TRACER:基于签名的静态漏洞检测方法|技术进展
一、 引言
在不同的程序中,类似的漏洞会反复出现,原因之一是对代码的重用,这导致重用代码中安全漏洞的传播;除此以外还有因为开发人员在实现相同的标准概念(如数学公式、物理定律、协议或语言解释器)时经常犯类似的错误或是由于编程语言复杂的底层语义导致的常见误解,使得语义上相似的漏洞经常在独立开发的不相关代码库中重复出现。
尽管研究人员已经开发出许多成功的技术来检测重复出现的安全漏洞,但现有的方法在几个方面存在局限性。基于代码相似度的方法旨在通过代码重用来检测重复漏洞。它们在预定义的边界(例如,文件或函数)内生成已知漏洞的签名,并将新程序中的语法模式与签名进行比较。这些方法是高度精确的、可扩展的和通用的,因为它们的方法是基于语法匹配的。但它们通常无法检测出语法结构完全不同但根源相同的已知漏洞的变体。另一类基于模式的静态分析会评估目标程序的语义,并考虑它们的语法模式,这使得分析器能够检测具有与已知漏洞的程序相似的语法和语义特征的漏洞。但是设计这样的分析需要静态分析的专业知识,并且会带来不小的工程负担。
因此作者提出了Tracer,它以一般的污点分析为基础,针对各种安全漏洞,如整数溢出、下溢、格式字符串、缓冲区溢出、命令注入等。在具有已知漏洞的代码库上运行静态分析器,分析器会检测从不受信任的输入(source)到安全敏感函数(sink)的潜在易受攻击的数据流,并在分析结果中识别实际的漏洞。然后提取漏洞从source到sink的数据依赖关系的轨迹。这些轨迹被编码为特征向量,形成漏洞的签名。一旦分析了一个新程序,Tracer提取程序中所有报告的警报的痕迹,并以相同的方式得到它们的特征向量,然后使用余弦相似性将警报的特征向量与已知易受攻击的轨迹的特征向量进行比较,最后提供了一个按相似性排序的警报列表。
二、 概述
Tracer的基本框架如下图,主要分为三个部分:
01通过静态分析获取潜在漏洞的轨迹
02从轨迹中提取特征向量
03已知漏洞的程序提取的向量将作为前面直接存储在数据库中,测试程序提取的向量会与数据库中的向量进行相似度检测
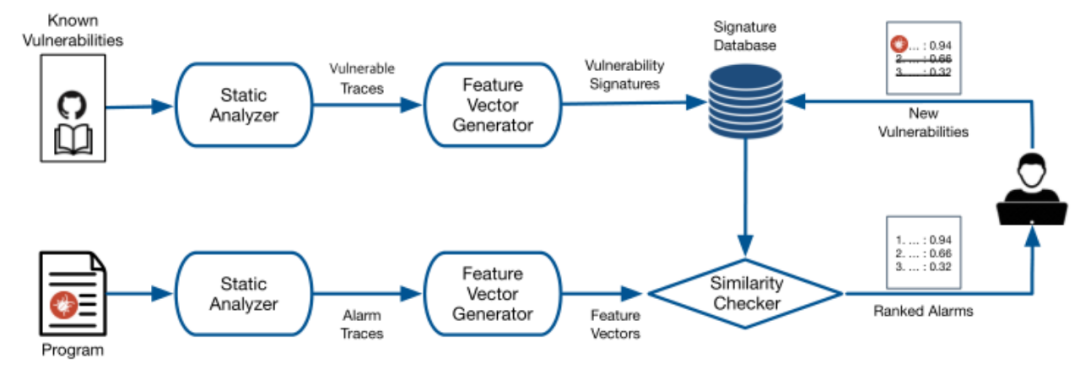
图1 Tracer总体框架
三、详细流程
1. 污点分析
Tracer基于通用的污点分析,计算从不可信的输入(source)到敏感函数(sink)的潜在数据流,这些数据流带有一个简单抽象域:T ={⊥t,⊤t},用来表示值没有被污染(⊥t)或是可能被污染(⊤t)。
为了更准确地分析,对于过污染overflow和欠污染underflow等情况,Tracer增加其他的抽象域来进行更详细分析。例如针对overflow,使用一个简单的抽象域I ={⊥o,⊤o}来估计一个整数值是否有可能溢出,一个不可信的输入值最初是被污染的(⊤t),但不会溢出(⊥o)。一旦该值被用作可能引入整数溢出(例如,+、<<)的操作符的操作数,结果就会变为被污染(⊤t)和溢出(⊤o),对于malloc的情况,分析器只在抽象值同时被污染(⊤t)和溢出(⊤o)的时候发出警报,这样可以在有效地计算恶意数据流的同时避免报告假警报。
在这一阶段会得出一个警报集合,每个警报有两个元素,c2为程序中的敏感函数(sink),c1为会影响到c2的不可信输入(source)。
2. 从数据依赖图提取轨迹
在污点分析获得程序中潜在恶意流后,Tracer会提取程序的数据依赖关系图,并根据每个警报的信息提取易受攻击的轨迹,如图2所示,轨迹包含了不受信任的数据从被读入到被函数使用过程中所有的语句。

图2 数据依赖图示例
3. 特征表示
接着Tracer会将每个轨迹编码成为整数特征向量,特征向量由两部分组成:低级特征和高级特征。低级特征表示轨迹中基本操作符,比如*、<<等,还有常用的API,比如strlen等,这部分会根据特征出现的频率形成向量,例如图2(a)中的轨迹最后会得到向量<1,3,3,2,1,1,1,1>。此外还有5种高级特征来描述轨迹的详细行为,用来判断轨迹中是否出现了大于、大于等于、小于、小于等于、等于、不等于、等于百分比等表达式,假设在目标程序的轨迹中存在这样的表达式,但在签名轨迹中不存在,则会认为目标轨迹是安全的,相似度得分降低。

图3 特征设计
4. 相似度检查
相似度检查会使用余弦相似度来计算程序提取的所有向量与数据库中的所有签名向量之间的相似性,得出相似性排名。例如图2中提取出的两个向量相似性结果为
(<1,3,3,2,1,1,1,1>·<1,3,3,2,1,0,0,1>)/(ǁ<1,3,3,2,1,1,1,1>ǁǁ<1,3,3,2,1,0,0,1>ǁ)=0.96.
四、实验
论文设计了以下几个问题:
RQ1: Tracer能否有效发现未知的重复漏洞?
RQ2: 与现有方法相比,Tracer的准确性如何?
RQ3: Tracer的高级特征是否有效?
RQ4: Tracer对大型程序的可扩展性如何?
1. 实验设置
作者在Facebook的Infer分析器上实现了Tracer,使用由Infer的缓冲区溢出检查器计算的指针信息。遵循Infer的框架,将污点分析设计成一个模块化的过程间分析。污点分析检查第4节中描述的五个常见漏洞:整数溢出、整数下溢、缓冲区溢出、命令注入和格式字符串错误。
用于当作签名的程序有3个来源:(1)真实世界的漏洞:从CVE报告和之前的工作中收集了16个漏洞。(2)Juliet测试套件:由大量的小程序集组成,每个集里的小程序都有一个共同的漏洞,总共使用了5383个程序。(3)网络教程:从OWASP提供的安全编程在线教程中收集了5个示例。用于检测的程序使用了273个用C/C++编写的Debian软件包。
对比工具则选用了VUDDY[1], CCAligner[2],Devign[3]和CodeQL[4]。
2. RQ1: 有效性
作者手动检查了所有相似度大于0.85的警报,在67个软件包中发现了112个新漏洞,截至写文章时,发开人员已经确认了30个漏洞,分配了6个CVE。漏洞如表1所示。
表1 Tracer检测到的新漏洞列表
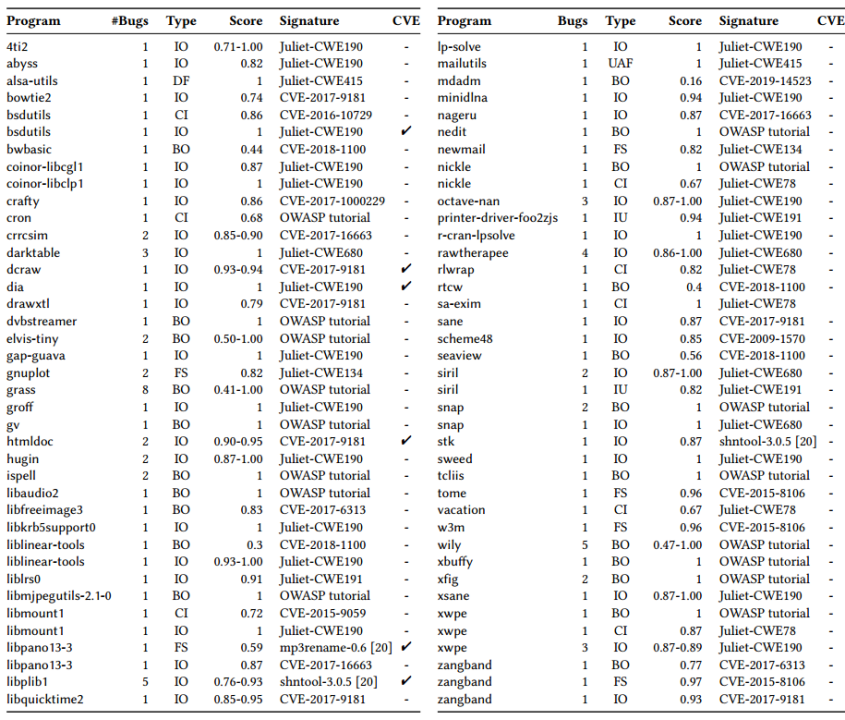
表 2 各个工具对比
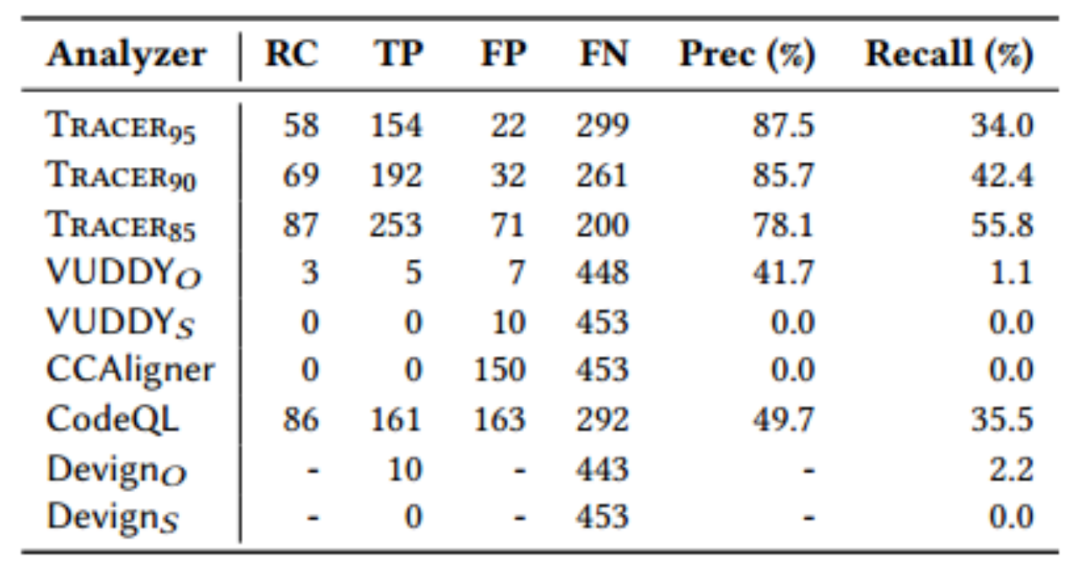
表2前三行显示,大多数真正例在报告中排名很高。底层静态分析报告1,975个警报,其中只有176个警报的得分高于0.95 (Tracer95)。其中真正例154个(87.5%)。如果将阈值分别设置为0.9 (Tracer90)和0.85 (Tracer85),则真正例率仍然很高(85.7%和78.1%)。Tracer基于相似性的评分有效地过滤掉了大量误报,同时保留了许多真正的bug。实验结果表明,该方法能够有效地检测出语义上重复出现的漏洞。特别是,由静态分析提供支持的基于轨迹的相似性度量对语法变体具有鲁棒性。因此,即使两个程序具有明显不同的语法特征,Tracer也可以报告具有高相似性得分的重复漏洞。
3. RQ2: 比较
(一)与VUDDY和CCAligner比较,如表2所示,VUDDYO报告的12个警报中有7个误报,报告了5个函数克隆问题,其中检测出了3个漏洞。VUDDYS报告了10个假警报,CCAligner报告了150个函数克隆,但没有检测到任何漏洞。由于CCAligner不是设计来查找漏洞的,因此一些不具有安全敏感调用的函数也会被报告。VUDDY和CCAligner都无法检测到大多数由Tracer检测到的重复漏洞。这主要是因为它们基于函数级粒度的语法相似性度量。然而,Tracer检测到的漏洞大多涉及多个函数,并且语法结构与签名有很大不同。现实世界程序中的这些特征阻碍了这些工具检测语义上反复出现的漏洞。
(二)与CodeQL比较,CodeQL报告了来自基准程序的3,488个警报。作者检查了其中324个警报,Tracer可以有效地检测到CodeQL遗漏的重复漏洞,CodeQL报告了161个真警报(35.5%),而Tracer85检测到253个真警报(55.8%),但是都没有检测到常见的漏洞,原因可能有三点:bug可以通过底层分析和CodeQL检测出来,但是Tracer会过滤掉它们,因为在签名数据库中没有类似的轨迹;只有CodeQL可以检测到bug,但由于作者执行的不健全,底层分析遗漏了bug,特别是作者只实现了在他们的签名数据库中观察到的外部库(例如,read, getenv)的语义而CodeQL支持更广泛的库模型;只有我们的分析才能检测到bug,但CodeQL无法检测到,作者推测,这主要是因为它们作为通常的静态bug检测器的设计选择不合理。在被检查的324个警报中,CodeQL报告163个假正例(50.3%),而Tracer85报告71个(21.9%)。
(三)与Devign比较,作者将Devign实例化为两种设置:DevignO使用作者提供的训练数据进行训练;DevignS使用签名库中的函数进行训练。我们抽取了10000个易受攻击的函数和10000个非易受攻击的函数来训练DevignS。DevignO只检测到了10个漏洞,而DevugnS没有报告任何漏洞,并且在这10次警报中,有8次Tracer85也检测到了。
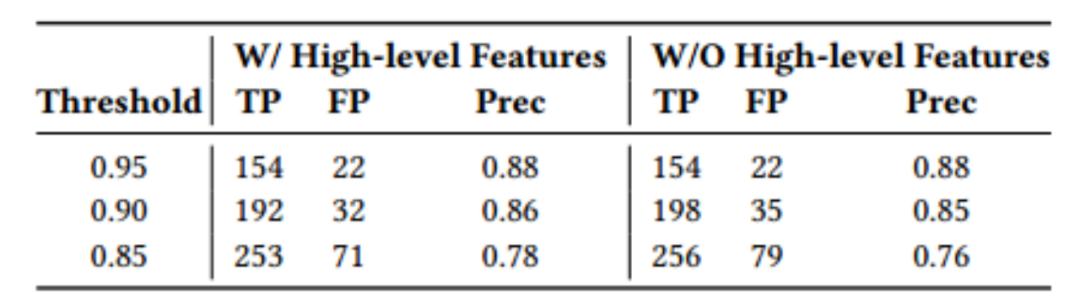
4. RQ3: 高级特征的影响
如表3所示,Tracer的性能从根本上不受高级特征选择的限制。当高级特征被禁用时,阈值为0.95的Tracer仍然报告相同的一组警报。但是高级特征能帮助较低阈值的Tracer有效地过滤掉假警报。当使用高级特征时,阈值为0.85和0.90的Tracer报告的假正例减少10.1%和8.6%,同时保留了所有的真警报。
表3 使用不同特征的Tracer准确率
5. RQ4: 可扩展性
作者测量了每个基准的静态分析和相似度检查的总计算时间。结果表明,Tracer可扩展到大型程序,对于每个包,静态分析平均需要140.42秒。特征向量构建和相似度计算的时间最多为2.71秒,与整个过程相比可以忽略不计,尽管大多数包的分析在20分钟内完成,但有些包的分析时间要比平均时间长得多。例如hugin大约需要53分钟,这主要是因为函数指针解析的不精确,导致通过虚假的间接调用分析过多的函数。另一个例外的例子是gettext,它只需要91秒,而它包含982K行代码。尽管代码规模巨大,但程序是由大量小型库函数组成。因此,模块化分析可以高度并行化。
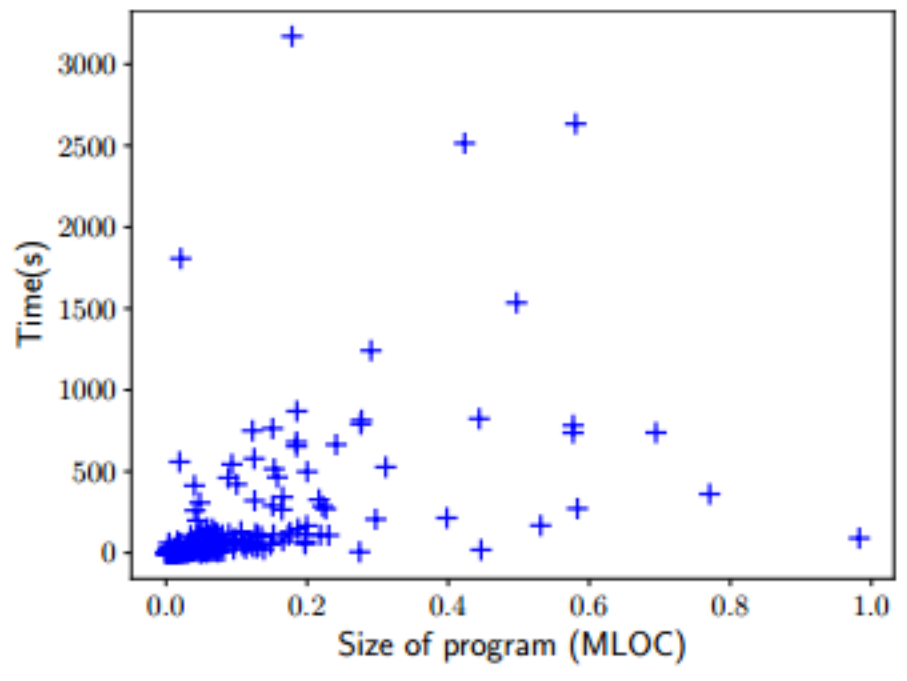
图4 Tracer在不同大小程序下的运行时间
五、 总结
文章提出了Tracer,一个用于检测语义上重复出现的漏洞的框架。Tracer基于静态分析,可以发现目标程序中潜在的易受攻击的轨迹,然后将每个候选轨迹与从各种来源收集的已知漏洞进行比较。作者的实证研究表明,Tracer可以准确地从各种开源程序中检测到语义相似的漏洞,作者预计Tracer将允许开发人员在不需要静态分析专业知识的情况下轻松地防止重复出现的漏洞。
