利用Lighthouse进行覆盖率统计及其优化
介绍IDA覆盖率统计插件Lighthouse的使用,并对其覆盖率输出方式进行修改,获得可阅读的明文代码执行路径信息。
1、背景
最近有统计覆盖率信息的需求,多方搜索后发现IDA插件Lighthouse具有统计覆盖率的功能,通过读取DynamoRIO或者Pin产生的覆盖率日志文件,在IDA中以图形化形式展现代码的详细执行路径。
DynamoRIO或Pin等插桩工具默认使用的日志文件格式为drcov格式,这是一种二进制格式,每个基本块的信息的都是以十六进制数据进行记录。虽然二进制形式的记录方式有利于提高性能,但是人工阅读困难。
2、Lighouse的基本使用
(1)下载:Lighthouse(https://github.com/gaasedelen/lighthouse)
(2)安装:
在IDA中找到插件文件的目录:
import idaapi, os; print(os.path.join(idaapi.get_user_idadir(), "plugins"))
将下载下来的源码中的/plugins/文件夹copy到上面命令执行结果的目录中,然后重启IDA。
(3)获取drcov格式覆盖率统计日志文件:
首先使用Pin或DynamoRIO获取覆盖率统计文件(这里以Pin为例):
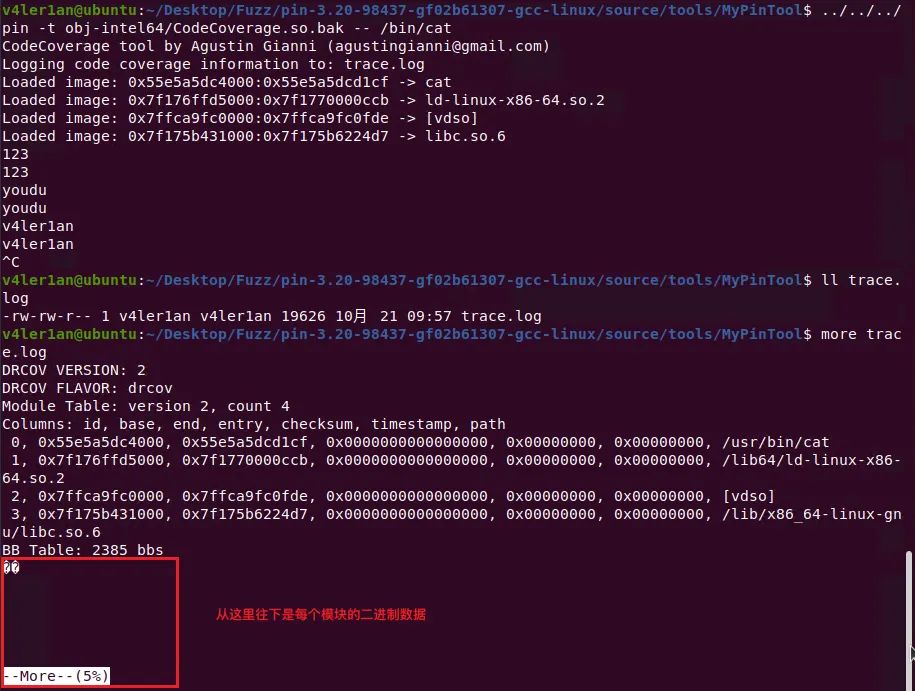
这里需要注意的是,Lighthouse默认使用的drcov文件版本为version 2,但是最新版的DynamoRIO生成的drcov文件的版本为version 3,所以在导入IDA时会提示文件格式错误。Lighthouse目前提供了pin和frida的覆盖率统计插件,DynamoRIO的需要做修改或者使用旧版本的DynamoRIO:
(4)IDA中导入日志文件:
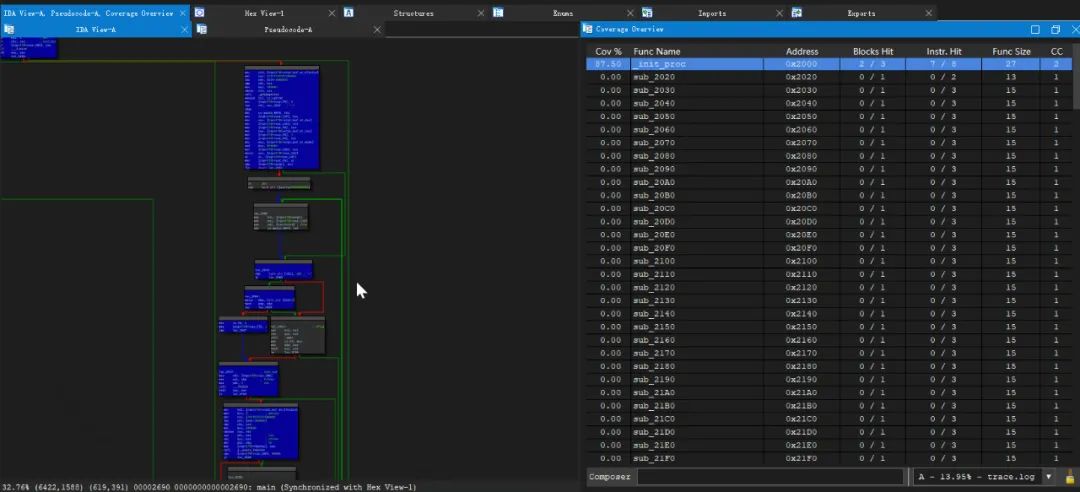
首先IDA加载要观察的可执行文件,然后File -> Load file -> Code coverage file...加载刚刚生成的日志文件:
控制流图的蓝色基本块为执行了的基本块,右侧为coverage的overview信息。
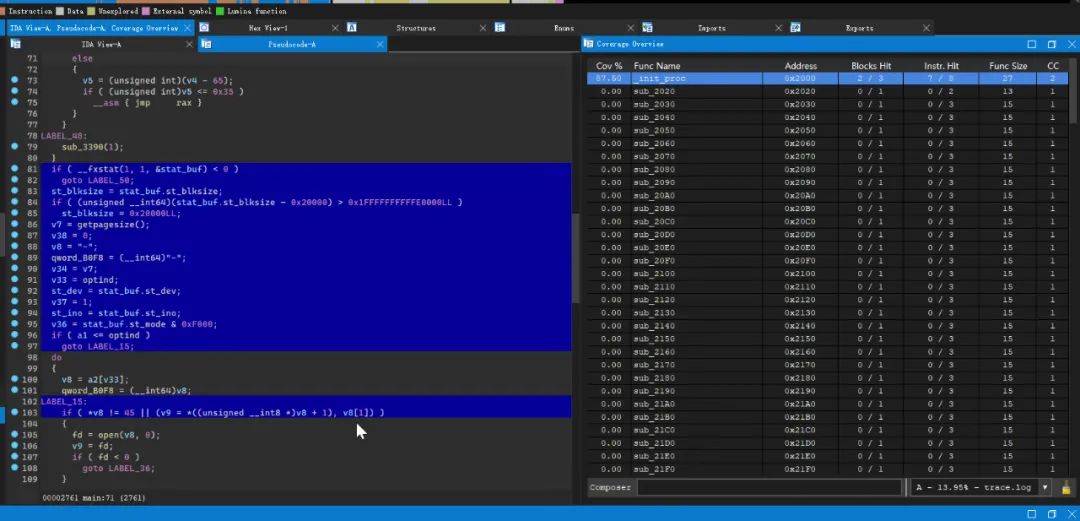
同样进行F5之后,可以看到执行过的伪代码:
3、drcov文件格式
(1)简介
drcov是基于DynamoRIO框架的用于收集二进制程序覆盖率信息的一种工具,其收集的覆盖率信息格式即为drcov格式。因为其成熟高效的特点,很多进行覆盖率收集的工具都会使用这种格式。
DynamoRIO官方并未对drcov格式进行详细的说明,所以此处进行说明记录,希望能对后续的覆盖率信息收集工具的开发起到一定的作用。
(2)详细格式
首先,drcov格式有一个包含一些metadata的头部:
DRCOV VERSION: 2DRCOV FLAVOR: drcov
在Lighthouse(https://github.com/gaasedelen/lighthouse)中只支持了version 2的格式;DRCOV FLAVOR是一个描述产生覆盖率信息的工具的字符串,并没有具体的实际作用。
然后,是在收集覆盖率信息的过程中加载的模块的映射的模块表:
Module Table: version 2, count 39Columns: id, base, end, entry, checksum, timestamp, path 0, 0x10c83b000, 0x10c83dfff, 0x0000000000000000, 0x00000000, 0x00000000, /Users/ayrx/code/frida-drcov/bar 1, 0x112314000, 0x1123f4fff, 0x0000000000000000, 0x00000000, 0x00000000, /usr/lib/dyld 2, 0x7fff5d866000, 0x7fff5d867fff, 0x0000000000000000, 0x00000000, 0x00000000, /usr/lib/libSystem.B.dylib 3, 0x7fff5dac1000, 0x7fff5db18fff, 0x0000000000000000, 0x00000000, 0x00000000, /usr/lib/libc++.1.dylib 4, 0x7fff5db19000, 0x7fff5db2efff, 0x0000000000000000, 0x00000000, 0x00000000, /usr/lib/libc++abi.dylib 5, 0x7fff5f30d000, 0x7fff5fa93fff, 0x0000000000000000, 0x00000000, 0x00000000, /usr/lib/libobjc.A.dylib 8, 0x7fff60617000, 0x7fff60647fff, 0x0000000000000000, 0x00000000, 0x00000000, /usr/lib/system/libxpc.dylib ... snip ...
模块表的头部有两种变体,都包含模块表中的条目数:
Format used in DynamoRIO v6.1.1 through 6.2.0 eg: 'Module Table: 11'Format used in DynamoRIO v7.0.0-RC1 (and hopefully above) eg: 'Module Table: version X, count 11'
每个版本的表格格式有些许不同:
DynamoRIO v6.1.1, table version 1: eg: (Not present)DynamoRIO v7.0.0-RC1, table version 2: Windows: 'Columns: id, base, end, entry, checksum, timestamp, path' Mac/Linux: 'Columns: id, base, end, entry, path'DynamoRIO v7.0.17594B, table version 3: Windows: 'Columns: id, containing_id, start, end, entry, checksum, timestamp, path' Mac/Linux: 'Columns: id, containing_id, start, end, entry, path'DynamoRIO v7.0.17640, table version 4: Windows: 'Columns: id, containing_id, start, end, entry, offset, checksum, timestamp, path' Mac/Linux: 'Columns: id, containing_id, start, end, entry, offset, path'
虽然有很多列的数值,但是实际上能于Lighthouse交互的数据只有以下几种:
id: 生成模块表时分配的序号,稍后用于将基本块映射到模块。
start, base: 模块开始的内存基地址。
end: 模块结束的内存地址。
path: 模块在硬盘上的存储路径。
最后,日志文件有一个基本块表,其中包含在收集覆盖信息时执行的基本块列表。虽然drcov可以以文本格式转储基本块表(使用-dump_text选项),但它默认以二进制格式转储表。
BB Table: 861 bbs<binary data>
该表首先是一个表头,表明基本块的数量。后续跟的数据是一个每个8字节大小的__bb_entry_t结构组成的数组,__bb_entry_t的结构如下:
typedef struct _bb_entry_t { uint start; /* offset of bb start from the image base */ ushort size; ushort mod_id;} bb_entry_t;
结构解释如下:
start: 距离基本块入口开始的模块的基地址的偏移。
size: 基本块的大小。
mod_id: 发现的基本块所在模块的id,与前面模块表中的id是对应的。
基于上面3个元素,就可以知道哪个基本块被执行了,从而作为覆盖率信息进行收集。
(3)修改输出方式为明文(以Pin插件为例)
因为Lighthouse默认输出的覆盖率日志文件时drcov格式的,人工阅读存在一定的困难。在某些场景下,需要直接获得人工易读的代码执行路径信息,所以考虑对Lighthouse的覆盖率统计插件进行修改。
Lighthouse的覆盖率统计功能在如下代码中:
# CodeCoverage.cpp static VOID OnFini(INT32 code, VOID* v){ ...snap... drcov_bb tmp; for (const auto& data : context.m_terminated_threads) { for (const auto& block : data->m_blocks) { auto address = block.first; auto it = std::find_if(context.m_loaded_images.begin(), context.m_loaded_images.end(), [&address](const LoadedImage& image) { return address >= image.low_ && address < image.high_; }); if (it == context.m_loaded_images.end()) continue; tmp.id = (uint16_t)std::distance(context.m_loaded_images.begin(), it); tmp.start = (uint32_t)(address - it->low_); tmp.size = data->m_blocks[address]; context.m_trace->write_binary(&tmp, sizeof(tmp)); } }}
首先设置了一个drcov_bb结构tmp,其完整格式如下:
struct __attribute__((packed)) drcov_bb { uint32_t start; uint16_t size; uint16_t id; };
然后进入到一个内外嵌套循环中,在每个内循环中每读到一个bb信息就对tmp结构进行赋值:
tmp.id = (uint16_t)std::distance(context.m_loaded_images.begin(), it);tmp.start = (uint32_t)(address - it->low_);tmp.size = data->m_blocks[address];
最后调用write_binary函数写入到trace文件中:
context.m_trace->write_binary(&tmp, sizeof(tmp));
而write_binary函数的实现在Trace.h文件中:
void write_binary(const void* ptr, size_t size){ if (fwrite(ptr, size, 1, m_file) != 1) { std::cerr << "Could not log to the log file." << std::endl; std::abort(); }}
可以看到本质上就是调用fwrite函数进行流操作。此外,还有一个write_string函数:
void write_string(const char* format, ...){ va_list args; va_start(args, format); if (vfprintf(m_file, format, args) < 0) { std::cerr << "Could not log to the log file." << std::endl; std::abort(); } va_end(args);}
该函数用作想trace文件中写入string格式的数据。这么一来就好办了,直接用现成的即可,只需要修改在写文件时的操作就ok了。修改后的代码如下:
// drcov_bb tmp; 这里要注释掉。否则有的环境会报编译不通过 for (const auto& data : context.m_terminated_threads) { for (const auto& block : data->m_blocks) { auto address = block.first; auto it = std::find_if(context.m_loaded_images.begin(), context.m_loaded_images.end(), [&address](const LoadedImage& image) { return address >= image.low_ && address < image.high_; }); if (it == context.m_loaded_images.end()) continue; uint16_t id = (uint16_t)std::distance(context.m_loaded_images.begin(), it); uint32_t start_addr = (uint32_t)(address - it->low_); int size = data->m_blocks[address]; context.m_trace->write_string("[+]module: [%d] 0x%08x %d\n", id, start_addr, size); }}
这种格式只能用作人工阅读或进一步的处理,没有办法再使用drcov2lcov和genhtml工具进行转换了,最终实现的效果如下:

会以明文形式打印出每个模块的执行的基本块的地址和块大小,这样就方便人工进行阅读,还可以进一步提取出模块执行的地址,进行后续处理。
