SparkStreaming和Kafka基于Direct Approach如何管理offset
VSole2022-08-03 16:33:42
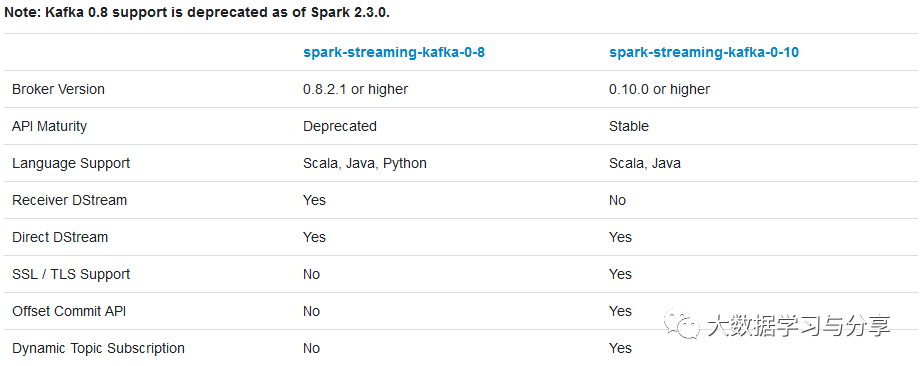
本文主要介绍,SparkStreaming和Kafka使用Direct Approach方式处理任务时,如何自己管理offset?
SparkStreaming通过Direct Approach接收数据的入口:
KafkaUtils.createDirectStream。在调用该方法时,会先创建
KafkaCluster:val kc = new KafkaCluster(kafkaParams)
KafkaCluster负责和Kafka,该类会获取Kafka的分区信息、创建DirectKafkaInputDStream,每个DirectKafkaInputDStream对应一个topic,每个DirectKafkaInputDStream也会持有一个KafkaCluster实例。
到了计算周期后,会调用DirectKafkaInputDStream的compute方法,执行以下操作:
- 获取对应Kafka Partition的untilOffset,以确定需要获取数据的区间
- 构建KafkaRDD实例。每个计算周期里,DirectKafkaInputDStream和KafkaRDD是一一对应的
- 将相关的offset信息报给InputInfoTracker
- 返回该RDD
关于KafkaRDD和Kafka的分区对应关系,可以参考这篇文章:
SparkStreaming和Kafka通过Direct方式集成,自己管理offsets代码实践:
1. 业务逻辑处理
object SparkStreamingKafkaDirect {
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println(
s"""
|Usage: SparkStreamingKafkaDirect <brokers> <topics> <groupid>
| <brokers> is a list of one or more Kafka brokers
| <topics> is a list of one or more kafka topics to consume from
| <groupid> is a consume group
|
""".stripMargin)
System.exit(1)
}
val Array(brokers, topics, groupId) = args
val sparkConf = new SparkConf().setAppName("DirectKafka")
sparkConf.setMaster("local[*]")
sparkConf.set("spark.streaming.kafka.maxRatePerPartition", "10")
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val ssc = new StreamingContext(sparkConf, Seconds(6))
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String](
"metadata.broker.list" -> brokers,
"group.id" -> groupId,
"auto.offset.reset" -> "smallest"
)
val km = new KafkaManager(kafkaParams)
val streams = km.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topicsSet)
streams.foreachRDD(rdd => {
if (!rdd.isEmpty()) {
// 先处理消息
do something...
// 再更新offsets
km.updateZKOffsets(rdd)
}
})
ssc.start()
ssc.awaitTermination()
}
}
2. offset管理核心逻辑
2.1 利用zookeeper
注意:自定义的KafkaManager必须在包org.apache.spark.streaming.kafka下
package org.apache.spark.streaming.kafka
/**
* @Author: 微信公众号-大数据学习与分享
* Spark-Streaming和Kafka直连方式:自己管理offsets
*/
class KafkaManager(val kafkaParams: Map[String, String]) extends Serializable {
private val kc = new KafkaCluster(kafkaParams)
def createDirectStream[
K: ClassTag,
V: ClassTag,
KD <: Decoder[K] : ClassTag,
VD <: Decoder[V] : ClassTag](ssc: StreamingContext,
kafkaParams: Map[String, String],
topics: Set[String]): InputDStream[(K, V)] = {
val groupId = kafkaParams.get("group.id").get
//从zookeeper上读取offset前先根据实际情况更新offset
setOrUpdateOffsets(topics, groupId)
//从zookeeper上读取offset开始消费message
val messages = {
//获取分区 //Either处理异常的类,通常Left表示异常,Right表示正常
val partitionsE: Either[Err, Set[TopicAndPartition]] = kc.getPartitions(topics)
if (partitionsE.isLeft) throw new SparkException(s"get kafka partition failed:${partitionsE.left.get}")
val partitions = partitionsE.right.get
val consumerOffsetsE = kc.getConsumerOffsets(groupId, partitions)
if (consumerOffsetsE.isLeft) throw new SparkException(s"get kafka consumer offsets failed:${consumerOffsetsE.left.get}")
val consumerOffsets = consumerOffsetsE.right.get
KafkaUtils.createDirectStream[K, V, KD, VD, (K, V)](ssc, kafkaParams, consumerOffsets, (mmd: MessageAndMetadata[K, V]) => (mmd.key, mmd.message))
}
messages
}
/** 创建数据流之前,根据实际情况更新消费offsets */
def setOrUpdateOffsets(topics: Set[String], groupId: String): Unit = {
topics.foreach { topic =>
var hasConsumed = true
//获取每一个topic分区
val partitionsE = kc.getPartitions(Set(topic))
if (partitionsE.isLeft) throw new SparkException(s"get kafka partition failed:${partitionsE.left.get}")
//正常获取分区结果
val partitions = partitionsE.right.get
//获取消费偏移量
val consumerOffsetsE = kc.getConsumerOffsets(groupId, partitions)
if (consumerOffsetsE.isLeft) hasConsumed = false
if (hasConsumed) {
val earliestLeaderOffsetsE = kc.getEarliestLeaderOffsets(partitions)
if (earliestLeaderOffsetsE.isLeft) throw new SparkException(s"get earliest leader offsets failed: ${earliestLeaderOffsetsE.left.get}")
val earliestLeaderOffsets: Map[TopicAndPartition, KafkaCluster.LeaderOffset] = earliestLeaderOffsetsE.right.get
val consumerOffsets: Map[TopicAndPartition, Long] = consumerOffsetsE.right.get
var offsets: mutable.HashMap[TopicAndPartition, Long] = mutable.HashMap[TopicAndPartition, Long]()
consumerOffsets.foreach { case (tp, n) =>
val earliestLeaderOffset = earliestLeaderOffsets(tp).offset
//offsets += (tp -> n)
if (n < earliestLeaderOffset) {
println("consumer group:" + groupId + ",topic:" + tp.topic + ",partition:" + tp.partition + "offsets已过时,更新为:" + earliestLeaderOffset)
offsets += (tp -> earliestLeaderOffset)
}
println(n, earliestLeaderOffset, kc.getLatestLeaderOffsets(partitions).right)
}
println("map...." + offsets)
if (offsets.nonEmpty) kc.setConsumerOffsets(groupId, offsets.toMap)
// val cs = consumerOffsetsE.right.get
// val lastest = kc.getLatestLeaderOffsets(partitions).right.get
// val earliest = kc.getEarliestLeaderOffsets(partitions).right.get
// var newCS: Map[TopicAndPartition, Long] = Map[TopicAndPartition, Long]()
// cs.foreach { f =>
// val max = lastest.get(f._1).get.offset
// val min = earliest.get(f._1).get.offset
// newCS += (f._1 -> f._2)
// //如果zookeeper中记录的offset在kafka中不存在(已过期)就指定其现有kafka的最小offset位置开始消费
// if (f._2 < min) {
// newCS += (f._1 -> min)
// }
// println(max + "-----" + f._2 + "--------" + min)
// }
// if (newCS.nonEmpty) kc.setConsumerOffsets(groupId, newCS)
} else {
println("没有消费过....")
val reset = kafkaParams.get("auto.offset.reset").map(_.toLowerCase)
val leaderOffsets: Map[TopicAndPartition, LeaderOffset] = if (reset == Some("smallest")) {
val leaderOffsetsE = kc.getEarliestLeaderOffsets(partitions)
if (leaderOffsetsE.isLeft) throw new SparkException(s"get earliest leader offsets failed: ${leaderOffsetsE.left.get}")
leaderOffsetsE.right.get
} else {
//largest
val leaderOffsetsE = kc.getLatestLeaderOffsets(partitions)
if (leaderOffsetsE.isLeft) throw new SparkException(s"get latest leader offsets failed: ${leaderOffsetsE.left.get}")
leaderOffsetsE.right.get
}
val offsets = leaderOffsets.map { case (tp, lo) => (tp, lo.offset) }
kc.setConsumerOffsets(groupId, offsets)
/*
val reset = kafkaParams.get("auto.offset.reset").map(_.toLowerCase)
val result = for {
topicPartitions <- kc.getPartitions(topics).right
leaderOffsets <- (if (reset == Some("smallest")) {
kc.getEarliestLeaderOffsets(topicPartitions)
} else {
kc.getLatestLeaderOffsets(topicPartitions)
}).right
} yield {
leaderOffsets.map { case (tp, lo) =>
(tp, lo.offset)
}
}
*/
}
}
}
/** 更新zookeeper上的消费offsets */
def updateZKOffsets(rdd: RDD[(String, String)]): Unit = {
val groupId = kafkaParams("group.id")
val offsetList = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
offsetList.foreach { offset =>
val topicAndPartition = TopicAndPartition(offset.topic, offset.partition)
val o = kc.setConsumerOffsets(groupId, Map((topicAndPartition, offset.untilOffset)))
if (o.isLeft) println(s"Error updating the offset to Kafka cluster: ${o.left.get}")
}
}
}
2.2 不利用zookeeper
/**
* @author 大数据学习与分享
* Spark Streaming和Kafka082通过mysql维护offset
*/
object SaveOffset2Mysql {
def getLastOffsets(database: String, sql: String, jdbcOptions:Map[String,String]): HashMap[TopicAndPartition, Long] = {
val getConnection: () => Connection = JdbcUtils.createConnectionFactory(new JDBCOptions(jdbcOptions))
val conn = getConnection()
val pst = conn.prepareStatement(sql)
val res = pst.executeQuery()
var map: HashMap[TopicAndPartition, Long] = HashMap()
while (res.next()) {
val o = res.getString(1)
val jSONArray = JSONArray.fromObject(o)
jSONArray.toArray.foreach { offset =>
val json = JSONObject.fromObject(offset)
val topicAndPartition = TopicAndPartition(json.getString("topic"), json.getInt("partition"))
map += topicAndPartition -> json.getLong("untilOffset")
}
}
pst.close()
conn.close()
map
}
def offsetRanges2Json(offsetRanges: Array[OffsetRange]): JSONArray = {
val jSONArray = new JSONArray
offsetRanges.foreach { offsetRange =>
val jSONObject = new JSONObject()
jSONObject.accumulate("topic", offsetRange.topic)
jSONObject.accumulate("partition", offsetRange.partition)
jSONObject.accumulate("fromOffset", offsetRange.fromOffset)
jSONObject.accumulate("untilOffset", offsetRange.untilOffset)
jSONArray.add(jSONObject)
}
jSONArray
}
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(5))
val kafkaParams = Map("metadata.broker.list" -> SystemProperties.BROKERS,
"zookeeper.connect" -> SystemProperties.ZK_SERVERS,
"zookeeper.connection.timeout.ms" -> "10000")
val topics = Set("pv")
val tpMap = getLastOffsets("test", "select offset from res where id = (select max(id) from res)")
var messages: InputDStream[(String, String)] = null
if (tpMap.nonEmpty) {
messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](
ssc, kafkaParams, tpMap, (mmd: MessageAndMetadata[String, String]) => (mmd.key(), mmd.message()))
} else {
kafkaParams + ("auto.offset.reset" -> "largest")
messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
}
// var oRanges = Array[OffsetRange]()
// messages.transform { rdd =>
// oRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// rdd
// }.foreachRDD { rdd =>
// val offset = offsetRanges2Json(oRanges).toString
// }
messages.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd.map(_._2).flatMap(_.split(" ")).map((_, 1L)).reduceByKey(_ + _).repartition(1)
.foreachPartition { par =>
if (par.nonEmpty) {
val conn = MysqlUtil.getConnection("test")
conn.setAutoCommit(false)
val pst = conn.prepareStatement("INSERT INTO res (word,count,offset,time) VALUES (?,?,?,?)")
par.foreach { case (word, count) =>
pst.setString(1, word)
pst.setLong(2, count)
pst.setString(3, offset)
pst.setTimestamp(4, new Timestamp(System.currentTimeMillis()))
pst.addBatch()
}
pst.executeBatch()
conn.commit()
pst.close()
conn.close()
}
}
}
ssc.start()
ssc.awaitTermination()
}
}
// Spark Streaming和Kafka010整合维护offset
val kafkaParams = Map[String, Object]("bootstrap.servers" -> SystemProperties.BROKERS,
"key.deserializer" -> classOf[StringDeserializer],
"key.deserializer" -> classOf[StringDeserializer],
"group.id" -> "g1",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false: java.lang.Boolean))
val messages = KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe(topicSet, kafkaParams, getLastOffsets(kafkaParams, topicSet)))
messages.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd.foreachPartition { iter =>
val o: OffsetRange = offsetRanges(TaskContext.get.partitionId)
println(s"${o.topic} ${o.partition} ${o.fromOffset} ${o.untilOffset}")
iter.foreach { each =>
s"Do Something with $each"
}
}
messages.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
def getLastOffsets(kafkaParams: Map[String, Object], topicSet: Set[String]): Map[TopicPartition, Long] = {
val props = new Properties()
props.putAll(kafkaParams.asJava)
val consumer = new KafkaConsumer[String, String](props)
consumer.subscribe(topicSet.asJavaCollection)
paranoidPoll(consumer)
val consumerAssign = consumer.assignment().asScala.map(tp => tp -> consumer.position(tp)).toMap
consumer.close()
consumerAssign
}
/** 思考: 消息已消费但提交offsets失败时的offsets矫正? */
def paranoidPoll(consumer: KafkaConsumer[String, String]): Unit = {
val msg = consumer.poll(Duration.ZERO)
if (!msg.isEmpty) {
// position should be minimum offset per topic partition
// val x: ((Map[TopicPartition, Long], ConsumerRecord[String, String]) => Map[TopicPartition, Long]) => Map[TopicPartition, Long] = msg.asScala.foldLeft(Map[TopicPartition, Long]())
msg.asScala.foldLeft(Map[TopicPartition, Long]()) { (acc, m) =>
val tp = new TopicPartition(m.topic(), m.partition())
val off = acc.get(tp).map(o => Math.min(o, m.offset())).getOrElse(m.offset())
acc + (tp -> off)
}.foreach { case (tp, off) =>
consumer.seek(tp, off)
}
}
}
上述给出一个demo思路。实际生产中,还要结合具体的业务场景,根据不同情况做特殊处理。

VSole
网络安全专家