实战 | 自动化日志分析工具的研究及应用
测试用例作为软件测试过程中最重要的资产之一,对于保证软件质量起到了至关重要的作用。随着自动化测试技术的不断发展,测试用例的数量也日益增多,并广泛应用于项目测试中。实际的测试工作中,执行失败用例的人工分析往往耗时耗力。目前,业界主流日志分析工具主要用于系统性能分析,缺少错误信息的分析及总结。然而当前普遍存在的问题是,随着执行测试用例数量的增长,对报错测试用例的分析成本变得更高,导致缺陷修复效率低。
本文提出了一种自动化日志分析模式,通过配置日志存放的服务器路径,获取日志文件,自动化检测日志文件中的错误关键字,对执行失败的案例进行分类并进行分析,帮助测试人员快速定位错误根源,提高缺陷修复效率。
自动化日志分析机制
“自动化日志分析”快速定位模式由日志文件获取模块、日志文本解析模块及关键词抓取模块、报错信息分类模块、日志报错信息特征库组成。自动化日志分析模型如图1所示。
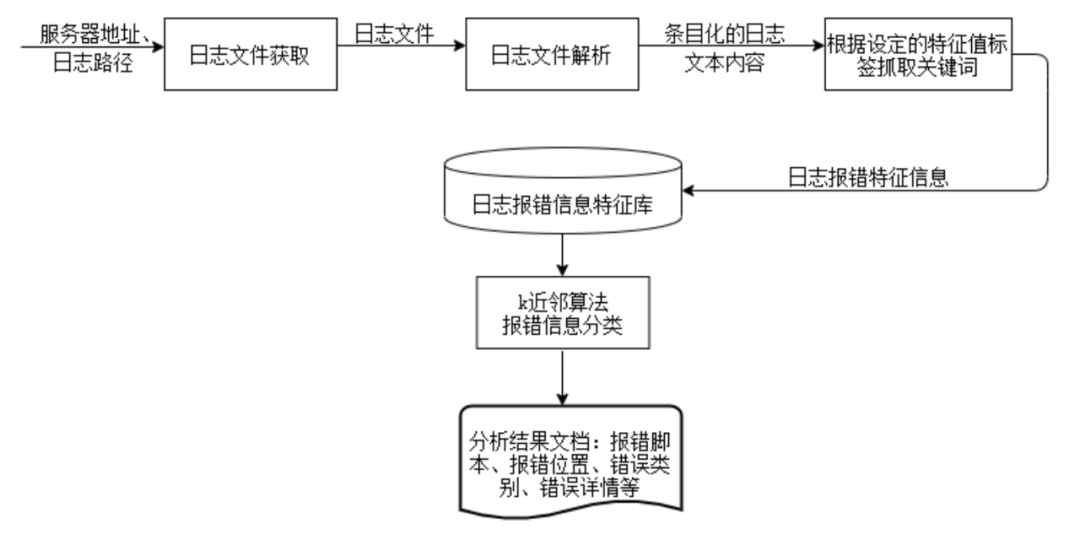
图1 自动化日志分析模型
1.日志文件获取模块。一个项目的程序及批量脚本执行日志通常具有存放路径集中、日志名称格式统一等特点,通过配置测试环境服务器的地址和执行日志存放路径,当程序或脚本执行之后,在指定服务器的指定路径下获取日志文件,取至本地,传入工具中。

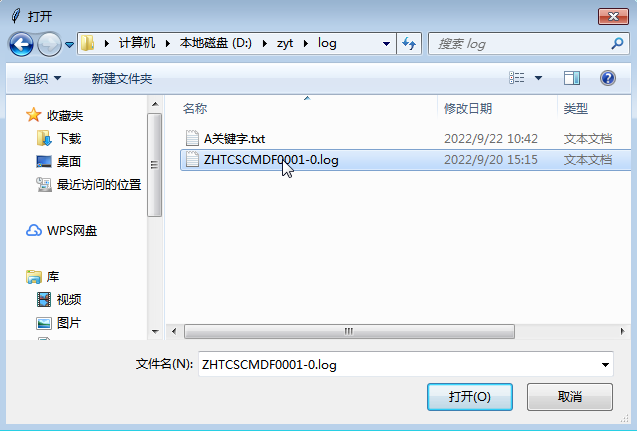
图2 日志文件上传与文件路径图
2.日志文本解析及关键词抓取模块。执行结果日志通常大且复杂,必须通过解析才能获取有用信息。该模块根据日志文本的编码格式,提取出文本内容,将文本中的信息抽取成一条一条的日志报错信息串,然后根据设定的特征值标签,抓取文本关键词作为特征词条,并按照组成特征向量各个维度,将每一条信息串表示成向量形式。
3.报错信息分类模块。对待分类的报错信息特征向量进行计算和分析,将其与日志报错信息特征库中已明确分类的错误信息特征向量的相似度一一计算出来,根据计算结果将特征向量分到相应类别中。根据各维度特征值,输出分析结果文档:报错位置、错误类别、错误详情等信息。
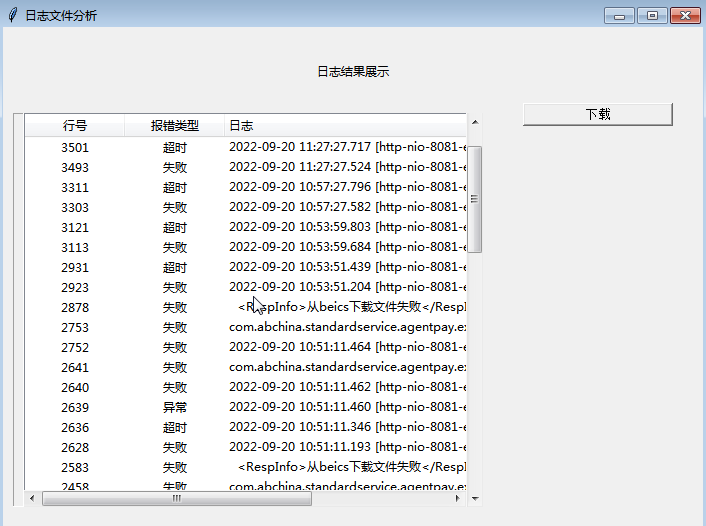
图3 日志输出结果展示
4.日志报错信息特征库。日志报错信息特征库存放已明确分类,具有代表性的错误信息特征向量,作为样本提供比较和分类的依据。日志报错信息主要包括数据库报错、程序异常、通讯问题、环境问题等,将各类报错样本的共同特征:函数名、错误码、错误信息、堆栈跟踪信息等提炼出来,作为组成特征向量的各维度分量,将各条样本表示成特征向量的形式,存放在日志报错信息特征库中。
自动化日志分析应用
在开展自动化测试时,测试用例数量庞大,即使失败率很低,失败用例的绝对数量也经常达到几十或几百个;批量交易测试时,一个项目的批量脚本量通常为几十到几百个,并且执行结果依赖开发人员判断及分析,测试人员难以主动把握测试结果。如果用传统的人工分析手段,就需要研发工程师投入大量时间和精力,效率低。本文提出的自动化日志分析机制可有效解决以上问题,且可广泛应用于以下三种情况。
1.回归测试。每一个系统的日志文件错误类型有其特点,特征信息库相对变化较少,当适应其他功能改造,本身产品功能没有改动时,执行大量的自动化案例进行回归测试,借助自动化日志分析工具,可清晰抓取出错误信息,提升回归测试效率。
2.批量交易测试。一个大型项目中,批量脚本通常达到几十到几百,一个作业链中可能有多个节点,调用多个程序或脚本。执行结果失败经常无法确定错误发生在哪个环节,借助自动化日志分析,减少开发和测试的沟通成本,加速问题定位。
3.对比测试。当架构调整、系统迁移、基础软硬件升级时,需要迁移前后的交易对比测试,迁移项目通常涉及开发人员多、交易繁杂,新旧系统基础语言及数据库差异大,引入自动化日志分析,可减少测试工作量,节约时间,保障大型迁移项目的顺利推进。
总结与展望
日志文件作为排查和定位程序及脚本问题的主要工具,涵盖了大量的有用信息。直接对日志进行分析存在缺陷无法直观分类展示,缺陷定位和追踪难度大等问题。相比于传统的人工分析模式,在自动化日志分析框架下,通过采用内部算法,根据设定的特征值,检测该路径下相关日志文件中的错误关键字,对失败的案例进行分类,可以输出分析结果文档,进而降低开发和测试的沟通成本,提升缺陷修复效率、彰显测试价值。
