基于文本分类的隐私政策合规性分析
VSole2022-05-26 05:56:31
介绍
本文针对GDPR中的第13章对隐私政策进行合规性研究。
GDPR第13章对APP隐私政策进行了以下如图1所示的9项规定,例如1. Collect Personal Info → Data Retention Period 代表如果APP要收集用户信息,则必须告知用户数据保留期限

图1
方法

图2
本文提出的方法如上图2所示,输入一篇隐私政策文本,首先进行文本分类,然后进行合规性验证,输出检测结果。
文本分类
对隐私政策文本的每个句子分为以下10类(1.收集个人信息CPI;2. 数据保存期限DRP;3.数据处理目的DPP;4.个人信息控制者的联系方式CD;5.用户的访问权RA;6.用户修改/销毁权PRE;7.用户限制对个人信息处理的权利RRP;8.用户拒绝处理数据的权利ROP;9.用户对数据的转移权利RDP;10.用户投诉权RLC):

图3
合规性验证
GDPR第13章的9项规定(图1)可以表示为“if A holds, then B must be satisfied”,A即“APP需要收集个人信息”,B即“隐私政策中需要向用户告知的内容”,其又可以进行如下表示(图4):
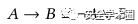
图4
也就是说,如果一个隐私政策是合规的,它要么“并未说明要收集用户个人信息”,要么“告知了用户所有必要内容”,于是通过第一步的文本分类任务可以直接进行合规性验证(文本分类任务中,第1类为“收集个人信息”,用于判断文本中是否有句子表明了要收集个人信息;第2-10类为隐私政策中需要告知用户的必要内容),即如果隐私政策合规,那么该隐私政策中的句子的预测标签要么不存在1,要么就要同时包含2-10。
结果
本文用了SVM(将n-gram和tf-idf作为特征)、BiLSTM和BERT作为三个不同的分类模型,其结果如下图:
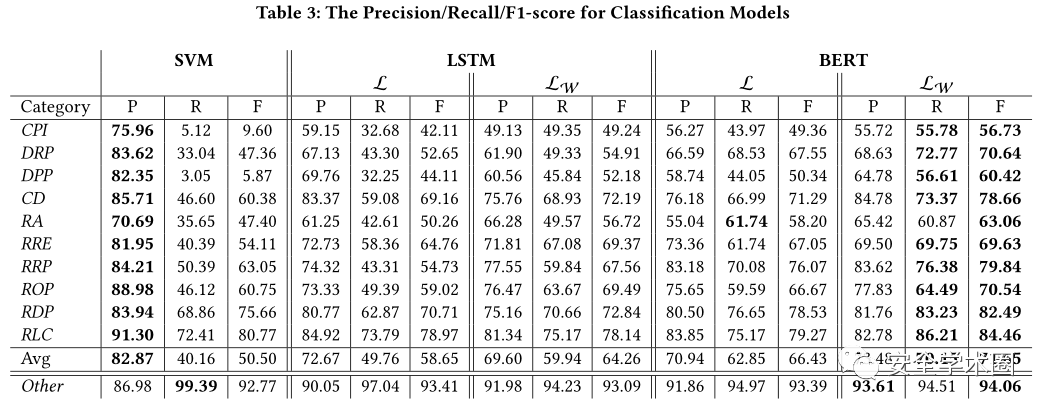
图5

VSole
网络安全专家