LargeGraph:依赖感知的GPU图计算加速技术
近来,许多out-of-GPU-memory系统被用于支持大规模图的迭代处理。由于活跃顶点的新状态沿图中路径的传播效率低,这些系统仍然需要很长时间才能达成收敛。为了有效地支持out-of-GPU-memory下的图处理,我们设计了LargeGraph系统。不同于现有的out-of-GPU-memory系统,LargeGraph提出了一种依赖感知的数据驱动执行方法,该方法可以显著加快活跃顶点沿图中路径的状态传播速度,同时有较低的数据访存开销和较高的并行性。具体来说,LargeGraph能够分析顶点之间的依赖关系,只对与活跃顶点的依赖链相关联的图数据进行加载和处理,以此来减少访存开销。由于现实世界中图数据普遍存在幂律特性幂律特性,大多数活跃顶点会经常使用一组不断演化的路径子集进行新状态的传播。通过在GPU上对路径子集进行动态识别、维护和处理,LargeGraph能够加速大多数活跃顶点的状态传播以更快达成收敛状态,其他的图数据则在CPU上进行处理。实验结果表明,和其他4种最新方案相比,LargeGraph能够进一步将目前流行的GPU外存储图计算系统Totem,Graphie,Garaph和Subway的性能分别提高5.19-11.62倍,3.02-9.41倍,2.75-8.36倍,2.45-4.15倍。
该成果“ LargeGraph: An Efficient Dependency-Aware GPU-Accelerated Large-Scale Graph Processing ”已被期刊ACM Transactions on Architecture and Code Optimization(TACO)收录(Volume 18,Issue 4,December 2021,Article No.: 58, pp 1-24),该期刊属于CCF B类英文期刊。

- 论文链接:
- https://dl.acm.org/doi/10.1145/3477603
背景与动机
随着大数据时代的来临,图作为一种能够良好表达数据关联性的数据结构,在许多领域广泛应用的同时,图数据的规模也越来越大。为了加速图数据处理速度,许多研究选择将图工作负载卸载到GPU上,开发出了一批out-of-GPU-memory图计算系统。这些系统将大规模图划分为几个大小相同的子图(或称为块),这些子图能加载到GPU的全局内存中供GPU处理。
实际上,图计算是基于图中每个顶点的直接/间接邻居顶点状态对其的影响,迭代计算顶点新状态的过程。然而,对于现有的out-of-GPU-memory图计算系统,在每轮图处理中,每个顶点仅根据其直接邻居顶点的状态进行顶点状态更新。因此,算法为了达到收敛,每个间接邻居顶点的状态需要沿着图路径(间接邻居顶点与目的顶点之间的路径)进行多次迭代传播。如图1所示,顶点v5的新状态要传播到v20需要经过多次迭代才能完成。
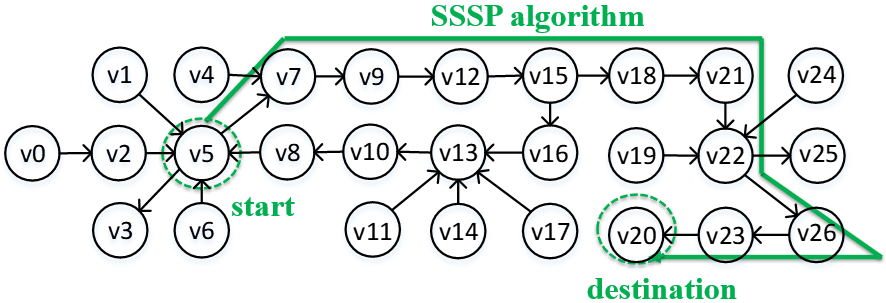
图1 顶点状态传播示例
进一步说,由于同一条路径上的顶点和边可能被划分到不同的子图中,而这些子图被分配在不同的CPU/GPU核上并发处理,当活跃顶点的状态沿路径传播时,会产生高额的同步开销和CPU-GPU数据传输成本。此外,由于活跃顶点的状态传播速度缓慢且代价高昂,许多GPU线程会处于空闲状态,导致设备利用率低,或者许多GPU核上的顶点使用其直接邻居的过时状态进行状态更新,这导致了大量的冗余图数据传输,当GPU拥有更多处理核心时,冗余图数据传输时间占整个数据传输开销的比率将会更高。
为了充分利用GPU的强大算力来加速out-of-GPU-memory图计算系统上的大规模图处理,我们提出了一种基于依赖感知的GPU图计算加速技术,这是一种轻量级的运行时方法,通过动态获取源自活跃顶点的依赖路径来实现更低的数据访问成本、更快的顶点状态传播速度和更高的GPU利用率。
路径的划分和存储
在预处理阶段,LargeGraph使用CPU对大规模图进行并行的路径划分。具体来说,LargeGraph首先为每个线程分配一个子图,这些子图实际上就是一系列顶点以及和顶点关联的边所组成。也就是说,LargeGraph只需要指定每个线程要处理的顶点的起始和结束索引。之后,这些线程会并行地将各个子图划分为不相交的路径。
如图2所示,对于每个子图,线程从中选取一个顶点作为路径的起始顶点,然后以深度优先搜索的方式遍历边,并将边的目的顶点加入到路径中。在某路径到达入度大于1的顶点时,线程停止向该路径继续加入顶点,并将该入度大于1的顶点作为路径的终止顶点。之后线程以该终止顶点作为另一路径的起始顶点继续进行路径划分过程,直到所有边都被遍历一遍为止。这样可以保证划分的每条路径除了起始/终止顶点之外,没有交点。
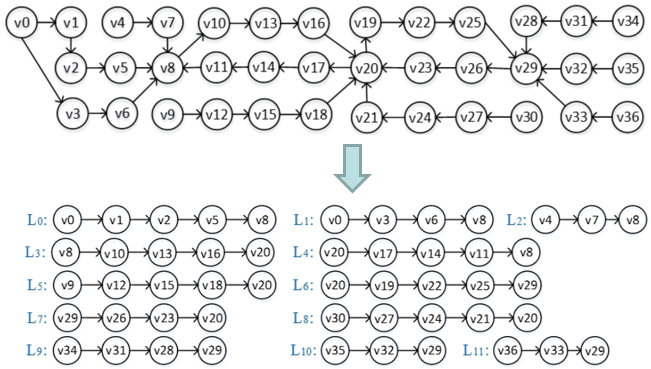
图2 路径划分示例
划分完成后,路径以图3所示的格式进行存储。其中数组EIdx存储顶点索引,两个连续值表示一条边。数组Sval大小和EIdx大小相同,它存储的是EIdx中对应顶点的状态。PathTable用于存储每条路径起始顶点在数组中EIdx的索引值,它相邻两项相减的差为前一项对应的路径长度。Eval和Vval则分别存储边的权值和顶点的状态值(按索引值升序)。
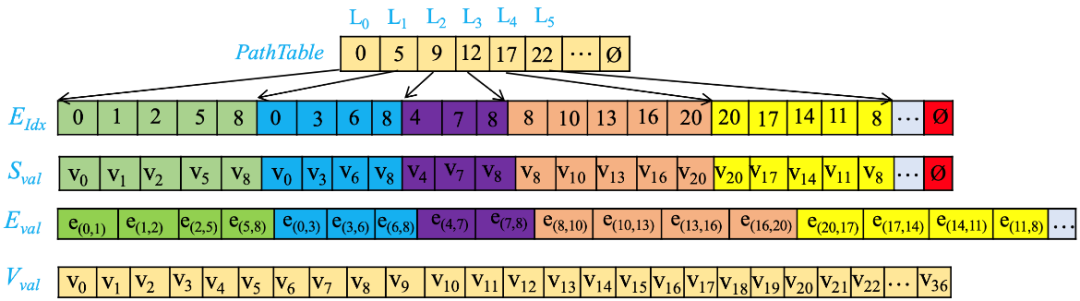
图3 路径存储格式
通过上述路径划分方法和存储格式,LargeGraph可以在执行时根据路径之间的依赖关系高效地识别所需要的路径子集。它使我们能够使用轻量级的运行时方法来动态探索在每一轮图形处理开始时源自活跃顶点的依赖链。
依赖感知的数据驱动执行方法
在图计算迭代过程中,只有在活跃顶点依赖链上的相关数据需要进行处理。因此,在每轮迭代开始前,LargeGraph会将所有活跃路径进行识别。具体来说,活跃路径包括:1) 具有活跃顶点的路径(初始活跃路径);2) 从活跃路径出发,根据路径之间依赖关系迭代探索到的路径。在识别完成之后,所有活跃路径被用于逻辑块的构成,如图4所示。然后CPU或GPU会对这些逻辑块进行处理。这样,许多与非活动路径相关联的图数据,不会被加载和处理。
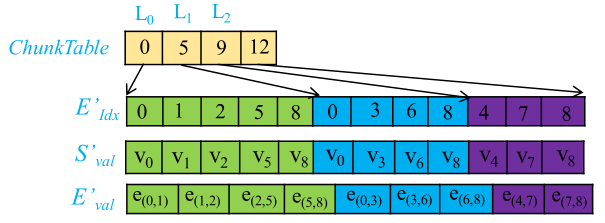
图4 逻辑块示例
生成逻辑块时,使用频率高的路径被放在同一个块中。剩余的路径合并成为使用频率较低的逻辑块。然后,逻辑块调度器将常用逻辑块的处理分配给GPU。具体实现是,将这些逻辑块存储在工作列表Wf中,而使用频率较低的逻辑块存储在其他工作列表Wr中。其中,Wf仅由GPU处理,Wr仅由CPU处理。如图5所示,Wf和Wr这两个工作列表是在主机的主内存中创建的。使用频率高的区块集和使用频率低的区块集会随着时间的推移而动态变化。工作列表中的逻辑块分别以异步方式并发驱动CPU线程和GPU线程。当两个工作列表中都没有逻辑块时,流程结束。由于使用频率高的块中的图路径被反复用于传播大多数顶点状态,所以需多轮图处理来达到收敛。所以,在交换出流多处理器之前,会重复处理每个加载的使用频率高的逻辑块,直到其所有顶点都处于非活跃状态。这样,每个逻辑块中的大多数传播可以通过频率高的逻辑块快速到达其他块。
即使对于列表,其中平均使用频率较低的逻辑块可能会使平均使用频率较高的区块频繁地出入GPU,这会导致平均使用频率更高的块的缓存抖动。而且,每个逻辑块的平均使用频率会随时间动态变化。因此,LargeGraph还在GPU内存中显式创建另一个工作列表WfG,并尝试将使用最频繁的一些路径存储在其中。即使这些路径在迭代过程中变成了非活跃状态,也很可能马上恢复活跃状态并被频繁访问。仅当GPU内存已满,而且WfG中路径的平均使用频率小于需要传输到GPU处理路径的平均使用频率时,这些路径才会从GPU中交换出来。换句话说,在GPU线程处理一个频繁使用逻辑块后,该线程从GPU内存上的工作列表WfG中获取下一个要处理的逻辑块。若无法获取,则再从主机内存中的工作列表Wf中获取合适的逻辑块。
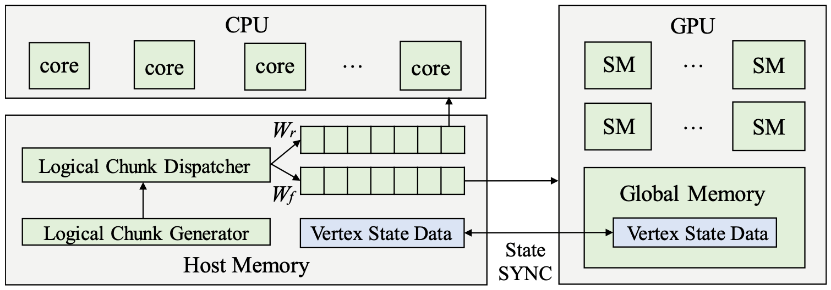
图5 LargeGraph系统架构
