Argus:基于RDMA的大数据作业调度系统
作业调度是大数据处理系统中的核心问题。在现有的大数据处理系统中,一个作业通常被抽象为一个DAG图,其中一个顶点代表一个计算阶段,而一条边代表计算阶段之间的数据传输。每条边同时也代表着阶段之间的依赖关系,即一个阶段必须等到它所依赖的所有阶段都完成才能开始执行。通常每个计算阶段都包含许多相同的任务,这些任务可以并行执行以充分利用系统资源。
现有的调度系统通常认为数据传输是制约系统性能的瓶颈,它们从而通过优化网络传输来提升系统性能。然而,现如今远程内存直接访问(RDMA)技术被广泛使用。在RDMA网络下,数据传输不再是制约系统性能的问题,而计算资源利用率则直接影响系统的性能。虽然现在也有一些调度系统针对提升计算资源利用率做优化,但它们都需要提前获得作业运行时信息,而这种信息通常是无法提前准确获取的。同时,作业执行过程中存在多个计算阶段可以同时调度的情况,不当的调度顺序会造成有空闲计算资源而没有任务可调度的情况,进而导致计算资源利用率低下。
针对以上问题,指出找到作业的可并行计算阶段间的最优调度顺序,才能避免有空闲计算资源而没有可调度任务的情况。首先,通过分析计算阶段之间的依赖关系,确定计算阶段的优先级,提出了一种依赖感知的作业调度方法。其次,设计了基于RDMA非对称性的数据传输机制。实际测试结果表明,Argus相比国际上最新系统,将作业完成时间降低了38%,系统资源利用率提升了20%。
Argus系统已开源,相应论文成果“Argus: Efficient Job Scheduling in RDMA-assisted Big Data Processing”被IEEE International Parallel and Distributed Processing Symposium (IPDPS)录用。该成果与华为公司开展了大数据系统的技术合作。

- 论文原文:
- https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9460510
- 系统开源:
- https://github.com/CGCL-codes/Argus
背景与问题
自大数据应用兴起后,大数据处理系统,如Hadoop和Spark等,被广泛应用到学术界和工业界中。对大数据处理作业进行高效的调度是大数据处理系统中的关键问题。
在大数据处理系统中,一个作业通常被抽象为一个DAG图,其中一个顶点代表一个计算阶段,而一条边代表两个计算阶段之间的数据传输与依赖关系。每个计算阶段都包含许多相同的任务,这些任务可以并行执行以充分利用系统资源。给定一个DAG作业和计算集群,调度器需要把任务分配到可用的机器上执行。调度器在调度过程中需要考虑许多因素,如阶段间依赖关系、计算资源利用率和数据的网络传输。
现有的调度系统通常是基于TCP/IP网络,它们认为数据传输是制约系统性能的瓶颈。因此,它们通过优化网络传输来提升系统性能,如提升任务的数据本地性,降低shuffle传输负载等。最近,远程内存直接访问(RDMA)技术被广泛地应用到了各种数据中心中。RDMA有着高吞吐、低延迟、低CPU占用的特性。在RDMA网络下,数据传输不再是制约系统性能的问题,计算资源利用率则直接影响系统的性能。然而,现有极少的基于RDMA的大数据处理系统仅仅使用RDMA加速网络传输,并没有设计相应的作业调度机制。另一方面,现有的优化计算资源利用率的系统都不能很好地在RDMA系统上工作,且他们都需要提前获得准确的作业运行时信息,而这种信息通常是无法提前准确获取的。
研究小组对真实Alibaba作业和TPC-DS测试集进行了分析,揭示了作业执行过程中存在多个计算阶段可以同时调度的情况(如图1所示)。作业执行过程中,如果有n个阶段可以并行执行,那么调度系统就有n!种可能的调度顺序。不当的调度顺序会造成有空闲计算资源而没有任务可调度的情况,进而导致系统计算资源利用率低下。
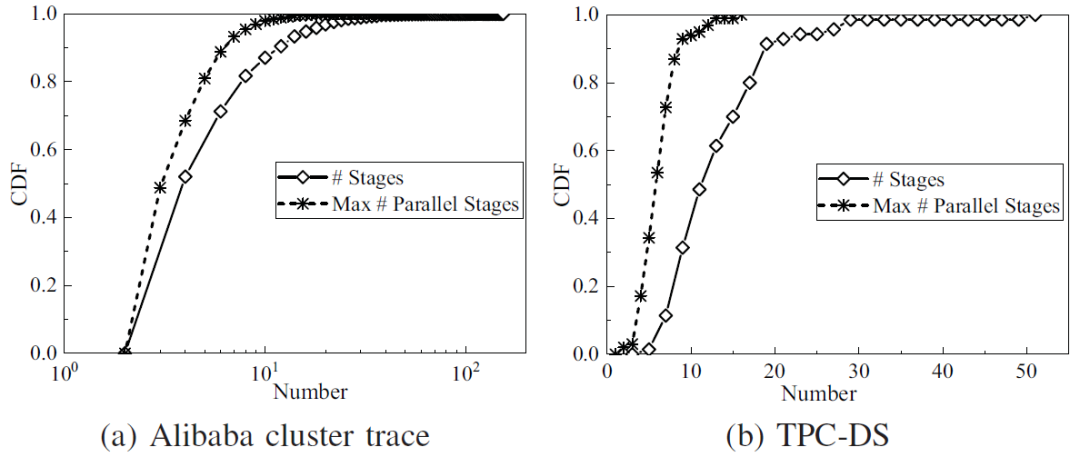
图1 真实作业中计算阶段和可并行执行阶段数
设计与实现
为了解决现有的RDMA系统中计算资源利用率低的问题,研究小组指出只有找到作业的可并行计算阶段间的最优调度顺序,才能避免有空闲计算资源而没有可调度任务的情况。然而,在作业真正运行之前,调度系统对作业信息的了解是非常有限的,通常只知道作业的DAG图,即计算阶段之间的依赖关系。因此研究小组仔细分析了作业的DAG结构,设计了一个依赖感知的作业调度机制。每当系统有空闲计算资源时,它都会优先调度那些完成后可以使更多阶段被调度的阶段。基于此,研究小组研发了基于RDMA的大数据作业调度系统Argus,其系统架构如图2所示。Argus主要包含两个模块,一个是阶段依赖感知的调度模块,负责确定任务优先级并调度任务。另一个是模式感知的RDMA传输模块,根据上下游任务间传输模式的不同选择适当的RDMA传输方式。
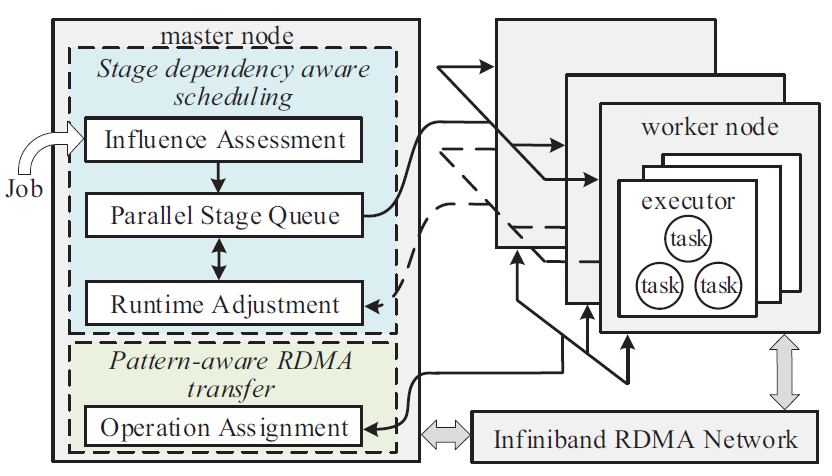
图2 Argus系统结构
通过对作业DAG图的观察分析,研究小组发现有两个因素影响计算阶段的调度顺序,分别是阶段深度和子阶段个数。为了充分利用计算阶段的这两个特征,研究小组在Alibaba真实作业上使用了模拟退火算法,确定了深度和子阶段个数这两个因素对阶段优先级的影响权重。基于这个权重,在调度作业时首先计算不同阶段的优先级,并根据优先级调度可并行执行阶段。同时,对于计算出的优先级相同的阶段,在执行过程中通过动态调整,优先执行时间较长的阶段以提升资源利用率。在计算任务调度完成后,任务之间的数据通过RDMA进行传输。由于RDMA的非对称性,发出RDMA请求比接收RDMA请求需要消耗更多的计算资源。研究小组设计了一种模式感知的RDMA传输机制,针对不同的上下游任务之间的传输关系,把发出RDMA请求这种开销大的操作平摊到不同节点上,避免了由于RDMA传输造成的负载不均。
基于真实系统数据的大规模实验结果表明,相比国际上最新系统,将作业完成时间降低了38%,系统资源利用率提升了20%,如图3所示。

图3 Argus性能对比
参考文献:
Sijie Wu, Hanhua Chen*, Yonghui Wang, Hai Jin, "Argus: Efficient Job Scheduling in RDMA-assisted Big Data Processing,” Proceedings of the 35th IEEE International Parallel and Distributed Processing Symposium (IPDPS 2021), Portland, Oregon, USA (online), May 17-21, 2021.
