基于深度学习方法“窃听”智能手机中的加速度计
背景介绍
目前智能手机上的运动传感器对振动敏感,已经被用于窃听音频。然而,存在两个公认的局限性,第一个限制是与麦克风不同,运动传感器只能接收通过固体介质传播的音频信号,因此之前唯一可行的设置是将运动传感器和扬声器放置在同一张桌子上;第二个限制是由于传感器的采样率上限是200Hz,而成年人的整个语音频段是85-255Hz,使用传感器只能采集到一部分的声音信息。
在NDSS 2020会议上,Zhongjie Ba等人重新审视了运动传感器对音频的威胁,提出了AccelEve方法,该方法利用运动传感器中的加速度计窃听同一智能手机中的扬声器,设计了一个基于深度学习的系统来识别和重建仅来自加速度计测量信号,得到对应的音频信号[1]。
实验模型
1.实验模型
对于以上提到的两个公认限制,作者提出了对应的解决方法。针对第一个限制,作者考虑一种更加糟糕的情况,使用智能手机的加速度计来窃听同一智能手机中的扬声器。同一设备的加速度计和扬声器将始终与同一电路板保持物理接触,并且彼此非常接近,从而使语音信号在加速度计测量中始终产生显著的影响。
针对第二个限制,随着智能手机型号的发展,加速度计的实际采样率迅速提高。下图为2016年至2019年各品牌手机内加速度计的采样率,对于2017年以后发布的高端智能手机,它们的加速度计采样率已经达到了400Hz以上的采样频率,因此能够得到相当大范围的人类语音。
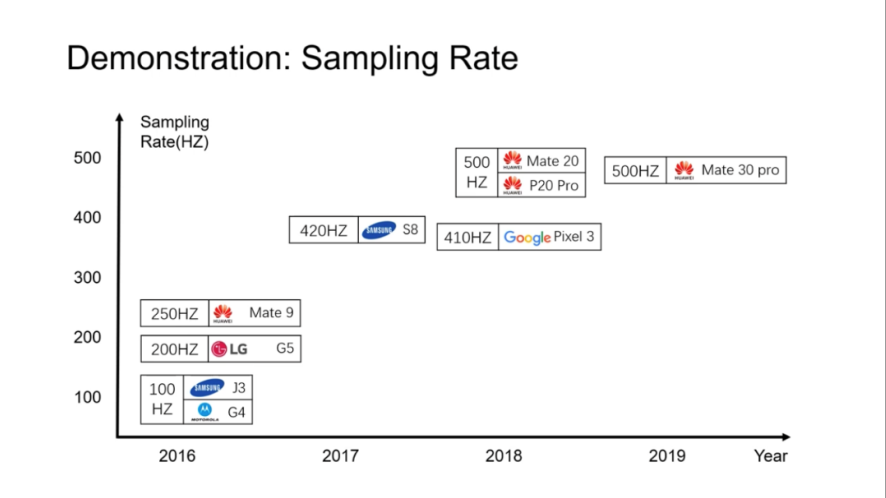
不同品牌手机内加速度计的采样率
在此基础上,作者提出了针对智能手机扬声器的侧信道攻击模型,该模型主要包括三个部分:预处理模块、语音识别模块和语音重建模块,在采集到加速度计信号后,使用预处理模块对信号进行处理,得到可以用于语音识别和语音重建的频谱图;频谱图进入语音识别模块,可以得到识别出的文字信息;频谱图进入语音重建模块,可以得到音频信息。
2.预处理模块
原始加速度信号存在三个主要问题:①由于手机系统为尽可能快地将加速度计测量值发送到应用程序,因此原始加速度计测量值不是按固定间隔采样的,②原始加速度计的测量结果会因人体运动而严重失真,③原始加速度计信号捕获了多个语音信息,需要进行分割。为了解决这些问题,作者使用以下步骤将原始加速度信号转换为频谱图。
- 线性插值
- 作者使用线性插值方法来处理加速度计测量的不稳定问题。由于传感器测量的时间戳是毫秒级的精度,解决不稳定间隔的方法是将加速度计测量的采样率提高到1000Hz。因此,作者使用时间戳来定位没有加速度计测量的所有时间点,并使用线性插值来填充缺失的数据,所得到的信号具有1000Hz的固定采样率。这种插值方法不会增加加速度计信号中的语音信息,其主要目的是产生具有固定采样率的加速度计信号。
- 高通滤波
- 使用高通滤波来消除由重力、硬件失真(偏移误差)和人类活动引起的显著失真。具体来说,首先使用短时傅里叶变换(STFT)将加速度信号沿每个轴转换到频域。它将长信号分成等长的片段,并分别计算每个片段的傅里叶变换。然后,将低于截止频率的所有频率分量的系数设置为零,并使用逆STFT将信号转换回时域。由于成年男性和女性的基频通常高于85Hz,而人类活动很少影响80Hz以上的频率分量,因此将语音识别的截止频率设置为80Hz,以尽量减少噪声分量的影响。
- 分割
- 由于沿三轴的加速度信号是完全同步的,作者使用z轴定位切割点,然后使用获得的切割点对滤波后的加速度信号沿三轴进行分割。具体来说,作者计算经过处理的信号的绝对值,经过两轮移动平均,窗口大小分别是200和30,得到一个平滑的序列,找到序列中的最大值max和最小值min,遍历序列,高于0.8min+0.2max的区域即为语音信号。为了保证分割后的信号覆盖整个语音信号,每个定位区域的起始点和结束点分别向前和向后移动100和200个样本。
- 将手机放置在桌子上和手中两种方式,分别获取对应的加速度信息,针对这两种场景计算出的切割点如下图所示。作者使用得到的截断点将滤波后的加速度信号分割成多个短信号,每个短信号对应一个单词。

针对手机放置在桌面和手握两种场景
获取到的加速计信号的处理
- 转为频谱图
- 为了生成单字信号的频谱图,首先将信号分成多个固定重叠的短段,段的长度和重叠部分的长度分别设置为128和120。然后,用汉明窗口对每个片段进行窗口化,并通过STFT计算其频谱,沿着每个轴的信号转换成一个STFT矩阵,记录每个时间和频率的幅度和相位。
3.语音识别和重建模块
经过预处理模块的操作后,得到加速度计信号的频谱图在调整大小后可以输入到各种标准化的神经网络内,语音识别模块选择的是DenseNet网络。相较于其他传统深度网络,DenseNet引入了每一层与前一层的连接,如图(a)所示,第一至四层都与第五层有直接连接,即将第一至四层的特征映射拼接为第五层的输入。因此,DenseNet可以使用更少的节点来实现VGG和ResNet相当的性能。经过语音识别模块,可以得到对应音频的文字信息。

DenseNet网络结构
此外,除了识别模块外,作者从相应的加速度计信号中重建了音频信息,这个模块可以用于重复检查识别结果。为了实现语音信号的重构,作者首先以加速度信号的频谱图作为输入,利用如下图的重构网络对加速度计频谱图进行重构,得到语音频谱图,然后利用论文[2]中提出的Griffin-Lim算法从重构的语音频谱图中估计语音信号。接下来,将详细介绍重建网络。
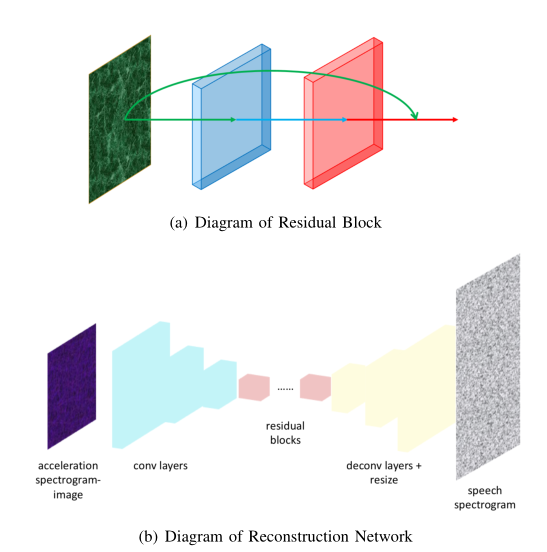
语音重构网络
重构网络由三个子网络组成,即编码器、残差块和解码器。重建网络的输入是一张覆盖20-500Hz频率分量的128*128*3的频谱图图像。每个通道对应于加速度信号的一个轴。编码器从32个9*9*3大小的卷积核开始学习大规模特征,然后分别有64个3*3*32和128个3*3*64大小的卷积核学习小规模特征。考虑到加速计信号频谱图和语音频谱图之间的相似性,恒等映射很可能是建立某些特征连接的最优映射。因此,在重构网络的中间添加一些残差块。最后,对语音频谱图进行解码,解码器由3个反卷积层组成,分别有64个大小为3*3*128的核,32个大小为3*3*64的核和3个大小为9*9*32的核。解码器的初始输出是一个128*128*3的矩阵,该矩阵将进一步调整为384*128的灰度图像,即相应的语音频谱图。
实验结果
1.语音识别模块
作者主要在从三星S8智能手机上收集加速度计信号来评估提出的系统。在智能手机上播放一系列语音信号,并通过后台运行的第三方Android应用程序AccDataRec收集加速度计信号。
语音信号主要来自两个数据集。第一个数据集是AudioMNIST数据集,包含来自20个说话者发出的10k个单独数字的语音组成。把数据集中的语音连接成间隔为0.1秒的长音频,来模拟受害者告诉别人他/她的密码的场景。第二个数据集是由36*260个数字和字母组成的语音。录制音频的志愿者需要拿着智能手机,以他们告诉别人密码时的语速读出一长串数字和字母。共有36个类别,包括10个数字(0-9)和26个字母(A-Z),每个类别包含从10个志愿者处收集到的260个样本。将数据集随机分为80%的训练数据和20%的测试数据。
目前,针对该问题准确率最高的语音识别模块是SOTA模块[3],下表为本文提出的模块与SOTA的实验结果对比。本文提出的的模块在识别10个数字加26个字母时达到了55%的top1准确率和87%的top5准确率。在识别说话者方面,该模块对20个说话者的分类准确率达到70%,而之前的SOTA模型对10个说话者的分类准确率只有50%。总的来说,本文的模型在所有任务中相较于SOTA模块都有了较大的提升。
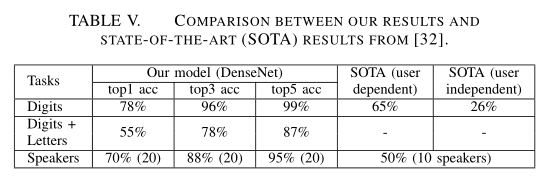
本文的语音识别模块与SOTA模块结果对比
2.语音重建模块
在本次实验中主要对热词进行识别,首先从句子中识别预训练的热词,再利用重建模型恢复音频信号,通过人耳对识别出的热词进行复核。该实验共收集到4名志愿者的200个短句。实验结果如下表所示,可以看出所有热词的误判率均在1%以下。
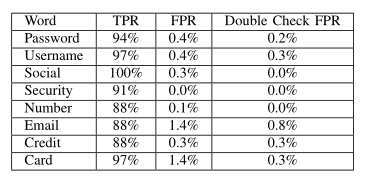
热词重建结果
总结
在本文中,作者重新审视了零权限运动传感器对语音信息的威胁,并提出了一种针对智能手机扬声器的侧信道攻击。作者首先提出了智能手机扬声器发出的语音信号总是会对同一智能手机的加速度计产生重大影响。其次,近几年的Android智能手机上的加速计几乎可以覆盖成人语音的整个基本频段。在这些基础上,作者提出了AccelEve方法,这是一种基于深度学习的智能手机窃听攻击,无论智能手机放在哪里和如何放置,都可以识别和重建智能手机扬声器发出的语音信号。
参考资料
[1] BA Z, ZHENG T, ZHANG X, 等. Learning-based Practical Smartphone Eavesdropping with Built-in Accelerometer[J]. Proceedings 2020 Network and Distributed System Security Symposium, 2020.
[2] ZHU X, BEAUREGARD G T, WYSE L L. Real-Time Signal Estimation From Modified Short-Time Fourier Transform Magnitude Spectra[J]. IEEE Transactions on Audio, Speech and Language Processing, 2007, 15(5): 1645-1653.
[3] MICHALEVSKY Y, BONEH D, GABI NAKIBLY. Gyrophone: Recognizing speech from gyroscope signals[C]//23rd USENIX Security Symposium (USENIX Security 14). USENIX Association, 2014: 1053-1067.

