基于深度强化学习的认知物联网资源分配的策略研究
摘 要:能量采集(Energy Harvesting,EH)和认知无线电(Cognitive Radio,CR)技术的组合可为物联网设备提供持续的能量,并有效地提高物联网系统的频谱效率。然而,在衬底模式下的认知物联网(Cognitive Radio IoT,CIoT)系统中,物联网设备之间的无线通信常常遭受窃听攻击。针对存在多窃听者条件下的 CIoT 系统无线通信场景,以保密速率作为系统保密性能指标。为解决所提的资源分配问题,将长短期记忆网络(Long-Term Memory Network,LSTM)、生成对抗网络(Generative Adversarial Networks,GAN)和深度强化学习(Deep Reinforcement Learning,DRL)算法相结合,设计一种联合能量采集时间和传输功率分配方案。数值仿真表明,与其他基准算法相比,所提方法能够有效地提高系统保密性能。
随着无线通信技术的快速发展,物联网正日益成为连接众多智能设备的新范式 。物联网规模的扩大使得物联网设备需要越来越多的频谱资源以满足日益增长的服务需求。然而,频谱资源已成为制约物联网未来发展的重要因素。认知无线电(Cognitive Radio,CR)允许次用户在不对主用户造成有害干扰的前提下去访问主用户的频谱资源,从而满足物联网的频谱需求。认知物联网(Cognitive Radio IoT,CIoT)通过将认知无线电与物联网相结合,已经成为物联网设备高效利用频谱资源的典型范式。
一般情况下,物联网设备由容量有限的蓄电池供电,然而这很难维持 CIoT 网络的长期运行。因此,为了延长 CIoT 网络的寿命,将能源采集(Energy Harvesting,EH)技术应用于 CIoT网络,能为物联网设备提供可持续的能量。然而,EH-CIoT 网络也面临许多安全风险。由于无线信道的广播特性,EH-CIoT 网络中的无线信息传输,如从传感器到控制器的上行链路通信或从控制器到执行器的下行链路通信很容易受到非法窃听 。作为传统加密技术的有效补充方案,物理层安全(Physical Layer Security,PLS)利用无线介质的物理特性(如衰落、噪声和干扰)来确保无线网络在信息理论上的绝对安全,而不受窃听者计算能力的影响 。代表性的 PLS 技术包括人工噪声、协作干扰和多天线传输。
近年来,针对 EH-CIoT 网络 PLS 增强的研究层出不穷。文献 [7] 研究了基于双跳射频能量的 CR 网络 PLS 性能,在该系统中,中继节点从次用户发射的源信号中采集能量。该文通过考虑不同信道的衰落模型是否服从同一分布,推导出保密中断概率的解析表达式。文献 [8] 考虑了一个认知环境后向散射通信网络,其中后向散射设备容易受到非法窃听。该文推导了合法用户、后向散射设备和窃听者的保密中断概率和截获概率的解析表达式。
在前面所提文献中,EH-CIoT 网络 PLS 增强可归结于对网络资源(如发射功率)的优化。然而,现有的文献大多采用传统的资源分配方法来解决这些非凸优化问题,其求解效率低下且计算复杂度高。实际上,由于无线网络环境的动态复杂性,传统的资源分配方法无法达到预期的性能,因此需要一种更加智能的方法来提高 PLS 性能。
深度强化学习(Deep Reinforcement Learning,DRL)逐渐兴起和发展。大量的文献已经证实了通过 DRL 方法对无线网络进行资源分配以提高系统性能的有效性。在文献 [9] 中,作者提出了两种基于深度确定性策略梯度的数据传输安全高效算法实现PLS下的数据传输。在文献[10]中,作者研究了雾计算网络中雾节点与终端用户之间的无线通信,利用 Q-Learning 算法获得动态环境下测试阈值的最优值。文献 [11] 研究了基于移动边缘计算的 CIoT 无线卸载安全问题,提出了视频帧分辨率选择、计算卸载和资源分配的联合问题,通过一种 DRL 方案来保证安全性,同时降低能耗。
据我们所知,通过 DRL 方法优化 EH-CIoT系统资源进而增强 PLS 性能的文献很少。虽然文献 [9] 和 [11] 研究了基于 PLS 技术的安全通信,但他们没有考虑在 CR 和 EH 技术下的通信过程,文献 [10] 只是采用传统的强化学习方法而不是 DRL方法,文献 [11] 没有考虑 EH 技术下的通信场景。因此针对上述问题,本文将 CR、EH 和 PLS 技术结合起来,研究存在多窃听者条件下的 EH-CIoT系统的保密通信过程,并基于 DRL 的资源分配方法来解决所提优化问题。
1
系统模型
如图 1 所示,EH-CIoT 系统模型包括一个主用户网络和一个次用户网络。主用户网络由一 个 主 发 射 机(Primary Transmitter,PT)和一个主接收机(Primary Receiver,PR)组成,次用户网络由多个次发射机和一个次接收机组成。干扰器 J 和每个次发射机 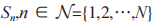 均配置了能量采集器和电池,可以从 PT 发射的射频信号中采集能量并存储。次发射机以衬底模式访问主用户的频谱,并通过时分多址方式依次占用信道与次接收器 D 通信,J 则发出干扰信号干扰窃听者
均配置了能量采集器和电池,可以从 PT 发射的射频信号中采集能量并存储。次发射机以衬底模式访问主用户的频谱,并通过时分多址方式依次占用信道与次接收器 D 通信,J 则发出干扰信号干扰窃听者
图 1 EH-CIoT 网络
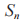 到 D,PR 和
到 D,PR 和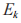 的信道增益系数分别用
的信道增益系数分别用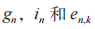 表示;PT 到
表示;PT 到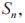 PR,D 和 J 的信道增益系数分别用
PR,D 和 J 的信道增益系数分别用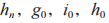 表示;从 J 到
表示;从 J 到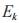 和 D 的信道增益系数分别用
和 D 的信道增益系数分别用 表示。假设所有信道增益系数都是独立的且服从均值为 0、方差为 1 的瑞利分布随机变量,窃听者在每个时间块上的信道状态信息对于次用户网络和 J 而言是完全可知的 ,J 产生的干扰信号可在 D处被消除,而在
表示。假设所有信道增益系数都是独立的且服从均值为 0、方差为 1 的瑞利分布随机变量,窃听者在每个时间块上的信道状态信息对于次用户网络和 J 而言是完全可知的 ,J 产生的干扰信号可在 D处被消除,而在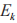 处无法被消除 。
处无法被消除 。
在第 n 个时间块上,以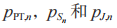 表示 PT,
表示 PT,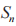 和 J 的发射功率,以
和 J 的发射功率,以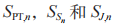 分别表示 PT,和 J 的发射信号,其中
分别表示 PT,和 J 的发射信号,其中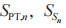 和
和 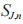 是均值为 0、方差分别为
是均值为 0、方差分别为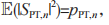
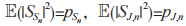 的循环对称复高斯随机变量,其中
的循环对称复高斯随机变量,其中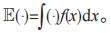 PR,D 和
PR,D 和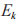 接收到的信号分别为:
接收到的信号分别为:
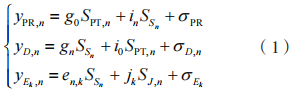
设总时间块的长度为 T。每个时间块考虑两阶段传输过程,即在 EH 阶段采集射频能量信号,在信息传输阶段向 D 传输保密信息,故有:
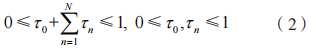
式中: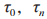 分别为能量采集时间、信息传输时间比例。在 EH 阶段,PT 向 PR 发射射频能量信号,则 和 J 采集到的能量为:
分别为能量采集时间、信息传输时间比例。在 EH 阶段,PT 向 PR 发射射频能量信号,则 和 J 采集到的能量为:
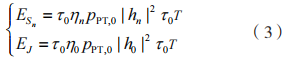
式中: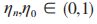 分别为 和 J 的 EH 效率。和 J 的发射功率受最大传输功率约束,故有:
分别为 和 J 的 EH 效率。和 J 的发射功率受最大传输功率约束,故有:
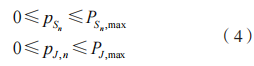
式中: 分别为 和 J 的最大发射功率。D,PR 和
分别为 和 J 的最大发射功率。D,PR 和 的信干噪比约束为:
的信干噪比约束为:
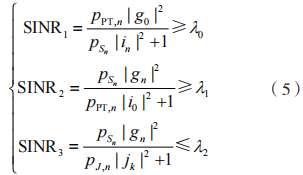
式中: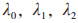 为相应的信干噪比阈值。和J 在第 n 个时间块上传输所消耗的能量不能超过当前电池可用容量,故其相应的能量因果约束分别为:
为相应的信干噪比阈值。和J 在第 n 个时间块上传输所消耗的能量不能超过当前电池可用容量,故其相应的能量因果约束分别为:
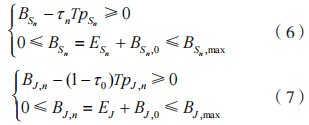
式中: 分别为 和 J 在第 n 个时间块开始时的可用电池容量;
分别为 和 J 在第 n 个时间块开始时的可用电池容量; 分别为 和 J 的最大电池容量。
分别为 和 J 的最大电池容量。
在信息传输阶段,第 n 个时间块上的保密速率为:
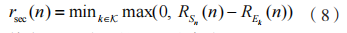
其中,到 D 的可达速率为:
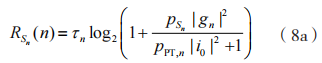
到 的窃听速率为:
的窃听速率为:
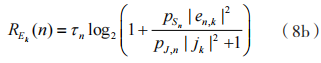
本文以保密速率作为系统性能指标,旨在对下列优化问题寻找最优的资源分配策略来优化安全性能。求系统保密速率最大化问题可表述为:
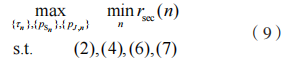
显然上述问题为非凸优化问题,寻找其全局最优解比较困难,因此需要寻找一种有效的方案。
2
深度强化学习算法设计
2.1 深度强化学习框架设计
将 第 n 个时间块上的 和 J 共同建模为一个智能体,共有 n 个智能体,EH-CIoT 网络中的其他部分建模为环境,DRL 框架如图 2 所示。智能体与环境的交互过程可建模为马尔可夫决策过程 (S,A,R,P,γ),其中 S 为状态空间,A 为动作空间,R 为奖励函数,P 为状态转移概率,γ∈ (0,1] 为奖励折扣因子。在第t个时间步,基于当前环境状态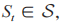 第 n ∈ N 个智能体获得局部观测
第 n ∈ N 个智能体获得局部观测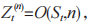 然后根据策略
然后根据策略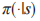 执行动作
执行动作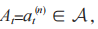 智能体从环境中获得奖励
智能体从环境中获得奖励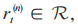 当前状态
当前状态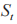 根据概率 P 转移到下一个状态
根据概率 P 转移到下一个状态
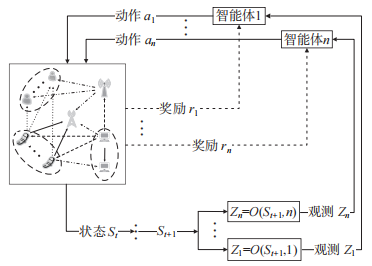
图 2 深度强化学习框架
2.2 状态空间设计
在多窃听者环境下的认知物联网中,环境状态是当前时隙 t 下对物联网场景的特征描述,状态的选取必须为智能体的决策提供足够的参考。具体而言,状态可包括通信链路的信道增益系数、信干噪比、次用户和干扰器的电池容量,智能体基于对环境状态的判断做出决策。因此在第 t 个时间步,第 n 个智能体的局部观测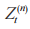 为:
为:
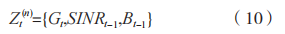
其中:
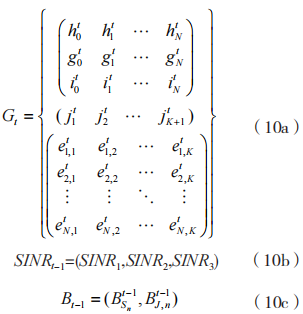
式中: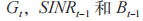 的状态变量个数分别为
的状态变量个数分别为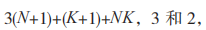 因此局部观测
因此局部观测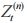 的状态变量个数为
的状态变量个数为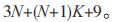
环境状态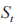 由所有智能体的局部观测组成,故表达式为:
由所有智能体的局部观测组成,故表达式为:
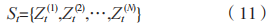
的状态个数变量为 N(3N+(N+1)K+9)。
2.3 动作空间设计
在认知物联网的资源分配场景中,需要在每个时隙对能量采集时间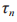 和发射功率
和发射功率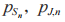 进行优化,因此在深度强化学习中,选择组合动作
进行优化,因此在深度强化学习中,选择组合动作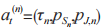 作为智能体 n 的一个动作。为了动作空间适用于本文算法,对连续变量
作为智能体 n 的一个动作。为了动作空间适用于本文算法,对连续变量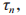
 的取值进行离散化操作 ,即基于式(12)将传输功率 离散化为
的取值进行离散化操作 ,即基于式(12)将传输功率 离散化为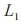 个功率层级:
个功率层级:
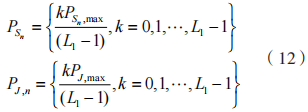
基于式(13)将 EH 时间 离散化为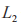 个时间层级:
个时间层级:
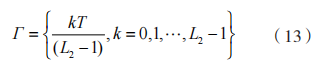
故动作空间大小为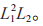
2.4 奖励函数设计
在深度强化学习中,奖励函数的好坏决定了系统的性能是否能够收敛。在认知物联网资源分配场景中,保密速率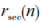 与认知物联网系统的保密性能相关联, 的值越大,智能体收获的奖励也越大,这表明智能体探索到一个好的策略,系统的保密速率收敛越迅速,反之亦然。因此将 作为奖励
与认知物联网系统的保密性能相关联, 的值越大,智能体收获的奖励也越大,这表明智能体探索到一个好的策略,系统的保密速率收敛越迅速,反之亦然。因此将 作为奖励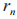 的主体部分。除此之外,奖励函数还包括信干噪比,用以引导智能体向信干噪比值高的方向探索策略。基于此,每个智能体的奖励设计为:
的主体部分。除此之外,奖励函数还包括信干噪比,用以引导智能体向信干噪比值高的方向探索策略。基于此,每个智能体的奖励设计为:
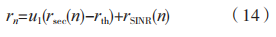
其中:
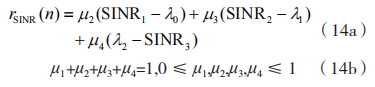
2.5 GAN-DRQN 资源分配算法
为 了 更 好 地 找 到 所 提 问 题 的 最 优 解, 本文 提 出 了 一 种 基 于 生 成 对 抗 网 络(Generative Adversarial Network,GAN)和长短时记忆(Long Short-Term Memory,LSTM)网络的 DRL 算法网络架构。在该网络架构中,GAN 网络用于克服随机噪声和时变信道对系统性能的负面影响,LSTM 网络用于提取环境输入特征。在经典强化学习中,在状态 s 下基于策略 π 采取动作 a 所产生的价值由状态 - 动作值函数表示:
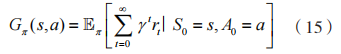
在本文设计的GAN网络模型中,生成器网络 G输出估计状态- 动作值分布,目标生成器网络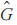 输出目标状态 - 动作值分布,鉴别器网络 D 则用于区分网络产生的目标状态 - 动作值与网络 G 产生的估计状态 - 动作值。
输出目标状态 - 动作值分布,鉴别器网络 D 则用于区分网络产生的目标状态 - 动作值与网络 G 产生的估计状态 - 动作值。
总体算法架构设计如图 3 所示。生成器网络 G 由 LSTM 层、嵌入层、公共层和输出层组成。LSTM 层作为输入层首先提取输入样本、噪声样本的特征;嵌入层由状态处理、噪声处理网络组成,状态和噪声特征分别由这两个网络进一步处理,通过 Hadamard 乘积将两个网络的输出融合成一个特征向量。特征向量经由公共层处理,最后输出层则生成状态 - 动作值。鉴别器网络 D 由多个全连接层组成,输出层只有一个神经元。在当前状态 s 中采取动作 a 所得到的价值与在下一状态 s' 中采取动作 a' 所得到的价值之间的关系可由 Bellman 期望方程描述:
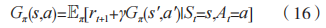
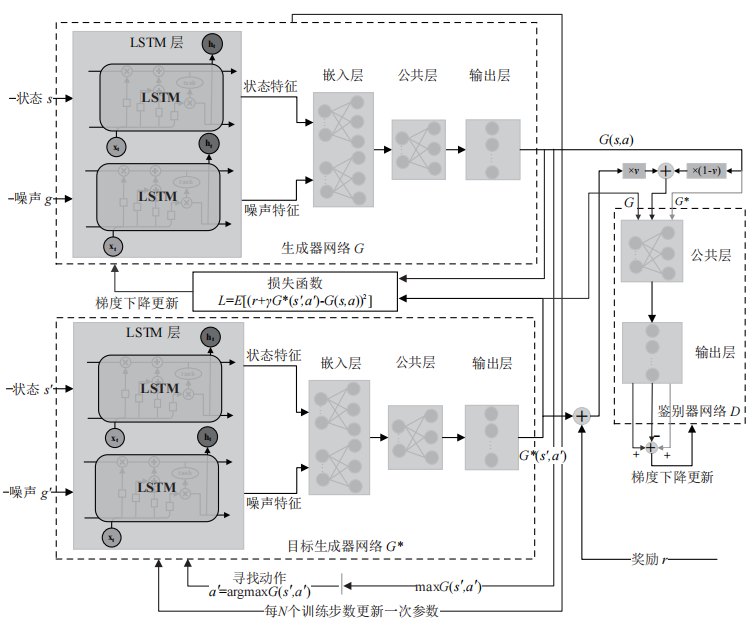
图 3 GAN-DRQN 算法网络架构
以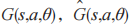 分别表示参数为 θ 的网络 G 和参数为
分别表示参数为 θ 的网络 G 和参数为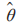 的目标网络 的状态 - 动作值函数。DRL 通过不断迭代式(16)来调整网络参数 θ,使得
的目标网络 的状态 - 动作值函数。DRL 通过不断迭代式(16)来调整网络参数 θ,使得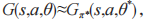 从而找到最优策略
从而找到最优策略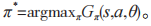 最优参数
最优参数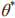 可以通过最小化样本
可以通过最小化样本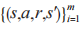 的损失函数得到。具体地,智能体 n 首先从回放池 B 中随机选取 m 个状态转移作为小批量训练样本,通过式(15)计算第 i 个样本的目标状态 - 动作值
的损失函数得到。具体地,智能体 n 首先从回放池 B 中随机选取 m 个状态转移作为小批量训练样本,通过式(15)计算第 i 个样本的目标状态 - 动作值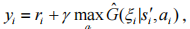 其中
其中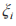 为噪声。网络D和G在第i 个状态转移
为噪声。网络D和G在第i 个状态转移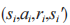 上的损失函数
上的损失函数 分别为:
分别为:
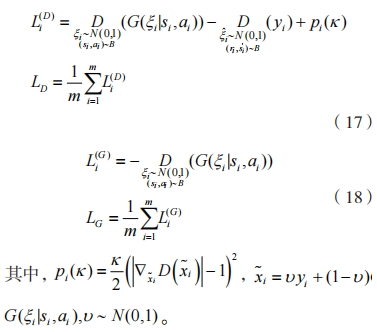
其中,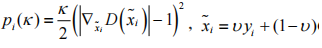
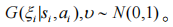
算法整个流程如算法 1 中所示。
3
实验仿真及结果分析
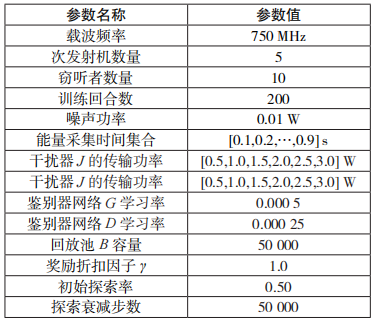
在每个训练回合,EH-CIoT 网络中的每个节点随机分布在一个边长为 240 m 的正方形区域中。LSTM 层的 LSTM 单元数设为 5,每个单元由 128 个神经元组成;在嵌入层,状态处理网络和噪声处理网络中的神经元数量均为 64,64 和 128;公共层的神经元数量为 256,256;输出层神经元数量为 嵌入层和公共层采用 ReLUs 作 为 激 活 函 数。主 要 的 仿 真 参 数 如表 1 所示。
嵌入层和公共层采用 ReLUs 作 为 激 活 函 数。主 要 的 仿 真 参 数 如表 1 所示。

表 1 仿真参数
为了评估本文所提算法在提高系统保密性能方面的有效性,所提方法与以下基准方案进行了对比。
(1)DQN 算法。该方案不考虑 EH 过程,而通过 DQN 算法为 和 J 分配发射功率。
和 J 分配发射功率。
(2)DRQN 算 法。DRQN 采 用 LSTM 网络架构,但无 GAN 网络架构,这有助于探索GAN 网络对系统性能的影响。
(3)随机资源分配算法。随机算法用于在每个时间步为 和 J 随机选择 EH 时间和发射功率。
图 4 为训练过程中 4 种算法下的保密速率随训练回合数变化情况。在图 4 中,随机算法的 表 现 水 平 最 差,DRQN 和 DQN 方案下的保密速率同时收敛到了不同层级的水平,本文所提方法与 DRQN 方案相比,尽管其在前 12 个训练回合中性能略有落后,但在后期的训练过程中性能优势逐渐明显并且将性能差距拉开,这表明本文方法在增强系统物理层安全性能方面是有效的。当超过 50 个训练回合数时,DRQN 方案与所提方法相比存在 28% 的保密速率差。
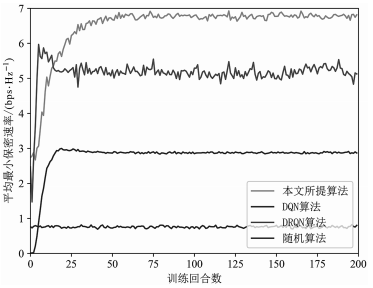
图 4 保密速率随训练回合数变化曲线
图 5 和 图 6 分别对比了几种算法下的保密速率随最大传输功率的变化。在图 5 的几种算法中,随着干扰器的最大传输功率的增加,本文所提方法的系统性能得到了最大限度的提升。在图 6 中,本文所提方法能以较少的训练回合数使系统性能最优,随机方案由于其随机行为而难以获得显著的性能提升,DQN 方案也因未采用 EH 技术而落后于所提方法,DRQN方案由于没有 GAN 网络而落后于本文所提方法。
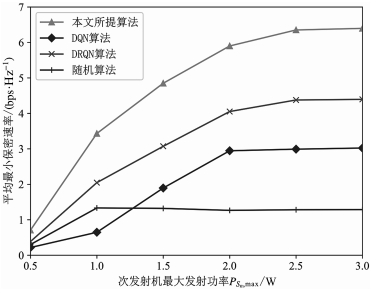
图 5 保密速率随次发射机的最大传输功率变化曲线
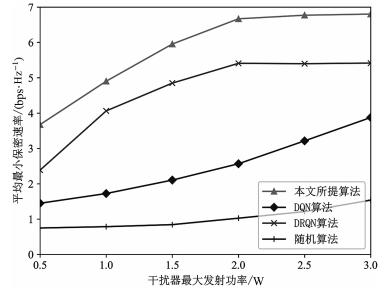
图 6 保密速率随干扰器的最大传输功率变化曲线
图 7 显示了训练过程中在不同折扣率 γ 下的奖励的变化。不同的折扣率对系统性能的影响不同,因为折扣率 γ 越接近 1.0,智能体越关注 EH 阶段和信息传输阶段的平衡;相反,折扣率 γ 越小,智能体越专注于短期收益,最大化每回合的累积奖励意味着要传输更多的保密信息,所以会尽可能地选择传输更多的保密信息到目的节点处。因此,为了在能量采集和数据传输之间取得平衡,当 γ 设为 1.0 时,系统性能可达到最优。
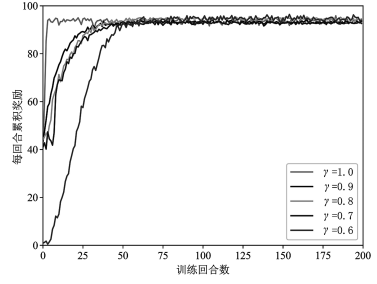
图 7 不同折扣率下的奖励变化曲线
图 8 分析了保密速率和窃听者数之间的关系。从图中可以看出,随着窃听者数的逐渐增加,保密速率不断下降。其主要原因是,增加窃听者数会使得窃听信道质量优于保密信道质量的概率增大。DQN 方案受窃听者数的影响较大,例如,存在 10 个窃听者与存在 1 个窃听者的情况相比,该方案下的保密速率大约下降了78%,而在本文所提方法下的保密速率下降了17%,本文所提方法在最大限度上保证了系统物理层的安全性能。
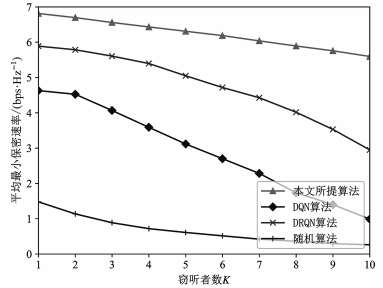
图 8 保密速率随窃听者数变化曲线
4
结 语
本文研究了多窃听者条件下的 EH-CIoT 系统安全传输过程,并提出了相应的联合 EH 时间和传输功率优化问题。针对所提优化问题,本文提出了一种 LSTM、GAN 和 DRL 结合的资源分配方案,在所设计的算法网络架构上,进一步设计了状态空间、动作空间和奖励函数。仿真结果表明,与基准方案相比,本文所提方法是一种通信效率高的方法,通过使智能体自适应地寻找最优的资源分配策略,最大化系统保密速率,最优化系统保密性能。在未来的工作中,将对 EH-CIoT 系统保密能效问题做进一步的研究。
