快速上手Thanos:高可用的 Prometheus
在一个成千上万的服务和应用程序部署在多个基础设施中的世界,在高可用性环境中进行监控已成为每个开发过程的重要组成部分。
本文将介绍使用 Thanos 在EKS多集群架构上存储多个集群的 Prometheus 指标的思考过程和经验教训。

介绍
随着 HiredScore 的产品和客户群越来越大,我们开始向 Kubernetes 过渡并迅速采用它。Kubernetes 是我们重要的障碍之一,也可能是最大的监控基础设施。此外,它还允许我们为 HiredScore 的高速增长做好准备。
我们在使用 Prometheus / Grafana 堆栈进行监控方面有一些经验,了解到我们希望创建一个更好、高可用性和弹性的基础架构,具有可行且具有成本效益的数据保留。
CNCF 推广了多种基础设施,可以解决这些监控痛点,并实现具有高可用性、数据保留和成本效益的监控。
要求
- 单点可观察性将聚合来自任何区域的所有集群的所有数据
- Prometheus 的高可用性和弹性基础架构
- 我们所有应用程序数据的数据保留
- 经济高效的解决方案
我们选择了 Bitnami 的 Kube-Prometheus 解决方案和 Thanos-io 的 Kube-Thanos 解决方案。该解决方案效果很好,并成功满足了我们的所有需求。
让我们来认识一下players:
- Prometheus — 用于事件监控和警报的免费软件应用程序。它在使用 HTTP 拉取模型构建的时间序列数据库中记录实时指标,具有灵活的查询和实时警报。
- Thanos — 一个基于 Prometheus 组件的开源 CNCF 沙盒项目,用于创建全球规模的高可用性监控系统。它通过几个简单的步骤无缝地扩展了 Prometheus。
它是如何工作的?
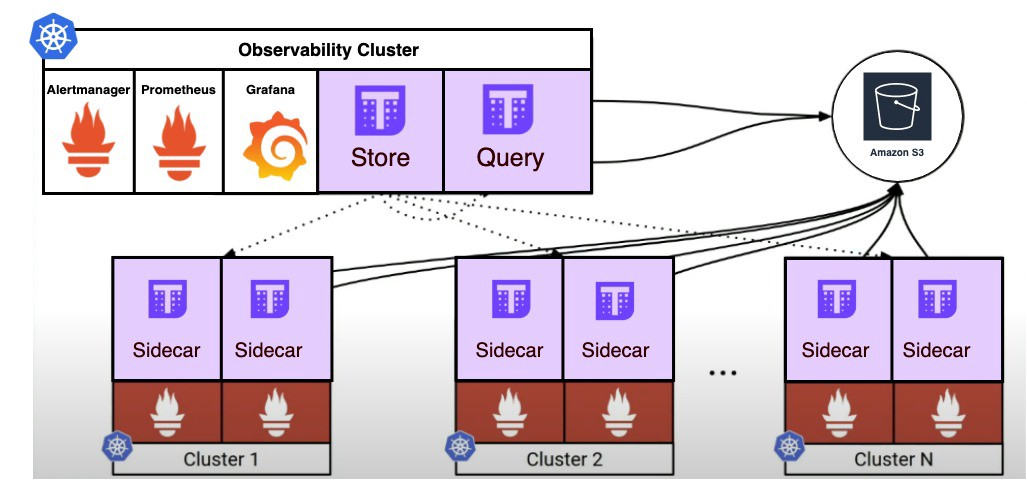
正如我们在图中所看到的,每个EKS集群在同一个名称空间中拥有两个 Prometheus pods,它们通过抓取集群行为来监视它们。每个 Prometheus pods 在专用PVC中保存最后几个小时,在规定的保留时间后,数据通过 Thanos sidecar 发送到S3桶。通过这种方式,我们可以在少量本地存储上节省成本,并将其他所有存储都集中在一个地方(S3)。
为了显示来自 k8s 集群的 Grafana 数据,我们创建了一个专用集群,负责使用连接到 thanos-sidecar 容器的 GRPC 直接从每个集群收集所有实时(最近约 2 小时)数据(暴露默认情况下在端口 10901 上)并从 S3 存储桶(配置存储)中获取远程数据。
让我们深入了解实现细节:
- 第一阶段是在每个集群中实现 kube-prometheus 和 Thanos sidecar。
- 第二阶段是在“聚合”集群中实现 kube-thanos 。它将负责从集群中收集所有集群的实时数据,并从发送到 S3 存储桶(ObjectStore)的保留数据中收集数据。
听起来很棒,那么我们实际上如何做到这一点呢?
第一阶段
在这里,我们关注如何在我们要监控的每个集群中部署和配置 Prometheus 以及 Thanos sidecar。在每个集群中创建一个名为 monitoring 的命名空间:
kubectl create ns monitoring
创建一个存储类以使 Prometheus 能够持久化日期:
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: prometheus-storage-class provisioner: kubernetes.io/aws-ebs parameters: type: gp3 reclaimPolicy: Retain allowVolumeExpansion: true volumeBindingMode: Immediate
kubectl apply -f prometheus-storage-class.yaml -n monitoring
安装 kube-prometheus:
helm repo add bitnami https://charts.bitnami.com/bitnami helm repo update
将要配置的相关值复制到本地文件夹中。需要在值中应用的一些更改:
第1步:使 Prometheus 高可用:设置Prometheus Replica Count— 所需的Prometheus副本数(超过2个)
- https://github.com/bitnami/charts/blob/master/bitnami/kube-prometheus/values.yaml
- https://github.com/bitnami/charts/blob/46afe376ae87a5af32504bc230a25
- d9c7e4522e2/bitnami/kube-prometheus/values.yaml#L760
## @param prometheus.replicaCount Number of Prometheus replicas desired ## replicaCount: 2
第2步:定义 pod 资源限制 Prometheus 资源-定义它以避免 Prometheus 消耗所有服务资源
resources:
requests:
cpu: 512m
memory: 3072Mi
limits:
cpu: 512m
memory: 4096Mi
第 3 步:启用 Thanos Sidecar 创建
thanos: ## @param prometheus.thanos.create Create a Thanos sidecar container ## create: true
第4步:将 Thanos sidecar 服务类型从更改 ClusterIP 为 LoadBalancer- 它将创建一个AWS经典负载均衡器端点,该端点将在GRPC端口 ( 10901) 中公开 sidecar,然后我们可以使用此端点通过 route53 将其路由到某个 DNS 名称 thanos-prometheus-(cluster_name)。在您自己的集群中公开 Thanos 端点 prometheus.thanos.service :https://github.com/bitnami/charts/blob/46afe376ae87a5af32504bc230a25d9c7e4522e2/bitnami/kube-prometheus/values.yaml#L1034
service:
type: LoadBalancer
port: 10901
annotations:
service.beta.kubernetes.io/aws-load-balancer-internal: "true"
现在,在创建 CLB 之后,我们需要在 kube-thanos 清单中实现它。我们稍后会在第二阶段讨论。
第 5 步:禁用压缩并定义保留——这是通过 Thanos sidecar 上传数据的一个非常重要的步骤:
https://prometheus.io/docs/prometheus/latest/storage/#operational-aspects
为了使用 Thanos 边车上传,这两个值必须相等--storage.tsdb.min-block-duration,--storage.tsdb.max-block-duration默认情况下,它们设置为2小时。Prometheus 的保留时间建议不低于 min block duration 的3倍,即6小时。可以在此处找到其他说明:
https://thanos.io/tip/components/sidecar.md/
retention: 12h disableCompaction: true
第 6 步:启用配置密钥——通过启用对象存储配置,我们可以将数据写入 S3 或任何其他受支持的 BlockDevice ,以确保我们长期数据的持久性
## @param prometheus.thanos.objectStorageConfig Support mounting a Secret for the objectStorageConfig of the sideCar container. objectStorageConfig: secretName: thanos-objstore-config secretKey: thanos.yaml
虽然源文件 thanos-storage-config.yaml 必须采用这种形式:
type: s3 config: bucket: thanos-store #S3 bucket name endpoint: s3..amazonaws.com #S3 Regional endpoint access_key: secret_key:
值得一提的是,目前我们只能使用单个 S3 存储桶(ObjectStore) 使用以下命令创建密钥:
kubectl -n monitoring create secret generic thanos-objstore-config --from-file=thanos.yaml=thanos-storage-config.yam
第 7 步:现在我们可以使用我们的相关自定义来安装/升级 helm chart
helm install kube-prometheus -f values.yaml bitnami/kube-prometheus -n monitorin
或者
helm upgrade kube-prometheus -f values.yaml bitnami/kube-prometheus -n monitorin
如果你做到了这里,你现在应该已经运行带有 Thanos sidecar 容器的 Prometheus pod,一方面通过GRPC将抓取的数据发送到清单,另一方面,相同的 sidecar 发送(大约 2 小时后)数据到S3存储桶(配置存储)。恭喜!
第二阶段
我们专注于如何在主要的可观察性集群上部署和配置 Thanos 。如前所述,它将负责从我们在第一阶段部署的所有集群中收集所有数据。
为此,我们使用 kube-thanos manifests。就目的而言,我们发现,只需实现查询和存储部分。
第1步:安装和自定义kube-thanos。在主可观察性集群中 创建一个名为thanos的命名空间:
kubectl create ns thano
可以选择克隆 kube-thanos 存储库并使用清单文件夹或自己编译 kube-thanos 清单。最后一个不需要复制整个存储库,只需要清单文件。
第2步:在通过第一阶段后,我们将负责 thanos-query-deployment.yaml 从第一阶段开始与其他集群之间的通信。为此,需要添加以下内容:
kubectl -n thanos create secret generic thanos-objectstorage --from-file=thanos.yaml=thanos-storage-config.yaml- --store=dnssrv+_grpc._tcp.thanos-prometheus-<cluster_name>.<domain_name>:1090
进入args我们在上面公开和定义的 Thanos sidecar GRPC 端点部分(步骤 4)
- args:
- query
- --grpc-address=0.0.0.0:10901
- --http-address=0.0.0.0:9090
- --log.level=info
- --log.format=logfmt
- --query.replica-label=prometheus_replica
- --query.replica-label=rule_replica
- --store=dnssrv+_grpc._tcp.thanos-store.thanos.svc.cluster.local:10901
- --store=dnssrv+_grpc._tcp.thanos-receive-ingestor-default.thanos.svc.cluster.local:10901
- --store=dnssrv+_grpc._tcp.thanos-prometheus-.<domain_name>:10901
- --query.auto-downsampling
第 3 步:现在,我们将处理 thanos-store 与配置要从第一阶段发送到的数据的S3存储桶(ObjectStore)之间的通信。因此,正如在第一步中所做的那样,我们需要配置一个名称,该名称在注入环境 thanos-store-statefulSet.yaml 的一部分中请求到 Thanos 存储 pod
env:
- name: OBJSTORE_CONFIG
valueFrom:
secretKeyRef:
key: thanos.yaml
name: thanos-objectstorage
然后我们可以重用第一阶段的相同源文件并为thanos-storethanos-storage-config.yaml创建一个秘密:
kubectl -n thanos create secret generic thanos-objectstorage --from-file=thanos.yaml=thanos-storage-config.yam
第4步:安装清单
kubectl apply -f manifests -n thano
现在,应该关闭循环。Thanos 通过 thanos-query 部署从其他集群接收实时数据,并通过 thanos-store-statefulSet 保留来自 S3 存储桶(ObjectStore)的数据。
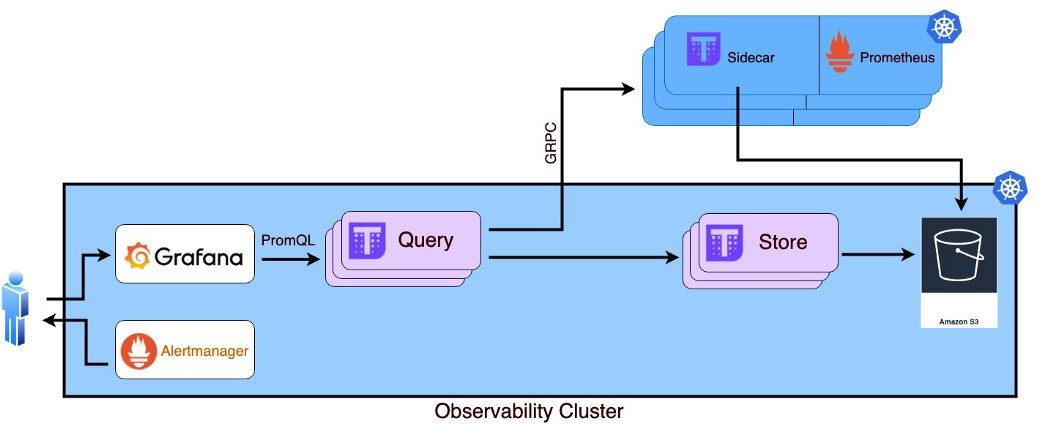
结论
Thanos 让我们改变了对 Prometheus 高度可用、耐用和经济高效的看法,在许多 Kubernetes 集群上实施 Thanos 和 Prometheus 需要付出很多努力,但如果我们关心确保高可用的 Prometheus,那么这是值得的。
