随着国内银行业数字化转型进程的加快,以及数据驱动战略在银行的落地实践,2019年中原银行围绕分布式数据仓库和大数据技术,以自主研发架构为主,构建了一套满足一站式数据集成、存储、整合、计算与开发的数据技术中台,解决了海量数据存储与分析的问题,并有效支撑了行内商业决策与各类应用规模化交付。近年来,全行数字化转型步入深水区,业务线上化、移动化和场景化比例越来越高,相应地也带来了数据规模爆发式增长和数据类型多样性等问题。
数据仓库作为中原银行主要的基础设施,我们围绕数据仓库建设的数据整合平台承接了行内大量的贴源、明细数据。3年间其存储的数据总量增加了2倍多,基于数据仓库架构的应用数量增长到60多个,数据仓库扩容已趋于常态化,数据存储成本占全行信息科技预算的比例也越来越高。
同时,以RPA、人机交互、知识图谱等为主的人工智能技术对半结构、非结构数据的存储、特征提取以及数据加工提出了新的要求,单一的数据仓库技术已无法应对上述的挑战。
行业湖仓一体的建设方案
2020年下半年,我们开始探索解决方案,数据湖进入了我们的视线。通过对比,我们发现数据湖和数据仓库作为大数据体系架构下两条不同的技术演进路线,具有各自的优势和局限性。具体表现在以下几个方面。
一是在数据处理和存储能力方面,数据湖支持结构化、半结构化、非结构化数据的存储与加工,而数据仓库基本上只支持结构化数据。
二是数据仓库在处理数据之前要先进行数据梳理、定义数据结构后才可以进行入库操作,而数据湖按照原样存储数据,无需事先对数据进行结构化处理,这也造成数据湖缺乏像数据仓库的数据管理能力,数据质量较差。
三是数据湖在灵活性上具备天然优势,开源大数据引擎只需遵循相对宽松的兼容协议就能够读写数据湖中的数据;而数据仓库只对特定引擎开放,并作了深度定制优化,进而换取更高的存储与计算性能。

不难看出,数据湖与数据仓库两者虽然能力互补但却很难直接合并成一套系统。有没有一种更好地架构可以将二者的能力相互统一?Gartner在2011年提出逻辑数据仓库的概念,推测企业数据分析将会转向一种更加逻辑化的架构,实现逻辑统一物理分开的协同体系。
借助逻辑数据仓库的架构理念,各大云厂商陆续推出自己的“湖仓一体”技术方案,采用湖仓协同工作的方式,将数据湖、数据仓库与数据类服务连接成为一个整体,数据在其间按需自由移动,以逻辑统一的方式为用户提供服务。
融合数据湖建设思路
数据显示,2021中国数据库市场行业分布,金融占20.2%,政府占18.4%,互联网14.8%,运营商8.9%。毫无疑问,以银行为代表的金融行业仍然是数据库销售额占比最高的市场,也是对数据库技术依赖度最高、要求最严格的市场。
数据仓库作为数据库技术在大数据时代的一种产品形态,其安全稳定、高效易用和完善而精细的数据管理能力完美地满足了金融行业对海量数据的分析需求。
因此在金融行业依然对数据仓库依赖较重的前提下,如何更好地兼容企业数据技术中台建设的历史现状,同时将数据湖的低成本、灵活性与数据仓库的企业级能力有机结合,成了我们数据技术中台下一步建设的重点。
通过对各主流云厂商有关“湖仓一体”架构方案的深入研究与学习,我们逐步明确了自己的融合数据湖的建设思路:
一是在数据仓库已经建设完善的前提下,数据湖可以作为数据仓库的补充,位于数据仓库的后端,主要用于卸载数据仓库的部分重载,如历史数据的存储与查询;
二是数据湖扩展其他场景下的数据探索与AI分析能力,原有数据仓库对外服务保持不变,依然以整合层、集市层、应用层批处理任务加工和报表查询等应用场景为主;
三是在逻辑层面,采用湖仓任务一体化开发、元数据统一管理以及联邦查询等技术将数据湖、数据仓库与数据类服务连接成为一个整体,满足用户的一体化使用需求。
融合数据湖方案总体架构
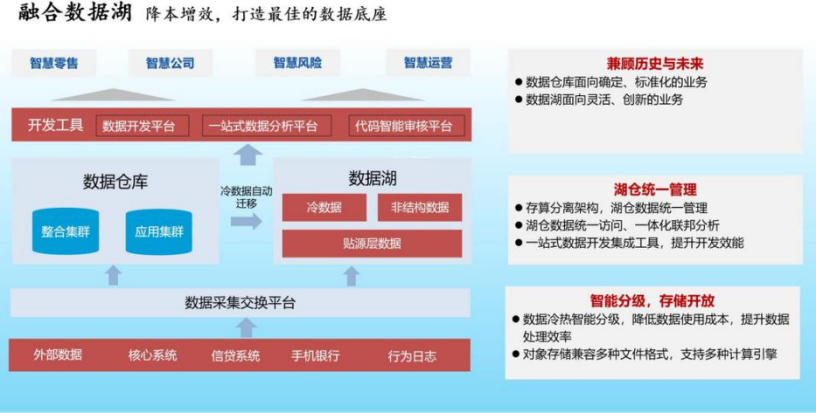
中原银行融合数据湖方案:涵盖了分布式存储、大数据、数据仓库等主流技术方案,通过构建湖仓与数据类服务的一体化方案,实现数据在其间按需高效流转与统一管理,满足全行不同业务条线的个性化多维度的数据统计分析需求。
融合数据湖方案具体技术架构
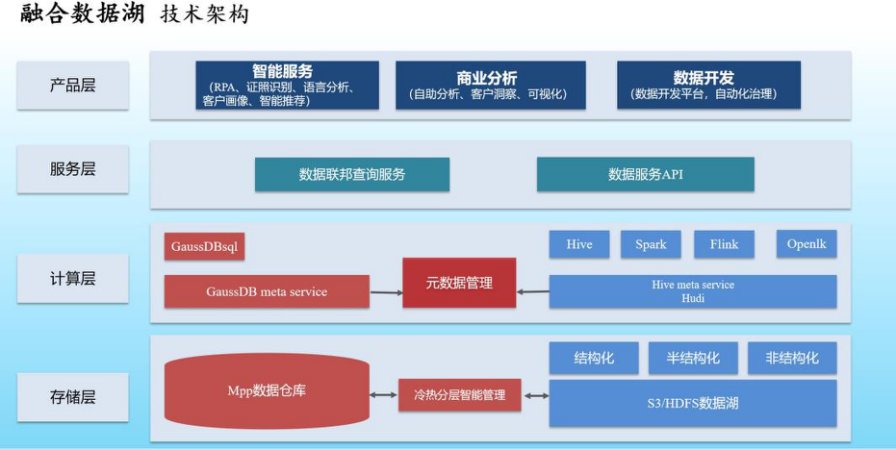
1.冷热分层智能管理
(1)冷热数据的定义
针对不同场景,用户对数据的需求程度是存在差异的,高频引用的数据,用户对数据的加工时长以及高性能访问往往要求严格;而低频引用的数据,则没有那么高的标准。
根据用户对数据的使用频次可以将存储周期内的数据分为热数据与冷数据。顾名思义,热数据为用户高频引用的数据,包括跑批和频繁使用的数据分析。冷数据则为低频引用的数据,一般是历史沉淀的业务数据,这类数据体量大,访问频度低,可以采用成本更低的存储方式,而不是全都存放在数据仓库中。
(2)冷热数据存储方案
具体而言,主流厂商的数据仓库产品为追求高性能的查询响应,一般采用存算一体的架构设计,通过控制与调度本地存储,达到快速访问的目标,虽然无法对存储和计算资源进行单独扩容,但有效保证了本地热数据的计算与查询性能。
数据湖在高扩展、低成本的基础上,实现了计算和存储分离,虽然牺牲了查询效率,但能够支持海量数据的存储,因此非常适合分担数据仓库中冷数据的存储压力。
通过采用基于湖仓一体的冷热数据分层存储方案,可以有效降低数据的单位存储成本。
(3)冷热分层的挑战
在基于湖仓一体的冷热数据分层存储方案实施过程中,我们遇到了一些问题与挑战。
用户对冷热数据是有比较明确的业务定义,但数据仓库在建表时并不能指定有关冷热数据分层的参数,如何定义冷热数据分层参数以及冷热数据如何关联冷热存储集群,是需要解决的首要问题。
(4)冷热分层的解决方案

一站式数据开发平台是中原银行为数据开发人员提供的标准化、自动化、敏捷化的全流程数据开发工作坊。在数据建模板块,我们为用户提供了标准建表功能,可以根据用户输入的中文信息,自动匹配词根并生成英文字段。同时支持用户按照表的分类,配置不同的数据存储策略。
平台可以根据用户建表时指定的数据存储周期策略精确关联业务上的冷热数据和分层存储中的冷热数据存储集群,采用智能化的调度策略,将冷数据自动从数据仓库迁移至数据湖内,并在数据资产平台端详细展示数据分布情况,方便用户查找。
当用户需要使用湖中的冷数据进行重跑批时,平台自动解析用户在补数据模块配置的表级依赖关系,并将用户所需冷数据回流至数据仓库,供重跑批使用,在缓存时间到期后由平台再次自动迁移回数据湖。
2.异构数据统一元数据管理
数据湖通过开放底层文件存储,给数据入湖带来了极致的灵活性。进入数据湖的数据可以是结构化的文本,也可以是半结构化的网页,甚至是完全非结构化的图片。
为避免数据湖成为数据沼泽,我们对数据湖的上传接口进行了定制开发:
● 强制用户配置数据资产标签,包括数据用途、数据生命周期以及所属关系等内容;
● 针对结构化与半结构化数据,平台可以基于特定的规则通过数据爬取功能自动识别并生成schema信息;
● 提供Hive MetaStore统一访问层,方便数据湖计算引擎使用。
针对湖仓一体化的元数据管理,则是在一站式数据开发平台的数据建模板块落地实现的:
● 数据建模板块提供了数据湖与数据仓库的标准建表功能,用户使用标准建表功能产生的元数据信息会统一注册到数据建模板块的元数据中心;
● 对于实现冷热分层存储的表,元数据中心则会根据用户配置的存储策略,精确关联湖仓中的热表信息与冷表信息,在逻辑层面将其作为一张表,并详细展示这张表在数据仓库中以及在数据湖中的表结构与日期范围,方便用户查看。
3.全域数据联邦分析
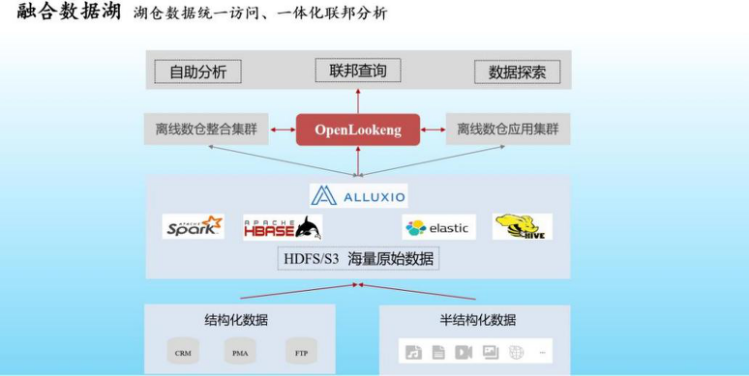
当一份数据按照冷热分层策略,分别存储到数据仓库和数据湖后,如何实现跨湖仓的高效数据分析以及高性能的数据湖查询,成为需要解决的另一个问题。
为此,通过对比分析主流开源的OLAP引擎,我们最终选择Openlookeng作为全域数据联邦查询引擎。
一方面,Openlookeng在底层计算框架继承了Presto的优势,包括存算分离、全内存并行处理、索引能力、分布式流水线等,能够实现高效的数据分析。另一方面,Openlookeng在高可用、缓存加速、动态catalog加载以及可扩展的连接器等方面做了加强,有效满足了企业级场景应用的需求。
通过对接BI工具,用户能够轻松使用标准SQL直接分析湖仓中的数据,避免不必要的ETL。在使用过程中,结合具体应用场景,我们也对OpenLooKeng的部分功能进行了性能优化与二次开发。
(1)湖仓查询性能优化
在实际湖仓联邦查询场景中,OpenLooKeng的查询性并没有达到预期,其主要原因是OpenLooKeng的connector端未实现GaussDB数据源的算子下推功能,导致源端所有数据直接加载到OpenLooKeng计算引擎侧,造成严重的数据传输延迟。
通过参照OpenLooKeng源码中已有其他数据源的算子下推方案,我们实现了GaussDB的算子下推与动态过滤功能,并以插件包形式通过SPI机制注册到OpenLooKeng服务内。
同时为解决存算分离场景下,数据读取本地性的问题,我们引入了开源数据编排技术组件Alluxio。通过将OpenLooKeng的worker节点和Alluxio的worker节点混合部署以及根据用户对数据湖中数据的访问频次进行统计分析,提前将湖中频繁访问的数据预加载到Alluxio中,以此实现数据本地拉取的功能,在有效降低网络传输IO的前提下,提高湖仓分析sql的执行效率。
(3)兼容GaussDB 函数和中文语法
GaussDB(DWS)作为行内主要的数据仓库,数据工程师已经熟练掌握了其语法规则。引入Openlookeng后,虽然两者均支持ANSI SQL2003语法,但对用户在GaussDB中高频使用的函数以及中文字段,Openlookeng是存在兼容性差异的。
为此在Openlookeng引擎端,我们以plugin形式新增了函数插件包,扩展了to_date、instr、to_char的使用场景。对于decode、nvl这类多参数函数,通过对源代码中的动态字节码生成函数方案进行优化,扩展了不同参数的生成策略,满足了参数类型和返回值类型不确定的使用场景。
针对Openlookeng不支持中文字段的问题,我们则是通过对源码中antlr4定义的语法规则进行重构,在SqlBase.g4文件中扩展identifier,定义中文匹配规则,支持了中文的词法匹配。
4.湖仓一站式数据开发与管理
在数据开发方面:我们自主研发了支持湖仓一体架构的数据开发与调度平台,在执行引擎端实现基于多租户的敏捷任务管理,无需人工干预由平台自动根据任务类型下发任务到数据仓库和数据湖中执行。同时依托于智能SQL解析服务,可以对湖仓任务SQL代码进行扫描,按照相应的规则进行匹配,检出质量隐患。
目前中原银行自研的数据任务调度引擎,支持万级别任务的复杂调度与全局依赖管理,支持丰富的调度参数,充分满足用户开发过程中的各类需求。
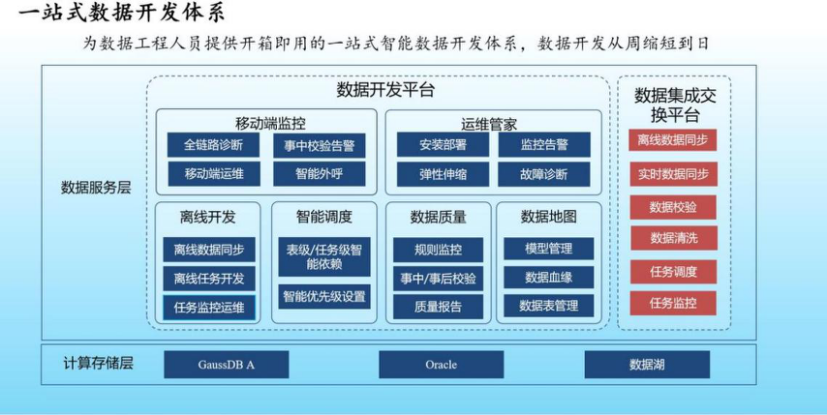
在数据集成与交换方面:平台配置简单灵活,无需编码,Source和Sink端支持丰富的外部数据源,包括ES、HBase、StarRocks、Oracle、GaussDB等;针对相同的数据源表平台采用一卸多装的策略,避免资源重复占用,通过建立资源动态分配机制,实现资源细粒度管控。同时平台采用Spark作为底层分布式执行引擎,支持多源异构数据高效入湖,将湖、仓与专门构建的数据服务有机的连接成为一个整体。
在数据分析方面:我们建设完成一站式数据分析平台,集合固定报表、交互式分析、客户洞察、可视化大屏、数据资产地图、数据创新社区于一体,为业务人员提供搜索、文档、批注等功能的一站式解决方案。平台集成数据湖查询服务,为用户提供高效便捷的数据湖查询、跨湖和仓的联邦分析能力。用户能够轻松使用标准SQL直接分析数据湖中的数据。
融合数据湖方案应用成效
融合数据湖方案从2021年年初开始建设到最终落地,历时1年左右时间。目前整体方案已在行内应用,并取得一定效果。
成本节约:融合数据湖方案支持多类型数据管理,PB级海量数据存储,数据湖分析与计算服务。通过采用湖仓一体的数据智能分层存储策略,有效降低行内数据单位存储成本20%以上。同时也与行内模型管理平台、反欺诈平台完成对接,支撑了各类平台对图片数据的存储与使用需求。
效率提升:通过Openlookeng提供的湖仓协同分析能力,在保持现有数仓业务模型和数据分析人员使用习惯的前提下,有效避免不必要的ETL,减少50%以上的数据搬迁,同时基于算子下推、元数据缓存、数据缓存等技术,支持数据湖查询秒级响应。
开发管理:通过构建湖仓与数据类服务的一体化方案,实现数据高效自由流转与统一管理,支持湖仓任务的协同开发与调度,为全行60多个项目组提供稳定高效的数据开发服务。截至目前,已累计承接行内2万余个数据集成与交换任务,3万余个跑批任务,每月完成20多万sql代码质量审核。
 Coremail邮件安全
Coremail邮件安全
 X0_0X
X0_0X
 RacentYY
RacentYY
 Coremail邮件安全
Coremail邮件安全
 Andrew
Andrew
 X0_0X
X0_0X
 Anna艳娜
Anna艳娜
 尚思卓越
尚思卓越
 X0_0X
X0_0X
 虹科网络安全
虹科网络安全
 安全侠
安全侠
 X0_0X
X0_0X
