随着大数据时代的来临,大数据的巨大价值让许多互联网企业看到了新的商机,促使一批又一批的行业精英成为数据资产化之路的“垦荒人”。大数据的价值也由一个抽象的描述逐渐变成了可视化的计量。借助对数据资产的运营,诸多互联网企业年年都可以拿出令人炫目的业绩报表。而对于它们的财富来源,我们整个社会都是缺乏追问的。
当前,我国数据资源资产化正在如火如荼地开展,实践的脚步早已超越理论走在“资产化”最前沿。目前,市场经济已证实数据资产具有价值属性,但其价值需要在数据的应用和流通中体现。实际上,无论政府还是部分企业,都拥有非常丰富的大数据资源,但是大部分都被束之高阁,有数据需求的企业无法获取。其中横亘的第一道“天堑”就是数据产权的问题。这个问题看似简单,实则不然。要探讨清楚,还要从“数据”一词说起。
1. 数据加工与数据资产化
(1)数据加工:从原生数据到衍生数据
以数据加工为界,数据可以分为原始数据和二次开发利用数据。原始数据是指不依赖现有数据而产生的数据,即数据从0到1的过程。二次开发利用数据是指原始数据被存储后,经过算法筛选聚合、加工、计算而成的系统的、可读取、有使用价值的数据,如购物偏好数据、浏览偏好数据、分析数据等,即从1到f(1)的过程(注:从0到1仅表示从无到有的含义,f()仅表示数据的加工、计算、聚合的操作过程,均不表示具体含义)。
原始数据是不能再生的数据,而二次开发利用数据是可再生的数据。以互联网为例,互联网上的数据主要基于用户行为而产生。用户在互联网上的操作包括两类,一类是输入,另一类是点击。前者如用户注册时输入姓名、邮箱,使用服务后的评论,使用搜索引擎时的搜索内容输入,等等;后者如用户通过鼠标点击某个页面、点击某个商品链接、点击下单、点击提交、点击确认,这些均属于原始数据的范畴。而二次开发利用数据则是在这些用户输入和点击的日志的基础上,通过算法计算、加工、聚合后形成一条条结构化的数据。
当数据量小时,原生数据体现数据的价值,因为从数据内容中可以直接读取直观的信息获取价值。当面对大数据时,原生数据的直观价值锐减,反而侧重于数据之间相关性的价值挖掘,这就是所谓的衍生数据价值。大数据时代,原生数据不能被直接利用,需要对其进行加工。就像翡翠原石的开采,在没有加工成饰品时,翡翠原石与石头一般无二。这样的数据加工、计算、聚合,实现了从数据原石到数据宝石的演变。演变后,这种数据就是我们所称的衍生数据。大数据经济环境下,企业追逐的数据价值基本都体现在衍生数据上,而衍生数据价值的高低则取决于原生数据到衍生数据的聚合、加工、计算的准确程度。
(2)数据资产化
数据加工让数据的价值凸显,而随着大数据时代的到来,数据分析处理技术的提升使一个个数据抽象的描述逐渐成了可视化的计量,成为大数据进入国民经济体系和国民视野的一个良好途径。
那么,数据能否和其他财产一样成为资产呢?我们还要先搞清楚资产的含义。在会计学领域,资产是指企业过去事项形成的属于企业管领控制的、预期能为企业带来经济利益的总流入。同理,数据资产作为资产大类中的一员,其定义也应突出两个方面:其一,企业合法占有数据资产,体现其控制属性;其二,数据资产预计能为企业带来经济利益的正向流入,彰显数据的价值属性。通过以上两个标准可知,数据并不等于数据资产。换句话说,并非所有的数据均有经济利益,除非同时满足可被计量、可被控制、可被变现的属性。值得一提的是,数据资产的变现过程就是当前数据资产化的过程。
近年来,我国数据产业迅速发展,数据产业链中的一大亮点就是数据交易产业。2015年4月15日,贵阳大数据交易所正式挂牌。随后,中关村数海数据资产评估中心有限公司也获批成立,这是我国首家数据资产登记确权赋值的服务机构。目前,已有不少企业通过数据资产运营,让数据实现了价值。广东省数字广东研究院、深圳市腾讯计算机系统有限公司作为卖方,完成了买方为中金数据系统有限公司、京东云平台的首批数据交易。许多数据创新型企业通过数据资产登记评估等资产化获得挂牌上市的机会,例如,优势科技、数云惠普成功在北京四板市场孵化板挂牌上市。还有很多企业成功将数据资产作为一种新型资产进行抵押,实现了融资,例如,贵州东方世纪科技有限公司成功抵押其数据资产,贷款100万元。由此可见,当前数据资产化是大势所趋,数据的经济价值必然成为人们追逐的热点。
2. 用数据说话:关于数据争议案件的统计
近年来,因为不清楚数据归谁而导致的问题数不胜数。下面,利用大数据的技术手段来介绍由此引发的纷争。这里利用Alpha案例库,检索获取了2019年3月30日前的民事纠纷裁判文书共计489678篇。其中,从2010年到2019年3月20日前的民事纠纷裁判文书分布如图1所示。
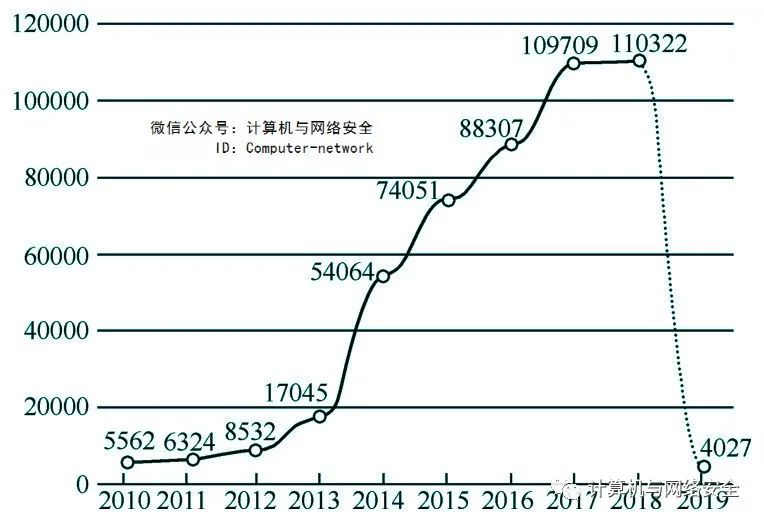
图1 民事纠纷裁判文书分布
从图1可以看到,“数据”民事案件数量伴随文书公开,基本呈逐年增长的趋势。
从图2的案由分类情况可以看到,当前的民事案件案由分布由多至少分别包括四类:合同、无因管理、不当得利纠纷类;侵权责任纠纷;劳动争议、人事争议类;知识产权与竞争纠纷类;人格权纠纷。
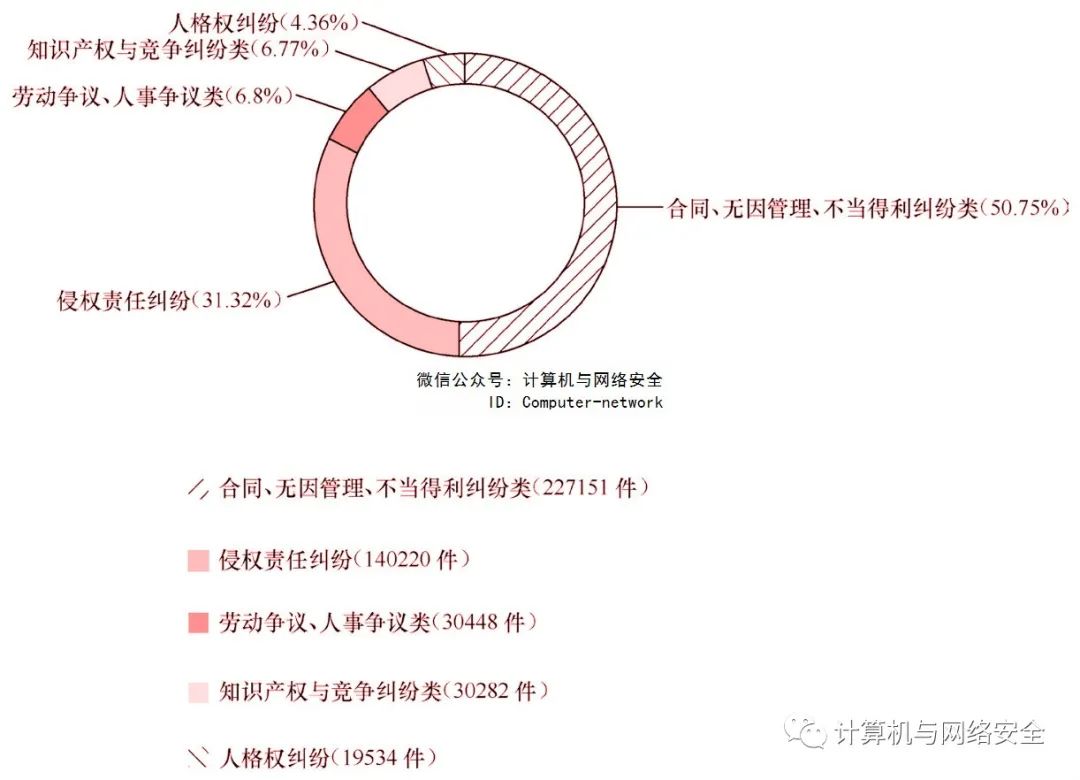
图2 “数据”民事案件案由分布
继续深入分析,目前有关数据权属的争议多以知识产权不正当竞争的案由显现。下面进一步细分,将案由锁定在知识产权与竞争纠纷类,看一下案件分布。本次检索获取了2019年3月30日前的知识产权与竞争纠纷裁判文书共30282篇。其中,从2010年到2019年3月20日前的知识产权纠纷裁判文书分布如图3所示。

图3 知识产权纠纷裁判文书分布
从图3可以看到,“知识产权与竞争类纠纷”在2016-2017年呈现爆炸式增长。
从图4的案由分类情况可以看到,当前最主要的案由是知识产权权属、侵权纠纷类,其次是知识产权合同纠纷类,然后是不正当竞争纠纷类、垄断纠纷类及其他知识产权与竞争纠纷。
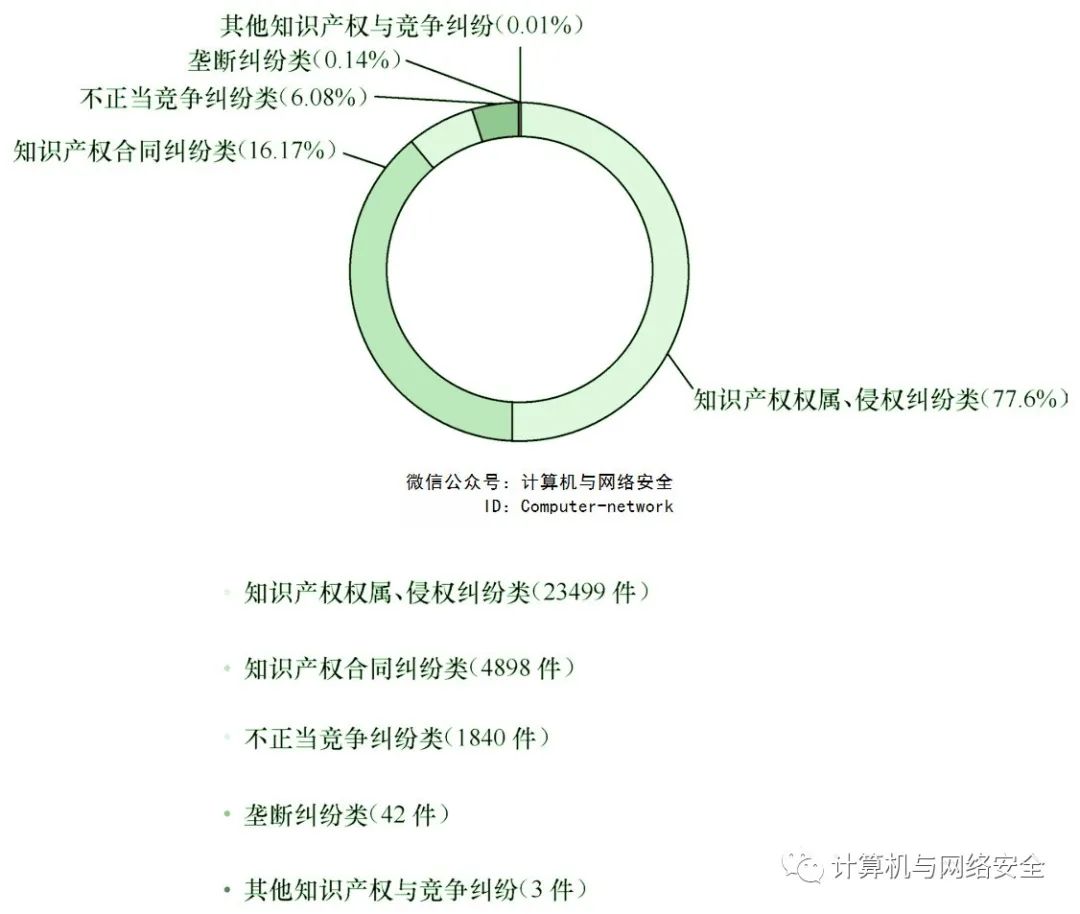
图4 “数据”知识产权与竞争纠纷案由分布
宏观上,大数据很好地展示了数据纠纷以及数据权属争议正在社会生活中频繁出现,数据问题并非学者们的凭空臆想。从数据概念分析以及现阶段围绕数据利用产生的争议来看,数据归谁所有的问题是根源,必须要加以解决。
3. 数据产权的三大争议:所有权、使用权、收益权
当前的数据产权争议可以归结为三大核心问题:数据归谁所有?谁可以用数据?数据收益如何分配?
(1)数据归谁所有
典型案例是新浪微博起诉脉脉抓取和使用微博用户信息案,该案也被业界称为“大数据引发不正当竞争第一案”。
脉脉作为一款社交软件,通过与新浪微博合作,能够利用用户的新浪微博发现新朋友,并帮助他们建立联系。根据二者之间签订的《开发者协议》,脉脉只能获得新浪微博用户的姓名、性别、头像、电子邮箱这些信息。然而,在合作期间,未经微博平台许可,脉脉调用了大量微博用户的教育信息、职业信息和手机号码。此外,在合作终止后,脉脉仍将其用户手机通信录里的联系人与新浪微博用户对应,并展示在脉脉用户“一度人脉”中。
新浪微博认为脉脉非法抓取了教育信息、职业信息以及手机号码等高级权限下才能调取的信息,违反了与新浪微博签订的《开发者协议》,获得了本属于新浪微博的用户信息。本案暴露的一个问题就是数据权属问题,即新浪微博是否合法取得用户在该平台上的所有数据。
另一类数据争议以腾讯微信与华为荣耀的数据之争为代表。华为荣耀Magic手机从一发布便以“开启智慧生活”“致未来”为口号,主打其高度的智能化。例如,用户在与朋友闲聊谈及某部电影时,手机会自动为用户推送该电影的评分、网友评论及票务信息等;当用户在晚上下班路过小区的快递柜时,手机可以产生震动或发出铃声并推送用户当天收到的快递信息,以提醒用户取件。
这是华为利用数据分析为我们展现的未来智能化生活。当人们在感慨华为荣耀Magic手机无比酷炫的同时,华为荣耀Magic手机却不得不面对腾讯的质疑。腾讯认为华为荣耀Magic手机在使用过程中私自扫描用户数据并自动加载相关信息的行为未经腾讯公司的许可,侵犯了微信用户的隐私。
近年来,政府作为公共事务管理机关,无时无刻不在收集社会各界的数据信息,如我们的身份证信息、指纹信息、信用信息及出行信息等。目前,中央和省级政府正在推动建立统一的政务云平台和数据共享交换平台,致力于打破“数据孤岛”,实现数据自由、有序流通。无论是政府各部门之间的数据交换共享,还是政府向社会公众释放数据信息以促进数字经济的深度发展,都无法回避数据权属问题。
公民的社保缴费记录,患者的就诊记录,企业的工商登记信息……这些数据的产权属于个人或企业,还是属于政府部门?如何做出清晰界定,将直接决定谁享有数据的权益。
大家普遍认为,政府部门收集数据是政府公共管理行为,也是非盈利性行为,所以政府部门收集的数据归属于政府无可厚非。但是,对于去除个人身份属性的数据交易中的数据,到底归属于个人,还是记录数据的企业,各方莫衷一是。
(2)谁可以用数据
我们每个人无时无刻不在产生数据,也在频繁地使用数据。例如,通过微信步数统计查看最近一周的运动量,通过应用监测睡眠状况、心跳情况,使用支付宝查询最近的消费记录,这些都是我们对自己数据的使用行为。个人产生和使用数据,并不意味着只有社会公众可以使用数据,企业对这块诱人的数据“蛋糕”只能望而却步。如果真的如此,那就明显与现阶段的社会实情相背离,数字经济也将面临巨大的发展困境。
事实上,当前大规模使用数据的主体有两个:一个是政府,另一个是企业。政府通过其各个行政机关、网站采集大量的政务数据。当前政府大数据使用旨在解决政务信息化建设中“各自为政、信息孤岛”的问题,结合各地实际统筹推进政务信息系统整合共享的工作。各部门、各级政府信息系统要想实现互联互通,首先面对的就是数据规模庞大,且来源、结构复杂的问题。
大数据在企业中的应用无处不在,包括金融、汽车、餐饮、电信、能源、体育和娱乐等在内的社会各行业都已经融入了大数据的印迹。具体地说,传统行业如制造业利用工业大数据提升生产水平,包括产品故障诊断与预测、分析工艺流程、改进生产工艺,以及优化生产过程能耗和生产排期;互联网行业更是使用大数据的重点阵地,借助大数据技术,互联网企业可以分析客户行为,进行商品推荐和针对性广告投放。在金融领域,大数据可以帮助企业分析高频交易、客户及信贷风险;当企业积累的数据达到一个量级时,可能产生质变,催生出新的商业模式。以蚂蚁微贷为例,阿里巴巴利用多年的线上零售数据、支付金融数据、个人身份数据等,通过多维数据的整合、加工、计算构建信用维度,极大地提高了蚂蚁微贷发放贷款的效率。这是人工智能和大数据在金融领域的初步应用,很多金融产品机构也在进行这方面的改进。
(3)数据收益如何分配
通过使用数据产生巨额的经济收益,那么,这份巨额收益是如何进行分配的呢?是分配给数据的产生者个人,还是赋予数据的收集、加工者政府或企业呢?对这个问题的回答牵动着众多主体的利益。
从当前企业之间的争议或司法判决来看,大数据产生的这部分收益归属于数据的收集、加工者,即企业。
新浪微博诉脉脉抓取用户信息案确认了企业对其收集积累的数据享有竞争法意义上的财产权利。虽然目前我们并未针对数据的绝对财产权做出明确规定,但是法院在该案件中明确了以下原则:作为投入努力和资源进行数据收集的企业,可以享有竞争法意义上的保护,即可以将该数据作为资产进行利用、许可,并从中获益。在该案例中,法院明确了即便在技术可行的情况下(未使用破坏性的技术,或绕开权利人一方的技术保护措施),他人未经许可和授权也不得随意进行信息抓取和利用。
大众点评诉百度不正当竞争案中,司法裁判论证提出百度可以向大众点评购买信息,这个论证思路暗含的规则就是承认大众点评平台对用户点评数据的控制权,大众点评平台对其用户数据享有收益、处分的权利,他人未经许可和授权不得随意进行抓取和利用。这个观点与新浪诉脉脉案不谋而合。
可见,当前无论是判决实践还是司法态度,都偏向将数据收益分配给二次开发利用数据的收集者、创造者、实际控制者——企业。那么,作为政务数据的采集者政府以及数据的生产者个人在没有司法判决的支持下,又是否能够合法合理地享有数据收益权呢?这些问题都是数据治理的关键,需要在理论和立法上加以解决。
 X0_0X
X0_0X
 Coremail邮件安全
Coremail邮件安全
 007bug
007bug
 X0_0X
X0_0X
 RacentYY
RacentYY
 Anna艳娜
Anna艳娜
 一颗小胡椒
一颗小胡椒
 Andrew
Andrew
 Andrew
Andrew
 X0_0X
X0_0X
