MTR和ping自相矛盾,听谁的?
这个可以看到,我MTR测试百度,然后我本地网关就lost 16%
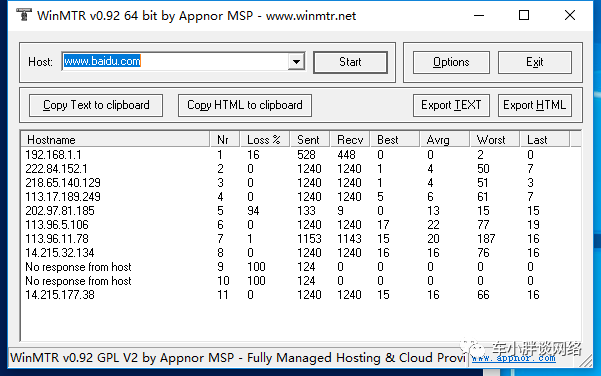
那么从图可以判断,我本地网出去就有点小问题,那么图中 202.97.81.158丢包率打到了可怕的 94% OK
从图中可以判断到百度的IP是 14.215.177.38 我用ping命令来评测看看
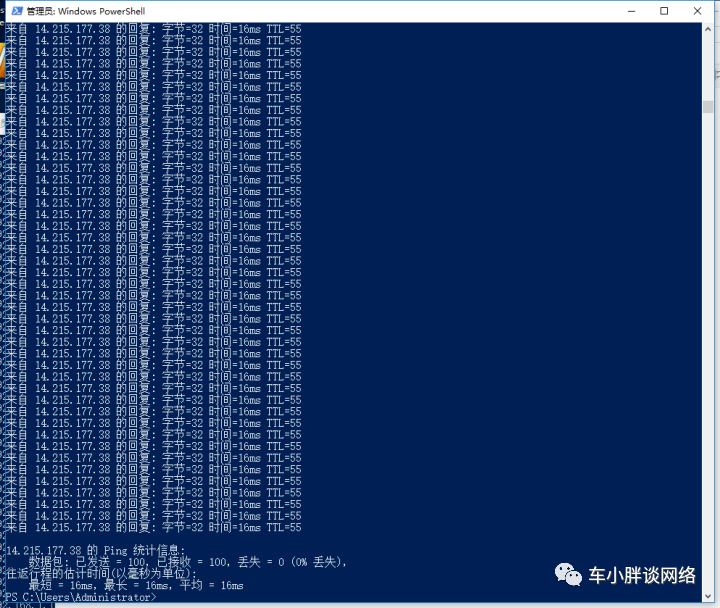
又没有问题,完全没有丢包,这个又怎么解释呢?
谁的拳头大听谁的,Ping的拳头大,以Ping的结果为准。准确地说,Ping的结果也不是很可靠,往往提供的虚假的表面信息,并不是真实的网络状况,仅供真实网络拥堵状况的参考,而不能当作唯一的度量值。
而要透过表面现象看本质,题主需要透彻理解以下三个知识点:
- Ping的工作原理 (ICMP Echo Request/Reply)
- MTR的工作原理 (ICMP TTL Expired Notification )
- CoPP (Control Plane Protection)
上文说了,Ping的拳头(可信度)大,所以MTR与Ping自相矛盾时,以Ping为准,即题主的主机到baidu服务器的网络没有任何问题。否则为何Ping都通了,丢包率=0%?
可是,为何MTR在第一跳(192.168.1.1)有16%的丢包率?
第一个问题:你的Ping 14.215.177.38经没经过第一跳(192.168.1.1)?肯定经过的吧,不可能飞毛腿过去。既然经过第一跳(192.168.1.1),第一跳丢没丢 “Ping 14.215.177.3“报文?肯定没丢,否则丢包率不可能=0%,对吗?
第二个问题:“Ping 14.215.177.3“报文途径第一跳(192.168.1.1)时,是第一跳(192.168.1.1)的硬件(芯片)转发,还是软件(CPU)转发?
硬件转发,几乎无需CPU的介入,所以对CPU的影响可以忽略不计。
第三个问题:“MTR
14.215.177.3“报文途径第一跳(192.168.1.1)时,为何报文的目的IP = 14.215.177.3,而不是第一跳(192.168.1.1),为何第一跳(192.168.1.1)要回复消息给题主的主机(192.168.1.x)?
因为第一跳(192.168.1.1)收到了TTL=1 的Ping 14.215.177.3,第一跳需要做TTL-1的操作。很显然TTL -1 = 1-1=0,故第一跳(192.168.1.1)需要将这个Ping包丢弃处理,同时使用ICMP TTL Expired Error Code发消息通知源主机(192.168.1.x),源主机MTR收到这个出错消息,就可以跟踪第一跳(192.168.1.1)的时间统计、丢包统计等等了。
MTR可以同时发出TTL =1、2、3、4。。。 N 。。255 Ping报文,这样就可以跟踪第1跳、第2跳、第3跳。。。。第N跳的网络中继(三层Relay)设备了。
第四个问题:第一跳(192.168.1.1)处理并发出“ICMP TTL Expired Error Code“是硬件(芯片)处理,还是软件(CPU)处理?
CPU处理,这个处理逻辑较复杂,需要CPU处理,因为要产生一个ICMP TTL
Expired Error报文,这不是硬件芯片能够轻松胜任的。
第五个问题:如果第一跳(192.168.1.1)的CPU繁忙,无法在timeout(默认2秒)发出ICMP TTL
Expired Error报文,题主的MTR如何反应并呈现?
MTR就会认为第一跳丢包了,然后就是看到的丢包率16%。
第六个问题:第一跳(192.168.1.1)的CPU繁忙造成的ICMP TTL Expired Error丢包可以理解,可是也不会有16%那么夸张吧?
如果第一跳(192.168.1.1)不是因为繁忙,而是故意不发ICMP
TTL Expired Error,16%就很好理解了。那个第5跳的丢包率94%也容易理解了。
第七个问题:为何第一跳、第五跳故意不发ICMP TTL Expired Error报文?
因为配置了CoPP,这个CoPP听起来很抽象,其实就是为了保护路由器的CPU不过载(Overload)。因为发ICMP
TTL Expired Error报文会消耗CPU资源,为了保护CPU,可以减少ICMP TTL Expired Error报文发送频率。
路由器的CPU资源,主要用来处理管理平面(配置)、控制平面(路由协议等)。一旦CPU过载,会造成控制平面的(路由update)消息来不及处理而出问题。
最后,究竟MTR什么时候可以看出网络有问题?
如果MTR从第五跳之后的丢包率都 =100%,那么第五跳到第六跳之间的链路出问题了。而Ping无法准确得到这个结论。
如果MTR从第五跳开始,到最后一跳的丢包率都 =94%,说明第四跳到第五跳之间可能有问题。这两者之间可能有16条等价路径(ECMP),其中只有一条路径是通的,其它的15条路径都是断开的,只有1/16 = 6%的MTR报文到达第5跳。
当然在真实的网络里。一般不可能有16条ECMP,但是如果有4条ECMP,上文的丢包率不是94%而是25%,那么就大约可以推断4个ECMP中的一条断了,因为1/4 = 25%。
