防封ip解决方案之ip代理池
本项目其实就是个简单的代理服务器,经过我小小的修改。加了个代理池进来。渗透、爬虫的时候很容易就会把自己ip给ban了,所以就需要ip代理池了。
ProxyPool 爬虫代理IP池
______ ______ _
| ___ \_ | ___ \ | |
| |_/ / \__ __ __ _ __ _ | |_/ /___ ___ | |
| __/| _// _ \ \ \/ /| | | || __// _ \ / _ \ | |
| | | | | (_) | > < \ |_| || | | (_) | (_) || |___
\_| |_| \___/ /_/\_\ \__ |\_| \___/ \___/ \_____\
__ / /
/___ /
ProxyPool
爬虫代理IP池项目,主要功能为定时采集网上发布的免费代理验证入库,定时验证入库的代理保证代理的可用性,提供API和CLI两种使用方式。同时你也可以扩展代理源以增加代理池IP的质量和数量。
- 文档: https://proxy-pool.readthedocs.io/zh/latest/
- 支持版本:


- 测试地址: http://demo.spiderpy.cn (勿压谢谢)
- 付费代理推荐: luminati-china. 国外的亮数据BrightData(以前叫luminati)被认为是代理市场领导者,覆盖全球的7200万IP,大部分是真人住宅IP,成功率扛扛的。付费套餐多种,需要高质量代理IP的可以注册后联系中文客服,开通后有5美金赠送和教程指引(PS:用不明白的同学可以参考这个使用教程)。
运行项目
下载代码:
- git clone
git clone git@github.com:jhao104/proxy_pool.git
- releases
https://github.com/jhao104/proxy_pool/releases 下载对应zip文件
安装依赖:
pip install -r requirements.txt
更新配置:
# setting.py 为项目配置文件# 配置API服务HOST = "0.0.0.0" # IPPORT = 5000 # 监听端口# 配置数据库DB_CONN = 'redis://:pwd@127.0.0.1:8888/0'# 配置 ProxyFetcherPROXY_FETCHER = [ "freeProxy01", # 这里是启用的代理抓取方法名,所有fetch方法位于fetcher/proxyFetcher.py
"freeProxy02", # ....]
启动项目:
# 如果已经具备运行条件, 可用通过proxyPool.py启动。# 程序分为: schedule 调度程序 和 server Api服务# 启动调度程序python proxyPool.py schedule# 启动webApi服务python proxyPool.py server
Docker Image
docker pull jhao104/proxy_pool docker run --env DB_CONN=redis://:password@ip:port/0 -p 5010:5010 jhao104/proxy_pool:latest
docker-compose
项目目录下运行:
docker-compose up -d
使用
- Api
启动web服务后, 默认配置下会开启 http://127.0.0.1:5010 的api接口服务:
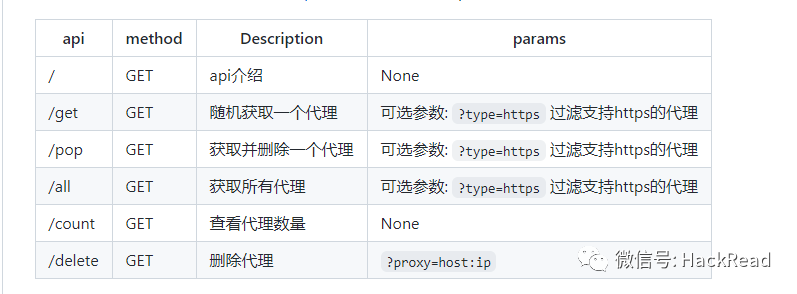
- 爬虫使用
如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:
import requestsdef get_proxy(): return requests.get("http://127.0.0.1:5010/get/").json()def delete_proxy(proxy): requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))# your spider codedef getHtml(): # ....
retry_count = 5
proxy = get_proxy().get("proxy") while retry_count > 0: try: html = requests.get('http://www.example.com', proxies={"http": "http://{}".format(proxy)}) # 使用代理访问
return html
except Exception: retry_count -= 1
# 删除代理池中代理
delete_proxy(proxy) return None
扩展代理
项目默认包含几个免费的代理获取源,但是免费的毕竟质量有限,所以如果直接运行可能拿到的代理质量不理想。所以,提供了代理获取的扩展方法。
添加一个新的代理源方法如下:
- 1、首先在ProxyFetcher类中添加自定义的获取代理的静态方法, 该方法需要以生成器(yield)形式返回host:ip格式的代理,例如:
class ProxyFetcher(object): # ....
# 自定义代理源获取方法
@staticmethod
def freeProxyCustom1(): # 命名不和已有重复即可
# 通过某网站或者某接口或某数据库获取代理
# 假设你已经拿到了一个代理列表
proxies = ["x.x.x.x:3128", "x.x.x.x:80"] for proxy in proxies: yield proxy
# 确保每个proxy都是 host:ip正确的格式返回
- 2、添加好方法后,修改setting.py文件中的PROXY_FETCHER项:
在PROXY_FETCHER下添加自定义方法的名字:
PROXY_FETCHER = [ "freeProxy01",
"freeProxy02", # ....
"freeProxyCustom1" # # 确保名字和你添加方法名字一致]
schedule 进程会每隔一段时间抓取一次代理,下次抓取时会自动识别调用你定义的方法。
免费代理源
目前实现的采集免费代理网站有(排名不分先后, 下面仅是对其发布的免费代理情况, 付费代理测评可以参考https://zhuanlan.zhihu.com/p/33576641):
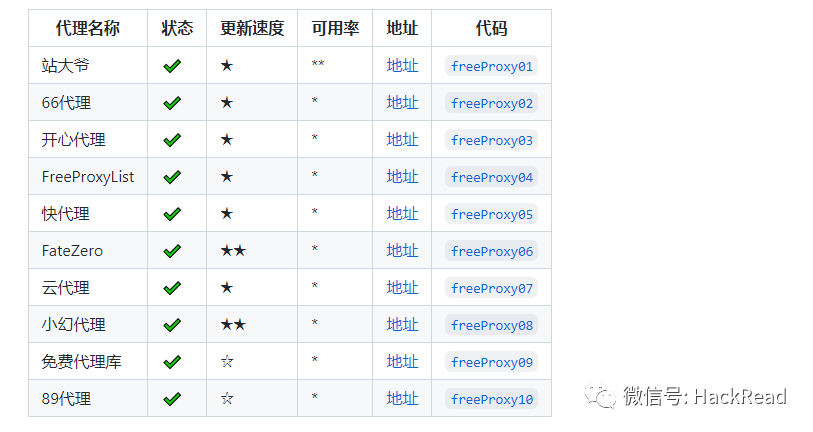
(具体地址可看项目地址)
项目地址
https://github.com/jhao104/proxy_pool
本项目其实就是个简单的代理服务器,经过我小小的修改。加了个代理池进来。渗透、爬虫的时候很容易就会把自己ip给ban了,所以就需要ip代理池了。
ProxyPool 爬虫代理IP池
______ ______ _
| ___ \_ | ___ \ | |
| |_/ / \__ __ __ _ __ _ | |_/ /___ ___ | |
| __/| _// _ \ \ \/ /| | | || __// _ \ / _ \ | |
| | | | | (_) | > < \ |_| || | | (_) | (_) || |___
\_| |_| \___/ /_/\_\ \__ |\_| \___/ \___/ \_____\
__ / /
/___ /
ProxyPool
爬虫代理IP池项目,主要功能为定时采集网上发布的免费代理验证入库,定时验证入库的代理保证代理的可用性,提供API和CLI两种使用方式。同时你也可以扩展代理源以增加代理池IP的质量和数量。
- 文档: https://proxy-pool.readthedocs.io/zh/latest/
- 支持版本:
- 测试地址: http://demo.spiderpy.cn (勿压谢谢)
- 付费代理推荐: luminati-china. 国外的亮数据BrightData(以前叫luminati)被认为是代理市场领导者,覆盖全球的7200万IP,大部分是真人住宅IP,成功率扛扛的。付费套餐多种,需要高质量代理IP的可以注册后联系中文客服,开通后有5美金赠送和教程指引(PS:用不明白的同学可以参考这个使用教程)。
运行项目
下载代码:
- git clone
git clone git@github.com:jhao104/proxy_pool.git
- releases
https://github.com/jhao104/proxy_pool/releases 下载对应zip文件
安装依赖:
pip install -r requirements.txt
更新配置:
# setting.py 为项目配置文件# 配置API服务HOST = "0.0.0.0" # IPPORT = 5000 # 监听端口# 配置数据库DB_CONN = 'redis://:pwd@127.0.0.1:8888/0'# 配置 ProxyFetcherPROXY_FETCHER = [ "freeProxy01", # 这里是启用的代理抓取方法名,所有fetch方法位于fetcher/proxyFetcher.py
"freeProxy02", # ....]
启动项目:
# 如果已经具备运行条件, 可用通过proxyPool.py启动。# 程序分为: schedule 调度程序 和 server Api服务# 启动调度程序python proxyPool.py schedule# 启动webApi服务python proxyPool.py server
Docker Image
docker pull jhao104/proxy_pool docker run --env DB_CONN=redis://:password@ip:port/0 -p 5010:5010 jhao104/proxy_pool:latest
docker-compose
项目目录下运行:
docker-compose up -d
使用
- Api
启动web服务后, 默认配置下会开启 http://127.0.0.1:5010 的api接口服务:
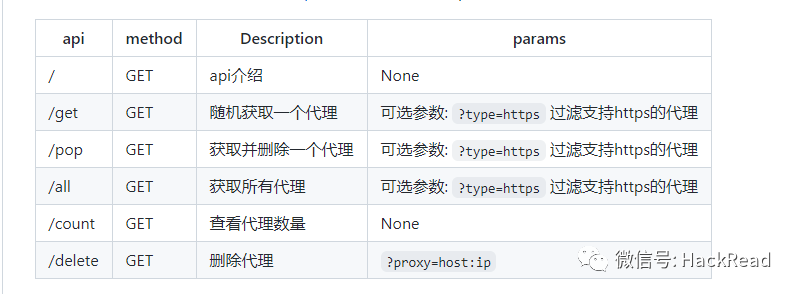
- 爬虫使用
如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:
import requestsdef get_proxy(): return requests.get("http://127.0.0.1:5010/get/").json()def delete_proxy(proxy): requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))# your spider codedef getHtml(): # ....
retry_count = 5
proxy = get_proxy().get("proxy") while retry_count > 0: try: html = requests.get('http://www.example.com', proxies={"http": "http://{}".format(proxy)}) # 使用代理访问
return html
except Exception: retry_count -= 1
# 删除代理池中代理
delete_proxy(proxy) return None
扩展代理
项目默认包含几个免费的代理获取源,但是免费的毕竟质量有限,所以如果直接运行可能拿到的代理质量不理想。所以,提供了代理获取的扩展方法。
添加一个新的代理源方法如下:
- 1、首先在ProxyFetcher类中添加自定义的获取代理的静态方法, 该方法需要以生成器(yield)形式返回host:ip格式的代理,例如:
class ProxyFetcher(object): # ....
# 自定义代理源获取方法
@staticmethod
def freeProxyCustom1(): # 命名不和已有重复即可
# 通过某网站或者某接口或某数据库获取代理
# 假设你已经拿到了一个代理列表
proxies = ["x.x.x.x:3128", "x.x.x.x:80"] for proxy in proxies: yield proxy
# 确保每个proxy都是 host:ip正确的格式返回
- 2、添加好方法后,修改setting.py文件中的PROXY_FETCHER项:
在PROXY_FETCHER下添加自定义方法的名字:
PROXY_FETCHER = [ "freeProxy01",
"freeProxy02", # ....
"freeProxyCustom1" # # 确保名字和你添加方法名字一致]
schedule 进程会每隔一段时间抓取一次代理,下次抓取时会自动识别调用你定义的方法。
免费代理源
目前实现的采集免费代理网站有(排名不分先后, 下面仅是对其发布的免费代理情况, 付费代理测评可以参考https://zhuanlan.zhihu.com/p/33576641):
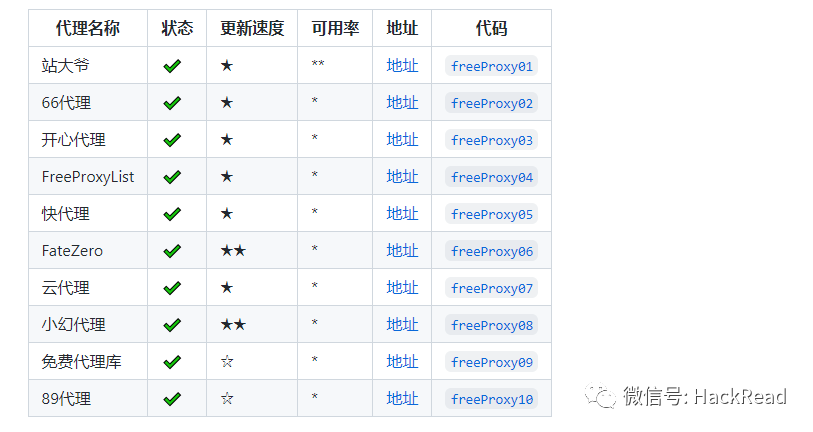
(具体地址可看项目地址)
项目地址
https://github.com/jhao104/proxy_pool
如有侵权,请联系删
