腾讯游戏安全技术竞赛2023 安卓客户端初赛题解
一、解题情况
没有去专门绕过壳的反调试,完全使用frida和IDA静态分析,完成了第一个任务成功获取flag。
加密算法共4种,第二个任务注册机,缺一个算法的解密算法,其他三个算法均已写好C实现的解密算法。
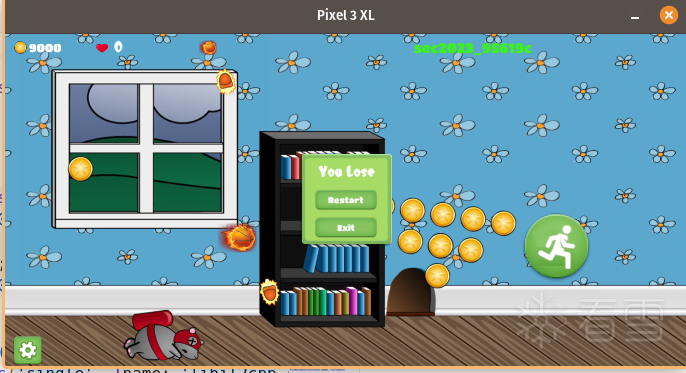
Flag截图
二、大概解题思路
frida默认会被检测,经过修改源码中的几个特征(端口号、临时目录、maps中相关字符串等),自行编译后获得一个可以hook除了libsec2023.so之外的所有so的frida。
随后hook系统函数dlopen,当加载libil2cpp.so之后从内存dump下来解密后的so文件,通过比较apk中的so来修复一些结构体信息,此时得到了一个完整的可被IDA正常解析的libil2cpp.so,因此可以用IL2CPPDumper恢复IDA中符号和结构体。
找到CollectCoin函数,使用frida去patch其中金币增加的逻辑,改为每次增加1000,这样我们就可以一次性达到获取flag的分数,从而轻易获取flag。
之后发现有两个被混淆了函数名称的C#类,经过足够的分析后,可以判断其中一个是VM,包含一些字段用来模拟栈、操作码等,总共有21个方法,除了构造方法外均为VM的Handler。随后在xxx函数通过frida分析找到XTEA加密,然后用frida在内存中找到并提取了密钥(第一处加密)。
(PS:这里的加密多少处是指我找的顺序,不是逻辑上的顺序)
Hook SmallKeyboard__iI1Ii_4610736函数后发现函数在开头跳转到了g_sec2023_p_array的函数中,随后在libsec2023.so分析该函数,发现被混淆。模式基本上都是将常规的分支、直接跳转改为用寄存器寻址跳转,寄存器中的跳转地址由一个常数+一个偏移来得到,常数和取偏移的基址在一个函数中是固定的,在跳转前,使用条件选择指令等来获取相应的偏移,从而间接实现分支跳转,使用Unicorn模拟执行+IDAPython修改汇编+遇到特殊情况手动改的方式,我们可以轻易地去除这个混淆。
去除混淆后可以找到两个加密算法(第三、四处加密),其中第三处可以直接分析,第四处加密通过frida hook得知是调用了Sec2023.Encrypt方法,该类由壳加载,JADX / JEB等工具无法直接分析,需要使用frida-dump工具在运行时dump下来,然后分析。随后可以发现一个加了BlackObfuscator的dex中就找到了该方法,由于没有去除混淆的方案,这里选择使用复制所有真实指令,结合第三处加密,通过frida观察加密结果来分析加密算法实现的是否正确了,得到了想要的结果之后就可以写这两处加密的解密函数。
最后回头去分析用VM实现的加密算法(第二处加密),我的解决方案是在frida中hook所有handler,通过输出所有被执行过的指令为C代码,将栈在输出的源码中处理成寄存器变量(register关键字),所有通过opcode来取出的值处理为常量,这样重新编译后就可以得到较为精简的加密算法,该过程需要结合frida多次观察和分析。
分析完这四处算法,逆向编写出这4处加密算法的解密算法,就可以成功实现注册机。
三、具体解题过程
*由于实际解题过程有点复杂和混乱,如果有地方没说清楚请谅解
整一个假的Frida
下载frida源码,将其中的/server/server.vala中的re.frida_server改为其他字符串,再把src/linux/linux-host-session.vala中的so文件特征字符串更改,然后用一个27042之外的端口启动修改好的frida,随后启动游戏,发现启动成功,并不会被检测。
Dump && Recover IL2CPP
虽然用修改后的frida去hook libsec2023.so仍然会被检测,但是hook其他库没有出现问题。而so在被dlopen加载之后有可能就解密好了,因此这里选择用frida去尝试hook dlopen去dump libil2cpp.so。
function WriteMemToFile(addr, size, file_path) {
Java.perform(function() {
var prefix = '/data/data/com.com.sec2023.rocketmouse.mouse/files/'
var mkdir = Module.findExportByName('libc.so', 'mkdir');
var chmod = Module.findExportByName('libc.so', 'chmod');
var fopen = Module.findExportByName('libc.so', 'fopen');
var fwrite = Module.findExportByName('libc.so', 'fwrite');
var fclose = Module.findExportByName('libc.so', 'fclose');
var call_mkdir = new NativeFunction(mkdir, 'int', ['pointer', 'int']);
var call_chmod = new NativeFunction(chmod, 'int', ['pointer', 'int']);
var call_fopen =
new NativeFunction(fopen, 'pointer', ['pointer', 'pointer']);
var call_fwrite =
new NativeFunction(fwrite, 'int', ['pointer', 'int', 'int', 'pointer']);
var call_fclose = new NativeFunction(fclose, 'int', ['pointer']);
call_mkdir(Memory.allocUtf8String(prefix), 0x1FF);
call_chmod(Memory.allocUtf8String(prefix), 0x1FF);
var fp = call_fopen(
Memory.allocUtf8String(prefix + file_path),
Memory.allocUtf8String('wb'));
if (call_fwrite(addr, 1, size, fp)) {
console.log('[+] Write file success, file path: ' + prefix + file_path);
} else {
console.log('[x] Write file failed');
}
call_fclose(fp);
});
}
function HookLibWithCallback(name, callback) {
var dlopen = Module.findExportByName('libdl.so', 'dlopen');
var detach_listener = Interceptor.attach(dlopen, {
onEnter: function(args) {
var cur = args[0].readCString();
console.log('[+] dlopen called, name: ' + cur);
if (cur.indexOf(name) != -1) {
this.hook = true;
}
},
onLeave: function() {
if (this.hook) {
console.log('[+] Hook Lib success, name:', name);
callback();
detach_listener.detach();
}
}
});
}
function DumpIL2CPP() {
var libil2cpp = TraverseModules('single', {name: 'libil2cpp.so'});
WriteMemToFile(libil2cpp.base, libil2cpp.size, 'libil2cpp.so');
}
function main() {
HookLibWithCallback('libil2cpp.so', DumpIL2CPP);
}
main();
从手机里把pull出来so,发现函数已经解密,IDA能正常解析,但是还有部分函数会爆红。因此用010editor对apk中的so和dump出来的so进行比对,补上尾部的重定位表,重新IDA打开,此时已经可以正常解析。
此时的libil2cpp.so非常完整,尝试使用IL2CPPDumper恢复符号,发现可以成功Dump。
Patch游戏逻辑 && 获得Flag
在dump.cs中搜索金币相关方法以及字段,发现了CollectCoin这个函数。
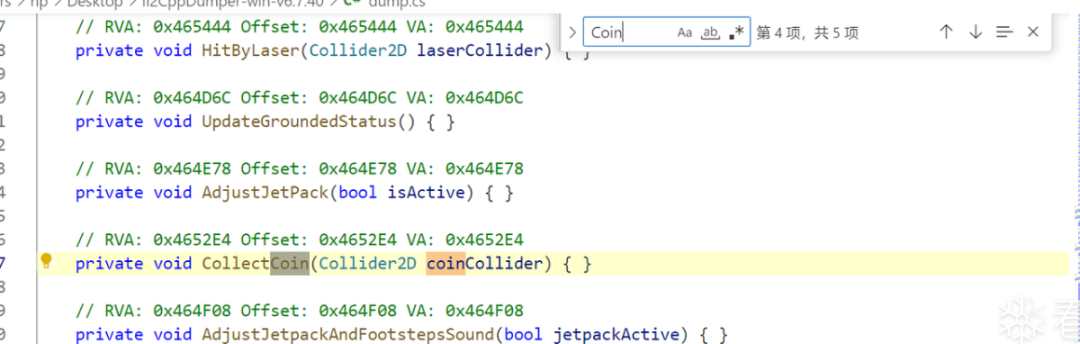
IDA不断跟进,可以找到一处自增逻辑,那么我们可以利用frida去修改这里的汇编来使我们的金币获取更快。
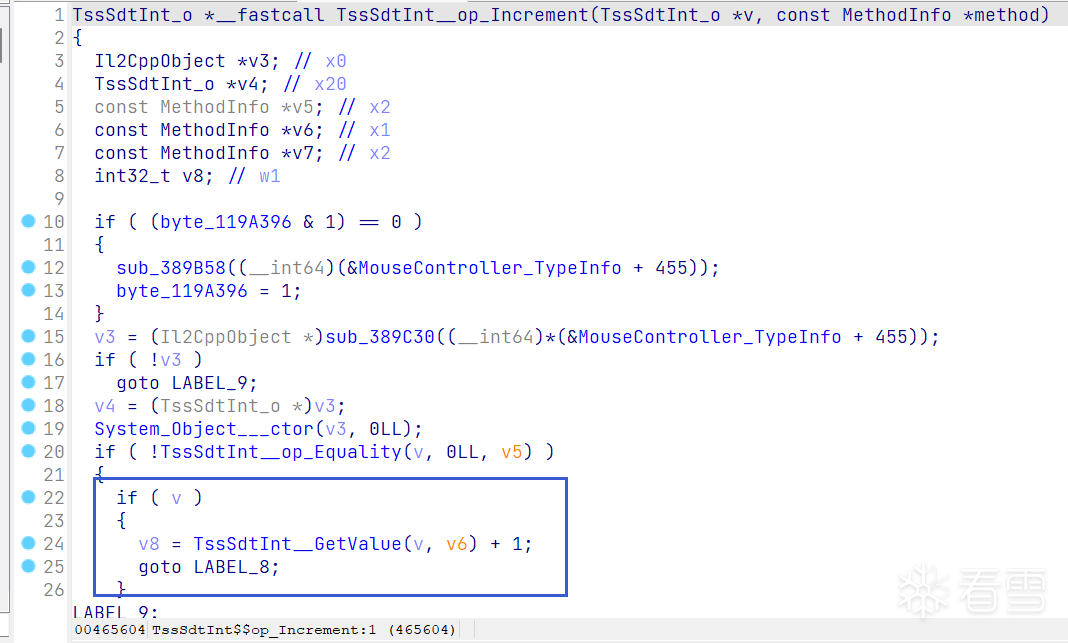
function PatchIncrease() {
var libil2cpp = TraverseModules('single', {name: 'libil2cpp.so'});
var insn = libil2cpp.base.add(0x465674);
console.log('[+] Patching..');
Memory.protect(insn, 4, 'rwx');
insn.writeByteArray([0x01, 0xA0, 0x0F, 0x11]);
}
重新启动游戏,随便吃几粒金币,即可获取flag。
分析IL2CPP
题目要求实现外挂的注册机,在dnspy中找到SmallKeyboard类,可以分析到输入的小键盘一些相关字段和方法。
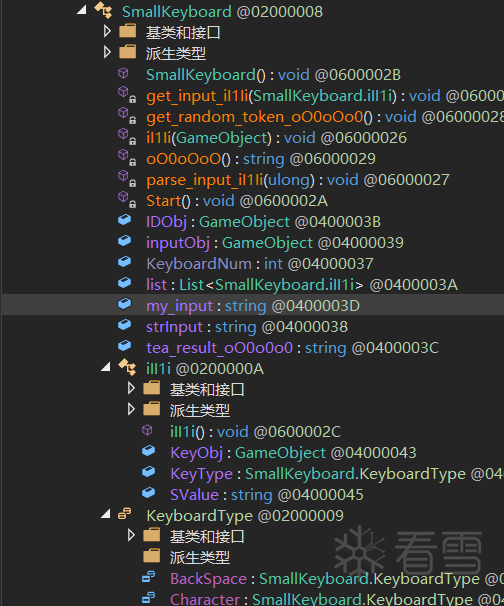
在IDA中跟进get_input_il1li函数,可以发现是一个判断按键类型进入不同函数的逻辑。
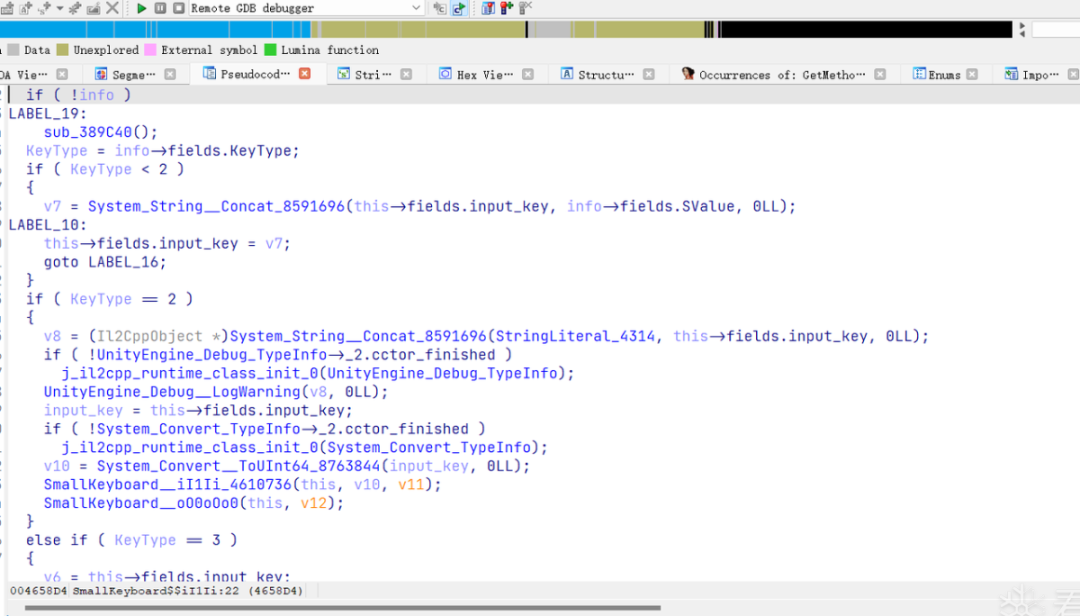
结合frida辅助分析可以知道,当KeyType<2时为数字输入,当KeyType=2时为确认,触发关键逻辑。
分析SmallKeyboard__iI1Ii_4610736函数
其中SmallKeyboard__iI1Ii_4610736为关键函数,将我们输入的key转为UInt64类型传入,跟进可以发现有一处跳转会跳到g_sec2023_p_array中的一个函数,此处我已经patch(为了IDA能正常反编译该函数)。
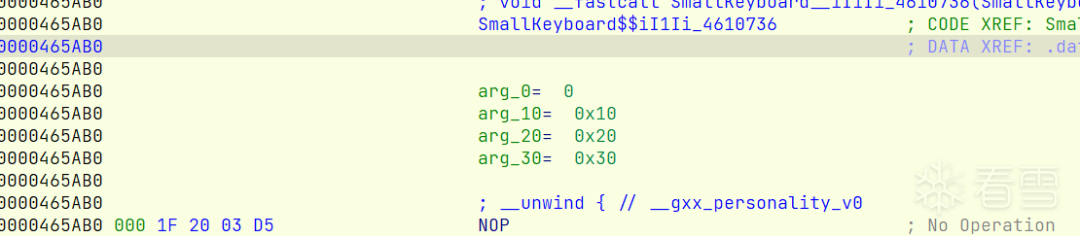
使用frida hook首部的跳转指令(此处已经是patch成NOP)后一条指令,可以发现我们输入的key发生了变化。
function HookSmallKeyboard$$parse_input_iI1Ii_4610736() {
var libil2cpp = TraverseModules('single', {name: 'libil2cpp.so'});
var HookSmallKeyboard$$parse_input_iI1Ii_4610736 =
libil2cpp.base.add(0x465AB4);
Interceptor.attach(HookSmallKeyboard$$parse_input_iI1Ii_4610736, {
onEnter: function(args) {
PrintNativeBackTraceFuzzy(this.context, TraverseModules('all', {}));
console.log('[+] HookSmallKeyboard$$parse_input_iI1Ii_4610736 called');
console.log('input_key: ', args[1]);
Dump_g_sec2023_o_array();
}
});
}
// 假设输入了1111,则key会变成0x7d8174410d817fa
// [+] HookSmallKeyboard$$parse_input_iI1Ii_4610736 called
// input_key: 0x7d8174410d817fa
该函数中,我们可以找到一个XTEA加密算法,通过frida hook我们可以获取到key。
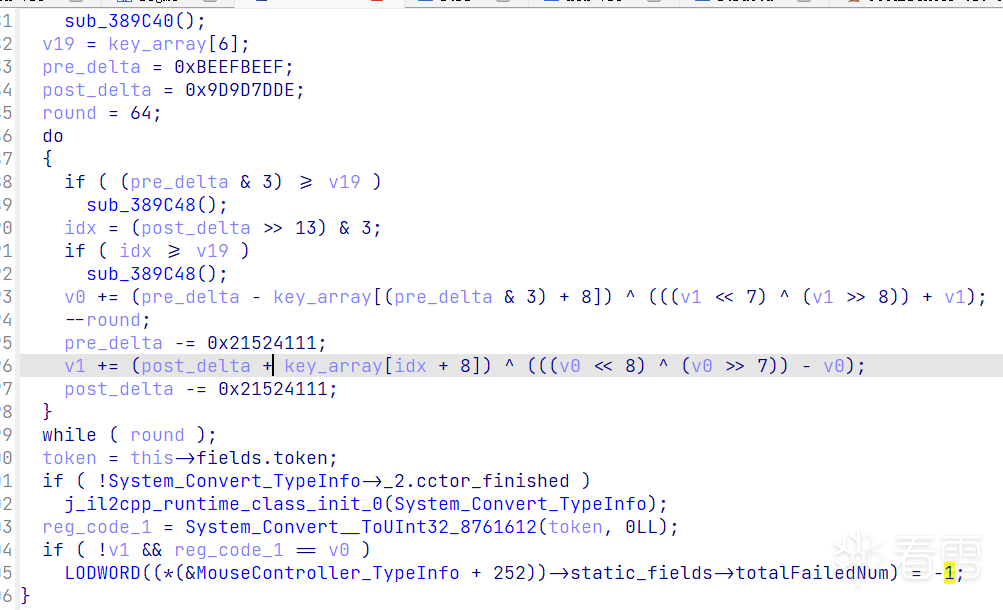
function get_reg_code() {
var libil2cpp = TraverseModules('single', {name: 'libil2cpp.so'});
var ctor = libil2cpp.base.add(0x4660E8);
Interceptor.attach(ctor, {
onEnter: function(args) {
console.log('[+] vm ctor called');
console.log('ipt_enc_high: ', this.context.x22);
},
onLeave: function(retval) {
console.log('[+] vm ctor returned');
}
});
var loc_465D34 = libil2cpp.base.add(0x465D34);
Interceptor.attach(loc_465D34, {
onEnter: function(args) {
console.log('[+] get_reg_code called');
console.log('key_array: ', parseSystemArrayObjectU32(this.context.x20));
console.log('ipt_enc_high: ', this.context.x22);
console.log('ipt_enc_low: ', this.context.x21);
console.log('reg_code_i32: ', this.context.x0);
}
});
}
下面是对该加密算法的实现,经过frida对输入输出进行验证,是正确的。
uint32_t key[4] = {0x7B777C63, 0xC56F6BF2, 0x2B670130, 0x76ABD7FE};
void EncryptXTEA(uint32_t *msg, uint32_t *key, ssize_t round) {
uint32_t v0 = msg[0], v1 = msg[1];
uint32_t delta = DELTA, sum = 0xBEEFBEEF;
for (ssize_t idx = 0; idx < round; idx++) {
v0 += (((v1 << 7) ^ (v1 >> 8)) + v1) ^ (sum - key[sum & 3]);
sum += delta;
v1 += (((v0 << 8) ^ (v0 >> 7)) - v0) ^ (sum + key[(sum >> 13) & 3]);
}
msg[0] = v0;
msg[1] = v1;
}
分析libsec2023.so中g_sec2023_p_array的函数
上面的情况说明跳转到的那个地方有对input进行加密的函数,打开libsec2023.so跟进那个函数分析,其中v5函数指针调用的是一个打log的函数,不用理会。主要是sub_3B8CC。
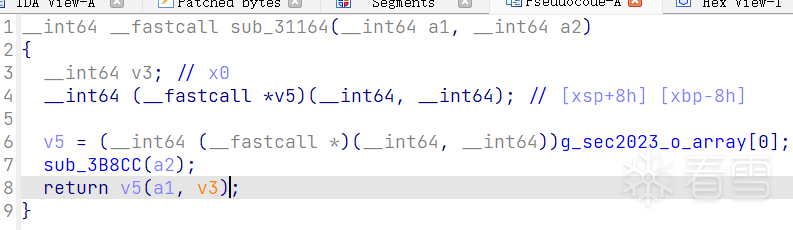
跟进可以发现函数被混淆了,因为分支跳转指令利用寄存器寻址。
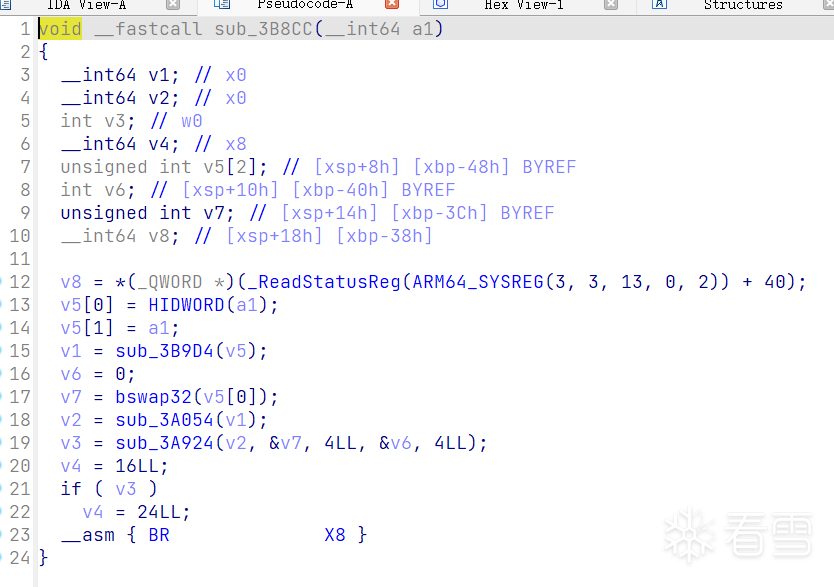
分析混淆机制以及使用Unicorn去混淆
分析可以发现,是将常规的分支、直接跳转改为用寄存器寻址跳转,寄存器中的跳转地址由一个常数+一个偏移来得到,常数和取偏移的基址在一个函数中是固定的,在跳转前,使用条件选择指令等来获取相应的偏移,从而间接实现分支跳转。

现在的情况是,我没有去干掉壳的反调试,因此没办法调试libsec2023.so,而这个壳frida也hook不上。但我又不想费力去手动patch掉所有混淆的汇编指令,此时的最佳选择显然是利用模拟执行相关的工具去帮我们完成。
去混淆脚本
通过脚本+人工半自动分析,可以很快的去除掉所有需要去除的花指令。
from emu_utils import *
from unicorn import *
from unicorn.arm64_const import *
# from ida_bytes import *
def trace_back_insn_with_target(insn_queue, target_reg):
for insn in insn_queue:
if (target_reg in insn.op_str):
if (insn.mnemonic == 'add'):
print(insn.mnemonic + '\t' + insn.op_str)
if (insn.mnemonic == 'ldr'):
print(insn.mnemonic + '\t' + insn.op_str)
if (insn.mnemonic == 'csel'):
print(insn.mnemonic + '\t' + insn.op_str)
def log_hook(emu, addr, size, user_data):
disasm = get_disasm(emu, addr, size)
print(hex(addr) + '\t' + disasm.mnemonic + '\t' + disasm.op_str)
def step_over_hook(emu, addr, size, none):
disasm = get_disasm(emu, addr, size)
if (disasm.mnemonic == 'bl' or disasm.mnemonic == 'blr'):
emu.reg_write(UC_ARM64_REG_PC, addr + size)
if (disasm.mnemonic == 'ret'):
print('function returned')
emu.emu_stop()
if (addr == 0x3ac68):
emu.reg_write(UC_ARM64_REG_W10, 0xEECF7326)
def normal_hook(emu, addr, size, insn_queue):
global const_value, offset_value, cond, cond_value, uncond_value
disasm = get_disasm(emu, addr, size)
reg_maps = get_reg_maps()
insn_queue.insert(0, disasm)
if (len(insn_queue) > 8):
insn_queue.pop()
if (disasm.mnemonic == 'csel'):
cond_value = emu.reg_read(reg_maps[disasm.op_str.split(', ')[1]])
uncond_value = emu.reg_read(reg_maps[disasm.op_str.split(', ')[2]])
cond = disasm.op_str.split(', ')[3]
if (disasm.mnemonic == 'cset'):
cond_value = 1
uncond_value = 0
cond = disasm.op_str.split(', ')[1]
if (disasm.mnemonic == 'ldr'):
if (len(disasm.op_str.split(', ')) == 3):
offset_value = emu.reg_read(
reg_maps[disasm.op_str.split(', ')[1].split('[')[1]])
elif (len(disasm.op_str.split(', ')) == 4):
offset_value = emu.reg_read(
reg_maps[disasm.op_str.split(', ')[1].split('[')[1]])
cond_value *= 8
if (disasm.mnemonic == 'add' and '#' not in disasm.op_str and 'w' not in disasm.op_str):
const_value = emu.reg_read(reg_maps[disasm.op_str.split(', ')[2]])
if (disasm.mnemonic == 'br'):
print('on br insn')
target_reg = disasm.op_str
trace_back_insn_with_target(insn_queue, target_reg)
print(hex(const_value), hex(offset_value),
cond, cond_value, uncond_value)
cond_addr = emu.mem_read(offset_value + cond_value, 4)
cond_addr = (int.from_bytes(
cond_addr, byteorder='little') + const_value) & 0xffffffff
uncond_addr = emu.mem_read(offset_value + uncond_value, 4)
uncond_addr = (int.from_bytes(
uncond_addr, byteorder='little') + const_value) & 0xffffffff
patch_asm = b''
patch_asm += get_asm('b' + cond + ' ' + hex(cond_addr), addr - 4)
patch_asm += get_asm('b ' + hex(uncond_addr), addr)
# patch_bytes(addr - 4, patch_asm)
emu.reg_write(UC_ARM64_REG_PC, addr + size)
def emulate_execution(filename, start_addr, hook_func, user_data):
emu = Uc(UC_ARCH_ARM64, UC_MODE_LITTLE_ENDIAN)
textSec = get_section(filename, '.text')
dataSec = get_section(filename, '.data')
textSec_entry = textSec.header['sh_addr']
textSec_size = textSec.header['sh_size']
textSec_raw = textSec.header['sh_offset']
TEXT_BASE = textSec_entry >> 12 << 12
TEXT_SIZE = (textSec_size + 0x1000) >> 12 << 12
TEXT_RBASE = textSec_raw >> 12 << 12
dataSec_entry = dataSec.header['sh_addr']
dataSec_size = dataSec.header['sh_size']
dataSec_raw = dataSec.header['sh_offset']
DATA_BASE = dataSec_entry >> 12 << 12
DATA_SIZE = (dataSec_size + 0x1000) >> 12 << 12
DATA_RBASE = dataSec_raw >> 12 << 12
VOID_1_BASE = 0x00000000
VOID_1_SIZE = TEXT_BASE
VOID_2_BASE = TEXT_BASE + TEXT_SIZE
VOID_2_SIZE = DATA_BASE - VOID_2_BASE
STACK_BASE = DATA_BASE + DATA_SIZE
STACK_SIZE = 0xFFFFFFFF - STACK_BASE >> 12 << 12
emu.mem_map(VOID_1_BASE, VOID_1_SIZE)
emu.mem_map(TEXT_BASE, TEXT_SIZE)
emu.mem_map(DATA_BASE, DATA_SIZE)
emu.mem_map(VOID_2_BASE, VOID_2_SIZE)
emu.mem_map(STACK_BASE, STACK_SIZE)
emu.mem_write(TEXT_BASE, read(filename)[TEXT_RBASE:TEXT_RBASE+TEXT_SIZE])
emu.mem_write(DATA_BASE, read(filename)[DATA_RBASE:DATA_RBASE+DATA_SIZE])
emu.reg_write(UC_ARM64_REG_FP, STACK_BASE + 0x1000)
emu.reg_write(UC_ARM64_REG_SP, STACK_BASE + STACK_SIZE // 2)
emu.hook_add(UC_HOOK_CODE, log_hook)
emu.hook_add(UC_HOOK_CODE, step_over_hook, user_data)
emu.hook_add(UC_HOOK_CODE, hook_func, user_data)
emu.emu_start(start_addr, 0x0)
if __name__ == '__main__':
filename = './libsec2023.so'
start_addr = 0x3ac68
insn_queue = []
emulate_execution(filename, start_addr, normal_hook, insn_queue)
分析加密函数
去混淆后即可分析函数,经过分析,可以知道是对input以4字节为一组分别进行加密。
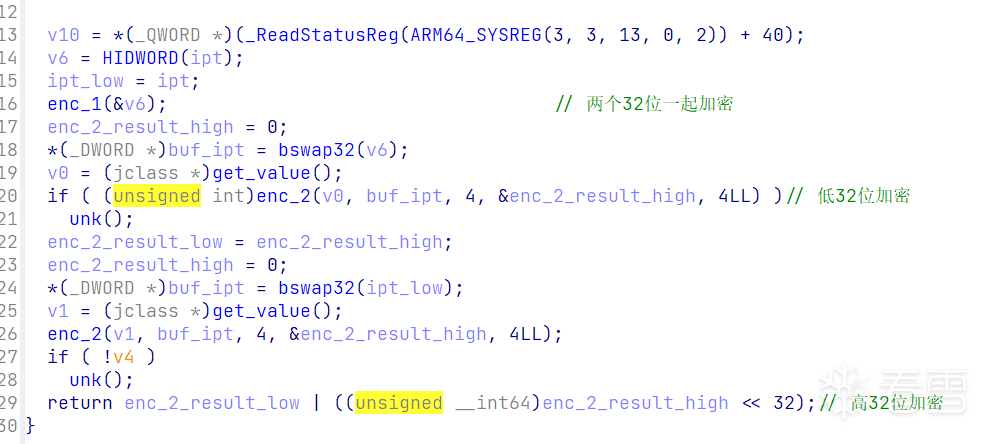
其中enc_1逻辑较为明显,显然是可逆的。
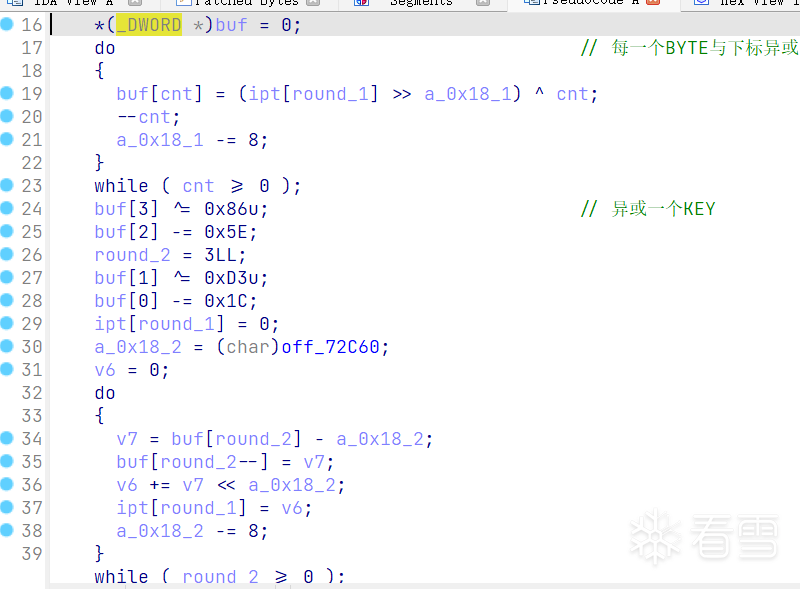
下面这个函数实现了上面的加密算法,经过frida验证输入输出是正确的。
void EncryptObfusedRoundI(uint32_t ipt[]) {
for (ssize_t idx = 0; idx < 2; ++idx) {
uint8_t buf[4] = {0}, tmp[4] = {0};
for (ssize_t i = 0; i < 4; i++) {
buf[i] = ((uint8_t *)&ipt[idx])[i] ^ i;
}
buf[3] ^= 0x86;
buf[2] -= 0x5E;
buf[1] ^= 0xD3;
buf[0] -= 0x1C;
for (ssize_t i = 0; i < 4; i++) {
tmp[i] = buf[i] - i * 8;
}
ipt[idx] = *(uint32_t *)&tmp;
}
}
而enc_2中调用了一个类中的方法,我们只知道这个方法叫什么,但是并不知道是哪个类下的方法,因此我们需要hook GetStaticMethodID这个JNI函数。
[圖片]
通过hook JNI函数找到调用解密函数的类
通过hook,我们可以知道调用的是Sec2023.Encrypt方法,但是JADX中并没有找到,不能直接分析。说明这个类是由壳动态加载的,因此我们需要找办法dump下来dex。
function HookGetStaticMethodID() {
var libart = TraverseModules('single', {name: 'libart.so'});
var GetStaticMethodID = libart.base.add(0x3A87B4);
Interceptor.attach(GetStaticMethodID, {
onEnter: function(args) {
var clazz = args[1];
var name = args[2].readUtf8String();
var sig = args[3].readUtf8String();
// get clazz name
var clazz_name = Java.vm.getEnv().getClassName(clazz);
console.log(`[*] GetStaticMethodID called: ${clazz_name} ${name} ${sig}`);
}
});
}
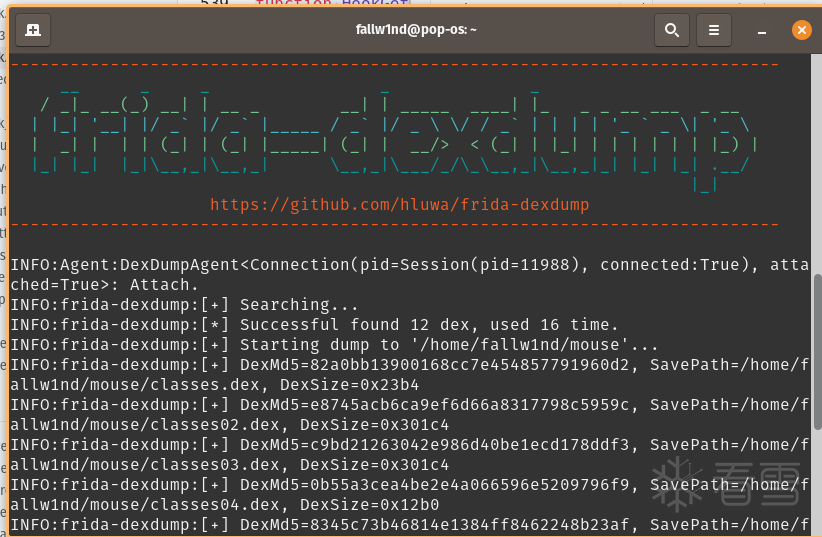
使用frida-dexdump获取壳加载的Dex && 分析Sec2023.Encrypt方法
通过这个工具我们可以很轻松地在内存里找到相关的dex,dump下来就可以接着分析了。
打开分析,可以发现加了BlackObfuscator,而我并没有现成的解决方案可以参考和使用,那就只能推理和猜猜看了。
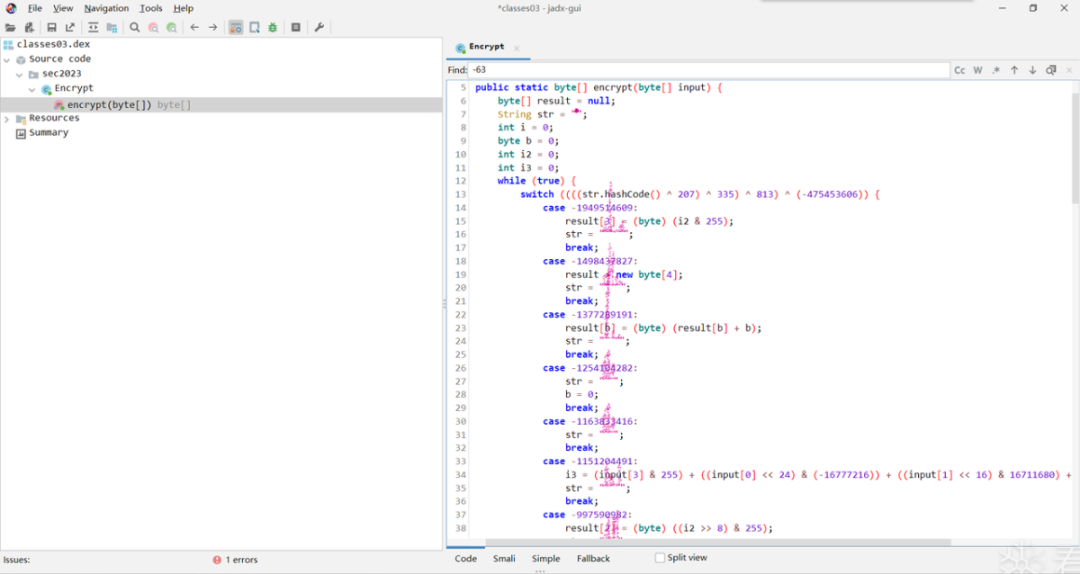
分析被BlackObfuscator混淆的算法
这里我用一种很简单粗暴的办法,就是把每个case中的真实指令直接复制出来,然后可以发现变量之间的运算有明显的逻辑关系,经过推理和结合frida分析验证(上面的frida脚本log了加密完的key),可以推理出正确的加密算法。
uint32_t EncryptObfusedRoundII(uint32_t ipt) {
uint32_t n1 = 0, n2 = 0;
uint8_t result[4] = {0}, *buf = (uint8_t *)&ipt;
uint8_t key[8] = {0x32, 0xCD, 0xFF, 0x98, 0x19, 0xB2, 0x7C, 0x9A};
n1 = __builtin_bswap32(*(uint32_t *)buf);
n2 = (n1 >> 7) | (n1 << 25);
*(uint32_t *)result = __builtin_bswap32(n2);
for (int idx = 0; idx < 8; idx++) {
result[idx] = (result[idx] ^ key[idx % 8]);
result[idx] = (result[idx] + idx);
}
return *(uint32_t *)result;
}
使用frida分析VM && 使用frida解释VM
分析完上面提到的算法之后,我们可以在此处找到一个函数的调用,它改变了input的值,所以应为加密算法。
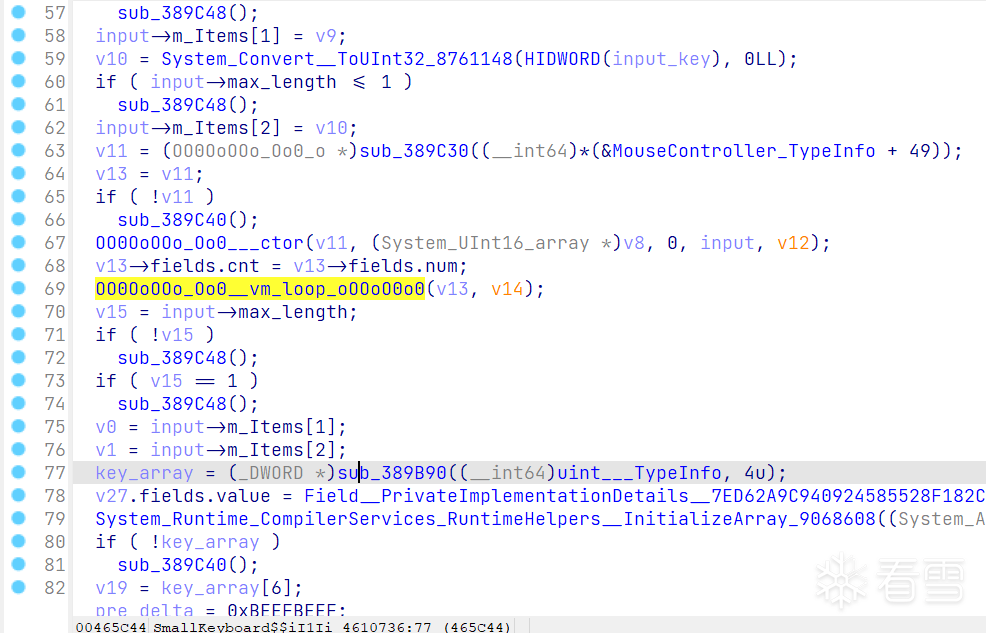
对这两个类进行分析,可以知道上面那个类中的都是opcode dict的key,下面那个类是VM的Handler和一些相关的字段。
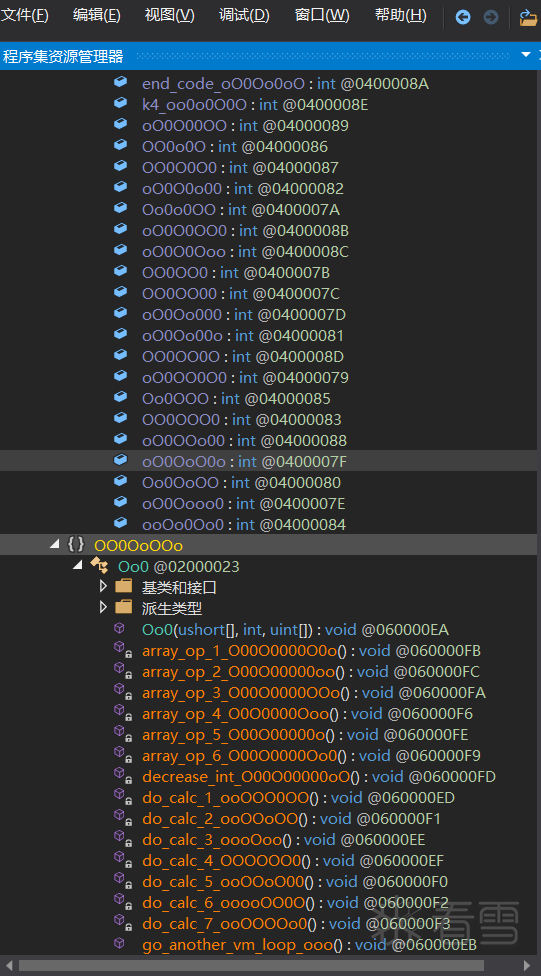
VM直接分析不好分析,我们需要侧面去分析。两种常用的方法:一是把指令数组和handler自己实现在程序外部自行分析,二是直接hook来分析。这里选择直接hook通过打log来还原VM逻辑。
首先需要解析VM类的this指针。
function ParseVMClazz(thiz) {
var fields = thiz.add(0x10);
var opcode = fields.add(0x00);
var input = fields.add(0x08);
var buf = fields.add(0x10);
var x = fields.add(0x18);
var cnt = fields.add(0x1C)
var maybe_idx = fields.add(0x20);
var num = fields.add(0x24);
var opdict = fields.add(0x28);
var vm_context = {
opcode: opcode.readPointer(),
input: input.readPointer(),
buf: buf.readPointer(),
x: x.readS32(),
cnt: cnt.readS32(),
maybe_idx: maybe_idx.readS32(),
num: num.readS32(),
opdict: opdict.readPointer(),
};
return vm_context;
}
然后通过手动hook一个个handler来实现VM解释器。
function VMparser() {
var libil2cpp = TraverseModules('single', {name: 'libil2cpp.so'});
var array_op_1_O00O0000O0o = libil2cpp.base.add(0x46B480);
Interceptor.attach(array_op_1_O00O0000O0o, {
onEnter: function(args) {
var x = ParseVMClazz(args[0]).x;
// console.log('[*] array_op_1_O00O0000O0o called');
console.log(` input[buf${x}] = buf${x - 1};`);
}
});
var array_op_2_O00O00000oo = libil2cpp.base.add(0x46B4E8);
Interceptor.attach(array_op_2_O00O00000oo, {
onEnter: function(args) {
var x = ParseVMClazz(args[0]).x;
var opcode = ParseVMClazz(args[0]).opcode.add(32);
var cnt = ParseVMClazz(args[0]).cnt;
// console.log('[*] array_op_2_O00O00000oo called');
console.log(` input[${opcode.add(cnt * 2).readU16()}] = buf${x};`);
}
});
var array_op_3_O00O0000OO = libil2cpp.base.add(0x46B3F8);
Interceptor.attach(array_op_3_O00O0000OO, {
onEnter: function(args) {
var x = ParseVMClazz(args[0]).x;
var opcode = ParseVMClazz(args[0]).opcode.add(32);
var cnt = ParseVMClazz(args[0]).cnt;
// console.log('[*] array_op_3_O00O0000OO called');
console.log(` buf${x + 1} = input[${opcode.add(cnt * 2).readU16()}];`);
}
});
var array_op_4_O0O0000Ooo = libil2cpp.base.add(0x46B28C);
Interceptor.attach(array_op_4_O0O0000Ooo, {
onEnter: function(args) {
var opcode = ParseVMClazz(args[0]).opcode.add(32);
var cnt = ParseVMClazz(args[0]).cnt;
// console.log('[*] array_op_4_O0O0000Ooo called');
console.log(` cnt = ${opcode.add(cnt * 2).readU16()};`);
}
});
.....
...
}
随便输入一个字符串,点击确认按钮,我们就可以得到一个输出的形式为C代码的VM逻辑。
输出如下,因为后面我放到直接把他作为加密函数来验证VM逻辑是否dump正确,所以有一些改动。
register uint32_t buf0, buf1, buf2, buf3, buf4, buf5, cnt;
uint32_t input[8] = {0};
input[0] = ipt[0];
input[1] = ipt[1];
buf0 = 24;
input[2] = buf0;
buf0 = input[0];
buf1 = input[2];
buf0 = ((~(buf0 + 0x100) | 0xFFFFFEFF) + 2 * buf0 +
(~(buf0 + 0x100) & 0xFFFFFEFF) + 0x202) >>
buf1;
buf1 = 255;
buf0 = (buf1 + (buf1 ^ ~buf0) + (~buf0 & ~buf1) + (buf0 & ~buf1) + 1) & buf0;
buf1 = input[2];
buf2 = 8;
buf1 = buf1 - buf2 + (buf1 ^ buf2) + (buf1 & buf2) - (buf1 | buf2);
input[2] = buf1;
buf1 = input[2];
buf2 = 0;
buf1 = buf1 < buf2;
if (buf1) {
cnt = 26;
} else {
cnt = 4;
}
.....
...
由于我们上面其他加密算法都已经找到了,再加上这个,我们可以对输入输出做完整的验证。经过frida hook输入输出可以知道dump下来的VM逻辑没问题。至此,最后一个问题就是如何去得到这个算法的逆算法。
重编译VM指令,恢复算法逻辑
对于这种VM,我们可以直接重新开优化编译,并把其中的一些变量用register关键字定义为寄存器变量,这样IDA的反编译效果会有极大的提升。
重新编译后,IDA反编译出的算法逻辑如下,总共一百多行,不多也不少。难就难在有指令替换。打算直接动调猜每一条指令的作用(因为变量不会被重复赋值,指令也并没有像原本VM这种难以接受的分析,所以我觉得这是可行的)。
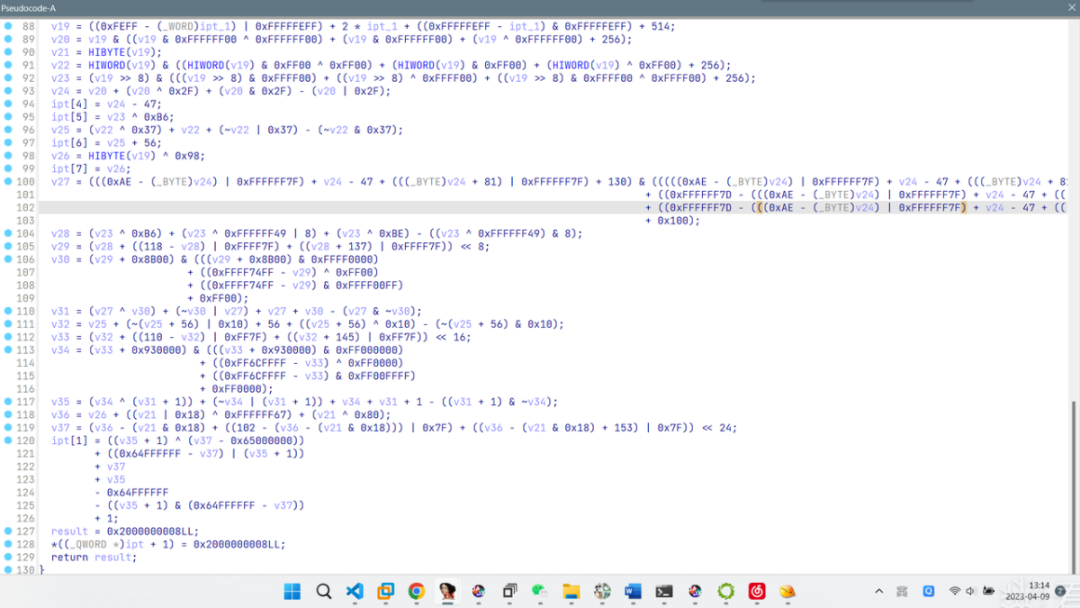
四、梳理加密过程,开整注册机
题目要求对于任意TOKEN,我们的注册机都能生成一个KEY来注册外挂。那就意味着随机生成的TOKEN经过解密之后就是KEY。那注册机其实就是上述所有算法的解密算法实现。我们知道,首先执行的是壳内两个算法加密,然后是VM内的算法加密,最后是XTEA算法加密,那么注册机就是逆过来实现就完事了。
XTEA解密算法
void DecryptXTEA(uint32_t *msg, uint32_t *key, ssize_t round) {
uint32_t v0 = msg[0], v1 = msg[1];
uint32_t delta = DELTA, sum = 0xBEEFBEEF + delta * round;
for (ssize_t idx = 0; idx < round; idx++) {
v1 -= (((v0 << 8) ^ (v0 >> 7)) - v0) ^ (sum + key[(sum >> 13) & 3]);
sum -= delta;
v0 -= (((v1 << 7) ^ (v1 >> 8)) + v1) ^ (sum - key[sum & 3]);
}
msg[0] = v0;
msg[1] = v1;
}
VM解密算法
暂未实现
壳内第二个算法的解密算法
uint32_t DecryptObfusedRoundII(uint32_t enc) {
uint32_t n1 = 0, n2 = 0;
uint8_t result[4] = {0}, *buf = (uint8_t *)&enc;
uint8_t key[8] = {0x32, 0xCD, 0xFF, 0x98, 0x19, 0xB2, 0x7C, 0x9A};
for (int idx = 0; idx < 8; idx++) {
result[idx] = (buf[idx] - idx);
result[idx] = (result[idx] ^ key[idx % 8]);
}
n2 = __builtin_bswap32(*(uint32_t *)result);
n1 = (n2 << 7) | (n2 >> 25);
return __builtin_bswap32(n1);
}
壳内第一个算法的解密算法
void DecryptObfusedRoundI(uint32_t enc[]) {
for (ssize_t idx = 0; idx < 2; ++idx) {
uint8_t buf[4] = {0}, tmp[4] = {0};
*(uint32_t *)&tmp = enc[idx];
for (ssize_t i = 0; i < 4; i++) {
buf[i] = tmp[i] + i * 8;
}
buf[3] ^= 0x86;
buf[2] += 0x5E;
buf[1] ^= 0xD3;
buf[0] += 0x1C;
for (ssize_t i = 0; i < 4; i++) {
tmp[i] = buf[i] ^ i;
}
enc[idx] = *(uint32_t *)&tmp;
}
}
