联邦学习面临的瓶颈与挑战
摘 要
联邦学习(Federated Learning,FL)是 Google 公司于 2016 年首次提出的概念,是一种在隐私约束下进行模型训练的机器学习训练范式。联邦学习具有无须客户端共享私有数据即可进行全局模型训练的特点,其在医疗、金融等需要严格保护用户私人信息的领域被广泛应用。虽然联邦学习因为可以保护用户的本地数据隐私而备受重视,但其也和其他机器学习架构一样面临着一些问题,并且容易受到黑客的攻击。将具体列举联邦学习所面临的瓶颈和安全问题,并介绍相应的防御机制,帮助联邦学习系统设计者更好地了解联邦学习的安全态势。
人工智能技术的广泛应用,显著推动了科技的发展与进步,但同时技术的安全性和用户的隐私安全也变得越来越重要。在大多数的机器学习架构中,来自不同组织或设备的数据被聚集在中央服务器或云平台中用来训练模型,用户隐私难以被保障。这对机器学习的广泛应用来说是一个严重的限制性因素,特别是当训练数据集包含敏感信息并因此构成安全威胁的时候。例如,为了开发核磁共振扫描的乳腺癌检测模型,不同的医院可以共享他们的数据来开发协作的机器学习模型。然而,向中央服务器共享患者的私有信息可能会向外界泄露敏感信息,从而产生消极的影响。在这种情况下,联邦学习可能是更好的选择。联邦学习是设备或组织之间的一种协作学习技术,其中来自客户端的本地模型的模型参数被共享和聚合,但客户端的本地数据并不需要被共享。
联邦学习的概念是由 Google 公司于 2016 年提出的,并将联邦学习应用于 Google Keyboard程序中,可以在多部安卓手机上进行协作学习。由于联邦学习可以应用于任何边缘设备,使得其在医疗保健、交通、金融、智能家居等领域被广泛应用。
虽然联邦学习的应用领域很多,但其面临着一些新的挑战。这些挑战大致可分为 2 类:与模型训练有关的挑战和与系统安全有关的挑战。与模型训练有关的挑战包括多次训练迭代期间的通信开销问题、参与学习的设备的异质性以及所用数据的异质性,而与系统安全有关的挑战包括用户隐私的泄露风险、针对联邦学习数据和模型的投毒攻击,以及针对联邦学习的后门攻击。本文将介绍联邦学习的基本过程和类别划分以及联邦学习的实际应用,并通过对当前联邦学习面对的瓶颈与安全挑战的概述,使联邦学习系统的设计者可以更加方便地发现现有框架中存在的潜在漏洞,同时帮助对联邦学习感兴趣的研究人员了解联邦学习现在所面临的威胁与挑战。
1
联邦学习的过程与类别划分
1.1 联邦学习的过程介绍
联邦学习的过程通常包括以下4个主要步骤。
(1)客户端的选择。服务器可以从设备池中随机选取所需的客户端,也可以使用自定义的算法进行客户端的选择。
(2)参数广播。服务器向选定的客户端广播全局模型参数。
(3)本地模型培训。客户使用其本地数据对模型参数进行同步后开始模型的训练。
(4)模型聚合。客户端将其训练好的本地模型参数发送回服务器,模型参数将向全局模型聚合。
上述步骤将按照需求迭代 n 次,直至模型收敛或达到需求。图 1 表示了联邦学习的基本过程。
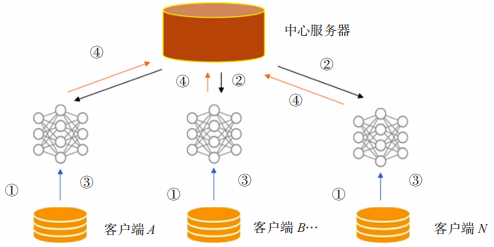
图 1 联邦学习的基本过程
1.2 联邦学习的类别划分
按照数据样本特征,联邦学习主要可以划分为横向联邦学习和纵向联邦学习。横向联邦学习适用于参与者的数据特征重叠较多,而样本 ID 重叠较少的情况,比如两家不同地区银行的客户数据。“横向”二字来源于数据的“横向划分(Horizontal Partitioning)”。横向联邦学习数据划分如图 2 所示,联合多个参与者的具有相同特征的多行样本进行联邦学习,即各个参与者的训练数据是横向划分的,称为横向联邦学习,横向联邦学习可以使训练样本的总数量增加。
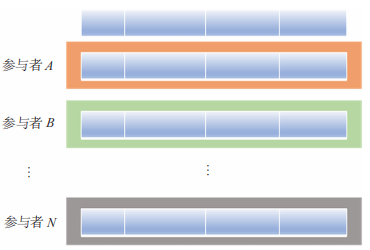
图 2 横向联邦学习数据划分
纵向联邦学习适用于参与者训练样本 ID 重叠较多,而数据特征重叠较少的情况,比如两个组织拥有同一组人的不同特征的数据,可以使用联邦学习来构建共享的机器学习模型。纵向联邦学习数据划分如图 3 所示,联合多个参与者的共同样本的不同数据特征进行联邦学习,即各个参与者的训练数据是纵向划分的,称为纵向联邦学习。纵向联邦学习需要先做样本对齐,即找出参与者拥有的共同的样本,只有联合多个参与者的共同样本的不同特征进行纵向联邦学习才有意义。纵向联邦学习可以使训练样本的特征维度增多。
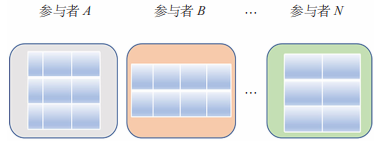
图 3 纵向联邦学习数据划分
2
联邦学习的应用
2.1 联邦学习在交通领域的应用
联邦学习在交通领域已经有了诸多应用。在无人驾驶方面,为了保持最佳的机器学习模型和模型做出最优决策的能力,Pokhrel 等人提出了一种基于自主区块链的联邦学习架构(Blockchain-Based Federated Learning,BFL)设计,该设计使用区块链的共识机制来实现车载机器学 习(On-Vehicle Machine Learning,oVML)。Zeng 等人结合基于契约理论的激励机制,设计出一个新的联邦学习框架,该框架可用于通信链路不稳定和复杂环境条件下的车辆间联邦学习以及模型控制器的自主优化。
2.2 联邦学习在医疗领域的应用
在医疗领域,随着个人电子健康信息的普及,对患者数据的保护通常会形成局部的数据孤岛,这使得医疗系统难以通过广泛的数据集建立起可靠的医疗辅助诊断模型。而联邦学习的方式可以很好地保护患者的隐私,使所训练的诊断模型可以充分利用更多数据集,进而大大提高诊断模型的准确性。2020 年,Xu 等人 通过联邦学习的方式开发出一种可用于新型冠状病毒诊断的模型系统,该系统可以在不损害患者隐私的情况下准确地对患者病情进行诊断。
2.3 联邦学习在金融领域的应用
随着数字时代的到来,金融犯罪也出现了新的形式,给银行和消费者造成了巨大损失。同时客户也非常关注其私人财务信息能否得到有效保护。因此,在机器学习技术与金融行业结合的过程中,如何保护好金融用户的隐私信息是一个重要的研究方向。联邦学习无须共享数据的方式为使用深度学习训练模型提供了一种新思路,每组数据的所有者可以在不进行客户私人信息共享的情况下进行协作,这样防止了客户私人信息的泄露,确保了数据安全。Feng等人提出了一种双边隐私保护的联邦学习方案,该方案可以保护训练过程中的迭代参数,同时在考虑客户端隐私的基础上,进一步保护模型参数不被外部攻击者获取。
3
联邦学习面临的瓶颈
联邦学习虽然已被应用于交通、医疗以及金融等诸多领域,并且对相关的用户隐私进行了有效保护,但其作为一个分布式的机器学习系统,在现在的发展阶段仍面临着制约其快速发展的瓶颈问题,下面将介绍联邦学习所面临的几种典型的瓶颈问题。
3.1 通信开销问题
联邦学习中的通信开销问题是联邦学习的主要瓶颈之一。随着深度神经网络的发展,模型变得非常复杂,每一轮迭代中变化的模型参数也大大增加,联邦学习在每一轮训练的过程中需要将这些参数上传和下发,这相较于传统的机器学习会增加巨大的通信开销。目前减少联邦学习过程中通信的开销都是以增加客户端本地的计算量为代价,将更多的计算放在本地执行,以此减少通信的轮次和通信过程中传递的参数数量。随着客户端计算能力的不断提高,这种方法的弊端正在逐渐减弱,因此以增加计算量的方式来减小通信的代价总体上来说是可行的。
3.2 数据的非独立同分布
通常情况下,机器学习的数据集是独立同分布的,而联邦学习的数据集却常常以非独立同分 布(Non-Independent Identically Distribution,Non-IID)的方式存在,这就对联邦学习的实际落地形成了挑战。针对 Non-IID 数据导致的联邦学习效率下降的问题,可以从性能、算法、模型等方面对联邦学习进行优化。联邦学习的训练效率很大程度上都和 Non-IID 数据有关,如果从 Non-IID 数据本身着手,也可以对联邦学习效率的提升有很大的帮助。此外,联邦平均算法(Federated Average Algorithm,FedAvg)是联邦学习中使用最为广泛的算法之一,该算法通过权重更新来更新全局模型,但只考虑到客户端数据量的大小,并未考虑到客户端数据质量对整体模型的影响。因此优化联邦学习算法,使其能够适用于不同数据质量的情形非常关键。
3.3 系统和数据的异质性
联邦学习网络中的客户端系统通常会有多种类别,系统的异质性以及来自设备的数据的不平衡、不一致分布会显著影响联邦学习模型的性能。并且客户端的庞大数量和不一致性可能会使模型的可靠性下降。经典的 FedAvg 对系统异构性不够健壮。针对联邦学习系统异构性的问题,可以通过修改模型聚合算法的方式来进行优化。
4
联邦学习的安全问题与防御机制
在上一节中介绍了联邦学习所面临的瓶颈问题,这些瓶颈制约着联邦学习的发展,但同时联邦学习也会面临着一些安全方面的挑战,影响着联邦学习技术是否可以落地。本节将讨论联邦学习背景下的安全问题,介绍针对联邦学习常见的攻击手段和防御机制。
4.1 隐私泄露
尽管在联邦学习中用户的原始数据不会离开本地设备,不需要数据共享,并且允许参与者自由加入和离开,但仍有许多办法可以推断出联邦学习中使用的训练数据信息。因为在整个培训过程中更新和传达的模型信息可能会暴露出用户的敏感信息(如性别、年龄、爱好),甚至会发生深度泄露,即使是一小部分原始梯度也可以揭示出有关用户数据的信息。NeurIPS2019 的最新研究表明,恶意攻击者可以通过有限次的操作从梯度中窃取到训练数据。目前,主要的防止隐私泄露的技术有安全计算、差分隐私以及为联邦学习构建可信的执行环境。
防御机制 1:安全计算。安全计算包括安全 多 方 计 算(Secure Multi-Party Computation,SMC)和同态加密两种主要技术。SMC 是指从每一方的隐私输入中协作计算一个函数的结果,而计算结果的过程不需要将输入展示给其他方。SMC 保证了参与方在获得正确结果的同时,无法获得计算结果之外的任何信息。SMC 可以通过不经意传输(Oblivious Transfer,OT)、秘密共享(Secret Sharing,SS)和阈值同态加密 3 种不同的框架来实现。在同态加密中,计算是在加密输入上执行的,而不需要首先解密。在过去,同态加密因为巨大的计算量开销,在机器学习领域的应用比较少,但由于技术的发展,使得设备的计算能力显著提高,人们对隐私保护的需求远远大于对计算资源的需求,同态加密技术进而也逐步应用到联邦学习中。
防御机制 2:差分隐私(Differential Privacy,DP)。在差分隐私方案中,通过在模型聚合前将噪声添加到模型参数中来屏蔽用户的信息,从而达到对用户隐私保护的效果。但是在参数中添加噪声会损失一定的模型精度,使联邦学习模型的收敛效果变差。
防御机制 3:可信执行环境(Trusted Execution Environment,TEE)。可信执行环境提供了一个安全的平台,通过分配计算资源的私有区域(例如内存),可以提供硬件和软件隔离,以较低的计算开销运行联邦学习模型,在不影响准确性和效率的情况下,保证了联邦学习的数据隐私。与同态加密等传统软件保护相比,TEE 提供了更低的开销和更高的隐私,但是当前的 TEE 环境仅适用于 CPU 设备。
4.2 数据投毒攻击
数据投毒是机器学习领域常见的攻击之一,其中攻击者向训练集中添加训练数据,从而对联邦学习的训练模型进行操控,进而影响全局模型的准确性。数据投毒攻击可以分为白标签攻击和脏标签攻击。
白标签攻击不要求攻击者控制训练数据的标记,而是控制分类器在特定测试实例上的行为,且不会降低总体分类器性能。例如,攻击者可以添加看似无害的图像(这是正确的标记)到人脸识别引擎的训练集并在测试时控制所选人员的身份。由于攻击者不需要控制标记,因此只要将毒物留在网络上,等待数据收集机器人抓取毒物,就可以将毒物输入到训练集中。Shafahi等人提出了一种优化的毒物制作方法,并通过实验表明在使用迁移学习时,仅一幅毒化图像就可以控制分类器的行为。
脏标签攻击需要攻击者对训练数据的标记进行破坏,使一类正常数据的标签被替换为其他类型数据的标签,用这种混乱的数据对模型开展训练的话会使模型的行为发生错乱,无法正确地执行分类任务,以此达成攻击者的目的。
防御机制:对数据投毒攻击的异常检测包括通用方法和特定方法两类 ,通用方法可以检测出所有种类的数据中毒样本,像基于生成对抗网络(Generative Adversarial Networks,GAN)的 De-Pois 模型,是检测中毒样本的通用且有效的方法。通过 GAN 生成与干净数据分布相似的训练数据,基于生成的数据来训练模仿模型。De-Pois 能够有效区分毒化样本和干净样本。而特定方法仅能识别特定类别的数据投毒样本。Levine 等人提出的两种针对特定数据投毒的认证防御方法——深度分区聚合(Deep Partition Aggregation,DPA)和半监督DPA(Semi-Supervised DPA,SS-DPA),可以检测特定种类的数据投毒攻击。
4.3 模型投毒攻击
模型投毒攻击类似于数据投毒攻击,攻击者将本地模型的更新参数毒害后发送到服务器。模型中毒攻击背后的主要动机是要在全局模型中引入错误。攻击者通过破坏某些设备并修改其局部模型参数来发起模型投毒攻击,从而影响全局模型的准确性。Fang 等人通过模型投毒攻击对 4 种拜占庭式的健壮联邦学习方法进行攻击,在 MNIST、Fashion-MNIST、CHMNIST数据集上建立的评估结果表明,模型投毒攻击可以显著提高全局模型的错误率,攻击效果有显著提高。
防御机制:模型投毒攻击的防御与数据投毒攻击的防御类似。较为常见的防御措施可以分为:基于错误率(Error Rate based Rejection,ERR) 的 防 御;基 于 损 失 函 数(Loss Function based Rejection,LFR)的防御;ERR+LFR 联合的防御。
(1)基于错误率的防御。通过计算每个局部模型对验证数据集错误率的影响来删除对错误率有较大负面影响的局部模型。具体来说,假设有一个聚合算法,对于每个局部模型,我们使用聚合规则来计算全局模型 A(包括某个局部模型)和全局模型 B(排除某个局部模型)。我们通过计算来验证数据集上全局模型 A 和 B的错误率,进而删除:一些使全局错误率显著提高的局部模型,并聚合其他局部模型以获得更新的全局模型。
(2)基于损失函数的防御。在这种防御中,我们是根据局部模型对损失的影响而不是验证数据集的错误率来移除局部模型。具体来说,就像基于错误率的拒绝一样,对于每个局部模型,计算全局模型 A 和 B,并验证数据集上模型A 和模型 B 的交叉损失函数值,分别表示为 LA和 LB。此外,定义 LA−LB 作为局部模型的损失影响。与基于错误率的拒绝一样,删除具有最大损失影响的局部模型,并聚合剩余的局部模型以更新全局模型。
(3)ERR+LFR 联合的防御。结合了 ERR和 LFR 的策略。具体来说,就是删除被 ERR 或LFR 拒绝的本地模型。
以上的 3 种防御方式,LFR 的防御比 ERR的防御更有效,LFR 可以实现比 ERR 更小的测试错误率。而 ERR+LFR 联合的方式会比 LFR更好。值得注意的是,在某些情况下,部署防御措施后,错误率反而会增长,这是因为防御措施可能会移除良性的局部模型,从而增加全局模型的测试错误率。
4.4 后门攻击
后门攻击是指攻击者利用联邦学习模型更新过程中的匿名特性,将后门功能引入到全局模型中,比如通过修改图像分类器,将攻击者选择的标签分配给具有特定特征的图像,或强制单词预测器使用攻击者选择的单词完成特定句子,后门攻击的效果大大优于数据投毒。使用后门,攻击者可以在不影响全局模型准确性的情况下错误标记某些任务,可以为具有特定特征的数据实例选择特定标签。后门攻击后的模型在输入正常数据时也可以正常工作,模型性能也没有问题,只有当输入为特定值的时候,模型才会按照攻击者的意图进行工作,因此后门攻击很难被发现。后门攻击也称为目标攻击,此类攻击的强度取决于受损设备的存在比例以及联邦学习的模型大小。
防御机制:对后门攻击的防御可以采用弱差分隐私或者范数阈值法。此外,Zhao 等人 通过实验表明,正常的后门攻击无法对其提出的 FedPrompt 模型实现高成功率的攻击,证明了FedPrompt 模型的鲁棒性。因此,FedPromp 模型的分割学习并进行即时调优的联邦学习方法值得借鉴。
5
结 语
联邦学习为不同设备提供了一个安全的协作机器学习框架,而无须共享其私有数据。这吸引了许多研究人员在该领域进行广泛的研究。联邦学习现在已经应用于医疗、交通等多个领域。虽然与其他机器学习框架相比,联邦学习框架提供了更好的隐私保障,但它仍然容易受到多种方式的攻击。联邦学习框架的分布式特性使得部署防御措施更加困难。例如,添加到局部模型的高斯噪声可能会混淆聚合方案,并可能导致遗漏良性参与者。因此,能否在使用低计算成本的同时确保用户的隐私和算法的鲁棒性,去中心化的联邦学习能否防御插入后门的攻击方式等问题,将是联邦学习领域新的研究方向。总体来说,联邦学习仍处于起步阶段,并且在可预见的未来仍将是一个快速发展且重要的研究领域。随着联邦学习防御技术的发展,攻击机制也会发生变化,因此,如何开发出一种在不降低模型性能的情况下对各种攻击具有防御效果的机制,这将需要更多的学者进行更加深入的研究。
