基于 Stacking 的网络恶意加密流量识别方法
摘 要:
随着加密流量的普遍应用,许多恶意软件开始隐藏在传输层安全协议(Transport Layer Security,TLS)流量中传输恶意消息,对通信安全造成严重威胁,因此对 TLS 恶意加密流量进行识别,对打击网络犯罪有着重要意义。通过对恶意和正常加密流量的会话和协议进行分析,在传统会话统计特征的基础上,提取出握手特征和证书特征,在单一特征和多特征条件下对恶意加密流量进行识别,证明了多特征的方法能显著提升识别效果。此外,为解决单一的机器学习方法泛化能力弱的问题,提出了一种基于 Stacking 的网络恶意加密流量识别方法,所提模型分类 ROC 曲线下方的面积(Area Under Curve,AUC)和召回率分别达到 99.7% 和 99.1%,在公开数据集上与XGBoost 等其他 4 种算法对比证明,所提算法性能有明显提升。
内容目录:
1 TLS 加密流量分析
1.1 TLS 协议分析
1.2 TLS 加密流量特征分析和提取
1.2.1 TLS 握手特征分析和提取
1.2.2 服务器证书特征分析和提取
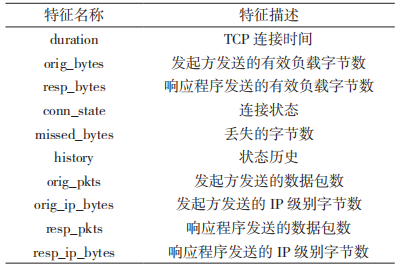
1.2.3 会话的特征分析和提取
2 基于 Stacking 集成学习的加密恶意流量检测方法
2.1 Stacking 集成模型
2.2 Stacking 模型构建
3 实验结果及分析
3.1 实验环境与数据集
3.2 评价指标
3.3 特征性能对比
3.4 元分类器选择
3.5 算法性能对比
4 结 语
在安全和隐私保护需求的驱动下,加密流量在网络中占据了越来越重要的地位。根据谷歌在2020 年发布的透明度报告,已经有 80% 的安卓应用程序默认使用传输层安全协议(Transport LayerSecurity,TLS)加密所有流量。根据 CISCO 2019年的报告,使用加密来隐藏远程控制以及数据泄露等恶意行为的恶意软件占比超过 70%,使用加密通信的恶意软件几乎覆盖了所有常见类型 。因此,高效识别 TLS 恶意加密流量有重要的现实意义。
目前,已经有国内外研究人员对网络恶意加密流量进行了研究,并且取得了一定的成就。Canard等人 提出了对加密流量进行深度包检测(Deep Packet Inspection,DPI) 而 无 需 解 密 的 技 术, 但在设置阶段需要大量的计算和较长的检测时间。Torroledo 等人 通过考虑 TLS 协议中的证书,利用证书内容对恶意流量进行识别,但是此方法对无证书传递的加密会话恶意性检测无效。Anderson 等人提出了一种 TLS 指纹识别系统,该系统利用目标地址、端口和服务器名精心构造了指纹串。但是,Matoušek 等人 发现以取证为目的创建唯一且稳定的 TLS 指纹并不容易,恶意用户可以通过恶意行为改变 TLS 版本、密码套件等信息躲避检测,因此指纹的发展受到了限制。此外,Anderson 等人在文献中研究利用 TLS 握手阶段的可用特征来识别加密恶意流量,但缺乏对握手阶段外的特征考虑,且只使用了逻辑回归分类器进行验证。
鉴于此,本文在 TLS 加密流量特征分析的基础上,提出了一种基于 Stacking 的网络恶意加密流量识别方法。该方法通过对恶意流量和正常流量进行分析,提取出能识别恶意流量的会话特征、握手特征和证书特征,并在单一特征和多特征条件下对恶意加密流量识别进行对比,发现多特征的检测方法能有效提升识别效果。为解决单一的机器学习方法在不同环境下的分类准确率难以保持稳定且泛化能力差的问题,构建 Stacking 模型并选择合适的基学习器和元学习器,最后在公开数据集上进行训练,实验证明所提算法的识别效果优于现有方法。
01
TLS 加密流量分析
1.1 TLS 协议分析
TLS 协议是加密流量传输中常用的协议,也是保护许多明文应用协议的主要协议。图 1 是一个完整的 TLS 握手过程。如图 1 所示,首先,客户端发送一条 ClientHello 消息,该消息为服务器提供了一系列密码套件和一组客户端支持的 TLS 扩展;其次,服务器发送一个 ServerHello 消息,其中包含从客户端列表中选择的加密套件,还包含服务器支持的扩展列表以及证书链的 Certificate 消息,该消息可用于对服务器进行身份验证;再次,在客户端发送 ClientKeyExchange 消息给服务器端后,客户端和服务器交换 ChangeCipherSpec 消息,以后的消息将使用协商好的加密参数进行加密;最后,客户机和服务器开始交换应用程序数据 。
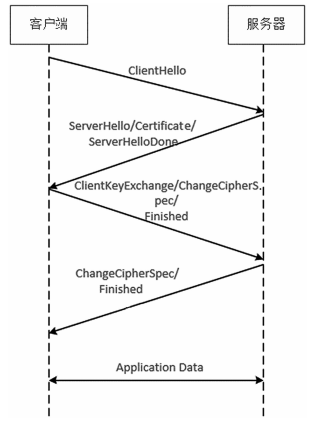
图 1 TLS 协议握手协商阶段流程
传统的通过 TLS 解密来查看流量密文内容的方式,不仅耗时,而且不能保护隐私。由于 TLS 协商的过程是通过明文来进行的,因此可以从未加密的消息中提取有用的信息。虽然证书是在 TLS 握手阶段得到的,但由于其对分类结果的影响明显,因此本文将证书作为单独特征向量进行考虑。
1.2 TLS 加密流量特征分析和提取
1.2.1 TLS 握手特征分析和提取
握手特征从客户端发送明文 Client Hello 消息和服务端反馈 Server Hello 消息中提取。图 2 展示了恶意会话和正常会话的服务器对 TLS 加密套件的选择对比和客户端支持的曲线对比。为了更清晰地表示,将密码套件用 16 进制代码表示。
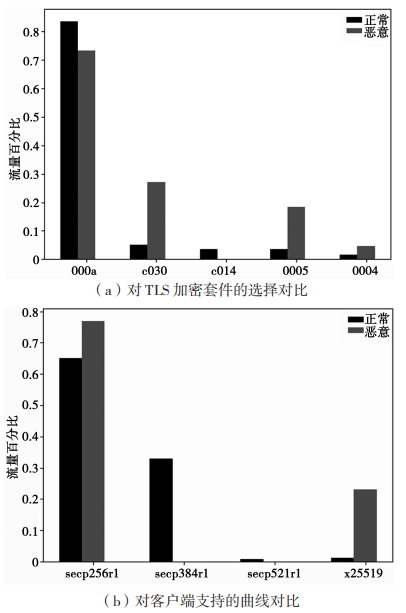
图 2 恶意会话和正常会话密码套件和曲线对比
服务器选择的密码套件针对大多数正常会话和恶意会话有严格划分。大多数正常的加密会话服务器选择的 TLS 密码套件为 000a、c014。
其中:
“000a”:TLS_RSA_WITH_3DES_EDE_CBC_SHA
“c030”:TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
“c014”:TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA
“0005”:TLS_RSA_WITH_RC4_128_SHA
“0004”:TLS_RSA_WITH_RC4_128_MD5
从图 2(a)中可以看出,恶意软件占比多的0004、0005 是比较弱的加密套件,安全性不足。从客户端支持的曲线对比看出,除选用基于 256 bits的素数域 P 上的椭圆曲线(secp256r1)外,有 23%的恶意会话的客户端依赖底层素数域特征为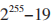 的椭圆曲线(x25519),而有 33% 的正常会话选用基于 384 bits 的素数域 P 上的椭圆曲线(secp384r1)。
的椭圆曲线(x25519),而有 33% 的正常会话选用基于 384 bits 的素数域 P 上的椭圆曲线(secp384r1)。
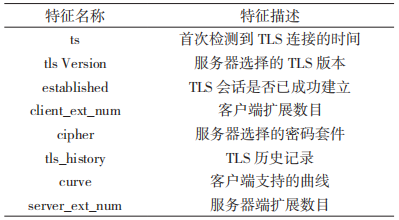
此外,观察到正常加密流量客户端支持的扩展种类丰富,恶意流量客户端扩展种类较为单一。提取出的 TLS 握手特征如表 1 所示。
表 1 TLS 握手特征
1.2.2 服务器证书特征分析和提取
服务器证书是用于验证服务器身份的文件,普通认证机构(Certificate Authority,CA)证书由可信的 CA 机构颁发。自签名证书任何人都可以颁发,它的 issuer 与 subject 相同。
在提取证书特征的过程中,证书的有效期、证书链的长度、证书是否自签名等重要特征指标无法直接获取,需要通过相应的算法来获得。图 3 展示了正常和恶意加密流量的服务器证书有效期时长对比和服务器证书的 issuer 长度对比。可以看出,正常的加密流量证书有效期较短,有 58% 的正常会话证书有效期是 80 天左右。而恶意加密流量有效期时间相对较长,甚至有 5.6% 达到 36 500 天。从服务器证书的 issuer 长度可以看出,60% 的正常加密会话的服务器证书 issuer 长度为 1,而恶意流量证书 issuer 长度为 2 和 3 的占比 86%。此外,观察到 TLS 服务器使用自签名证书的频率和使用公钥的长度等指标在恶意和正常加密流量中也有明显区别。提取出的服务器证书特征如表 2 所示。
1.2.3 会话的特征分析和提取
会话特征是现有文献中的常见特征。通过观察发现,大部分恶意软件的接收数据包数量为 5~12个,而正常流量数据包的数量变化范围较大。恶意加密流量的连接状态为连接已建立,发起方中止RSTO 的最多,占比 43%,而正常加密流量的连接状态以正常建立和终止 SF 的居多。此外,包长度、包到达时间等也是重要的会话统计特征。提取出的会话特征如表 3 所示。
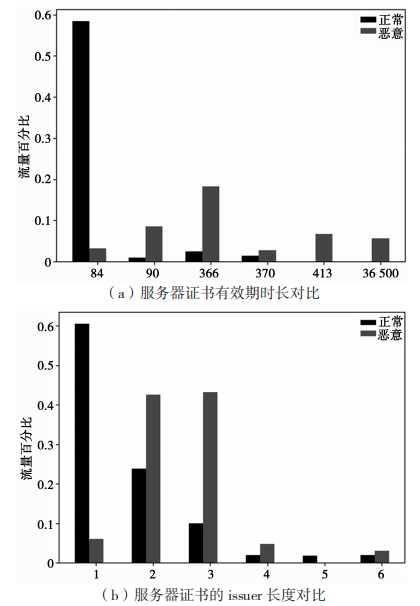
图 3 恶意和良性流量证书有效期和 issuer 长度对比
表 2 证书特征
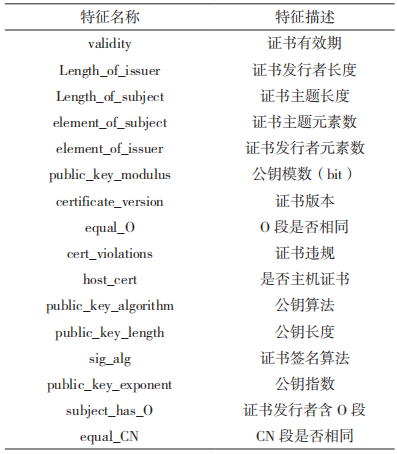
表 3 会话特征
02
基于 Stacking 集成学习的加密恶意流量检测方法
2.1 Stacking 集成模型
Stacking 是组合异质分类器的集成学习方法,它融合不同的学习算法实现高精度的分类任务,能够有效降低泛化误差,并通过元学习器来取代Bagging 的投票法,来综合降低偏差和方差。同时,Stacking 作为一种集成框架,往往采用两层结构,第 1 层组合多个基学习器输出特征,第 2 层使用元学习器组合第 1 层的输出特征,给出最终的预测结果。研究表明,Stacking 在增加有限计算开销的同时,有出色的性能和鲁棒性。
Stacking 算法共分成 3 个步骤:
(1)根据原始数据 D 训练第一层分类器,一共有T个分类器,其中ht是第t次循环得到的分类器;(2)根据第一层分类器的输出,构造新的数据集,第一层的预测结果将作为数据的新特征,原始数据的标签成为新数据的标签;(3)根据新的数据集训练第二层分类器得到新的分类器 h´,对于每一个数据实例 x, 分类器的预测结果为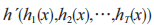 , 其 中,
, 其 中,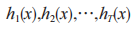 表示第一层中的分类器。
表示第一层中的分类器。
Stacking 算法伪代码如下:


2.2 Stacking 模型构建
Stacking 集成方法通过将不同的算法结合在一起,发挥每个算法的优势来获得更佳的预测性能。在构建 Stacking 集成模型中,首先需要确定基学习器的种类,而基学习器的选择需从准确性和多样性两个方面考虑。
从基学习器的预测性能方面考虑,本文除了选择 随 机 森 林(Random Forest,RF) 和 LightGBM[13]模型作为基学习器,还选择了其他预测性能优异的模型。其中,XGBoost 针对传统的梯度提升决策树进行改进,在训练时间等方面都有所提升。
为了获得最佳的集成模型,还需要考虑基学习器之间的相关性。选择相关性较小的算法能够充分发挥不同算法的优势 ,达到互补的目的。本文采用 Pearson 相关系数衡量算法之间的相关性大小,
其表达式为:
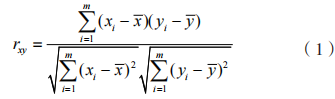
式中: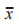 和
和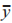 分别为各向量中元素的平均值。最后,依据基分类器追求“准而不同”的原则,初步选 择 RF、K 近 邻(K-Nearest Neighbor,KNN)、XGBoost、支持向量机(Support Vector Machine,SVM)和 LightGBM 作为基学习器。
分别为各向量中元素的平均值。最后,依据基分类器追求“准而不同”的原则,初步选 择 RF、K 近 邻(K-Nearest Neighbor,KNN)、XGBoost、支持向量机(Support Vector Machine,SVM)和 LightGBM 作为基学习器。
Wolpert 在提出 Stacking 时,就说明了元学习算法和新数据的属性表示对 Stacking 集成的泛化性能影响很大 。对于输出类概率的初级分类器,分类器 h 对样例 x 的预测是,x 属于所有可能类标签的概率为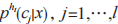 ,其中,
,其中, 是指个分类问题,
是指个分类问题,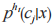 定义了分类器 h 估计样例 x 属于类别
定义了分类器 h 估计样例 x 属于类别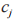 的概率值。将基分类器对所有类预测的后验概率作为元层学习器的输入属性,乘以最大概率的概率分布,其表达式为:
的概率值。将基分类器对所有类预测的后验概率作为元层学习器的输入属性,乘以最大概率的概率分布,其表达式为:
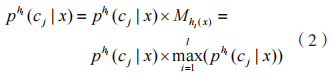
概率分布的熵为:
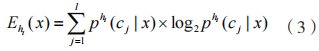
元模型通常很简单,为了减轻过拟合,第二层元学习器选择逻辑回归模型。本文构建的基于Stacking 的加密恶意流量检测模型如图 4 所示。
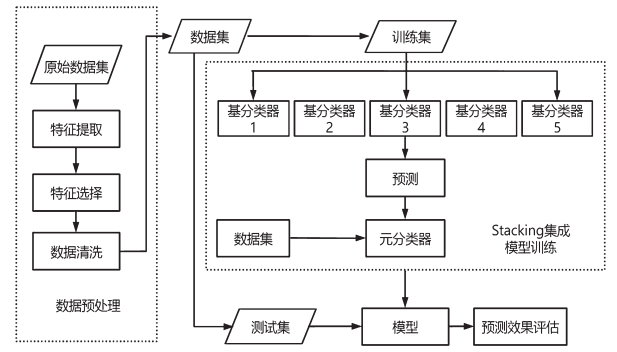
图 4 基于 Stacking 的恶意加密流量识别算法流程
03
实验结果及分析
3.1 实验环境与数据集
本文采用 scikit-learn 机器学习库构建 Stacking模型并完成实验评估,在 Windows 10 环境下运行,处理器为 AMD Ryzen 4800H,图形处理器(GraphicsProcessing Unit,GPU)为 RTX 2060,内存为 16 GB。
本实验选用 DataCon 开放数据集 ,源自 2020年 2—6 月收集的恶意软件与正常软件,经奇安信技术研究院天穹沙箱运行并采集其产生的流量筛选生成,数据集格式为 pcap 文件。由于本文研究需要更精确的数据集,对数据进行以下处理:
(1)过滤未完成完整握手过程的会话;(2)过滤确认包、重传包及传输丢失的坏包;(3)借助 Zeek[18] 将 pcap 包转换为流量日志,进行特征提取;(4)特征提取后对非数值型的特征流量使用One-Hot 编码,满足模型输入的需要;(5)对特征的缺失值和异常值进行处理,采用 Z-score 对数据进行标准化。经过数据预处理后,最终的数据集如表 4 所示。
表 4 最终数据集构成

3.2 评价指标
本文采用精确率(Precision)、召回率(Recall)、F1 值和 ROC 曲线下方的面积(Area Under Curve,AUC)值作为评价指标来估计方法的分类效果。精确率(Precision)、召回率(Recall)和 F1 值的定义分别为:

式中:TP 为被模型预测为正类的正样本数量;FN为被模型预测为负类的正样本数量;FP 为被模型预测为正类的负样本数量。
3.3 特征性能对比
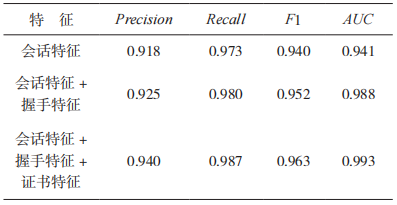
本文提取出会话统计特征 86 维,握手特征 62维和证书特征 31 维,共计 179 维特征向量。为了分析不同特征组合的性能,使用随机森林算法分别测试了 3 种特征组合下的识别效果,实验结果如表 5 所示。
表 5 不同的特征组合五折交叉验证结果
为了减小特征冗余和噪声,去除相关度高及有负影响的特征,使用特征筛选算法 Correlation AttributeEval,分别选择特征从 10 到 100 维的 10 种情况进行实验,确定特征维数为多少时,模型分类效果最佳,实验结果如图 5 所示。
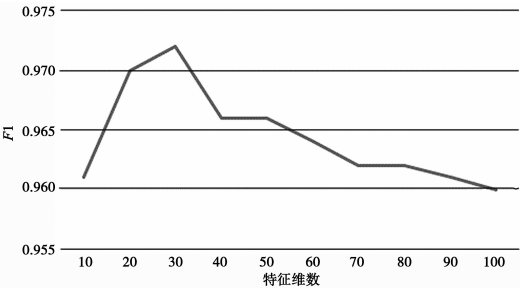
图 5 特征维数确定
当特征维数为 30 时,使用随机森林算法分类时,F1 最高,达到 97.2%。此后随着维数的增加,F1 值逐渐降低。因此,本文将特征维数缩减到 30 来进行实验,在提高识别效果的同时缩短了运行时间。不同特征组合下分类性能对比如图 6 所示。
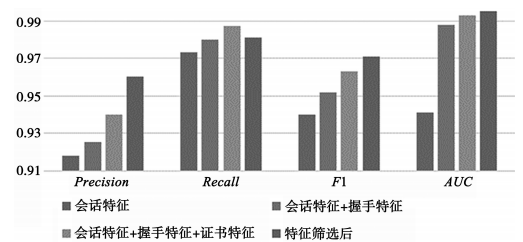
图 6 不同特征组合对检测结果的影响对比
可以看出多特征识别显著提升了模型精确率和召回率,特征筛选进一步提升了模型的性能。
3.4 元分类器选择
为 了 减 轻过 拟 合, 第 二 层 元 学 习 器 一 般 选择简单的模型,本文选择逻辑回归作为元分类器学习。表 6 比较了常用于 Stacking 模型中的 K 近邻(K-Nearest Neighbor,KNN)、 支 持 向 量 机(Support Vector Machine,SVM)和逻辑回归(LogisticRegression,LR)算法作为基分类器的差异。结果表明 LR 算法作为元学习器时,Stacking 模型表现最好。
表 6 元学习器对比

3.5 算法性能对比
将 本 文 构 建 的 Stacking 模 型 与 SVM、RF、XGBoost、CNN 算法对比,实验结果如表 7 所示。
表 7 算法性能对比
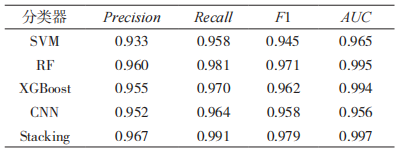
由表 7 可以看出,本文构建的 Stacking 模型的查准率、召回率、F1 值和 AUC 值均高于其他算法模型。与 SVM 相比,分别提高了 3.4%,3.3%,3.4%和 3.2%;与 XGBoost 相比,分别提高了 2.2%,2.1%,1.7% 和 0.3%;与 CNN 相比,分别提高了 1.5%,2.7%,2.1% 和 4.1%。因此,通过上述对实验结果的分析,验证了本文提出的基于 Stacking 的网络恶意加密流量识别方法的可行性。
04
结 语
本文通过分析大量的正常和恶意加密流量,从中提取出具有显著区分度的会话特征、握手特征和证书特征。对单一特征和多特征识别网络恶意加密流量进行对比,结果表明加入了握手和证书特征后可以显著提升模型的识别效果。构建基于 Stacking集成学习的网络恶意加密流量检测模型,实验表明,在 Datacon2020 数据集下,本文 Stacking 模型效果比 XGBoost 等 4 种算法效果均有所提升,解决了单一的机器学习方法泛化能力弱的问题。此外,文章还存在一些不足之处,如在构建 Stacking 模型时可以尝试更多基分类器和元分类器的组合,从而作出更优的选择,这也是今后进一步研究的方向。
