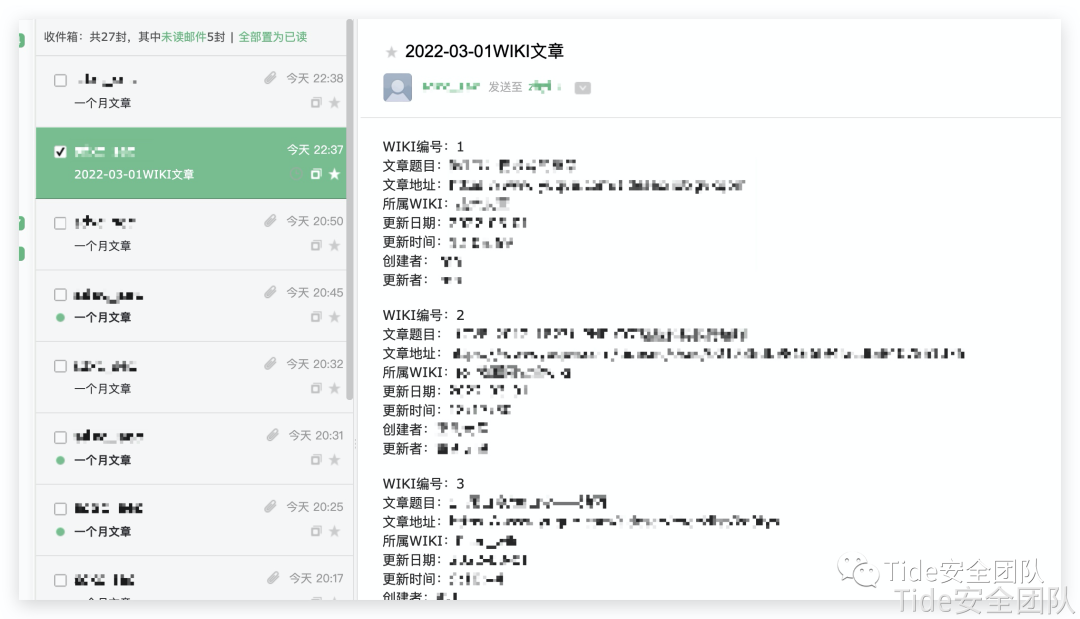
语雀文章监测脚本设计与实现—yuqueGetter
0x01 功能介绍
语雀是一个很方便的知识库整理工具,每天都会有很多小伙伴在语雀上更新自己的文章
Tide安全团队Wiki知识库:
https://www.yuque.com/tidesec
Tide安全团队的小伙伴每天都会把自己的学习过程及学习成功更新到语雀中,为了更方便读者每天阅读小伙伴的文章,lmn在此设计了一个小程序可以每天获取一次当天在某个语雀知识库中的更新文章
总功能有两个
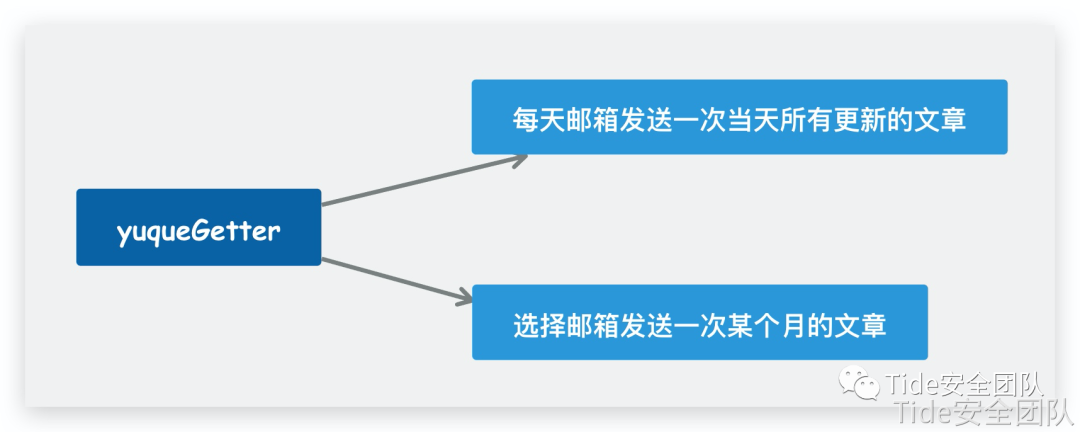
功能实现
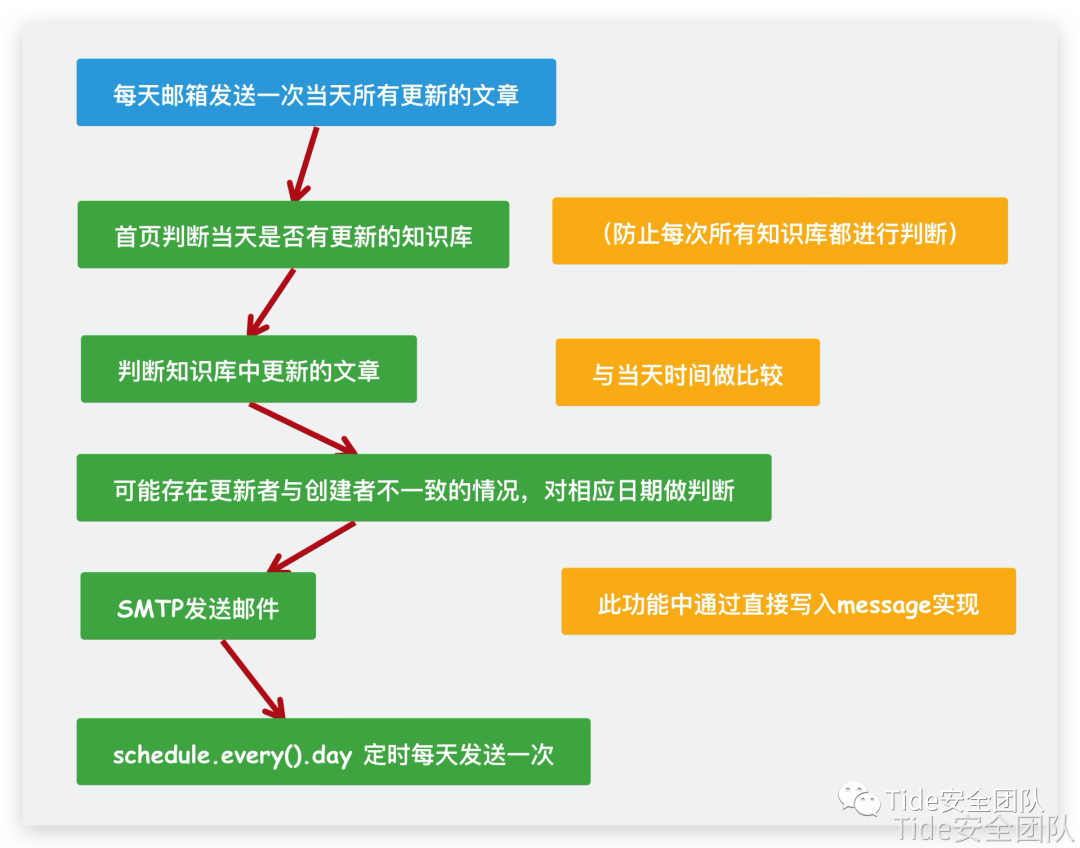
首先第一个功能:实现每天往相应的邮箱发送一次此知识库所有更新的文章
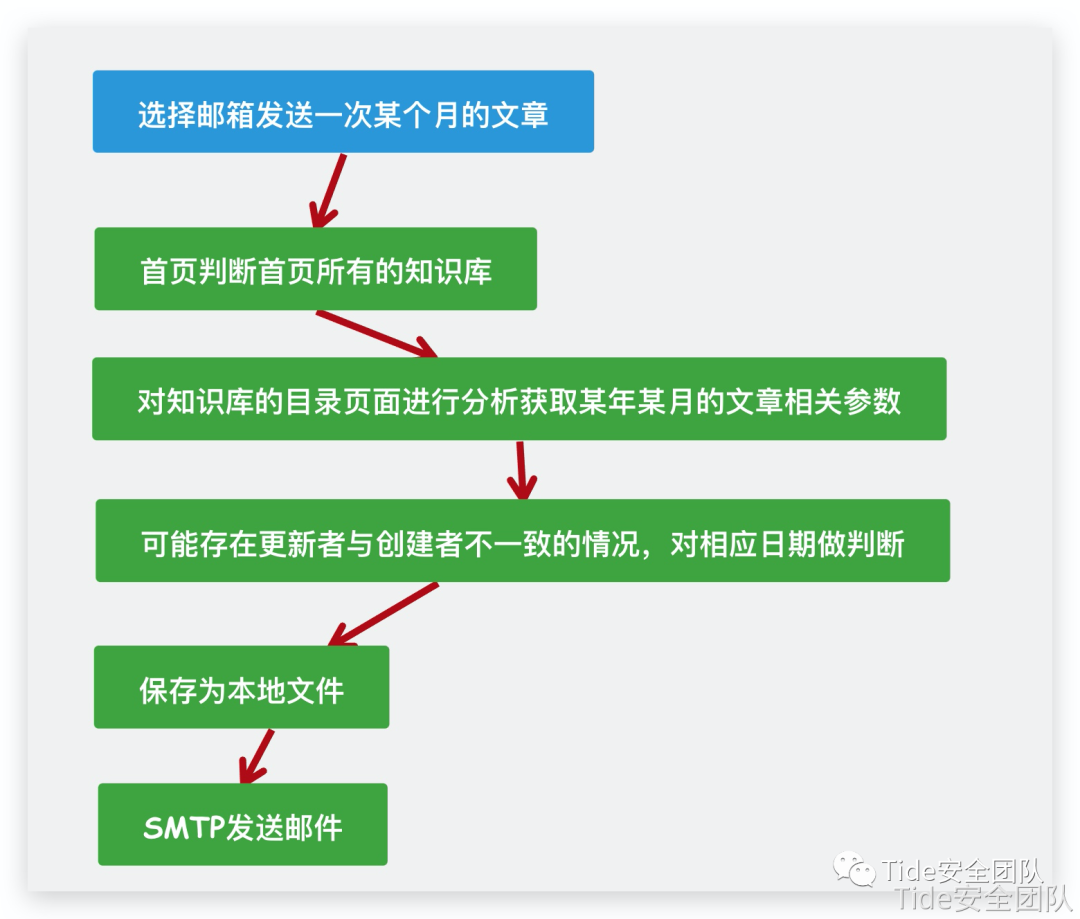
第二个功能:用户可以选择某年某月的文章获取更多想要的内容
0x02 具体实现代码
引入头文件 & 获取当前时间,方便下面做判断
# -*- coding = utf-8 -*-# @Time : 2022/2/28 4:12 下午# @Author : lmn# @File : yuque.py# @Software : PyCharm
import jsonfrom urllib import request, parseimport reimport scheduleimport timefrom email.mime.multipart import MIMEMultipartimport urllib.request
import sslssl._create_default_https_context = ssl._create_unverified_context
# 获取当前时间Time = time.strftime('%Y-%m-%d', time.localtime(time.time()))
模拟头部获取返回信息,user-Agent 与 Cookie 可通过抓包或直接网页获取

# 得到一个网页内容def askUrl(url): # 模拟头部 head = { "User-Agent": "XXXX", "Cookie": "XXXX" } req = urllib.request.Request(url, headers=head) html = "" try: # 异常处理 response = urllib.request.urlopen(req) html = response.read().decode("utf-8") # print(html) except Exception as e: print(e) return html
判断首页是否更新过,如果不从首页判断,只能通过对每个分支的语雀WIKI库进行判断,可能造成大量的不必要的运行,此段目的是为了提高判断效率,减少运行时间
部分注释用与测试,可自行测试
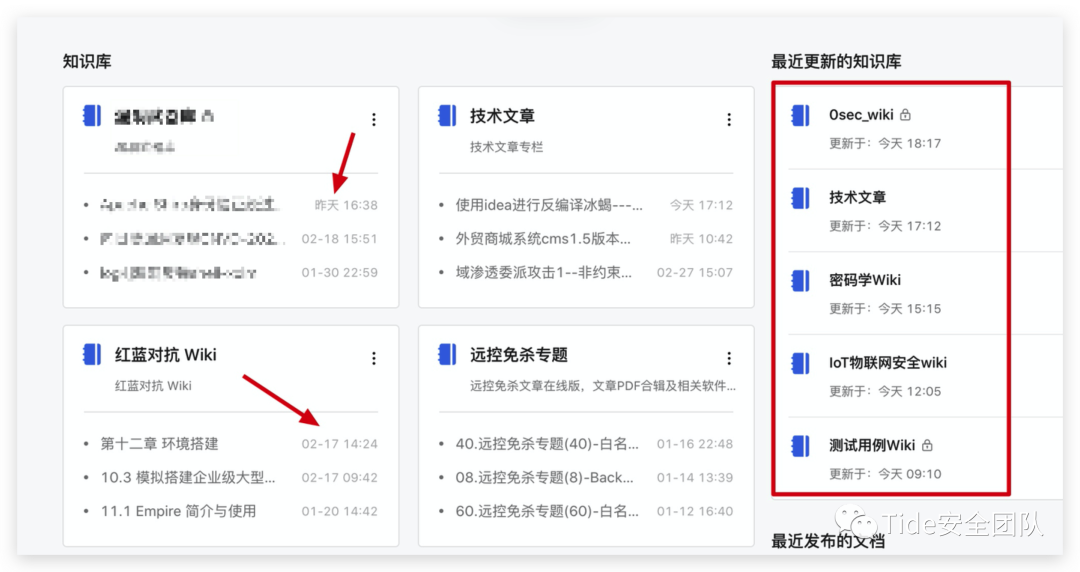
判断只判断每个知识库的第一条,若有今天的文章则判定这个知识库今天更新过
虽然首页显示“最近更新的知识库”,但只能显示五条,为了提高近准读,这里不通过“最近更新的知识库”直接判断
# 判断哪个WIKI更新过def judgeUpdate(url): # 1. 获取网页 html = askUrl(url) data = json.loads(html) updateWikiName = [] # 已更新的WIKI名称 updateWikiUrl = [] # 已更新的WIKI地址 updateWiki = [] # 已更新的WIKI集 for x in data['data'][1]['placements'][0]['blocks'][0]['data'][0]['books']: # 判断主页更新的文章 # print(x['name'], 'https://www.yuque.com/tidesec/' + x['slug'], x['summary'][0]['updated_at'][0:10]) # 判断是否为今天 if x['summary'][0]['updated_at'][0:10] == Time: # 更新的名称 updateWikiName.append(x['name']) # 更新的地址 updateWikiUrl.append('https://www.yuque.com/tidesec/' + x['slug']) # print("今天的文章") # print(updateWikiUrl) # 打印时间 # print(time.strftime('%Y-%m-%d', time.localtime(time.time())))
updateWiki.append(updateWikiName) updateWiki.append(updateWikiUrl) return updateWiki # 返回['Wiki名','地址']
在我们已经知道哪些数据库更新过后,通过如下函数可以判断某知识库中哪些文章更新过
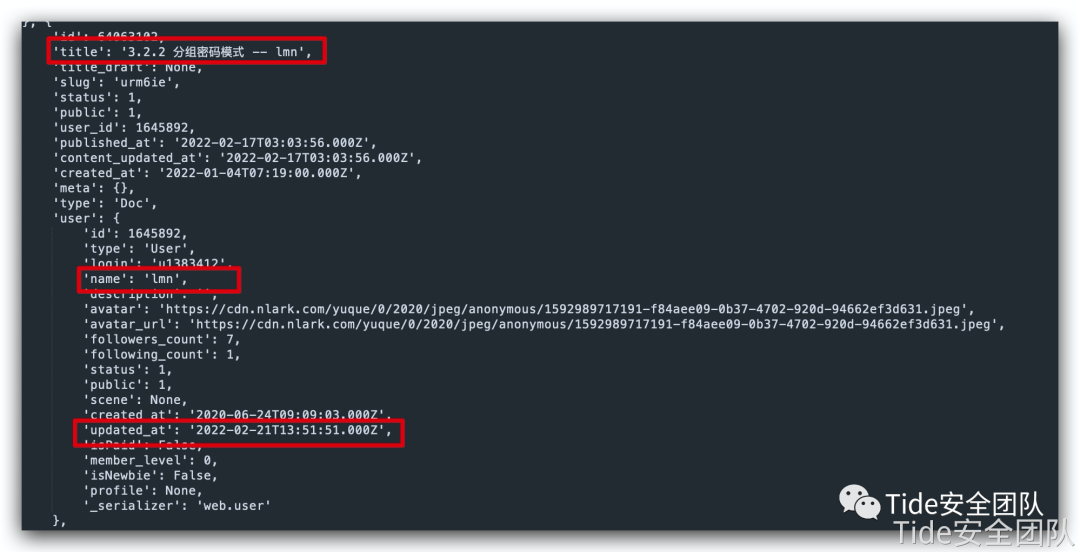
返回相关参数用于输出与发送邮件
# 返回更新过的WIKI并返回固定格式def uploadArticleALL(ArticleALL): document = open("ArticleOneMonth.txt", "w+") content = [] b = '' content2 = [] for y in ArticleALL: # [[编号], [题目], [地址], [所属WIKI], [更新日期],[时间], [作者]] y[5] = str(int(y[5][0:2]) + 8) + y[5][2:10] newUser = checkUser(y, y[4], y[5]) content2 = "WIKI编号:" + str(y[0]) + "" + "文章题目:" + y[1] + "" + "文章地址:" + y[2] + "" + "所属WIKI:" + y[3] + "" + "更新日期:" + y[4] + "" + "更新时间:" + y[5] + "" + "创建者:" + y[6] + "" + "更新者:" + newUser + "" print(content2) content.append(content2) # print(b.join(content)) # sendEmail(b.join(content)) # print(b.join(content)) Result = b.join(content) document.write(Result) document.close() sendEmail("NULL", "file")
到这里不算完,测试时发现一个巨型坑,这里虽然通过目录文章给出的信息获取到作者参数,但若文章被第二作者更新,这里并不显示
也就是最后更新的作者现在无名无姓没有人知道(除非点进去在最下面才能看到)
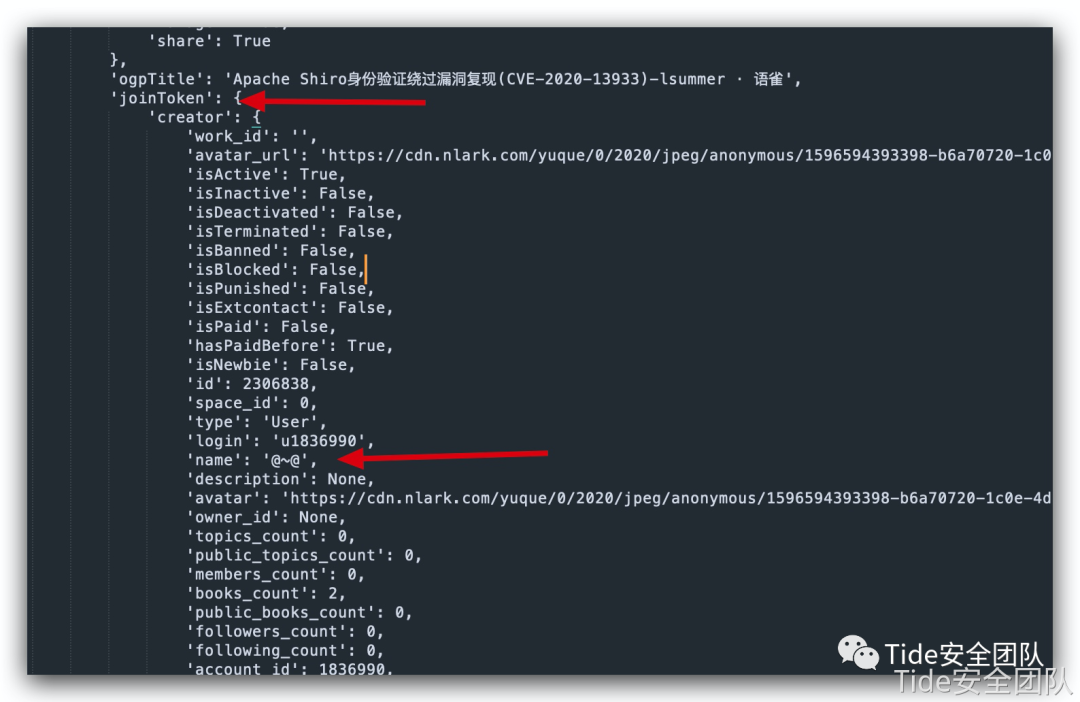
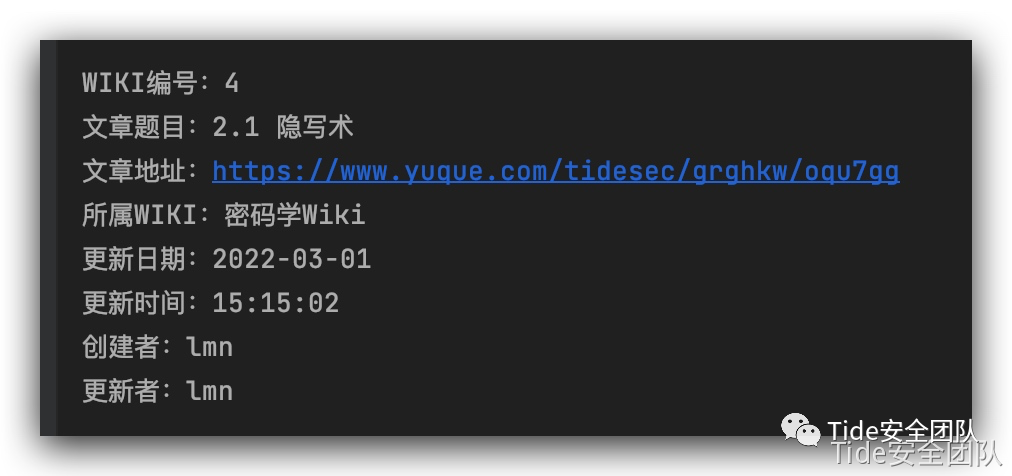
这里通过设计一个checkUser函数判断两者最后更新的时间,通过判断年月日小时分钟秒来精确判断谁是最后一个更新的
但是这里又不能说最后更新的是写文章的人,所以我们显示更新和创建两个人的名字
def checkUser(updateArticleALL, articleDate, articleTime): All = [] html = askUrl(updateArticleALL[2]) # print(html) pattern = re.compile(r"decodeURIComponent\(\"(.+?)\"\)") tags = re.findall(pattern, html) # s = urllib.parse.unquote(tags[0]) data = json.loads(urllib.parse.unquote(tags[0])) for y in data: All.append(y) # print(All) if "book" not in All: # print(updateArticleALL[5]) return 1 else: # print(data) # print(data['doc']['joinToken']['creator']['name']) if int(articleDate[0:4])>int(data['doc']['joinToken']['creator']['updated_at'][0:4]): return 1 elif int(articleDate[5:7])>int(data['doc']['joinToken']['creator']['updated_at'][5:7]): return 1 elif int(articleDate[8:10])>int(data['doc']['joinToken']['creator']['updated_at'][8:10]): return 1 elif int(articleTime[0:2]+8) > int(data['doc']['joinToken']['creator']['updated_at'][11:13]): return 1 elif int(articleTime[3:5]) > int(data['doc']['joinToken']['creator']['updated_at'][14:16]): return 1 elif int(articleTime[6:8]) > int(data['doc']['joinToken']['creator']['updated_at'][17:19]): return 1 else: return data['doc']['joinToken']['creator']['name']
(这里应该设置时区,但方便期间+8计算)
下面这段代码用于调整一个最好的格式用于发送邮件
def uploadArticleALL(ArticleALL): document = open("ArticleOneMonth.txt", "w+") content = [] b = '' content2 = [] for y in ArticleALL: # [[编号], [题目], [地址], [所属WIKI], [更新日期],[时间], [作者]] y[5] = str(int(y[5][0:2]) + 8) + y[5][2:10] newUser = checkUser(y, y[4], y[5]) if (newUser) == 1: newUser = y[6] content2 = "WIKI编号:" + str(y[0]) + "" + "文章题目:" + y[1] + "" + "文章地址:" + y[2] + "" + "所属WIKI:" + y[3] + "" + "更新日期:" + y[4] + "" + "更新时间:" + y[5] + "" + "创建者:" + y[6] + "" + "更新者:" + newUser + "" print(content2) content.append(content2) # print(b.join(content)) # sendEmail(b.join(content)) # print(b.join(content)) Result = b.join(content) document.write(Result) document.close() sendEmail("NULL", "file")
下面这段代码用于实现在第二个功能中,我们需要获取所有目录中的文章相关参数
# 或者某个WIKI主页的内容并返回更新过的文章def getWiki(updateWiki): updateWikiUrl = updateWiki[1] updateArticleALL = [] count = 0 for i in updateWikiUrl: # print(i) html = askUrl(i) # print(html) pattern = re.compile(r"decodeURIComponent\(\"(.+?)\"\)") # 正则表达式匹配 tags = re.findall(pattern, html) # s = urllib.parse.unquote(tags[0]) data = json.loads(urllib.parse.unquote(tags[0])) # print(data['book']['docs']) for y in data['book']['docs']: # print(y['title'], y['content_updated_at'][0:10]) if y['content_updated_at'][0:10] == Time: count += 1 # [[编号], [题目], [地址], [所属WIKI], [更新时间], [作者]] updateArticle = [count, y['title'], i + '/'+y['slug'], updateWiki[0][count-1], y['content_updated_at'], y['user']['name']] updateArticleALL.append(updateArticle) # print(updateArticleALL) # 打印时间 # print(time.strftime('%Y-%m-%d', time.localtime(time.time()))) return updateArticleALL
这个函数用于第二个功能获取某个知识库中某个Wiki的相关参数
# 获取某个Wiki全部内容def getAllWiki(Wiki, Year, Month): WikiUrl = Wiki[1] ArticleALL = [] count = 0 count2 = 0 for i in WikiUrl: # print(i) html = askUrl(i) pattern = re.compile(r"decodeURIComponent\(\"(.+?)\"\)") tags = re.findall(pattern, html) data = json.loads(urllib.parse.unquote(tags[0])) count += 1 for y in data['book']['docs']: if y['content_updated_at'][0:4] == Year: if y['content_updated_at'][6:7] == Month: count2 += 1 Article = [count2, y['title'], i + '/' + y['slug'], Wiki[0][count - 1], y['content_updated_at'][0:10], y['content_updated_at'][11:19], y['user']['name']] # Article = [y['title'], i + '/' + y['slug'], Wiki[0][count - 1]] ArticleALL.append(Article) return ArticleALL
下面就是发送邮件的代码!
这里通过163邮箱
首先设置一下
新增授权密码
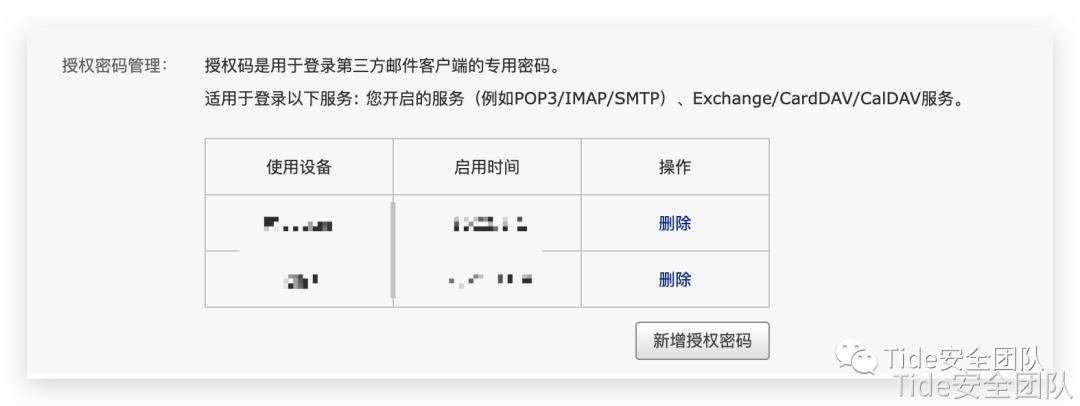
之后通过函数实现,因为两个功能都通过这个函数进行发送
但由于第二个功能输出过多,所以采用附件的形式,这里通过采用判断实现具体功能
# 发送邮箱def sendEmail(content, type): import smtplib from email.header import Header from email.mime.text import MIMEText # 第三方 SMTP 服务 mail_host = "XXXX" # SMTP服务器 mail_user = "XXXX" # 用户名 mail_pass = "XXXX" # 授权密码
sender = 'XXXX' # 发送方
receivers = ['XXXX'] # 接收方1 receivers2 = ['XXXX'] # 接收方2 receiver = receivers + receivers2
content = content title = Time+'WIKI文章' if type == "text": message = MIMEText(content, 'plain', 'utf-8') message['From'] = "{}".format(sender) message['To'] = ",".join(receivers) message['Subject'] = title elif type == "file":
# 创建一个带附件的实例 message = MIMEMultipart() message['From'] = "{}".format(sender) message['To'] = ",".join(receivers) message['Subject'] = "一个月文章"
# 邮件正文内容 message.attach(MIMEText('一个月的文章请查收', 'plain', 'utf-8'))
# 构造附件1,传送当前目录下的 test.txt 文件 att1 = MIMEText(open('ArticleOneMonth.txt', 'rb').read(), 'base64', 'utf-8') att1["Content-Type"] = 'application/octet-stream' # 这里的filename可以任意写,写什么名字,邮件中显示什么名字 att1["Content-Disposition"] = 'attachment; filename="ArticleOneMonth.txt"' message.attach(att1) try: smtpObj = smtplib.SMTP_SSL(mail_host, 465) smtpObj.login(mail_user, mail_pass) smtpObj.sendmail(sender, receiver, message.as_string()) print("mail has been send successfully.") except smtplib.SMTPException as e: print(e)
这里又有一个坑,这里我在设置显示格式时设置了center,但这里需要html的居中
踩坑代码如下
content1 = "文章题目".center(50 - 4, ' ') + "文章地址".center(50 - 4, ' ') + "作者名".center(50 - 3, ' ')content = []content.append(content1)c = ''b = ''for y in updateArticleALL: content2 = [] for i in y: content2.append(i.center(50 - len(re.findall('([\u4e00-\u9fa5])', i)), ' ')) content.append(c.join(content2))print(b.join(content))
实现每天都发送的函数如下:
def everyDay(): global Time Time = time.strftime('%Y-%m-%d', time.localtime(time.time())) # 判断是否有更新 mainUrl = "https://www.yuque.com/api/groups/1542173/homepage?include_data=true" # 更新的文章的地址 updateWiki = judgeUpdate(mainUrl) # 获取文章 updateArticleALL = getWiki(updateWiki)
# updateArticleUserALL = checkUser(updateArticleALL)
# 发送邮件 content = [] b = '' content2 = [] for y in updateArticleALL: y[4] = y[4][0:11] + str(int(y[4][11:13])+8) + y[4][13:19] newUser = checkUser(y, y[4][0:10], y[4][11:19]) if (newUser) == 1: newUser = y[5] # [[编号], [题目], [地址], [所属WIKI], [更新时间], [作者]] content2 = "WIKI编号:" + str(y[0]) + "" + "文章题目:" + y[1] + "" + "文章地址:" + y[2] + "" + "所属WIKI:" + y[3] + "" + "更新日期:" + y[4][0:10] + "" + "更新时间:" + y[4][11:19] + "" + "创建者:" + y[5] + "" + "更新者:" + newUser + "" content.append(content2) # print(b.join(content)) sendEmail(b.join(content), "text")
实现发送某个月的总文章如下
def oneMonth(Year, Month): mainUrl = "https://www.yuque.com/api/groups/1542173/homepage?include_data=true" html = askUrl(mainUrl) data = json.loads(html) WikiName = [] WikiUrl = [] Wiki = [] for x in data['data'][1]['placements'][0]['blocks'][0]['data'][0]['books']: WikiName.append(x['name']) WikiUrl.append('https://www.yuque.com/tidesec/'+x['slug']) Wiki.append(WikiName) Wiki.append(WikiUrl) ArticleALL = getAllWiki(Wiki, Year, Month) uploadArticleALL(ArticleALL)
主函数
def main(): print("Welcome To Use yuqueGetter") choose = 1 while choose: print("***** 1 每天发一次当天更新文章 *****") print("***** 2 选择接收某个月的文章 *****") print("***** 0 退出 *****") choose = int(input("please choose the function:>")) if choose == 1: # schedule.every(1).minutes.do(everyDay) # 每分钟,测试用 schedule.every().day.at("23:55").do(everyDay) while True: schedule.run_pending() time.sleep(1) elif choose == 2: Year = input("选择年份(2020、2021、2022):>") Month = input("选择月份(1、2 ... 11、12):>") oneMonth(Year, Month) elif (choose < 0) or (choose > 2): print("请重新输入")
if __name__ == '__main__': main()
其中每天都定时发送的语句(已包含在代码中)
schedule.every().day.at("23:55").do(everyDay)
最后,也可自行添加功能,例如爬取全部文章
def ALLWIKI(Year, Month): mainUrl = "https://www.yuque.com/api/groups/1542173/homepage?include_data=true" html = askUrl(mainUrl) data = json.loads(html) WikiName = [] WikiUrl = [] Wiki = [] for x in data['data'][1]['placements'][0]['blocks'][0]['data'][0]['books']: WikiName.append(x['name']) WikiUrl.append('https://www.yuque.com/tidesec/'+x['slug']) Wiki.append(WikiName) Wiki.append(WikiUrl) getAllWiki(Wiki)
0x03 实现效果
运行效果
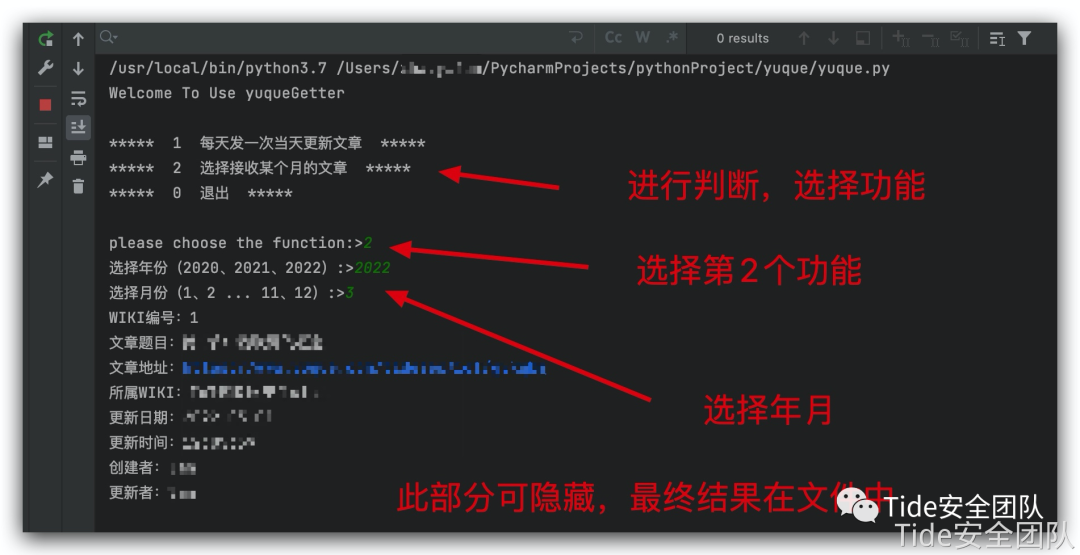
保存文件中
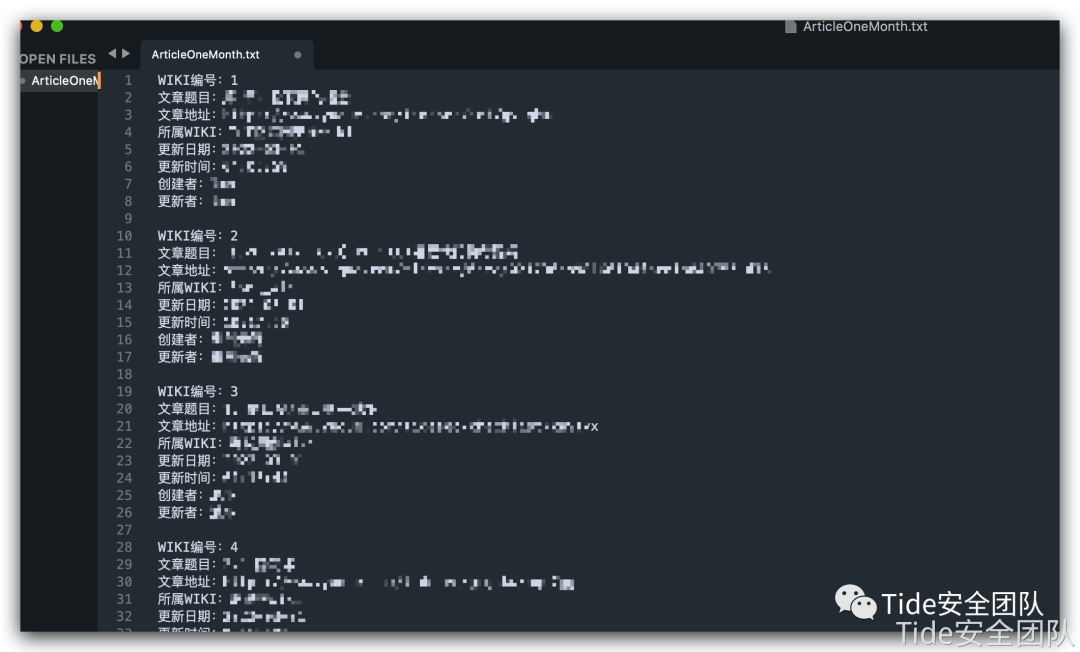
发送方
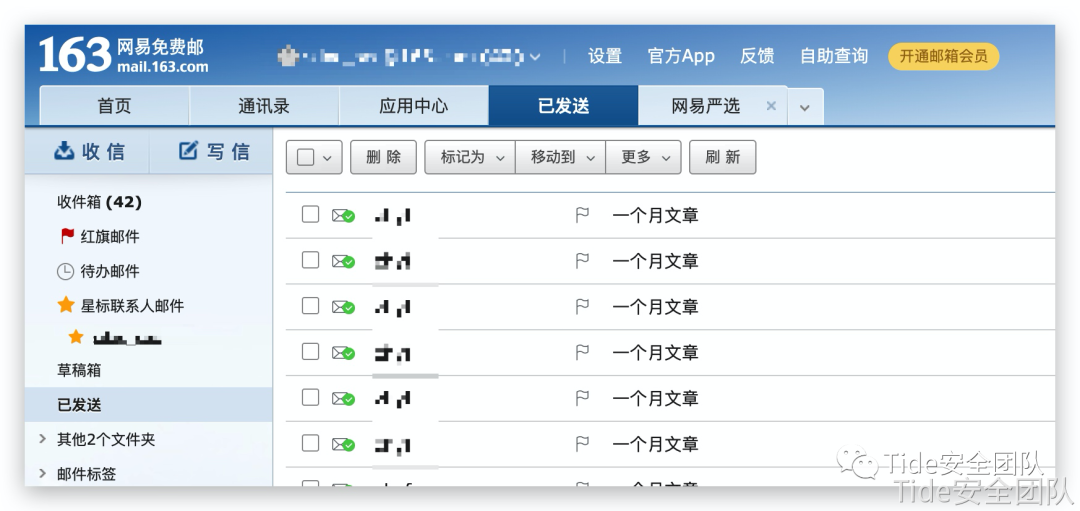
第二个功能接收方效果
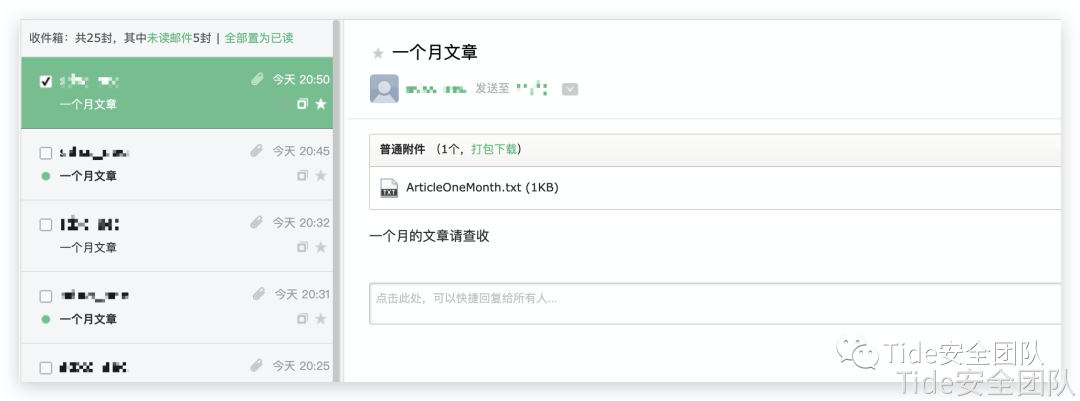
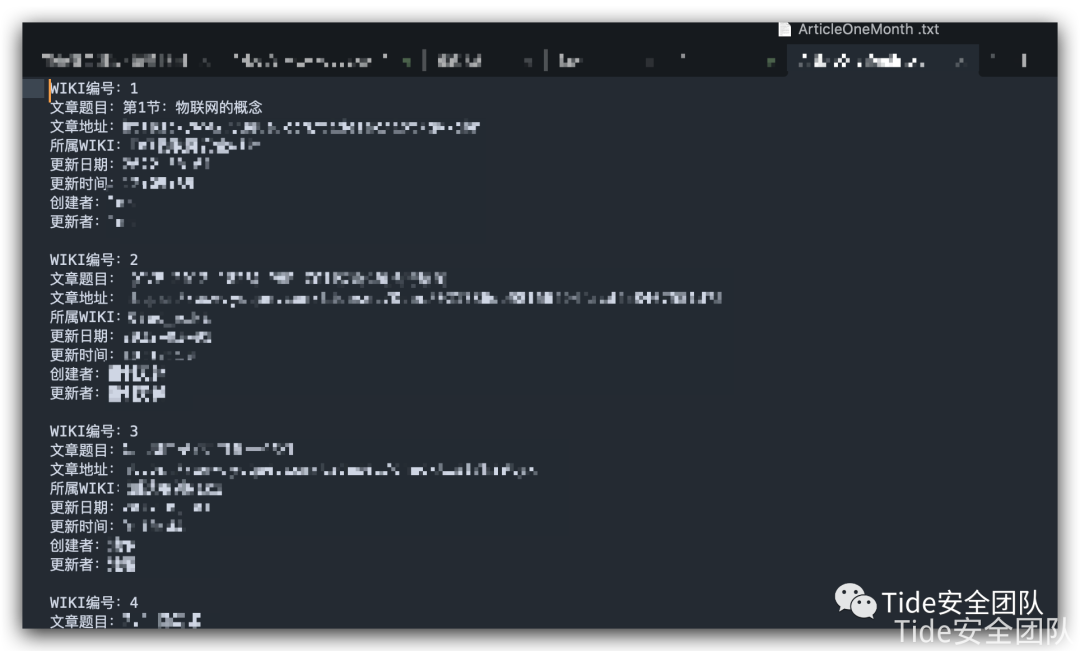
第一个功能接收方效果