SEVulDet:一种语义增强的可学习漏洞检测器
Introduction
近年来越来越多的工作采用基于深度学习的漏洞识别框架来对漏洞模式进行识别。然而,不能全面地对源码中的语义进行捕获或是采用适当的神经网络设计仍是大多数现有工作存在的问题。在此之上作者提出了SEVulDet,其具备两个特点:(1)SEVulDet采用了一种路径敏感的代码切片方法来提取足够的路径语义和控制流逻辑至code gadget;(2)同时在结合多层注意力机制的CNN网络中插入一层中空间金字塔池化层,使得SEVulDet能够处理变长的code gadget语义,避免由传统方法(截断或填充)所导致的代码语义缺失。
Background & Motivation
Problem
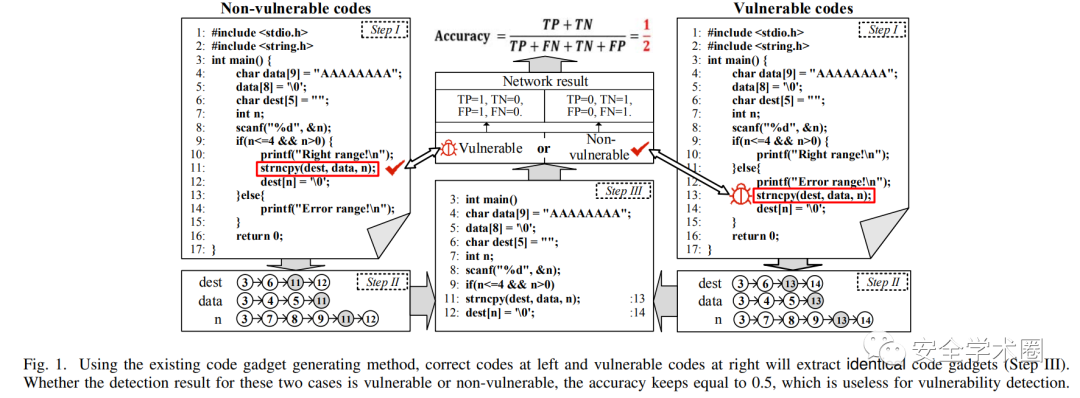
针对现有深度学习框架中存在的影响漏洞识别主要缺陷——语义缺失,作者采用一个例子对其进行了描述。
为了更好地描述,作者做了以下的一些定义:
- Program, statement, token: 程序 由一系列有序的statement组成,即 ,statement由一系列的有序token构成,即, token可以是标识符,常量,运算符,关键字等。
- data-dependence:在程序 中,如果存在两个语句 , 中的变量标识符token被 使用,则称 数据依赖于。
- control-dependence:对于程序 中的两个语句, 当的结果会影响是否执行时,称控制依赖于。
- special token:给定程序 , 且语句 由个special token组成, , 此处的special token指一些特殊的满足语法特点的记号,如库函数调用,数组使用,指针使用以及表达式等。
- code gadget:给定程序 , 且语句 由个special token组成, , code gadget 则是通过这些特殊记号递归生成的具有语义信息(存在数据依赖与控制依赖)的复数有序语句。
- PDG:给定程序 , 且语句 由个函数调用 , 其中的一个函数调用对应的PDG(Program Dependency Graphs)则可表示为有向图 , 是由语句和判断式组成的集合,而 则为表示依赖关系的有向边集合。
接着作者指出了此前的两项同领域工作[1][2]在提取code gadget时存在的问题,即路径不敏感(path insensitive)。
根据code gadget的的定义,我们首先找到special token——strncpy,然后再分别提取strncpy数据依赖的三个记号(dest,data,n),提取记号相应前序与后序的代码切片,结果如step II所示,最终根据这些代码在文件中的位置与调用顺序组合形成code gadget。然而此时存在漏洞的代码与不存在漏洞的代码提取结果是一致的,当模型的输入不发生改变时,其输出也不会发生改变,这也就意味着当模型对这些代码进行分类时,其准确率是不会改变的。
Solution
为了解决上述的问题,作者从两个方向出发:
- 改变对代码的预处理方式。目前的处理方法对于语句间的控制依赖处理过于粗糙,且并未指明语句对应的路径。并且在代码片重组的过程中存在暴力堆叠的问题,使不在同一控制范围内的语句彼此直接相邻,从而导致了路径不敏感。一种解决策略是标识每个控制语句的控制范围。
在此基础上作者给出了path-sensitive code gadget的定义:
- path-sensitive code gadget:给定程序 , 且语句 由个special token组成, , code gadget 则是通过这些特殊记号递归生成的具有语义信息(存在数据依赖与控制依赖)的复数有序语句或特殊记号所处的控制条件下的控制范围语句。
- 在此前的工作中更多是选择RNN作为漏洞识别模型,因为其能识别上下文并对文本进行分类。但是在RNN中token的长度必须被预定义且为定长,其所采用的处理方式也较为暴力(截断和填充),这也导致对代码语义产生了影响,因此作者针对网络结构设计进行优化,使其得以处理变长的code gadget。
Design of SEVulDet
下图展示了SEVulDet的训练阶段与检测阶段,训练阶段相较于检测阶段多了打标签这一环节。整体上可分为两个步骤:(1)从源代码中提取必需的语法语义至路径敏感的 code gadget;(2)使用模型学习潜在的漏洞模式。
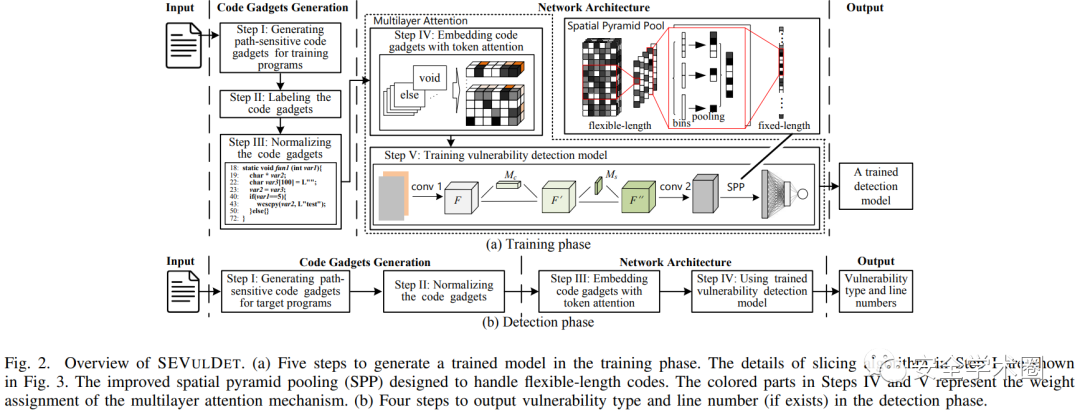
Path-sensitive Code Gadgets Generation
code gadget 的生成大体分为如下几个步骤:
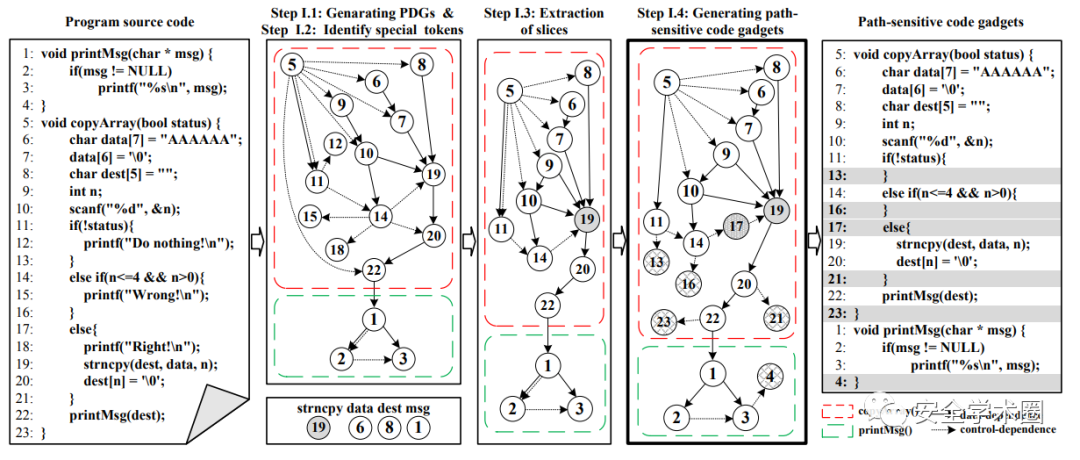
- 生成PDG,图中的虚线与实线分别表示控制依赖与数据依赖。
- 识别special tokens,此处作者定义的special token包括库/API函数调用,数组使用,指针使用。在图中的例子作者提取出了strncpy,data,dest以及prinMsg。
- 接着分别通过前序分析获取special token所在语句的后继statemen,后序分析获取special token所在语句的前驱statement,而不存在这种关系的statement(12,15,18)则被移除。
- 最后则是补充上路径信息。为了识别所有的路径信息,作者通过语法树对关键节点(if,else if,else,for,while,do while,switch and case)进行识别,然后确定其控制范围。例如 14-16 为else if的控制范围,17-21 是else的控制范围,如果没有正确声明控制范围,17-21则处在了else if的控制范围。因此作者通过为PDG添加相应的叶子节点使其能够确定控制范围,避免了语义的缺失。
Network Architecture Design
作者在CNN中设计了多层注意力机制与一个空间金字塔池化层,后者消除了RNN中对于code gadget预定义长度的限制。
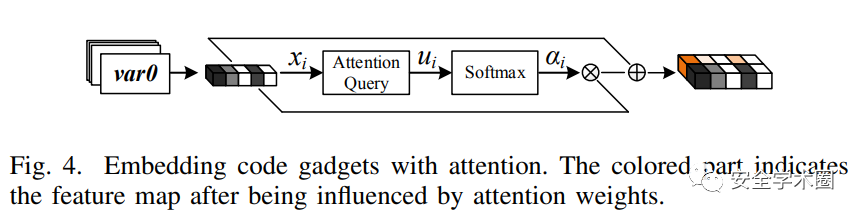
Embedding code gadgets with token attention
作者首先使用word2vec将token进行向量化,然后设计token注意力来学习哪些token是对检测有帮助的。
Trainning vulnerability detection model
在多层注意力机制的第二部分作者采用了[3]的Channel Attention和Spatial Attention,并将二者进行了串联。然后便是采用了空间金字塔池化层进行变长优化。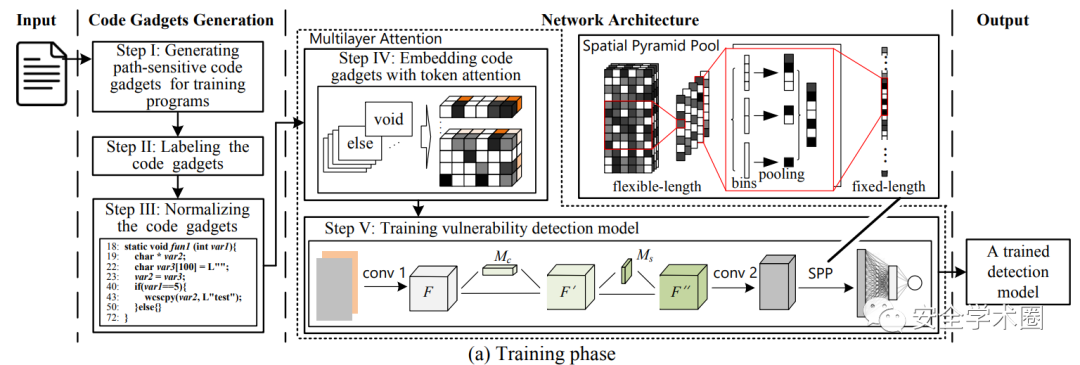
Evaluation
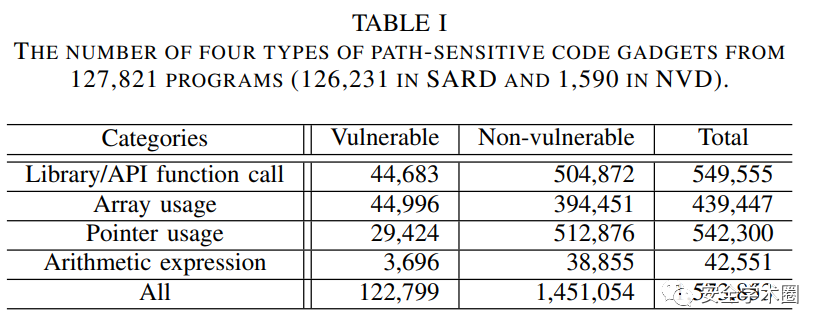
作者在验证时采用了两组通用的数据集Software Assurance
Reference Dataset (SARD)和Nation Vulnerability Dataset
(NVD)。
作者设计以下研究问题并作出了解答:
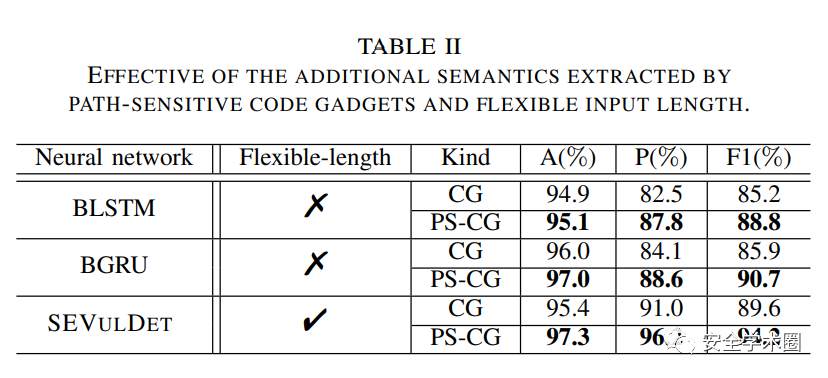
- 变长路径敏感code gadget带来的额外语义信息是否对于漏洞识别有帮助?
- 作者采用了定长的网络结构进行对比,并且设置了不同的条件:(1)仅提取数据与控制依赖的code gadget——CG;(2)在CG的基础上加上了路径语义——PS-CG。
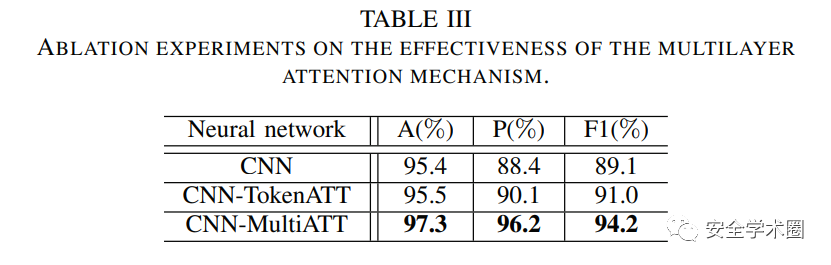
- 多层注意力机制是否使得SEVulDet更加有效?
- 与最先进的漏洞检测框架相比,SEVulDet的效果如何?
- 与经典的静态漏洞识别框架相比:
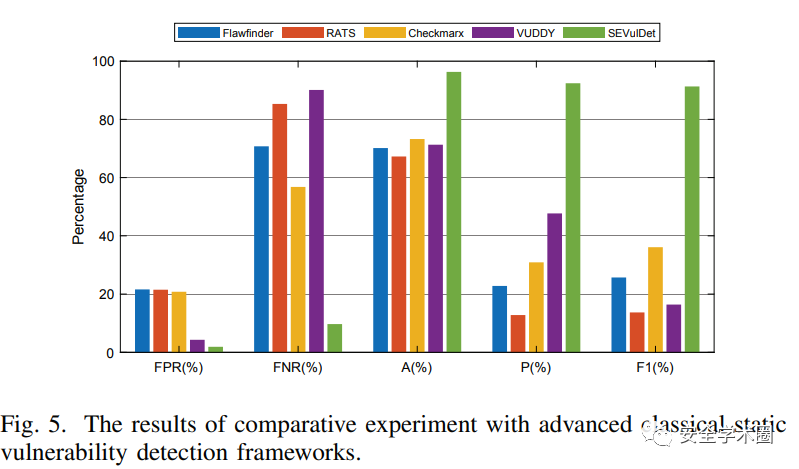
- 与其他深度学习漏洞识别框架相比:
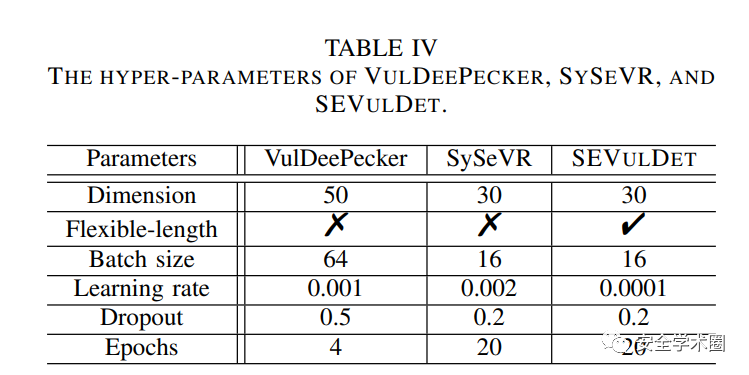
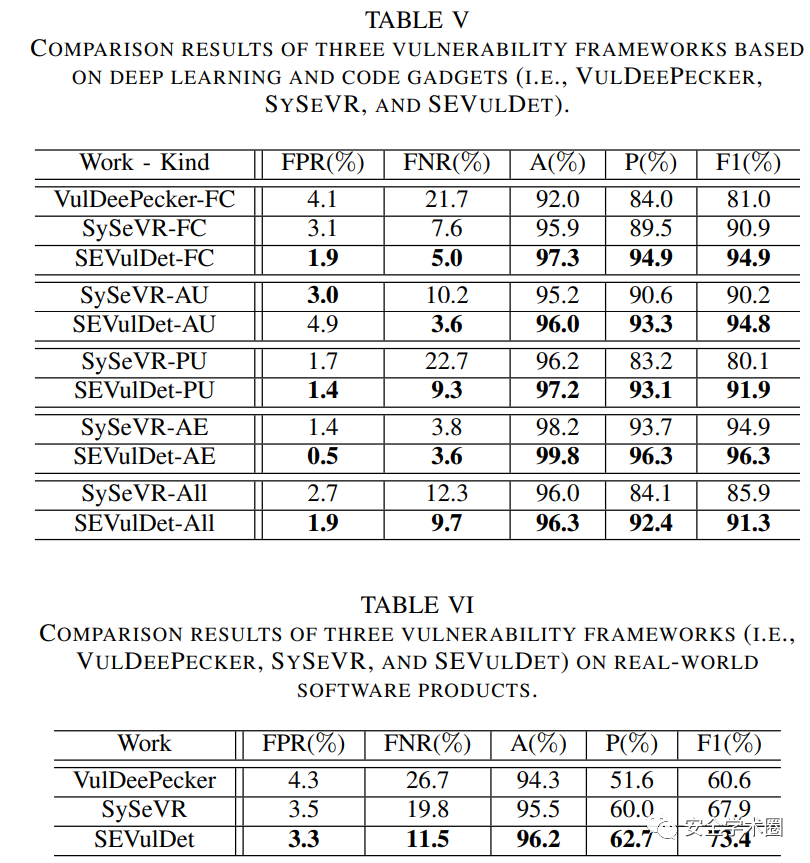
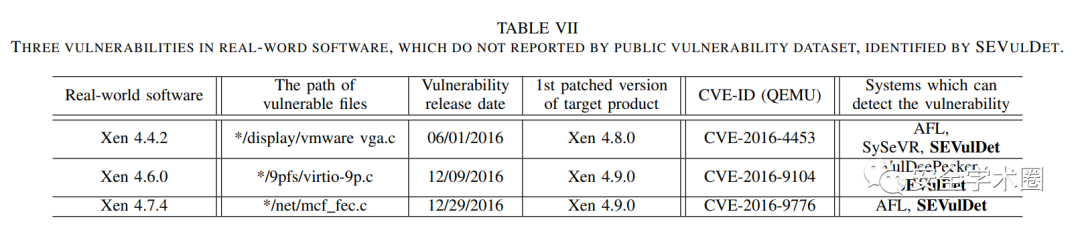
- 在真实世界的软件产品上测试:
- 变长路径敏感code gadget与多层注意力机制使得SEVulDet发现更多漏洞的原因是什么?
- 在这部分,作者选取了一个未报告过的漏洞作为例子,该漏洞导致的死循环可以被路径敏感code gadget所捕获,避免了语义信息的损失,并展示了由注意力机制计算所得的token权重,验证了SEVulNet确实从code gadget中学习到了潜在的漏洞模式。

