基于覆盖率的Fuzzer和AFL
一 Fuzzer的类型
模糊测试器的分类方法方式有好几种,本文将着重介绍基于覆盖率的模糊测试器,因此只详细介绍根据fuzzing策略的分类。基于fuzzing的策略,可将fuzzer分为基于定向的fuzzing和基于覆盖率的fuzzing。
对于基于覆盖率的模糊测试工具来说,往往需要使用恰当的种子测试目标程序,基于目标程序的反馈引导种子的变异生成更多恰当的测试用例,以引导测试覆盖尽可能多的代码路径。之所以用覆盖率这一个指标做为衡量,是因为在实践中人们发现更高的覆盖率往往能够找到更多的bug。
然而在实际场景中,一个项目中大部分代码都是不包含bug的,而且实际过程中,对于覆盖率模糊测试,仅靠依靠模糊测试器自己盲目测试是几乎不可能达到极高的覆盖率。定向模糊工具正是基于上诉原因应运而生。因此对于定向模糊测试工具而言,其目的旨在快速的测试特定的目标位置是否可能存在bug。(定向模糊测试工具并非本文的着眼点,因此将略过。)
二 基于覆盖率的Fuzzer
基于覆盖率的模糊测试策略是最先被完整应用的,在长时间的应用中十分可靠,高效且有效。对于基于代码覆盖率的Fuzzer来说,我们先讲一个重要的概念,代码覆盖率(Code Coverage),其次我们再介绍基于覆盖率的Fuzzer的一般工作流程,最后我们简单的介绍以下fuzzing另一个重要的概念种子语料库(Seed Corpus)。
代码覆盖率及度量方法
代码覆盖是软件测试中的一种度量,描述程序中源代码被测试的比例和程度,简单的说即测试目标代码的覆盖程度,所得比例称为**代码覆盖率。**代码覆盖率的度量方式主要有基本快覆盖、边覆盖率、条件覆盖率。
基本块(Basic Block)是具有单一入口和单一出口的代码片段,即一组顺序执行的指令。如下图,IDA中CFG图的代码块即是一种基本块。
一个基本块从其中第一条指令执行开始,直到执行到最后一条指令才结束(跳转到其他块)。也即,单一入口是指只能从基本块的第一条指令进入基本块,单一出口是指只能从基本块的最后一条指令跳转离开。
所谓基本块覆盖率即统计代码中基本块执行的情况,那些基本块执行了,那些没有执行。用执行了的基本块除于总的基本块即是基本块覆盖率。
边的概念也是依托于基本块的概念,基本块之间的跳转若用一条线画出来,这条线就叫做边。如下图所示。
所谓边覆盖率则是统计基本块之间的分支跳转的情况,也即统计那些边被执行了,那些边没有。相信诸位眼尖的可能发现了,边覆盖率能够覆盖相比于基本块覆盖率,虽然代码执行语句上似乎并无区别,但覆盖了更多的代码逻辑。
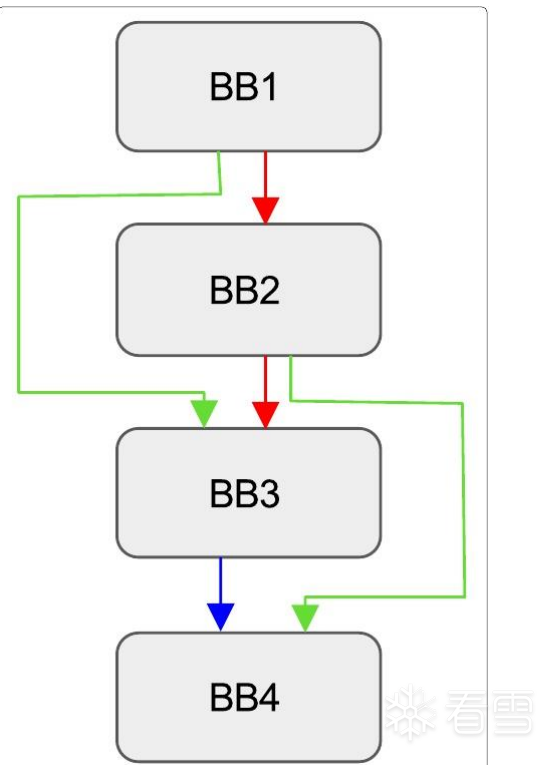
我们用一个例子来说明。如下图所示,有BB1、BB2、BB3和BB4,四个基本块。若执行路径BB1->BB2->BB3->BB4,则以基本块覆盖率来说,我们可以理所当然的说,覆盖率已经达100%了。
但是我们却发现代码中许多隐含的逻辑并未被测试出来。例如,我们走BB1->BB3->BB4和BB1->BB2->BB4,显然用基本块覆盖率来衡量自然是100%,但是却展示了一种全然不同的代码逻辑。
我们发现,若我们以边的执行程度来衡量,当所有的边被访问时,此时基本块覆盖率必然100%,并且还挖掘出许多隐含的代码逻辑,也是说,不但代码测的全还测的更加彻底。
一般工作流程
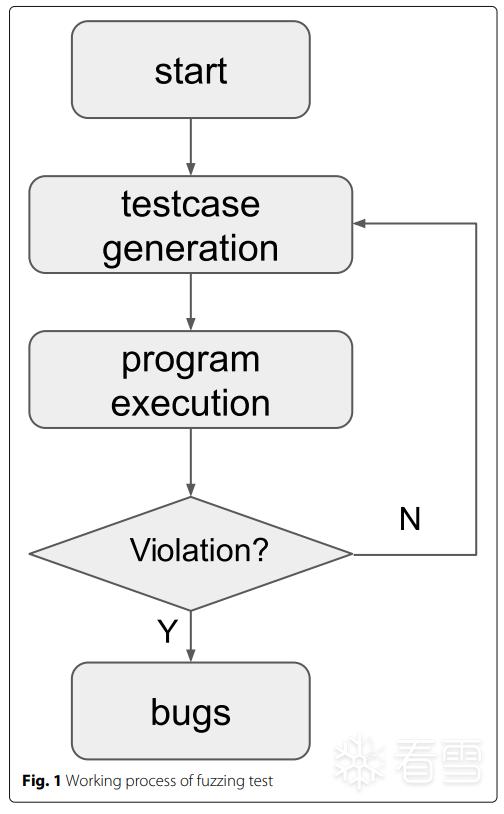
我们以《Fuzzing:a survey》给出的覆盖率Fuzzer的一般工作过程的伪代码做为例子来解读。
首先,我们需要输入一个初始种子S,若没有给定初始种子S,则模糊器自己将构造一个。
随后,从初始种子选择种子进行变异生成测试用例,测试程序,若测试的结果为crash则加入Crash输出集。若并未产生crash则模糊器判断该测试用例是否有价值、足够有趣,若答案是肯定的则加入种子集合,再后续的主循环中利用。直到模糊器收到终止信号,则退出循环,并将运行中收集到的crash集输出。

我们可以从这样一个流程中看到,模糊器无外乎做了两件事情,一是根据种子生成测试用例,二是根据测试用例测试程序并追踪程序的状态,如此循环往复。可以简单的兑换为以下的流程图。
种子语料库
我们在0x02章中,工作流程这个小节中发掘,种子库对于fuzzer来说是一个至关重要的环节,而在实践过程中也的确证实,好的种子库对于fuzzer结果的影响和执行效率都十分巨大。
对于基于覆盖率的fuzzer来说,种子语料库的质量显著的影响fuzzing的质量。良好的初始种子可以显著提高fuzzing的效率和效果。
具体来说,提供目标测试程序输入要求良好格式的种子,可以避免因大量无用的CPU消耗。良好的种子输入格式,可以避免模糊器在该阶段盲目的变异猜测。良好输入的格式的种子可以抵达更深和盲目变异难以抵达的路径。
此外,种子语料库的制作是也是一门重要的技能。
三 AFL
AFL是由Google工程师开发的一款基于引导覆盖的模糊测试器,可以用于白盒测试与黑盒测试。在Github上,Google官方的AFL项目对AFL的描述如下:
American Fuzzy Lop is a brute-force fuzzer coupled with an exceedingly simple but rock-solid instrumentation-guided genetic algorithm. It uses a modified form of edge coverage to effortlessly pick up subtle, local-scale changes to program control flow.
AFL工作流程
AFL的工作流程可以体现为下图。根据Google对AFL主要算法工作原理的总结,可以归纳为下面几点:
1.从用户获取初始种子,加载到种子池队列中。
2.从队列中获取一个种子文件,并且优先取得最小和最快的种子。
3.对取得的种子文件进行变异,生成一系列测试例子。
4.将一系列的测试例子,基于AFL的模糊测试策略进行测试和追踪。
5.对于有利于提高覆盖率的测试例子将被筛选为好的例子,加入到种子队列中,同时记录Crash。
6.go to 2。
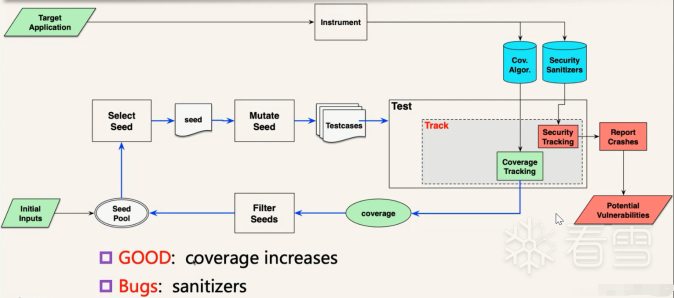
在AFL执行流程的每一步中,都有许多迫切的问题。例如,如何挑选种子、如何变异、如何测试、如何测量覆盖率等等,许多的问题都有行之有效的解决方法,但有效的人工干预仍然是一个好的选择。
再下面一节,我们将讨论再AFL中,对于上诉问题采取什么策略,是如何应对的。
AFL的工作原理
覆盖率度量与引导
AFL的覆盖率度量是一种混合度量,它将边覆盖率与在一次执行中相应边的次数相结合,并设置一个上限(一个2的幂次方),防止路径爆炸。
如果一个testcase访问到了一条新的边(edge),那么AFL则认为它是有趣的(GOOD),将加入到种子队列中。
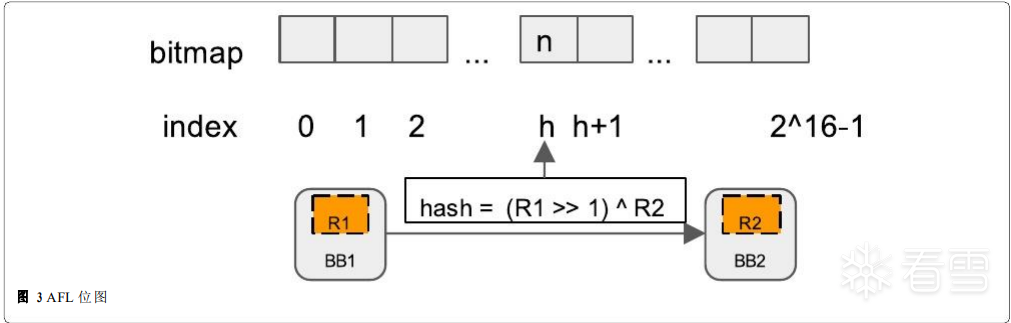
那么AFL又是如何记录已经访问的边呢?AFL是这样计算的。如下图所示,有两个基本块BB1和BB2,当发生从BB1到BB2的跳转时,即可认为BB1和BB2之间的边被访问。AFL在会在编译插桩阶段对基本块BB1和BB2分别插入一个标识R1和R2,根据这个R1和R2计算出一个哈希值,更新至位图中相应索引的字节。
上诉逻辑可以兑现为如下伪代码。
cur_location = shared_mem[cur_location ^ prev_location]++; pre_location = cur_location >> 1;
Seed Mutations
AFL的变异分为deterministic和havoc两种类型。其中deterministic对testcase的内容进行确定性的突变,如位翻转、加法、一些特定值的替换(-1、INT_MAX)等。
havoc模式中,突变将具有更大的不可确定性,如可能会调整testcase的内容(添加或删除部分内容)。
ForkServer
最初AFL对于每次fuzz都会建立一个虚拟进程空间,显而易见,频繁的进程创建对CPU来说是一个巨大的开销,对于fuzzing的效率不可忍受。
为了避免execve()的开销,AFL设计了一套Forkserver机制。每当AFL需要fuzz新的testcase时,AFL会重新写入testcase,然后告诉target fork自己。在这种情况下,AFL不需要每次都支付新进程初始化的开销,而是fork一次后不断在在第一次fork的进程中复用进程空间的资源,直到发生write时。
使用AFL进行fuzzing
优先推荐使用AFL的增强版本,AFL++。在比较新的Linux发行版上,大都可以通过一条命令安装AFL++,以Ubuntu为例子,执行以下命令即可。
sudo apt install afl
然而,更加简单快捷的使用完整的新版本AFL++,可以选择容器构建。具体的只需要执行如下命令即可。
docker pull aflplusplus/aflplusplus docker run -ti -v /location/of/your/target:/src aflplusplus/aflplusplus
具体的如何使用AFL进行fuzzing可以参考我的一篇文章,Fuzzing101-Exercise2 fuzz CVE-2009-3895和CVE-2012-2836 - 辰星-cxing - 博客园(https://www.cnblogs.com/cx1ng/p/17362871.html)
Fuzzer面临的挑战
fuzzer面临的挑战有许多,这里挑选了可以通过人工干预改进fuzzer效率和结果的几个问题。
第一个是关于变异种子的,有两个关键的问题,分别是在哪里变异、如何变异。因此只有少数关键位置上的恰当变异才会实质的影响程序的控制流。
第二个是关于验证。许多的程序中有各种各样的验证,诸如验证版本号、Magic值、特定字符串、特征值、输入格式等等。这个问题在黑盒测试过程中尤为重要,你不能期待fuzzer的盲目试探可以给你一个很好的结果,由于上诉验证的存在,盲目的变异将极大降低fuzzing的效率。
对于fuzzer的使用者来说,这两个问题实际上都指向一个问题,即如何制作一个行之有效的种子语料库,正确的意识到这两个问题对于我们制作特定程序高质量的种子库有十分巨大的帮助。
具体的,对于验证我们可以制作有通过验证与没有通过验证的种子,这样我们即可以测试验证代码又可以绕过验证代码继而测试更深处的代码,这将大幅提高fuzzing的效率。对于这种子变异问题,我们也可以人工干预,在某些我们感兴趣的位置制作一些指向目标代码区域的种子。
此外,除了制作种子之外,我们可以通过修改目标程序的一些代码,使fuzzing容易的略过一些我们不感兴趣或充分fuzzing的区域,使得fuzzing可以更加容易的深入,但需要注意。
