一款APP外壳原理分析
文件格式的处理
010editor打开libDexHelper.so。
一眼假的section。
操作系统加载并不关心section,先直接删除掉,后面修复dynamic后再重新生成一份。

一眼假的dynamic。
dynamic除了vaddr,其他成员都是可以伪造欺骗的,因为操作系统也只关心dynamic的vaddr。
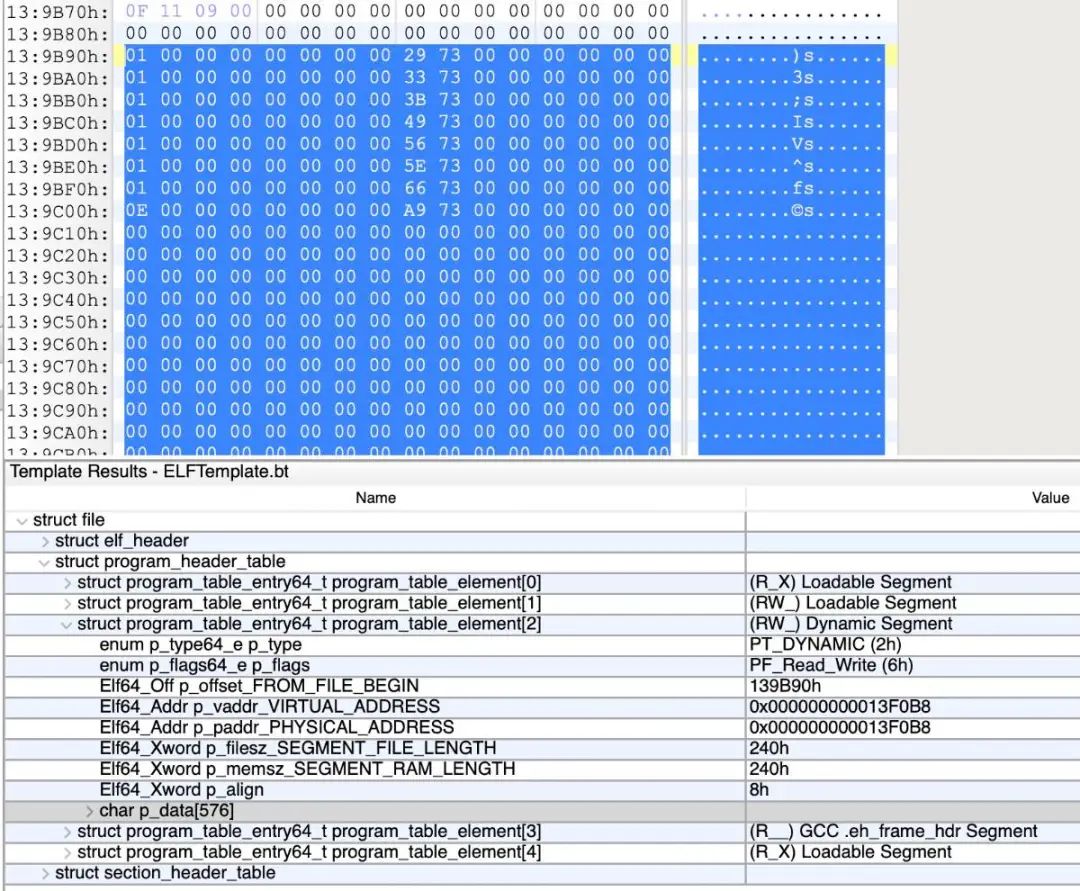
通过分析PT_LOAD的信息,即RVA和FA的转换,对dynamic的file_offset进行简单修复。
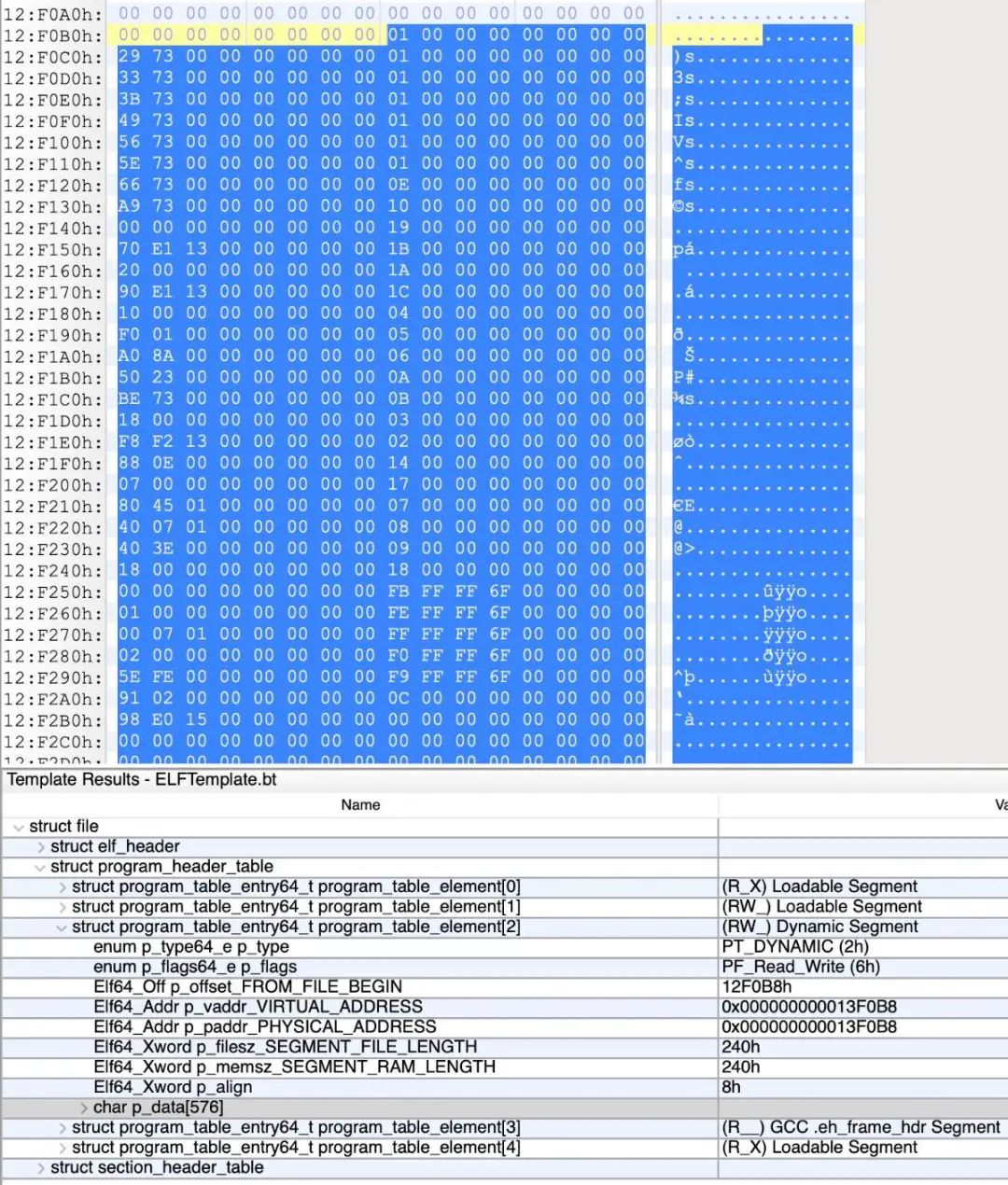
跑工具重新生成了一份section后,ida已经可以正常的解析so了。
so解密后dump
简单看了一下init_arrary和JNI_OnLoad方法,都是被加密的。
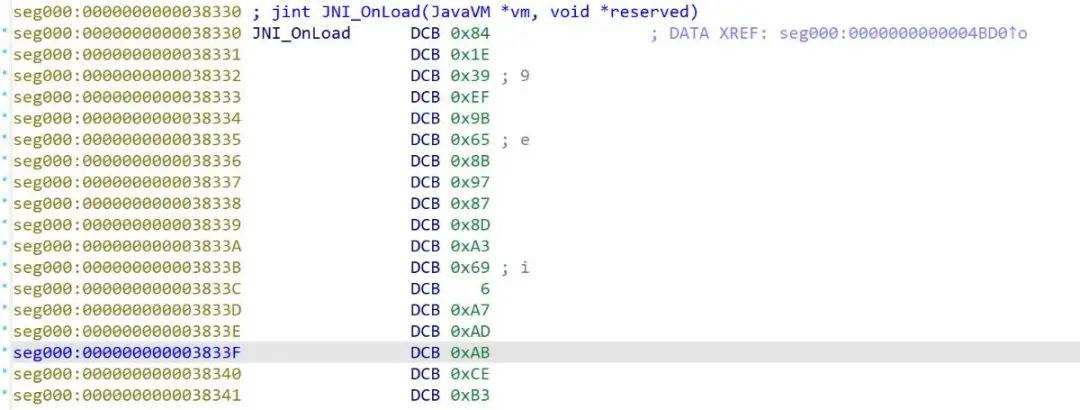
猜测解密方法在.init方法中。
暂时不去关心解密算法的实现,等.init方法运行结束后,直接dump内存,可以看到数据已经解密完成。
dump内存可以写ida脚本,也可以直接使用dd来dump(注意先要使用ida把app挂起,壳对/proc/self/mem的读写做了监控)。
混淆的简单处理
ida识别寄存器跳转失败。
类似于这样:
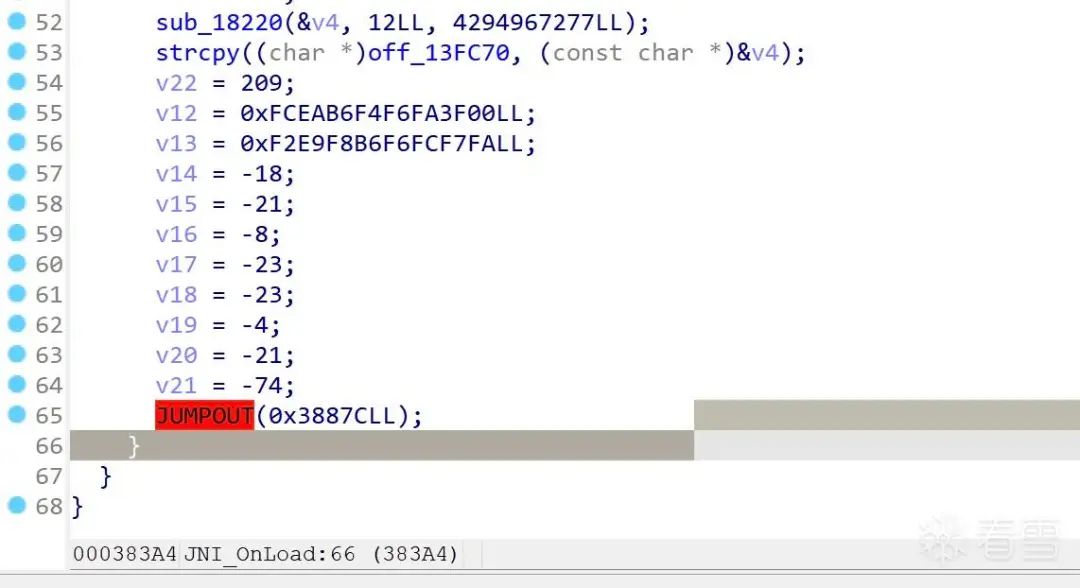
实际是ida对switch-case的识别失败。

解决办法就是帮助ida正确识别switch-case,具体可以参考这篇文章
正确修复后,ida也就能正常反编译了。

平坦化的处理
代码的正常流程被switch-case打乱了。
简单分析了一下汇编的代码结构,可以发现直接跳转到分发块的case块,会直接写死下一个要执行的case块。
于是可以通过计算获取到目标case块的地址,将case块跳回分发块,改成直接跳转到对应的case块的地址。
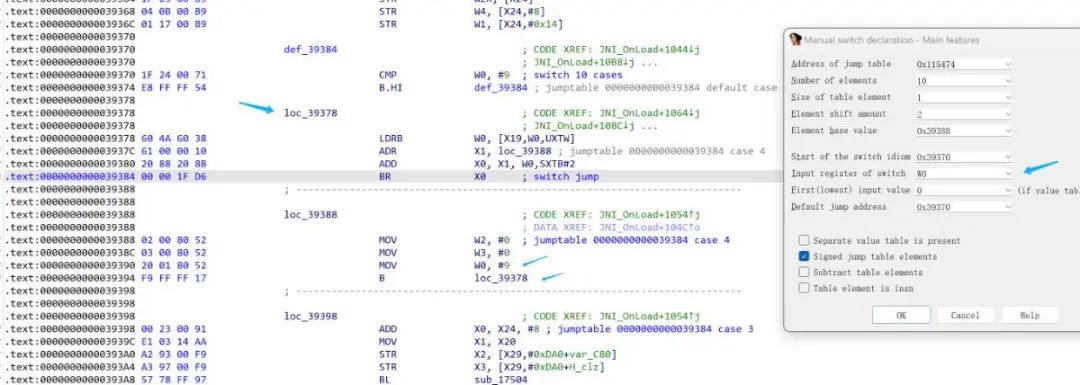
对于跳回def块的case块,则会通过条件执行来决定下一个要执行的case块。
同样可以计算出不同条件所要跳转的case块,将对应的跳转改为条件跳转。
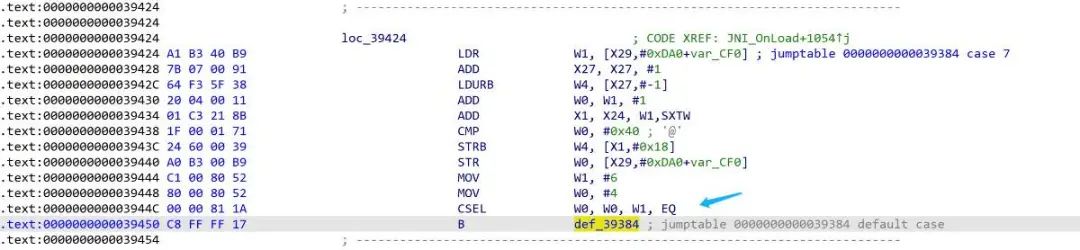
脚本还有待完善,有一些跳转的修改可能需要手动去修改。
import idautils
import idc
import idaapi
from keystone import *
ks = keystone.Ks(keystone.KS_ARCH_ARM64, keystone.KS_MODE_LITTLE_ENDIAN)
# 跳转表的信息,根据switch-case表修改
jump_table = 0x1154B4
element_sz = 2
element_base = 0x3B348
element_shift = 2
# def块 和 分发块,根据switch-case表修改
def_block = 0x3B330
jump_block = 0x3B338
def_init_block = -1
# input reg switch,根据switch-case表修改
reg_base = 129
reg_switch = reg_base + 0
# 当前处理的函数,根据switch-case表修改
func_addr = 0x38330
f_blocks = idaapi.FlowChart(idaapi.get_func(func_addr), flags=idaapi.FC_PREDS)
def get_code_refs_to_list(ea):
result = list(idautils.CodeRefsTo(ea, True))
return result
def get_block(addr, f_blocks):
for block in f_blocks:
if block.start_ea <= addr and addr <= block.end_ea - 4:
return block
return None
def get_next_case(start_ea, end_ea):
next_case = -1
ea = start_ea
while ea < end_ea:
mnem = idc.ida_ua.ua_mnem(ea)
if mnem == 'MOV':
op1 = idc.get_operand_value(ea, 0)
op2 = idc.get_operand_value(ea, 1)
op2_type = idc.get_operand_type(ea, 1)
if op1 == reg_switch and op2_type == idc.o_imm:
next_case = op2
ea = ea + 4
return next_case
def get_cond(ea):
cond = None
disasm = idc.GetDisasm(ea)
if disasm.find('LT') != -1:
cond = 'blt'
elif disasm.find('EQ') != -1:
cond = 'beq'
elif disasm.find('CC') != -1:
cond = 'bcc'
elif disasm.find('GT') != -1:
cond = 'bgt'
elif disasm.find('NE') != -1:
cond = 'bne'
elif disasm.find('GE') != -1:
cond = 'bge'
elif disasm.find('HI') != -1:
cond = 'bhi'
elif disasm.find('LE') != -1:
cond = 'ble'
else:
print('unknow cond:0x%x' % ea)
return cond
def get_cond_next_case(start_ea, end_ea):
cond_case = -1
uncond_case = -1
cond_reg = idc.get_operand_value(end_ea - 8, 1)
uncond_reg = idc.get_operand_value(end_ea - 8, 2)
ea = start_ea
while ea < end_ea:
mnem = idc.ida_ua.ua_mnem(ea)
if mnem == 'MOV':
op1 = idc.get_operand_value(ea, 0)
op2 = idc.get_operand_value(ea, 1)
op2_type = idc.get_operand_type(ea, 1)
if op1 == cond_reg and op2_type == idc.o_imm:
cond_case = op2
if op1 == uncond_reg and op2_type == idc.o_imm:
uncond_case = op2
ea = ea + 4
# 部分case值的初始化,在init块中,不在对应的case块
if cond_case == -1 or uncond_case == -1:
#print('def_init_block 0x%x' % def_init_block)
block = get_block(def_init_block, f_blocks)
ea = block.start_ea
end_ea = block.end_ea
cond_flag = False
uncond_flag = False
if cond_case == -1:
cond_flag = True
if uncond_case == -1:
uncond_flag = True
while ea < end_ea:
mnem = idc.ida_ua.ua_mnem(ea)
if mnem == 'MOV':
op1 = idc.get_operand_value(ea, 0)
op2 = idc.get_operand_value(ea, 1)
op2_type = idc.get_operand_type(ea, 1)
if cond_flag:
if op1 == cond_reg and op2_type == idc.o_imm:
cond_case = op2
if uncond_flag:
if op1 == uncond_reg and op2_type == idc.o_imm:
uncond_case = op2
ea = ea + 4
if cond_reg == 160:
cond_case = 0
elif uncond_reg == 160:
uncond_case = 0
return cond_case, uncond_case
def do_patch(ea, opcode, src, dst):
jump_offset = " ({:d})".format(dst - src)
repair_opcode = opcode + jump_offset
#print(repair_opcode)
encoding, count = ks.asm(repair_opcode)
idaapi.patch_byte(ea, encoding[0])
idaapi.patch_byte(ea + 1, encoding[1])
idaapi.patch_byte(ea + 2, encoding[2])
idaapi.patch_byte(ea + 3, encoding[3])
jump_block_list = get_code_refs_to_list(jump_block)
jump_def_list = get_code_refs_to_list(def_block)
def hex_to_dec(hex_str):
#print(hex_str)
#print(hex_str[0])
# 把16进制字符串转成带符号10进制
if hex_str[0] in '0123456789':
dec_data = int(hex_str, 16)
else:
# 负数算法
width = 32 # 16进制数所占位数
d = 'FFFF' + hex_str
dec_data = int(d, 16)
if dec_data > 2 ** (width - 1) - 1:
dec_data = 2 ** width - dec_data
dec_data = 0 - dec_data
return dec_data
def do_B_block(addr, cond):
block = get_block(addr, f_blocks)
if block is None:
return
next_case = get_next_case(block.start_ea, block.end_ea)
if next_case == -1:
return
if element_sz == 1:
case_data = idc.get_wide_byte(jump_table + next_case)
if case_data > 0x7f:
case_data = hex_to_dec(hex(case_data)[2:])
jmp_off = case_data * (2 * element_shift)
jmp_addr = jmp_off + element_base
elif element_sz == 2:
case_data = idc.get_wide_word(jump_table + next_case * 2)
if case_data > 0x7fff:
case_data = hex_to_dec(hex(case_data)[2:])
jmp_off = case_data * (2 * element_shift)
jmp_addr = jmp_off + element_base
print('jump_block_list->addr: 0x%x, next_case: %d, jmp_addr: 0x%x' % (addr, next_case, jmp_addr))
if cond == 'cbnz':
reg_cmp = idc.get_operand_value(addr - 4, 0)
cond = "cbnz x{:d}, ".format(reg_cmp - reg_base)
elif cond == 'cbz':
reg_cmp = idc.get_operand_value(addr - 4, 0)
cond = "cbz x{:d}, ".format(reg_cmp - reg_base)
do_patch(addr, cond, addr, jmp_addr)
# 处理 jump_block
for addr in jump_block_list:
mnem = idc.ida_ua.ua_mnem(addr)
if mnem == 'B':
do_B_block(addr, 'b')
elif mnem == 'TBZ':
do_B_block(addr, 'b')
elif mnem == 'CBNZ':
do_B_block(addr, 'cbnz')
elif mnem == 'CBZ':
do_B_block(addr, 'cbz')
else:
print('unknow jump_block:0x%x' % addr)
def do_cond_block(addr, ins):
cond = get_cond(addr - 4)
if cond is None:
print('unkown cond 0x%x' % addr)
return
block = get_block(addr, f_blocks)
if block is None:
return
cond_case, uncond_case = get_cond_next_case(block.start_ea, block.end_ea)
if cond_case == -1 or uncond_case == -1:
return
if mnem == 'CSINC':
uncond_case = uncond_case + 1
cond_jmp_addr = -1
uncond_jmp_addr = -1
if element_sz == 1:
case_data = idc.get_wide_byte(jump_table + cond_case)
if case_data > 0x7f:
case_data = hex_to_dec(hex(case_data)[2:])
jmp_off = case_data * (2 * element_shift)
cond_jmp_addr = jmp_off + element_base
case_data = idc.get_wide_byte(jump_table + uncond_case)
if case_data > 0x7f:
case_data = hex_to_dec(hex(case_data)[2:])
jmp_off = case_data * (2 * element_shift)
uncond_jmp_addr = jmp_off + element_base
elif element_sz == 2:
case_data = idc.get_wide_word(jump_table + cond_case * 2)
if case_data > 0x7fff:
case_data = hex_to_dec(hex(case_data)[2:])
jmp_off = case_data * (2 * element_shift)
cond_jmp_addr = jmp_off + element_base
case_data = idc.get_wide_word(jump_table + uncond_case * 2)
if case_data > 0x7fff:
case_data = hex_to_dec(hex(case_data)[2:])
jmp_off = case_data * (2 * element_shift)
uncond_jmp_addr = jmp_off + element_base
print('jump_def_list->addr: 0x%x, cond_case: %d, cond_jmp_addr: 0x%x, uncond_case: %d, uncond_jmp_addr: 0x%x' %
(addr, cond_case, cond_jmp_addr, uncond_case, uncond_jmp_addr))
do_patch(addr - 4, cond, addr - 4, cond_jmp_addr)
do_patch(addr, 'b', addr, uncond_jmp_addr)
# 处理 def_block
for addr in jump_def_list:
#print('jump_def_list->addr: 0x%x' % addr)
if addr + 4 == def_block:
def_init_block = addr
# print('def_init_block 0x%x' % def_init_block)
continue
mnem = idc.ida_ua.ua_mnem(addr)
if mnem != 'B':
continue
mnem = idc.ida_ua.ua_mnem(addr - 4)
if mnem == 'CSEL':
do_cond_block(addr, 'CSEL')
elif mnem == 'CSINC':
do_cond_block(addr, 'CSINC')
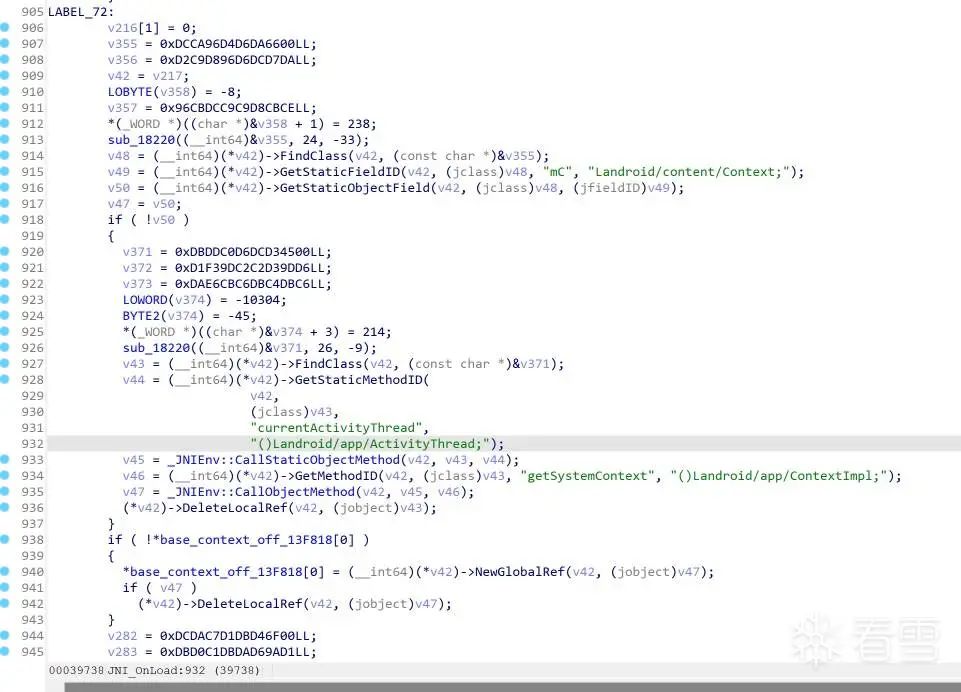
拿JNI_OnLoad做了简单的测试。
修改前:
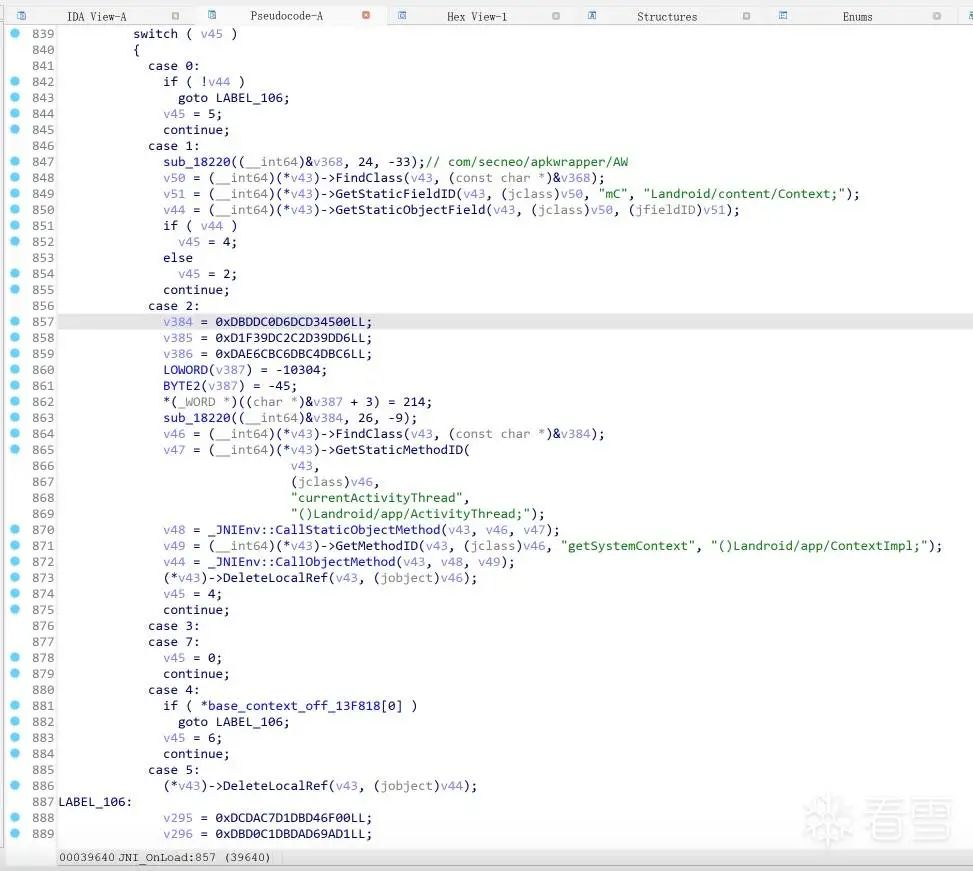
修改后:
frida检测分析
准备工作做完了,开始上frida。
意料之中,存在frida检测。
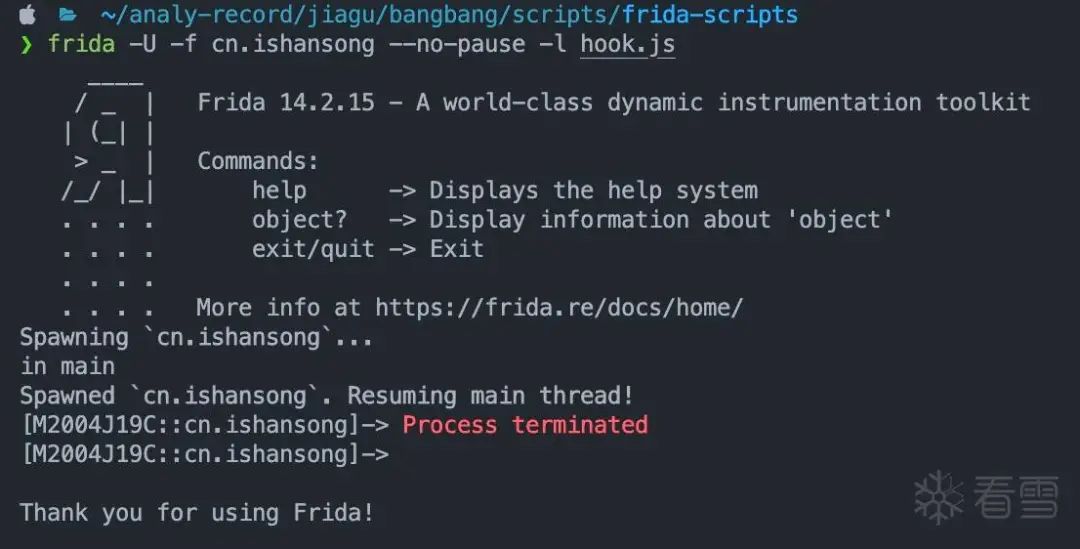
简单测试了一下:
◆单独启动了frida- server,不注入app进程,程序正常运行。
◆注入app进程,但不进行任何hook,程序闪退。
看来是对frida的基本特征做了检测。
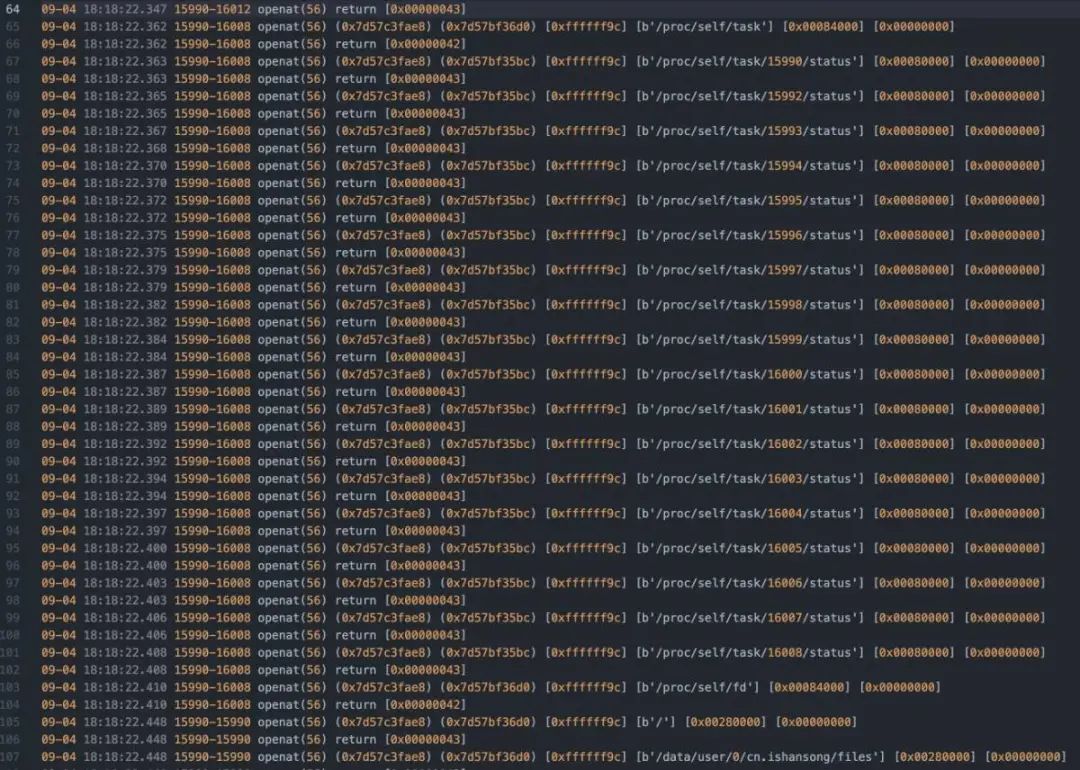
对openat进行hook。
/** * gum js 引擎的线程名字:Name: gum-js-loop * vala 引擎的线程名字:Name: gmain * dbus 线程名字:Name: gdbus * */
定位到检测代码的位置:

用的去特征的frida-server,不知道为啥gdbus的特征仍然存在。
对gdbus字符串的比较在sub_9DE68进行,简单的处理一下。
function pass_frida(){
var module = Process.findModuleByName("libDexHelper.so")
var base = module.base
var sub_9DE68 = base.add(0x9DE68)
Interceptor.attach(sub_9DE68, {
onEnter:function(args){
},
onLeave:function(ret){
if(ret != 0){
ret.replace(0)
}
}
})
}
除了通过hook svc调用来定位,还可以通过hookpthread_create来获取创建的所有线程来定位检测。
>>> hex(0x000000764F830C5C - 0x000000764F792000) '0x9ec5c' >>> hex(0x000000764F83C97C - 0x000000764F792000) '0xaa97c' >>> hex(0x000000764F82F73C - 0x000000764F792000) '0x9d73c' >>> hex(0x000000764F875FD0 - 0x000000764F792000) '0xe3fd0' >>> hex(0x000000764F82F030 - 0x000000764F792000) '0x9d030'
此时frida已经可以使用了。
继续测试,会发现对部分libc库函数(比如open)进行hook时,一样会被检测到。
猜测是存在代码的hash值校验,或比较了内存与文件中的代码是否一致。
ida调试检测分析
逆向分析时,肯定是少不了动态调试的,且遇到反调试肯定也是不可避免的。
首先也是通过对openat进行hook来定位检测。
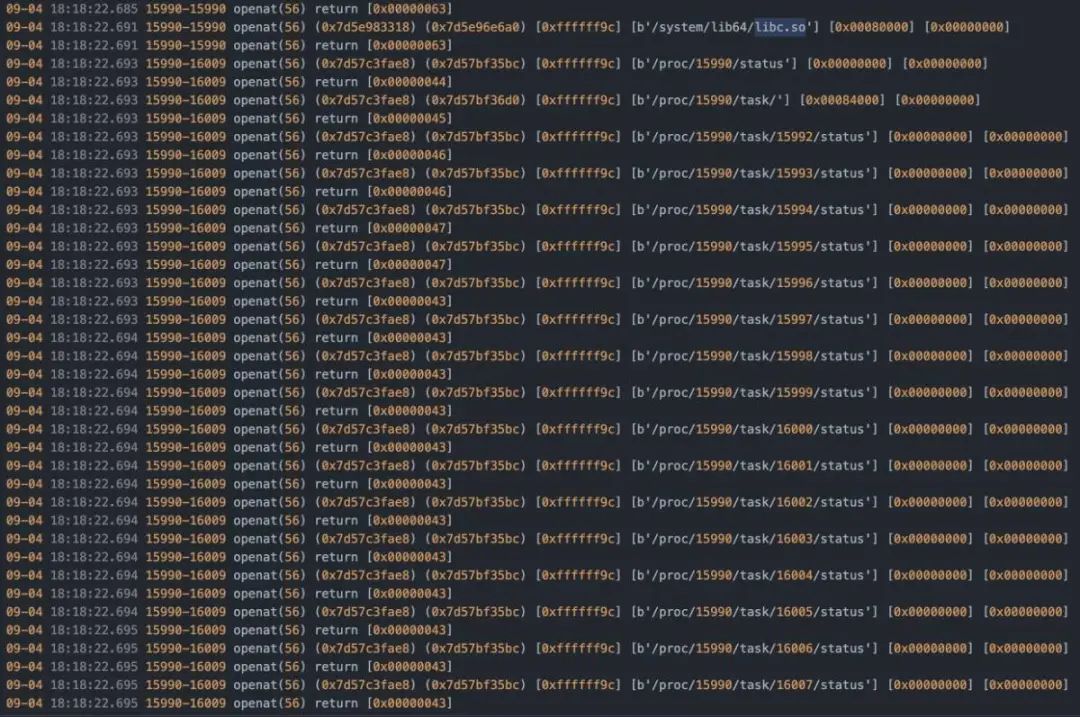
定位到线程0xaa97c。
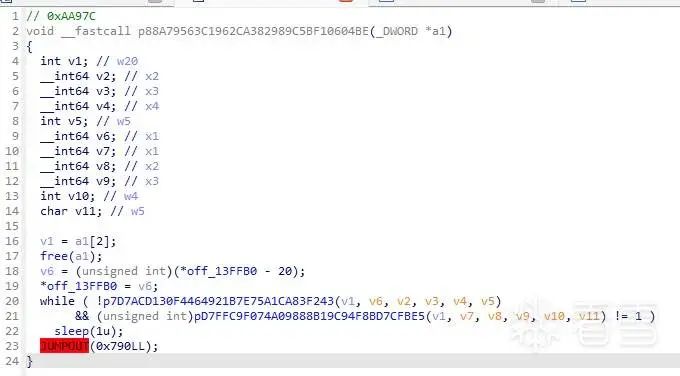
也是很常规的检测方式。

简单修改一下,JNI_OnLoad就可以正常调试了。
此时此刻,想要彻底攻克壳的保护,需要的就只剩下时间和耐心了。
