边缘场景下DNN模型高效切分与放置策略研究
近年来,随着边缘设备与边缘应用的爆发式增加,近边端的智能数据处理需求急剧增加。然而,将资源需求较低的人工智能算法由云端迁移到边端任存在许多挑战:1)智能算法的资源需求与边缘设备受限于资源之间的矛盾;2)服务质量与隐私保护之间的矛盾;3)智能任务需求多样与边缘设备能力单一之间的矛盾。传统的云-边协同的处理模式给网络传输带来巨大的压力,且已不能满足边缘端对计算实时性的要求。因此对DNN模型进行有效切分,利用边缘与边缘之间协同计算来共同承担大规模DNN的训练与推理计算任务成为了重要的研究内容。
此外,出于对数据隐私保护的考虑,在医疗、金融等领域,当多个实体的原始数据不能直接共享时,如何实现分布式的神经网络训练。FL是一种解决方案[1],通过节点间更新加载模型参数实现对全局模型的训练。另一种解决方案是对DNN模型进行切分,实体间保留DNN模型的不同部分,通过在多个实体间传递模型中间层梯度的形式来代替原数据的共享[2],从而既保护了原数据的隐私性,又完成全局DNN模型的训练。
基于推理的模型切分
先前的工作表明,基于DNN的智能应用如语音或图像查询需要比基于文本的输入数据多几个数量级的处理。普遍认为,传统移动设备无法以合理的延迟和能耗支持如此大的计算量。因此,网络服务提供商用于智能应用的现状方法是将所有计算托管在后台高端云服务器上。从用户移动设备生成的查询被发送到云端进行处理。但是使用这种方法,大量数据(例如,图像、视频和音频)通过无线网络上传到服务器,导致高延迟和能源成本[3]。然而基于移动硬件的性能和能效的不断提升,越来越多的机器学习应用从云端推向移动设备。因此如何充分利用云端资源和移动硬件资源执行基于DNN的应用显得尤为重要。
我们知道DNN被组织成一个有向图,其中每个节点都是一个神经元,图的边是每个神经元之间的连接,相同功能的多个神经元被定义成一个层。因此我们以层级为单位对图像处理应用(AlexNet)进行分层切分测试,测试在不同分层情况下,云服务器与移动设备分别执行分层后AlexNet的不同部分时所表现出的执行延迟和能源消耗,如图1所示,星号表明了最优分层点的位置。
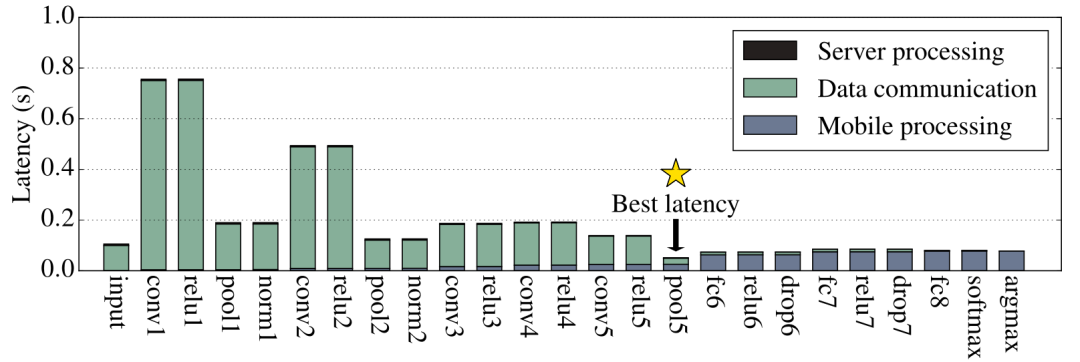
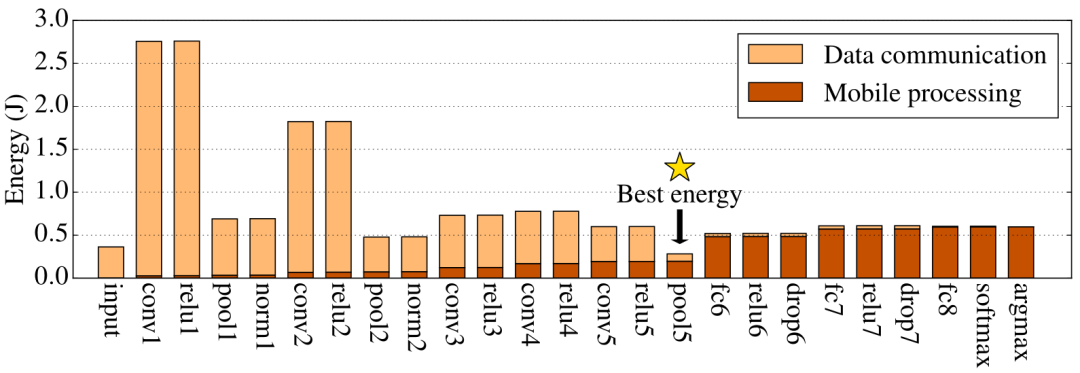
图1 不同分层时AlexNet执行延迟和能源消耗
实验证明了不同的分层切分方案会带来不同的执行效果,并且存在最佳切分点使得整个模型执行的延迟更低,能耗更少。DNN模型的最佳划分点取决于DNN的拓扑结构,这体现在每层的计算和数据大小变化上。此外,动态因素(如无线网络状态和数据中心负载)会影响最佳分区点,即使对于相同的DNN架构也是如此。因此需要一种自动系统来智能地选择最佳点来划分DNN,以针对端到端延迟或移动设备能耗进行优化。而系统中最关键的一点就是实现在不执行DNN模型推理任务的情况下,预测DNN模型不同层的执行延迟如何。
对于每种层类型,各层配置之间的延迟差异很大。因此,为了构建每种层类型的预测模型,需要改变层的可配置参数,并测量了每种配置的延迟。使用不同的profile对同类型层的不同延迟建立回归模型[4],结果包含FC层的回归模型、Conv层的回归模型、Pool层的回归模型、Activation层回归模型等。进一步使用这些回归模型预测DNN每一层的执行延迟,从而确定最优模型切分点。
另一种方案是考虑到Server端的资源竞争问题,进一步加入Server端的GPU信息(GPU核、内存使用情况、GPU温度等)[5],通过Random Forest训练层级预测模型。在进行模型切分阶段,使用最短路径方案找到最优模型切分点的位置[6],如图2。
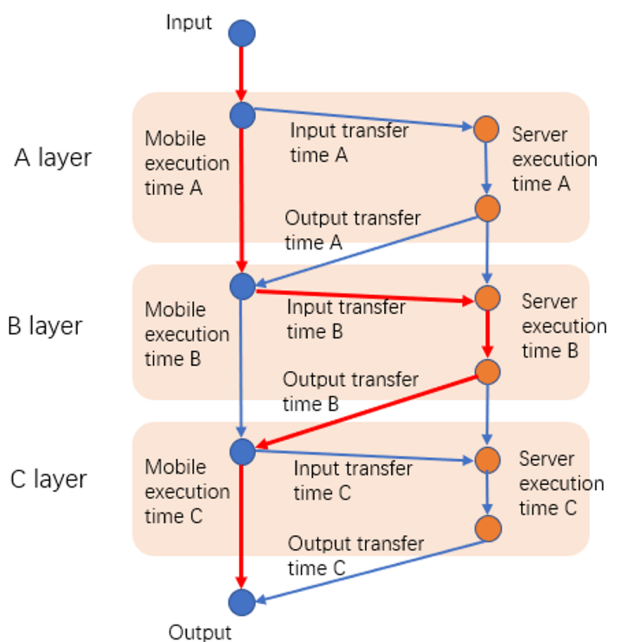
图2 基于最短路径的模型切分
按层级粒度对模型进行切分时,有一个重要问题被忽略掉:层与层之间的优化操作[7]。由于层级间优化操作的存在,使得DNN整体执行时间的延迟不完全等于每一层执行时间延迟的总和。此外由于底层硬件的差异(CPU、GPU和VPU)、驱动的差异以及推理平台的差异(例如TFLite、OpenVINO等),层级间的优化操作也存在诸多不同。进一步考虑到很多平台并非开源,也就无从得知优化操作的具体实现如何。因此另一种方案不再基于层级粒度对DNN模型执行时间进行预测,而是尝试以相对粗粒度的方式Kernel描述模型执行时间,如图3。通过Test Cases测试不同平台、不同硬件的Fusion rules,进一步根据Fusion rules 划分模型的Kernel。以Kernel为单位的好处在于屏蔽掉了层级间的优化操作,因此即便我们不知道具体的优化操作如何,我们也能更加精确地训练Random Forest。
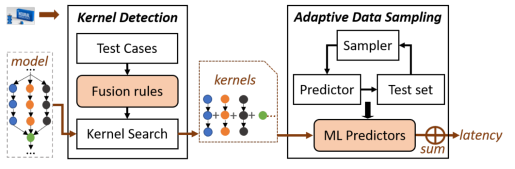
图3 基于kernel的模型预测系统
二
基于训练的模型切分
除了使用模型切分对推理任务的执行时间进行优化之外,模型切分也用于模型训练时对数据隐私保护方面。深度神经网络的训练是数据密集性的,需要从多个实体收集大规模的数据集。深度神经网络通常包含数百万个参数,并且需要巨大的计算能力来进行训练,这使得单个数据数据库很难训练它们[8]。考虑到医疗、金融等领域匿名化数据共享相关的隐私和道德问题,虽然许多这样的数据实体在开发新的深度学习算法方面有既得利益,但也有义务保持用户数据的私密性。因此提出具有多个数据源和一个主节点的架构训练神经网络的方法来解决这些问题。
如图4中Slave是数据源节点,Master是超级主节点。为了保持原始数据的私有性,Slave节点之间以及Slave与Master之间不共享各自的原数据[9]。我们的目标是得到优化后的模型W*= [ W* C, W* S ],我们将模型切分成两部分,W = [ W C, W S ],其中Slave节点训练神经网络时仅训练前几层网络 W C,而后几层网络 W C由Master节点训练,当Slave 1与Master节点完成训练后,进行Slave 2节点与Master节点的训练,依次训练直到Slave 6节点也完成训练,最后将完整的训练模型共享。通过这种方式在数据源之间以及数据源与主节点之间传递的是梯度值和层级间的张量,从而有效避免了原数据的共享。
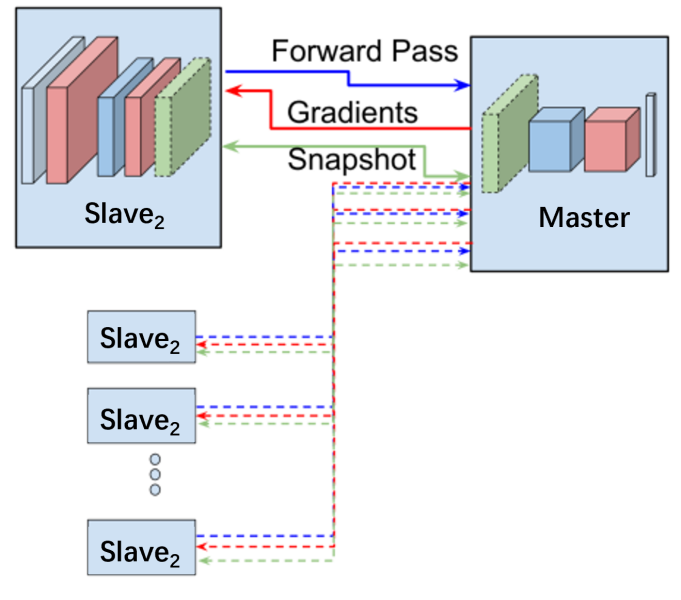
图4 全局梯度的模型切分训练
进一步探讨训练过程使用模型切分策略时,带来的一个额外问题是通信开销。由于全局梯度的使用使得模型训练过程中需要不断传递梯度信息和张量,为了解决模型切分过程中的通信开销的问题,Dong-Jun Han[10]等人提出了新的方法local-loss-based training。在 W C后增加auxiliary network,auxiliary network的作用是对client端的 W C部分求局部损失函数。
三
总结展望
本文主要讨论了目前关于DNN模型切分的工作。DNN模型切分包含推理阶段和训练阶段两种不同的方式。推理阶段进行模型切分的目的主要是为了预测设备上或服务器上模型每一层的执行时间,进而可以根据层的执行时间实现机器学习应用的协同执行,从而减少总的执行延迟并降低移动终端设备中能源的消耗。然而目前推理阶段模型切分存在时间预测的精确度的问题,该问题的挑战在于模型执行过程中硬件设备、应用平台的优化操作是一种黑盒状态,我们无法获知这些优化操作包含哪些,又是以怎样的形式发生的。因此接下来的工作在于如何避免优化操作对时间预测产生的的影响。
在训练阶段中的模型切分除了需要解决通信开销的问题以外,还存在训练时层级时间预测问题。例如在模型压缩过程中,压缩性能的好坏通过FLOPs或推理时间来判断,但如果可以以层级粒度实现准确预测模型训练时间,那么就可以更好对模型压缩的性能进行有效评测。
文献引用:
[1] McMahan, B., Moore, E., Ramage, D., Hampson, S., and y Arcas, B. A. Communication-efficient learning of deepnetworks from decentralized data. In Artificial Intelligence and Statistics, pp. 1273–1282, 2017.
[2] Thapa, C., Chamikara, M. A. P ., and Camtepe, S. Splitfed: When federated learning meets split learning. arXiv preprint arXiv: 2004. 12088, 2020.
[3] C. Hu, W. Bao, D. Wang, and F. Liu, “Dynamic adaptive DNN surgery for inference acceleration on the edge,” in IEEE INFOCOM 2019 IEEE Conference on Computer Communications, 2019, pp. 1423–1431.
[4] Y . Kang, J. Hauswald, C. Gao, A. Rovinski, T. Mudge, J. Mars, and L. Tang, “Neurosurgeon: Collaborative intelligence between the cloud and mobile edge,” in Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems. ACM, 2017, pp. 615–629.
[5] H.-J. Jeong, H.-J. Lee, C. H. Shin, and S.-M. Moon, “Ionn: Incremental offloading of neural network computations from mobile devices to edge servers,” in Proceedings of the ACM Symposium on Cloud Computing, ser. SoCC ’18. New York, NY, USA: ACM, 2018, pp. 401–411.
[6] H.-J. Jeong, H.-J. Lee, C. H. Shin, and S.-M. Moon,“PerDNN Offloading Deep Neural Network Computations to Pervasive Edge Servers,” in International Conference on Distributed Computing Systems, ICDCS, 2020, pp.1055-1066.
[7] Li Lyna Zhang, Shihao Han, Jianyu Wei, Ningxin Zheng, Ting Cao, Yuqing Yang, Yunxin Liu,” nn-Meter: Towards Accurate Latency Prediction of Deep-Learning Model Inference on Diverse Edge Devices,” The 19th ACM International Conference on Mobile Systems, Applications, and Services ,MobiSys 2021, pp. 81-93.
[8] Maarten G.Poirot,Rajiv Gupta,Praneeth V epakomma,“Split Learning for collaborative deep learning in healthcare”,arXiv preprintarXiv: 1912. 12115. 2019.
[9] Otkrist Gupta and Ramesh Raskar. Distributed learning of deep neural network over multiple agents. Journal of Network and Computer Applications, 116:1–8, 2018. ISSN 1084-8045.
[10] Nathalie Baracaldo · Olivia Choudhury · Gauri Joshi · Peter Richtarik · Praneeth Vepakomma · Shiqiang Wang · Han Yu,“Accelerating Federated Learning with Split Learning on Locally Generated Losses,” in International Workshop on Federated Learning for User Privacy and Data Confidentiality in Conjunction with ICML 2021.
