分布式任务 + 消息队列框架 go-queue
为什么要写这个库?
在开始自研 go-queue 之前,针对以下我们调研目前的开源队列方案:
beanstalkd
beanstalkd 有一些特殊好用功能:支持任务 priority、延时 (delay)、超时重发 (time-to-run) 和预留 (buried),能够很好的支持分布式的后台任务和定时任务处理。如下是 beanstalkd 基本部分:
job:任务单元;tube:任务队列,存储统一类型job。producer 和 consumer 操作对象;producer:job生产者,通过 put 将 job 加入一个 tube;consumer:job消费者,通过 reserve/release/bury/delete 来获取 job 或改变 job 的状态;
很幸运的是官方提供了 go client:https://github.com/beanstalkd/go-beanstalk。
但是这对不熟悉 beanstalkd 操作的 go 开发者而言,需要学习成本。
kafka
类似基于 kafka 消息队列作为存储的方案,存储单元是消息,如果要实现延时执行,可以想到的方案是以延时执行的时间作为 topic,这样在大型的消息系统中,充斥大量一次性的 topic(dq_1616324404788, dq_1616324417622),当时间分散,会容易造成磁盘随机写的情况。
而且在 go 生态中,
同时考虑以下因素:
- 支持延时任务
- 高可用,保证数据不丢失
- 可扩展资源和性能
所以我们自己基于以上两个基础组件开发了 go-queue:
- 基于
beanstalkd开发了dq,支持定时和延时操作。同时加入redis保证消费唯一性。 - 基于
kafka开发了kq,简化生产者和消费者的开发 API,同时在写入 kafka 使用批量写,节省 IO。
整体设计如下:
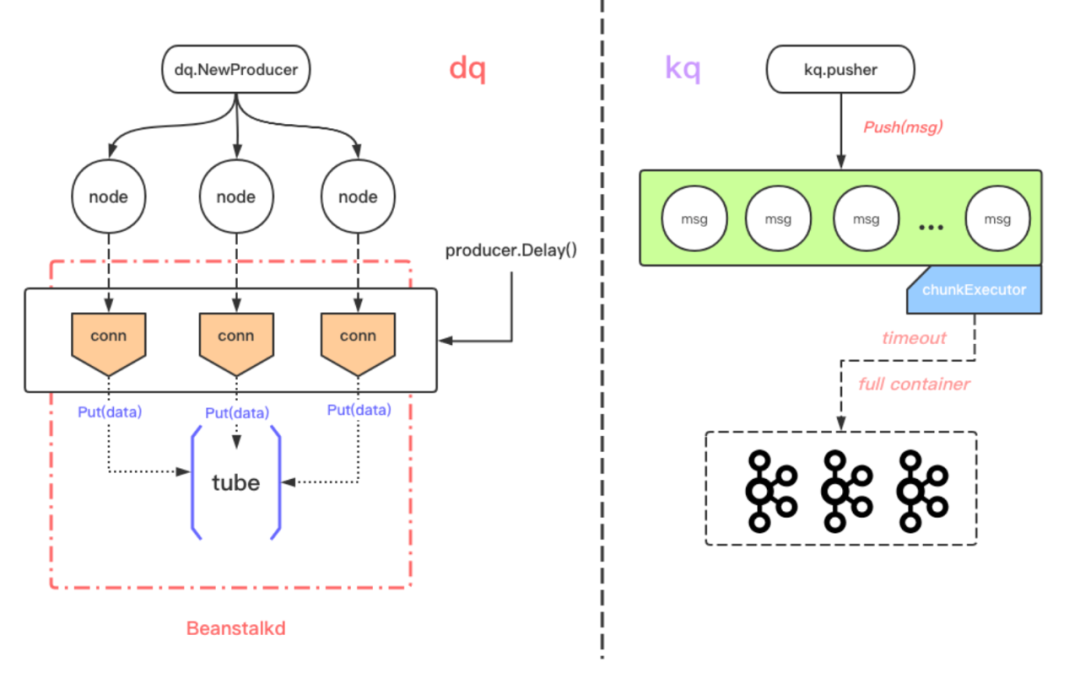
应用场景
首先在消费场景来说,一个是针对任务队列,一个是消息队列。而两者最大的区别:
- 任务是没有顺序约束;消息需要;
- 任务在加入中,或者是等待中,可能存在状态更新(或是取消);消息则是单一的存储即可;
所以在背后的基础设施选型上,也是基于这种消费场景。
dq:依赖于beanstalkd,适合延时、定时任务执行;kq:依赖于kafka,适用于异步、批量任务执行;
而从其中 dq的 API 中也可以看出:
// 延迟任务执行 - dq.Delay(msg, delayTime); // 定时任务执行 - dq.At(msg, atTime);
而在我们内部:
- 如果是 异步消息消费/推送 ,则会选择使用
kq:kq.Push(msg); - 如果是 15 分钟提醒/ 明天中午发送短信 等,则使用
dq;
如何使用
分别介绍dq和 kq的使用方式:
dq
// [Producer]
producer := dq.NewProducer([]dq.Beanstalk{
{
Endpoint: "localhost:11300",
Tube: "tube",
},
{
Endpoint: "localhost:11301",
Tube: "tube",
},
})
for i := 1000; i < 1005; i++ {
_, err := producer.Delay([]byte(strconv.Itoa(i)), time.Second*5)
if err != nil {
fmt.Println(err)
}
}
// [Consumer]
consumer := dq.NewConsumer(dq.DqConf{
Beanstalks: []dq.Beanstalk{
{
Endpoint: "localhost:11300",
Tube: "tube",
},
{
Endpoint: "localhost:11301",
Tube: "tube",
},
},
Redis: redis.RedisConf{
Host: "localhost:6379",
Type: redis.NodeType,
},
})
consumer.Consume(func(body []byte) {
// your consume logic
fmt.Println(string(body))
})
和普通的 生产者 - 消费者 模型类似,开发者也只需要关注以下:
- 开发者只需要关注自己的任务类型「延时/定时」
- 消费端的消费逻辑
kq
producer.go:
// message structure
type message struct {
Key string `json:"key"`
Value string `json:"value"`
Payload string `json:"message"`
}
pusher := kq.NewPusher([]string{
"127.0.0.1:19092",
"127.0.0.1:19093",
"127.0.0.1:19094",
}, "kq")
ticker := time.NewTicker(time.Millisecond)
for round := 0; round < 3; round++ {
select {
case <-ticker.C:
count := rand.Intn(100)
// 准备消息
m := message{
Key: strconv.FormatInt(time.Now().UnixNano(), 10),
Value: fmt.Sprintf("%d,%d", round, count),
Payload: fmt.Sprintf("%d,%d", round, count),
}
body, err := json.Marshal(m)
if err != nil {
log.Fatal(err)
}
fmt.Println(string(body))
// push to kafka broker
if err := pusher.Push(string(body)); err != nil {
log.Fatal(err)
}
}
}
config.yaml:
Name: kq Brokers: - 127.0.0.1:19092 - 127.0.0.1:19092 - 127.0.0.1:19092 Group: adhoc Topic: kq Offset: first Consumers: 1
consumer.go:
var c kq.KqConf
conf.MustLoad("config.yaml", &c)
// WithHandle: 具体的处理msg的logic
// 这也是开发者需要根据自己的业务定制化
q := kq.MustNewQueue(c, kq.WithHandle(func(k, v string) error {
fmt.Printf("=> %s\n", v)
return nil
}))
defer q.Stop()
q.Start()
和 dq 不同的是:开发者不需要关注任务类型(在这里也没有任务的概念,传递的都是 message data)。
其他操作和 dq 类似,只是将 业务处理函数 当成配置直接传入消费者中。
总结
在我们目前的场景中,kq 大量使用在我们的异步消息服务;而延时任务,我们除了 dq,还可以使用内存版的 TimingWheel「go-zero 生态组件」。
关于 go-queue 更多的设计和实现文章,可以持续关注我们。欢迎大家去关注和使用。
