的理解进而进行漏洞分析,整个逻辑过程会比较通顺,也易于理解。经过了此次漏洞分析,对于TTF文件格式也有了更深一步的认识。
