ollvm反混淆学习
看了@无名侠大佬发的一篇关于使用unicorn模拟执行还原ollvm的贴子受到了很大的启发, 自己也基于这个思路做了些样本学习,下面来探讨一下。
ollvm原理
Ollvm大致可分为 bcf(虚假块), fla(控制流展开), sub(指令膨胀), Split(基本块分割)
bcf:
克隆一个真实块,并随机替换其中的一些指令,然后用一个永远为真的条件建立一个分支。克隆后的块是不会被执行的。
Fla:
将所有的真实块使用一个switch case结构包裹起来,每个真实块执行完毕后都会重新赋值switch var,对于有分支的块会使用select指令,并跳转到switch起始代码块(分发器)上,根据switch var来执行下一个真实块。
Sub:
指令膨胀,将一条运算指令,替换为多条等价的运算指令。
Split:
利用随机数产生分割点,将一个基本块分割为两个,并使用绝对跳转连接起来。
关于ollvm具体的实现,可参考源码。
还原思路
网上有很多还原ollvm的脚本,但是只能还原特征很明显的ollvm,或者说只是debug版的ollvm。在debug版中ollvm的特征非常明显,一个分发器,和引用了这个分发器的真实块。但经过编译器优化后,分发器可能会变成多个,基本块会合并造成虚假块也可能会和真实块合并,等等。
现实情况是,你基本上碰不到简单的ollvm,所以那些东西个人感觉意义不是很大,还是需要靠自己。
谈下还原思路
Bcf:
Bcf块是执行不到的块,所以说当使用unicorn 跑过一遍函数后,其中没有执行到的块肯定有包括bcf块,我们只需要将它挑出来标记下就好。
但函数中可能存在分支,只跑一遍函数是无法覆盖到所有分支的,所以要想办法找到函数的所有分支。一开始采用的是无名侠大佬的方法,当碰到csel指令时人工干预让其覆盖所有分支,但整个函数经常陷入死循环,分析过后发现虚假块的跳转也有可能使用csel指令。
后来想到了在二进制漏洞挖掘中的思路fuzz(模糊测试),即变异函数的参数传递给函数,来覆盖更多的分支。这样做也不能说能够找到函数的所有分支。影响一个函数的分支执行大概有三种情况,参数,全局变量,内部函数调用的返回值。后两种情况的话留意下模糊执行的trace应该能找到些蛛丝马迹,可能会比较麻烦。
Fla
这个环节会产生控制流块,我们只需要将这些块挑出来标记,找出所有的真实块,并通过模拟执行还原真实块之间的关系就好。
控制流块的剔除采用了无名侠大佬对基本块签名的方法。
Sub:
指令膨胀的还原,使用llvm的pass优化效果还可以,但目前一些ir翻译工具对arm64的支持不怎么样。
Split:
基本块分割更多是用来增加bcf和fla效果的。
总结整体思路:
(1)利用模拟执行和fuzz技术,找出bcf块并剔除。
(2)使用基本块签名剔除控制流块。
(3)将剩余的块标记为真实块,并使用模拟执行找出对应关系。
(4)根据对应关系,重构cfg。
实战
自己编译的一个样本如下:
void HexDump(char *buf,int len,int addr)__attribute((__annotate__(("split"))))__attribute((__annotate__(("fla"))))__attribute((__annotate__(("bcf")))){ int i,j,k; char binstr[80]; for (i=0;i if (0==(i%16)) { sprintf(binstr,"%08x -",i+addr); sprintf(binstr,"%s %02x",binstr,(unsigned char)buf[i]); } else if (15==(i%16)) { sprintf(binstr,"%s %02x",binstr,(unsigned char)buf[i]); sprintf(binstr,"%s ",binstr); for (j=i-15;j<=i;j++) { sprintf(binstr,"%s%c",binstr,('!''~')?buf[j]:'.'); } printf("%s",binstr); } else { sprintf(binstr,"%s %02x",binstr,(unsigned char)buf[i]); } } if (0!=(i%16)) { k=16-(i%16); for (j=0;j sprintf(binstr,"%s ",binstr); } sprintf(binstr,"%s ",binstr); k=16-k; for (j=i-k;j sprintf(binstr,"%s%c",binstr,('!''~')?buf[j]:'.'); } printf("%s",binstr); }}
先找出所有的基本块(以跳转指令结尾的块)
这里需要注意下由于编译器优化的关系,基本块会合并,有些基本块并不是以跳转指令结尾,就如这样:
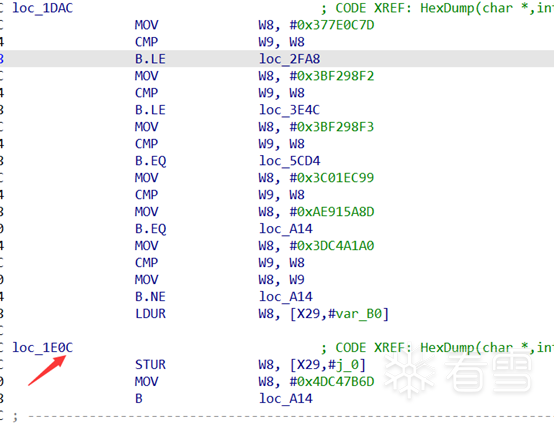
这些情况,是因为两个基本块同时引用了这个块,所以需要将这个块拷贝一份,并将另一个块的引用修改为新拷贝的块,不然还原关系的时候会乱掉。
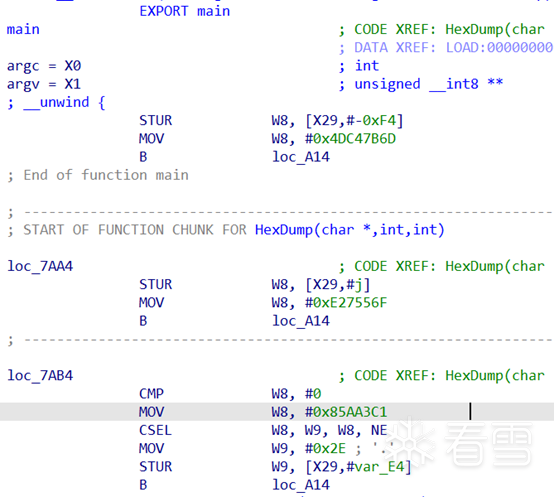
我这里占用了main函数的空间。
找出所有的基本块后开始fuzz执行,并统计所有被执行到的块。这里fuzz采用了,先使用peach编写规则生成参数的语料库保存到文件中,然后读取文件中的内容当作参数传递给函数, 当然如果不关心函数的其他分支,fuzz的步骤感觉可以跳过,例如一些纯算法函数。
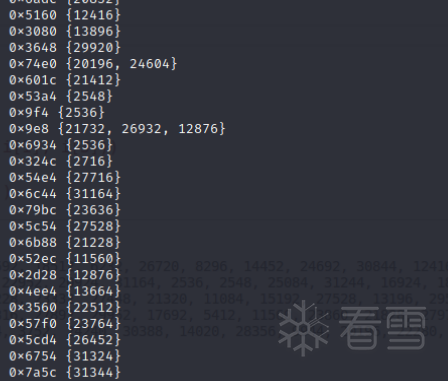
经过几十轮fuzz后,共统计到如下被执行了的块。

这些块中肯定是包含了控制流块的,所以现在用签名法来过滤掉控制流块。

过滤后还剩下169个块,这些块就是真实块了,为了保险起见我还人工过滤了一下,基本没什么问题。
接下来开始模拟执行找出他们之间的对应关系了,当碰到一个真实块时记录下它上一个执行的真实块,并保存起来。
传递给函数的参数也需要使用上面fuzz使用的参数,这样才能执行到每一个块。
模拟执行后,基本块之间的关系如下:
如果数组中只有一个基本块的话,那么他们是一个顺序关系,如果有两个的话则是分支关系, 如果2个以上则有三种情况:
(1)漏了真实块;
(2)该块不是一个真实块;
(3)该块是一个分支共用块。
经排查这里是第三种情况,如下:


9e8这个块被两个基本块引用,并两个基本块都是一个分支块,所以会出现这种情况。具分析其中一个块的分支对应的是bcf,不会被执行到,所以数组中是3个基本块而不是4个。对于这个情况也需要将9e8这个块copy一份,将两个基本块中的其中一个引用修改为copy后的块。


修改完毕后,记得将copy块添加到真实块中,并重试。
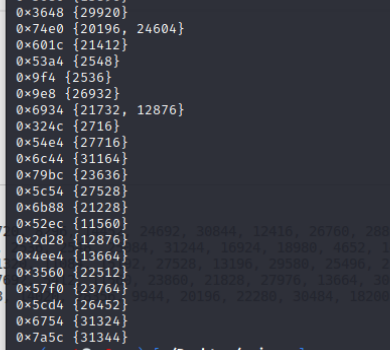
可以看到问题解决了。
找出对应关系后需要接着还原分支关系,当条件为真时跳到那个块,为假时跳转到那个块。因为每个分支块都会有一条cmp 和csel指令, 如果找到的分支块中没有这两条指令,那么就是漏了真实块。
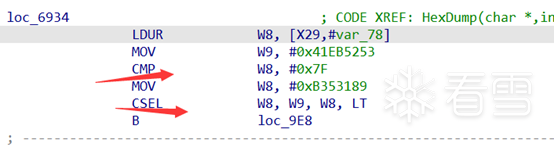
还原他们的关系,只需要在模拟执行时,记录cmp的返回值,和返回值对应的真实块即可,这里会比较麻烦,需要手动找到cmp的地址, 左右值, 和比较关系。

模拟分支块的关系如下:
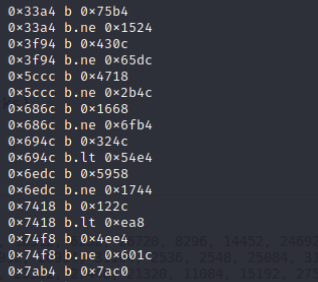
我这里根据记录的条件,翻译成了汇编。
最后根据这些真实块之间的关系patch即可, 注意在patch分支块时需要注意csel和cmp的关系,像这种:
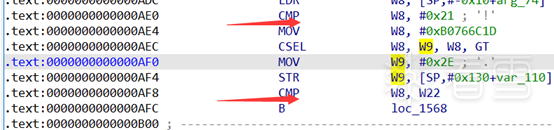
如果我们如果在基本块的最后patch b.ne xxx b xx, 那么标志位就会被上面的一个cmp干扰,所以需要将上面 一个cmp也patch掉。
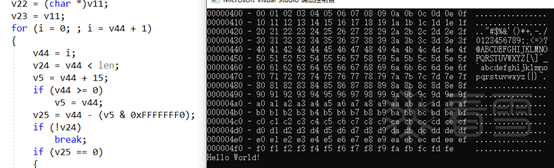
好了现在大功告成,直接来看伪代码。

把伪代码拿出来编译测试:
写在最后
目前还在测试大概还原了5 6个样本,可能还有一些细节方面未考虑到,所以发出来希望听下大佬的意见。
之所以没贴代码出来是因为代码太杂了和篇幅太大了,实在是不太方便,有需要的话可以参考无名侠大佬的帖子和源码,我都是基于他之上的。
如果大家感觉以上有不妥或者不理解的地方,欢迎和我一起探讨一起学习。
