【技术分享】OLLVM Deflattener

前言
笔者于五月份时遇到几个经控制流平坦化的样本,由于之前没有接触过这方面知识,未深入分析。
七月初看到一篇博客——MODeflattener – Miasm’s OLLVM Deflattener,作者同时在Github上公开其源码,故笔者决定对其一探究竟。该工具使用miasm框架,Quarklab于2014年的博客——Deobfuscation: recovering an OLLVM-protected program中已提到此框架,但其采用符号执行以遍历代码,计算每个Relevant Block目标终点,恢复执行流程。腾讯SRC于2017年的博客——利用符号执行去除控制流平坦化中亦是采用符号执行(基于angr框架),而MODeflattener采用静态分析方式来恢复执行流程。笔者于下文首先结合具体样本分析其源码及各函数功能,之后指出该工具不足之处并提出改进方案。关于涉及到的miasm框架中类,函数,属性及方法可参阅miasm Documentation与miasm源码。LLVM,OLLVM,LLVM Pass及控制流平坦化不再赘述,具体可参阅基于LLVM Pass实现控制流平坦化与OLLVM Flattening源码。
源码分析
0x01.1 检测平坦化
def calc_flattening_score(asm_graph): score = 0.0 for head in asm_graph.heads_iter(): dominator_tree = asm_graph.compute_dominator_tree(head) for block in asm_graph.blocks: block_key = asm_graph.loc_db.get_offset_location(block.lines[0].offset) dominated = set( [block_key] + [b for b in dominator_tree.walk_depth_first_forward(block_key)]) if not any([b in dominated for b in asm_graph.predecessors(block_key)]): continue score = max(score, len(dominated)/len(asm_graph.nodes())) return score
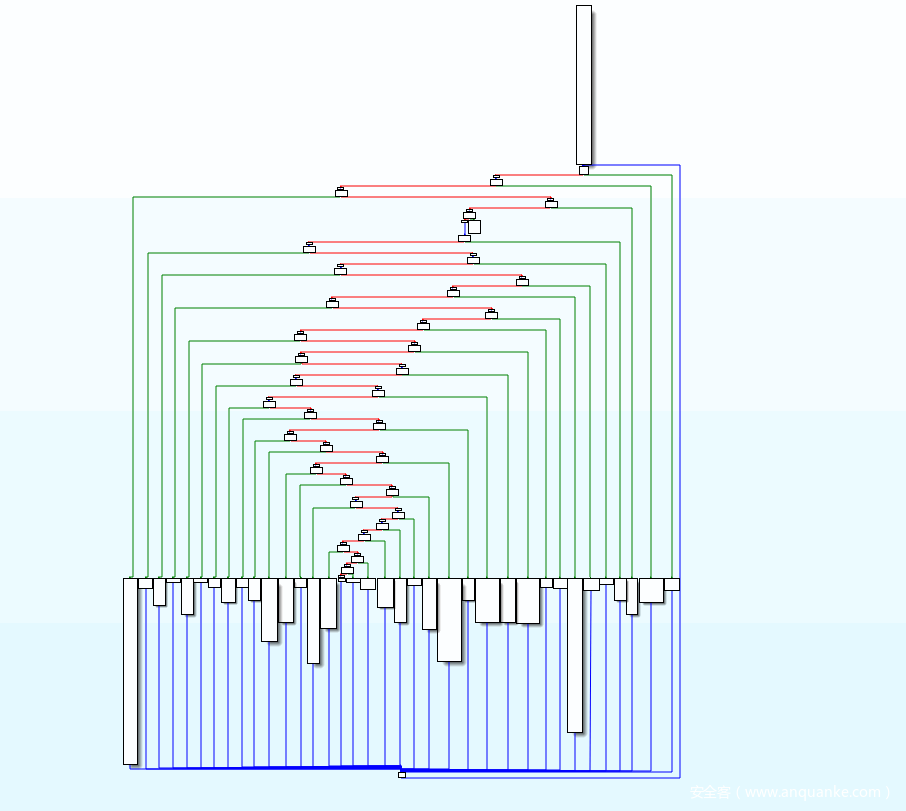
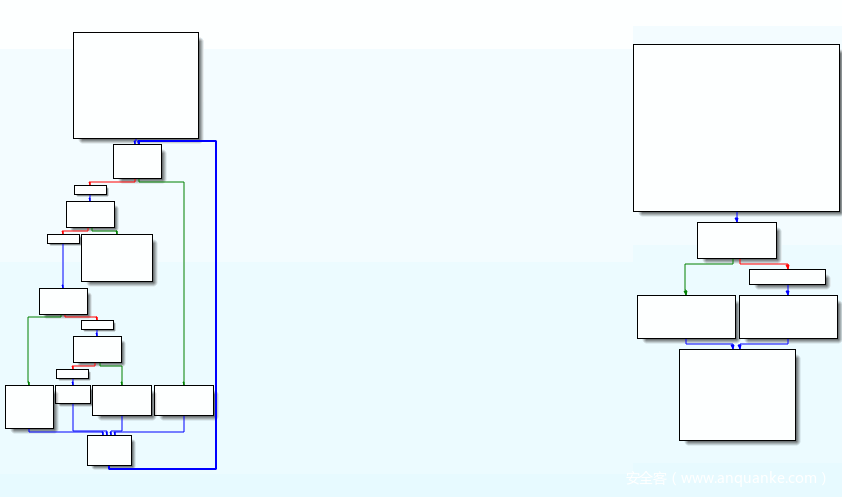
计算每个块支配块数量,除以图中所有块,取最高分——若不低于0.9,证明该函数经过控制流平坦化。如下图:
块b支配除块a外其余所有块(包含自身),那么其得分为9/10=0.9即最高分。读者可自行查阅Dominator Tree及Predecessors相关数据结构知识,此外不作展开。
0x01.2 获取平坦化相关信息
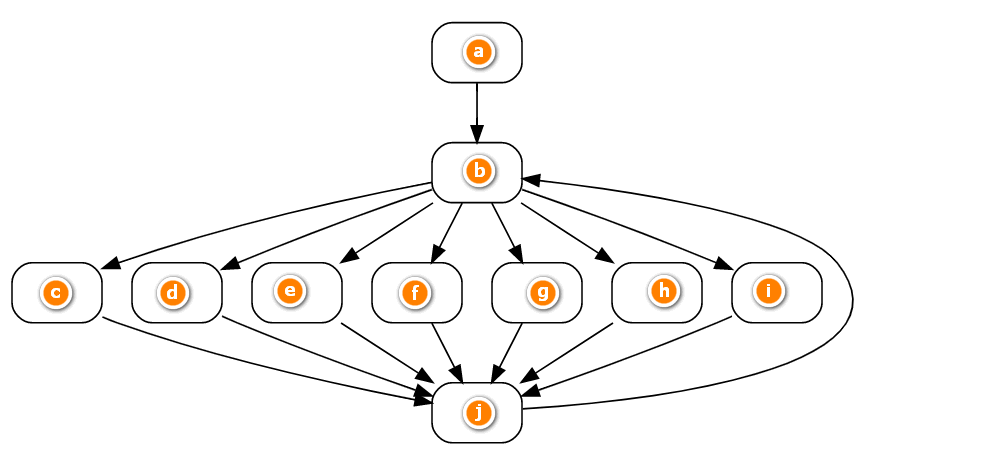
def get_cff_info(asmcfg): preds = {} for blk in asmcfg.blocks: offset = asmcfg.loc_db.get_location_offset(blk.loc_key) preds[offset] = asmcfg.predecessors(blk.loc_key) # pre-dispatcher is the one with max predecessors pre_dispatcher = sorted(preds, key=lambda key: len(preds[key]), reverse=True)[0] # dispatcher is the one which suceeds pre-dispatcher dispatcher = asmcfg.successors(asmcfg.loc_db.get_offset_location(pre_dispatcher))[0] dispatcher = asmcfg.loc_db.get_location_offset(dispatcher)
# relevant blocks are those which preceed the pre-dispatcher relevant_blocks = [] for loc in preds[pre_dispatcher]: offset = asmcfg.loc_db.get_location_offset(loc) relevant_blocks.append(get_block_father(asmcfg, offset))
return relevant_blocks, dispatcher, pre_dispatcher
首先拥有最大数量Predecessor者即为Pre-Dispatcher,而Pre-Dispatcher后继为Dispatcher,Pre-Dispatcher所有前趋均为Relevant Block。
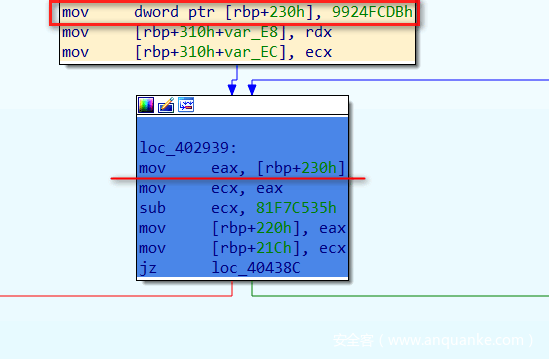
dispatcher_blk = main_asmcfg.getby_offset(dispatcher) dispatcher_first_instr = dispatcher_blk.lines[0] state_var = dispatcher_first_instr.get_args_expr()[1]
Dispatcher块第一条指令为状态变量:
0x01.3 去平坦化
for addr in relevant_blocks: _log.debug("Getting info for relevant block @ %#x"%addr) loc_db = LocationDB() mdis = machine.dis_engine(cont.bin_stream, loc_db=loc_db) mdis.dis_block_callback = stop_on_jmp asmcfg = mdis.dis_multiblock(addr)
lifter = machine.lifter_model_call(loc_db) ircfg = lifter.new_ircfg_from_asmcfg(asmcfg) ircfg_simplifier = IRCFGSimplifierCommon(lifter) ircfg_simplifier.simplify(ircfg, addr)
遍历每个Relevant Block,为其创建ASM CFG及IR CFG,作者实现了一save_cfg函数可将CFG输出(需要安装Graphviz):
def save_cfg(cfg, name): import subprocess open(name, 'w').write(cfg.dot()) subprocess.call(["dot", "-Tpng", name, "-o", name.split('.')[0]+'.png']) subprocess.call(["rm", name])
之后查找所有使用状态变量及定义状态变量语句:
nop_addrs = find_state_var_usedefs(ircfg, state_var)...def find_state_var_usedefs(ircfg, search_var): var_addrs = set() reachings = ReachingDefinitions(ircfg) digraph = DiGraphDefUse(reachings) # the state var always a leaf for leaf in digraph.leaves(): if leaf.var == search_var: for x in (digraph.reachable_parents(leaf)): var_addrs.add(ircfg.get_block(x.label)[x.index].instr.offset) return var_addrs
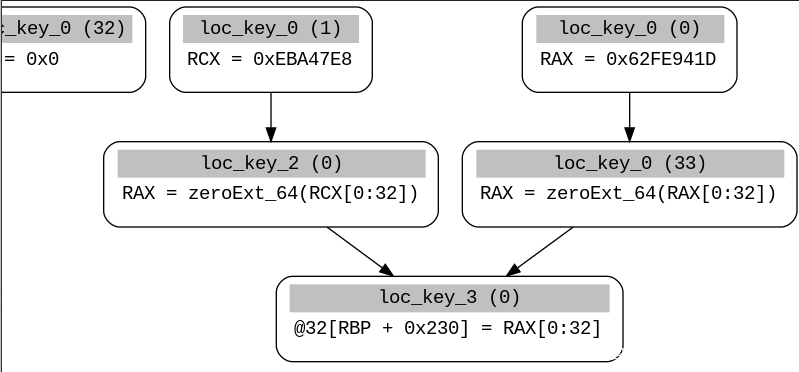
可以看到DefUse图与语句对应关系:
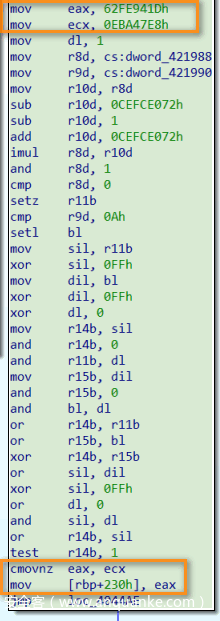
查找状态变量所有可能值:
def find_var_asg(ircfg, var): val_list = [] res = {} for lbl, irblock in viewitems(ircfg.blocks): for assignblk in irblock: result = set(assignblk).intersection(var) if not result: continue else: dst, src = assignblk.items()[0] if isinstance(src, ExprInt): res['next'] = int(src) val_list += [int(src)] elif isinstance(src, ExprSlice): phi_vals = get_phi_vars(ircfg) res['true_next'] = phi_vals[0] res['false_next'] = phi_vals[1] val_list += phi_vals return res, val_list
为状态变量赋值有两种情况——一种是直接赋值,不涉及条件判断及分支跳转,其对应ExprInt:
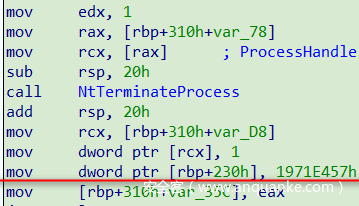
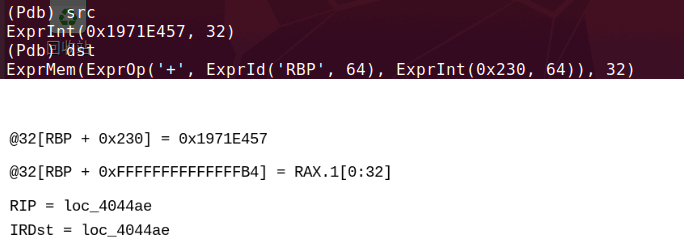
另一种是CMOV条件赋值,其对应ExprSlice:
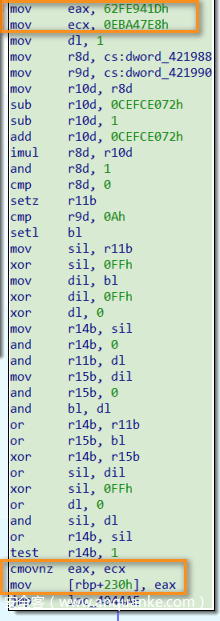

之后计算每一状态变量可能值对应Relevant Block:
# get the value for reaching a particular relevant block for lbl, irblock in viewitems(main_ircfg.blocks): for assignblk in irblock: asg_items = assignblk.items() if asg_items: # do not enter if nop dst, src = asg_items[0] if isinstance(src, ExprOp): if src.op == 'FLAG_EQ_CMP': arg = src.args[1] if isinstance(arg, ExprInt): if int(arg) in val_list: cmp_val = int(arg) var, locs = irblock[-1].items()[0] true_dst = main_ircfg.loc_db.get_location_offset(locs.src1.loc_key) backbone[hex(cmp_val)] = hex(true_dst)
如下图:

将fixed_cfg中存储的状态变量值替换为目标Relevant Block地址:
for offset, link in fixed_cfg.items(): if 'cond' in link: tval = fixed_cfg[offset]['true_next'] fval = fixed_cfg[offset]['false_next'] fixed_cfg[offset]['true_next'] = backbone[tval] fixed_cfg[offset]['false_next'] = backbone[fval] elif 'next' in link: fixed_cfg[offset]['next'] = backbone[link['next']] else: # the tail doesn't has any condition tail = int(offset, 16)
将所有无关指令替换为NOP:
for addr in rel_blk_info.keys(): _log.info('=> cleaning relevant block @ %#x' % addr) asmcfg, nop_addrs = rel_blk_info[addr] link = fixed_cfg[hex(addr)] instrs = [instr for blk in asmcfg.blocks for instr in blk.lines] last_instr = instrs[-1] end_addr = last_instr.offset + last_instr.l # calculate original length of block before patching orig_len = end_addr - addr # nop the jmp to pre-dispatcher nop_addrs.add(last_instr.offset) _log.debug('nop_addrs: ' + ', '.join([hex(addr) for addr in nop_addrs])) patch = patch_gen(instrs, asmcfg.loc_db, nop_addrs, link) patch = patch.ljust(orig_len, b"\x90") patches[addr] = patch _log.debug('patch generated %s' % encode_hex(patch))
_log.info(">>> NOPing Backbone (%#x - %#x) <<<" % (backbone_start, backbone_end)) nop_len = backbone_end - backbone_start patches[backbone_start] = b"\x90" * nop_len
其中patch_gen函数定义如下:
def patch_gen(instrs, loc_db, nop_addrs, link): final_patch = b"" start_addr = instrs[0].offset
for instr in instrs: #omitting useless instructions if instr.offset not in nop_addrs: if instr.is_subcall(): #generate asm for fixed calls with relative addrs patch_addr = start_addr + len(final_patch) tgt = loc_db.get_location_offset(instr.args[0].loc_key) _log.info("CALL %#x" % tgt) call_patch_str = "CALL %s" % rel(tgt, patch_addr) _log.debug("call patch : %s" % call_patch_str) call_patch = asmb(call_patch_str, loc_db) final_patch += call_patch _log.debug("call patch asmb : %s" % encode_hex(call_patch)) else: #add the original bytes final_patch += instr.b
patch_addr = start_addr + len(final_patch) _log.debug("jmps patch_addr : %#x", patch_addr) jmp_patches = b"" # cleaning the control flow by patching with real jmps locs if 'cond' in link: t_addr = int(link['true_next'], 16) f_addr = int(link['false_next'], 16) jcc = link['cond'].replace('CMOV', 'J') _log.info("%s %#x" % (jcc, t_addr)) _log.info("JMP %#x" % f_addr)
patch1_str = "%s %s" % (jcc, rel(t_addr, patch_addr)) jmp_patches += asmb(patch1_str, loc_db) patch_addr += len(jmp_patches)
patch2_str = "JMP %s" % (rel(f_addr, patch_addr)) jmp_patches += asmb(patch2_str, loc_db) _log.debug("jmp patches : %s; %s" % (patch1_str, patch2_str))
else: n_addr = int(link['next'], 16) _log.info("JMP %#x" % n_addr)
patch_str = "JMP %s" % rel(n_addr, patch_addr) jmp_patches = asmb(patch_str, loc_db)
_log.debug("jmp patches : %s" % patch_str)
_log.debug("jmp patches asmb : %s" % encode_hex(jmp_patches)) final_patch += jmp_patches
return final_patch
首先检查每个块中是否存在函数调用,如果存在,计算其修补后偏移;否则直接使用原指令:
if instr.is_subcall(): #generate asm for fixed calls with relative addrs patch_addr = start_addr + len(final_patch) tgt = loc_db.get_location_offset(instr.args[0].loc_key) _log.info("CALL %#x" % tgt) call_patch_str = "CALL %s" % rel(tgt, patch_addr) _log.debug("call patch : %s" % call_patch_str) call_patch = asmb(call_patch_str, loc_db) final_patch += call_patch _log.debug("call patch asmb : %s" % encode_hex(call_patch)) else: #add the original bytes final_patch += instr.b
之后修复执行流程:
# cleaning the control flow by patching with real jmps locs if 'cond' in link: t_addr = int(link['true_next'], 16) f_addr = int(link['false_next'], 16) jcc = link['cond'].replace('CMOV', 'J') _log.info("%s %#x" % (jcc, t_addr)) _log.info("JMP %#x" % f_addr)
patch1_str = "%s %s" % (jcc, rel(t_addr, patch_addr)) jmp_patches += asmb(patch1_str, loc_db) patch_addr += len(jmp_patches)
patch2_str = "JMP %s" % (rel(f_addr, patch_addr)) jmp_patches += asmb(patch2_str, loc_db) _log.debug("jmp patches : %s; %s" % (patch1_str, patch2_str))
else: n_addr = int(link['next'], 16) _log.info("JMP %#x" % n_addr)
patch_str = "JMP %s" % rel(n_addr, patch_addr) jmp_patches = asmb(patch_str, loc_db)
如果是条件赋值,替换为条件跳转;否则直接替换为JMP指令。
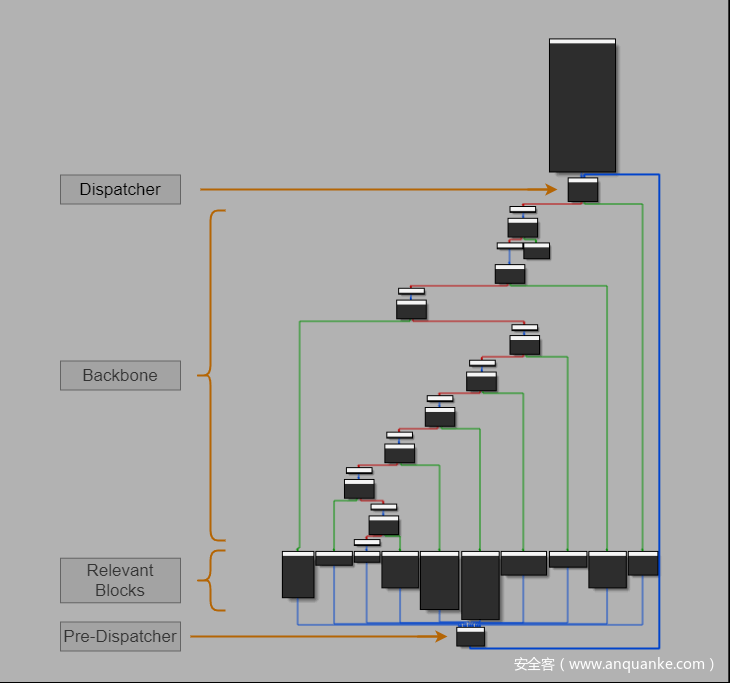
至此,源码分析结束。如下图所示,可以看到其效果很不错:
不足及改进
0x02.1 不支持PE文件
其计算基址是通过访问sh属性:
section_ep = cont.bin_stream.bin.virt.parent.getsectionbyvad(cont.entry_point).sh bin_base_addr = section_ep.addr - section_ep.offset _log.info('bin_base_addr: %#x' % bin_base_addr)

故笔者首先增加一参数baseaddr:
parser.add_argument('-b',"--baseaddr", help="file base address")
之后判断文件类型:
try: if args.baseaddr: _log.info('Base Address:'+args.baseaddr) baseaddr=int(args.baseaddr,16) elif cont.executable.isPE(): baseaddr=0x400C00 _log.info('Base Address:%x'%baseaddr) except AttributeError: section_ep = cont.bin_stream.bin.virt.parent.getsectionbyvad(cont.entry_point).sh baseaddr = section_ep.addr - section_ep.offset _log.info('Base Address:%x'%baseaddr)
如果是PE文件且未提供baseaddr参数,则直接给其赋值为0x400C00;若是ELF文件,则访问sh属性。
0x02.2 获取CMOV指令
elif len(var_asg) > 1: #extracting the condition from the last 3rd line cond_mnem = last_blk.lines[-3].name _log.debug('cond used: %s' % cond_mnem) var_asg['cond'] = cond_mnem var_asg['true_next'] = hex(var_asg['true_next']) var_asg['false_next'] = hex(var_asg['false_next']) # map the conditions and possible values dictionary to the cfg info fixed_cfg[hex(addr)] = var_asg
通常CMOV指令位于倒数第三条语句,但笔者在测试时发现部分块CMOV指令位于倒数第四条语句:

故改进如下:
elif len(var_asg) > 1: #extracting the condition from the last 3rd line cond_mnem = last_blk.lines[-3].name _log.debug('cond used: %s' % cond_mnem) if cond_mnem=='MOV': cond_mnem = last_blk.lines[-4].name var_asg['cond'] = cond_mnem var_asg['true_next'] = hex(var_asg['true_next']) var_asg['false_next'] = hex(var_asg['false_next']) # map the conditions and possible values dictionary to the cfg info fixed_cfg[hex(addr)] = var_asg
0x02.3 调用导入函数
if instr.is_subcall(): #generate asm for fixed calls with relative addrs patch_addr = start_addr + len(final_patch) tgt = loc_db.get_location_offset(instr.args[0].loc_key) _log.info("CALL %#x" % tgt) call_patch_str = "CALL %s" % rel(tgt, patch_addr) _log.debug("call patch : %s" % call_patch_str) call_patch = asmb(call_patch_str, loc_db) final_patch += call_patch _log.debug("call patch asmb : %s" % encode_hex(call_patch))
仅判断是否为函数调用,但并未判断调用函数地址是否为导入函数地址,如下图两种情形所示:

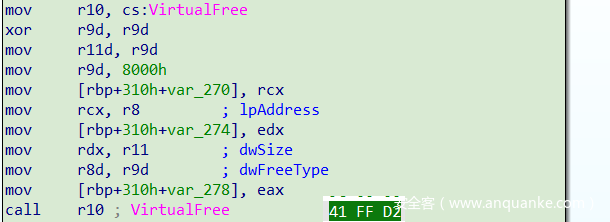
改进如下:
if instr.is_subcall(): if isinstance(instr.args[0],ExprMem) or isinstance(instr.args[0],ExprId): final_patch += instr.b else: #generate asm for fixed calls with relative addrs patch_addr = start_addr + len(final_patch) tgt = loc_db.get_location_offset(instr.args[0].loc_key) _log.info("CALL %#x" % tgt) call_patch_str = "CALL %s" % rel(tgt, patch_addr) _log.debug("call patch : %s" % call_patch_str) call_patch = asmb(call_patch_str, loc_db) final_patch += call_patch _log.debug("call patch asmb : %s" % encode_hex(call_patch))
0x02.4 get_phi_vars
def get_phi_vars(ircfg): res = [] blks = list(ircfg.blocks) irblock = (ircfg.blocks[blks[-1]])
if irblock_has_phi(irblock): for dst, sources in viewitems(irblock[0]): phi_vars = sources.args parent_blks = get_phi_sources_parent_block( ircfg, irblock.loc_key, phi_vars )
for var, loc in parent_blks.items(): irblock = ircfg.get_block(list(loc)[0]) for asg in irblock: dst, src = asg.items()[0] if dst == var: res += [int(src)]
return res
未考虑到由局部变量存储状态变量值情形:
mov eax, 0B3584423hmov ecx, 0CAE581F5h...test cl, 1mov r9d, [rbp+18Ch]mov r14d, [rbp+17Ch]cmovnz r9d, r14dmov [rbp+230h], r9djmp loc_4044AE
如果是上述情形,状态变量值往往位于头节点中,故改进如下:
def get_phi_vars(ircfg,loc_db,mdis): res = [] blks = list(ircfg.blocks) irblock = (ircfg.blocks[blks[-1]])
if irblock_has_phi(irblock): for dst, sources in viewitems(irblock[0]): phi_vars = sources.args parent_blks = get_phi_sources_parent_block( ircfg, irblock.loc_key, phi_vars )
for var, loc in parent_blks.items(): irblock = ircfg.get_block(list(loc)[0]) for asg in irblock: dst, src = asg.items()[0] if dst == var and isinstance(src,ExprInt): res += [int(src)] elif dst==var and isinstance(src,ExprOp): reachings = ReachingDefinitions(ircfg) digraph = DiGraphDefUse(reachings) # the state var always a leaf for head in digraph.heads(): if head.var == src.args[0]: head_offset=loc_db.get_location_offset(head.label) if isinstance(mdis.dis_instr(head_offset).args[1],ExprInt): res+=[int(mdis.dis_instr(head_offset).args[1])]
return res
参阅链接
- MODeflattener – Miasm’s OLLVM Deflattener
- Deobfuscation: recovering an OLLVM-protected program—Quasklab
- 利用符号执行去除控制流平坦化—腾讯SRC
- Automated Detection of Control-flow Flattening
- miasm—Github
- OLLVM Flattening—Github
- 基于LLVM Pass实现控制流平坦化—看雪
