无监督的12个最重要的学习算法介绍及用例总结
无监督学习(无监督学习)是和监督学习的另一种数据监督机器的方法,无监督学习是没有的明显学习数据本身。
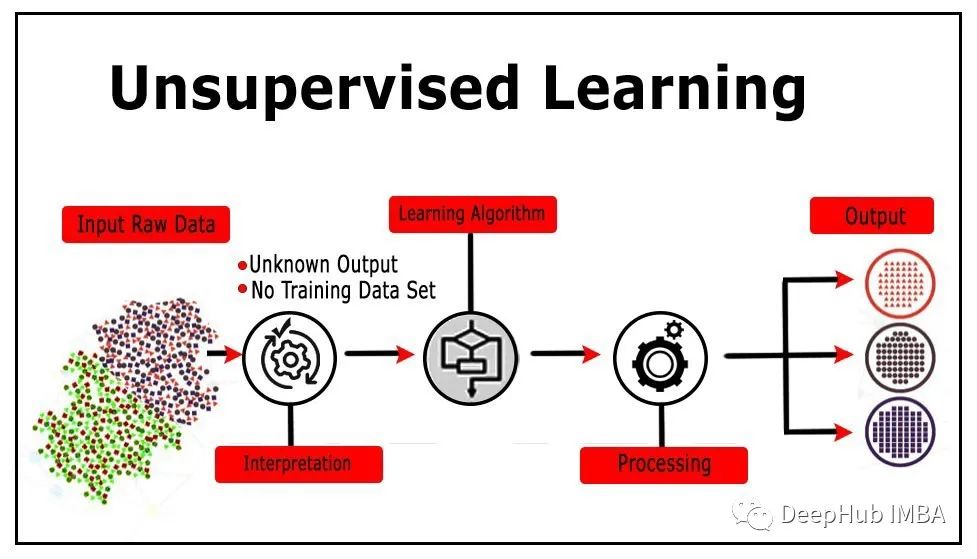
无学习监督算法有几种类型,以下是其中最重要的12种:
1、智能识别由相似性将点组成的簇
k-means是一种流行的算法,数据划分为k组。
2、降维算法降低了数据的维数,使可视化和处理更容易
主成分分析(PCA)是一种降维算法,将数据投影到低维空间,PCA可以使用将数据降维到其最重要的特征。
3.异常检测算法点识别异常值或异常数据
对向支持机可以用于异常检测(示例)算法[26]。需要方法标注数据集,而无需监督。
基于[20]个无异常数据监控空间中密集区域的点。
一个简单的方法是计算出每个点到最近的邻居的平均距离。发现点非常可能是异常点。
还有很多基础的异常检测算法,包括离群因子(Local Outlier Factor)和支持相关的数据描述(支持向量域描述)。这些算法可以比简单的近邻检测方法更复杂,通常更复杂例如到的可能出现的某些异常程度[21]。大多数检测算法都需要对参数进行异常调整,指定一个过高的参数来对异常进行调整。如果参数过低,算法会漏掉异常。算法可能会产生错误报告(将正常点识别为异常点)。
4、分割算法将]数据段或组[12
分割算法可以将图像分割为背景。
这些算法可以在不需要人工监督的情况下将数据集划分成k-组的距离。这个领域中比较知名的一个算法是手段。 k组。
一种鲁棒的分割算法算法中心是通过另外一种方式,可以通过不同的方式将数据点移向邻近区域的平均偏移量,实现异常值的处理。在大型数据集上运行它计算可能的价格但是。
高混合模式(GMM)可以用于最近的模型类型。以前的gmm模型需要计算来训练它们,但它们的研究进展正在进行中。gmm非常灵活,可以用于数据模型。但有时可以用于任何类型的数据。并且不能总是产生最好的结果。对于数据集,k-means 是一个很好的选择,而 gmm 则更适合于复杂的数据集。均值偏移可以用于一种简单的情况,但在任何大型的情况下数据集上计算的价格会涨。
5、去噪声滤波器或删除数据中的噪声
小波变换可以使用图像无发射数据。但包含可能产生的数据损坏、价值和异常值。去电视通过[10]中的噪声量来提高各种监督学习模型的大小。 。
现有的成分分析有多种成分,包括主分析(PCA)、成分分析(ICA)和非负成分(矩阵)[11]。
6、预测网络节点之间的未来连接预测(例如,预测每个节点之间的未来网络链接)
预测可用于预测哪些人将成为社交网络中的朋友。更常用的链接预测算法之一是优先连接算法[15],如果预测两个节点有多个现有连接,则它们更有可能被连接。
[1] [1] [1] [1] [1] [1] [1] [1] [1] [1] [1] [1] [1] [1] [1] [1] [1] [1] [1] [1] [1] [1] [16] [1] [1] [1] 可能“另一种结构”概念,因此在生物网络中经常使用。
步行者重启算法是一种线性预测算法,它模拟网络上的一个启动点最后移动的人,在不断节点[17]中,步行者到达特定节点的随机排列者。两个节点之间存在连接。
7、强化学习算法通过反复试验来进行学习
Q-learning是基于值的学习算法[1]的一个它实现简单且通用。但是Q-learning有时会收敛到次优解[18]。另一个例子是TD learning,它在计算上Q-学习学习要求更高,但通常可以找到更好的解决方案[19]。
8、生成模型:算法使用训练数据生成新的数据
自编码数据集生成独特的图像,可用于从这些数据集生成的图像。在机器学习中,生成模型属性是一个捕捉器的数据集的统计模型。所用的训练的数据一样。
生成模型任务各种,模型学习,数据压缩和像无像一样使用[很像 22]。生成模型有多种,隐含和可监督的模型机[22]。优缺点,并且适用于不同的任务。
隐马尔可夫擅长模型对顺序建模,而尔兹曼更擅长对高维数据[22]建模。通过在无标记数据上它们,生成可以用于无监督学习。然后模型训练,就可以使用这些过程生成新的数据。然后生成的数据可以由人类或其他机器学习算法进行标记。这个可以重复,直到生成模型生成数据,就像想要的输出。
9、随时森林是一种机器学习算法,可用于监督和无监督学习[9]
对于无监督学习,随时可以找到类似的学习森林,识别异常值,并压缩数据[9]。
和无监督任务经常被证明已被证明使用类似流行的机器学习(如机器)[9]。它们也刚刚过地推广到这意味着它们可以很好的数据。
10、CAN是一种基于数据库的学习算法,可用于无密监督
它基于,也就是每个点的数量很接近。并且具有一些优势,它可以找到不同大小的簇,集供不同和用户预先指定的数量。[23] [28]。没有类似的数据。例如,它可能会在另外一个数据集上增加一个很好的数据集。 ]。
11、用于优先选择关联、A项4项和顺序模式
四月算法也是第一个关联规则算法,使用最经典的算法规则。
Apriori算法有很多种方式,可以根据不同的需求进行定制。例如,可以控制支持度和置信度阈值以找到不同的规则[24]。
22、Eclat 2019 2019 2019 2019-08-20 2019-08-20 2019-08-08 2019-08-08 2019-08-08 11:24:00 来源: 2019-06-08 11:13:01
Eclat算法是一种深度优先算法,纵向数据表示,在格理论的基础上采用基于概念的等价关系搜索空间格)为概念的子空间格(子概念格)。
以上就是无学习中的算法,如果你对他们感兴趣,请详细查看下面的引用(长,建议查看监督的)
Q-Learning简介:强化学习: https ://www.freecodecamp.org/news/an-introduction-to-q-learning-reinforcement-learning-14ac0b4493cc/
2. Q-learning视频演练: https ://www.youtube.com/watch?v=4dcgjcuR-1o
3. 无监督学习:使用 DBSCAN 进行聚类: https ://web.cs.dal.ca/~kallada/stat2450/lectures/Lecture15.pdf
4.机器学习中的DBSCAN聚类算法: https ://www.kdnuggets.com/2020/04/dbscan-clustering-algorithm-machine-learning.html
5. 深度生成模型中全局因素的无监督学习。arXiv:2012.08234
6. Harshvardhan GM、Mahendra Kumar Gourisaria、Manjusha Pandey、Siddharth Swarup Rautaray,机器学习中生成模型的全面调查和分析,计算机科学评论,第 38 卷,2020 年,100285,ISSN 1574–0137, https://doi。 org/10.1016/j.cosrev.2020.100285 。
7. 提升: https ://aws.amazon.com/what-is/boosting/
8. 装袋: https ://www.ibm.com/cloud/learn/bagging
9. Breiman, L. (2001)。随机森林。机器学习,45(1),5-32。
10. Hastie, T.、Tibshirani, R. 和弗里德曼, J. (2009)。统计学习的要素:数据挖掘、推理和预测(第 2 版)。施普林格科学与商业媒体。
11. 主教,CM(2006 年)。模式识别和机器学习。施普林格。
12. 功能材料断层图像数据分割的机器学习技术。https://www.frontiersin.org/articles/10.3389/fmats.2019.00145/full
13. 复杂网络中的链接预测:调查。https://arxiv.org/pdf/1010.0725.pdf
14.链接预测。https://neo4j.com/developer/graph-data-science/link-prediction/
15. 在线网络中的偏好依恋:测量和解释。https://arxiv.org/pdf/1303.6271.pdf
16.一种新的相似性度量,用于挖掘长路径网络中的缺失链接。https://arxiv.org/pdf/2110.05008.pdf
17. 带重启的快速随机游走及其应用。https://www.cs.cmu.edu/~christos/PUBLICATIONS/icdm06-rwr.pdf
18. Q-Learning:教程和扩展。https://link.springer.com/chapter/10.1007/978-1-4615-6099-9_3
19. 时间差分学习: https ://web.stanford.edu/group/pdplab/pdphandbook/handbookch10.html
20. 异常检测的机器学习技术:概述。https://www.researchgate.net/profile/Salima-Benqdara/publication/325049804_Machine_Learning_Techniques_for_Anomaly_Detection_An_Overview/links/5af3569b4585157136c919d8/Machine-Learning-Techniques-for-Anomaly-Detection-An-Overview.pdf
21. 网络异常检测的机器学习方法。https://www.usenix.org/legacy/event/sysml07/tech/full_papers/ahmed/ahmed.pdf?ref=driverlayer.com/web
22.墨菲,KP(2012 年)。机器学习:概率视角(第 1 版)。麻省理工学院出版社。
23. 一种基于密度的算法,用于在大空间中发现集群……。https://www.osti.gov/biblio/421283 。
24. Rakesh、Agrawal 和 Ramakrishnan Srikant。“矿业协会规则的快速算法”。https://www.researchgate.net/publication/2460430_Fast_Algorithms_for_Mining_Association_Rules
25.帕克,伊克巴尔。机器学习:算法、实际应用和研究方向。https://link.springer.com/article/10.1007/s42979-021-00592-x
26. 使用多代理系统进行异常检测。https://users.encs.concordia.ca/~abdelw/papers/Khosravifar_MSc_S2018.pdf
27. 用于图生成的深度生成模型的系统调查| 深度人工智能。https://deepai.org/publication/a-systematic-survey-on-deep-generation-models-for-graph-generation
28. Hierarchical K-Means Clustering:优化集群——Datanovia。https://www.datanovia.com/en/lessons/hierarchical-k-means-clustering-optimize-clusters/
