angr符号变量转LLVM IR
前言
之前看到过国外的一篇文章。关于如何处理虚拟机的,并给出了针对tigress虚拟机的攻击方法。
具体是这样处理的:
- 装载目标文件
- 初始化一些hook
- 对虚拟机函数进行符号执行,获取各种符号变量
- 将符号变量转化成llvm的ir
- 使用llvm编译优化重编译
后面那作者还研究出来了攻击VMP的方法,具体可以参考。
https://github.com/JonathanSalwan/VMProtect-devirtualization
这个方法确实很巧妙,但是使用的triton,然而其python接口基本没有说明。属实劝退。
angr?
观察下具体的实现,发现是将triton处理出的符号变量的expr进行遍历,然后将某些语义节点转化为对应的llvm ir。从而实现了将expr lift到llvm的ir。然后就可以享用llvm自带的丰富的优化pass了。
由于triton的学习成本较大(x,所以我们可以采用更加简单的符号执行工具angr。同样的angr也使用树结构来描述一个符号变量。然后将其转化成llvm的ir。
claripy?
众所周知,angr的约束求解框架前端是claripy,执行出来的符号变量被claripy表示出来,然后交给后端的约束求解引擎,例如z3。
claripy的表示中有很多种操作,这里列出两种常见又难以处理的操作。
- concat,将两个符号变量链接
- extract,提取符号变量中的某几位。
由于使用python编写,所以考虑使用llvmlite来构建llvm的ir。安装过程略。
对于一些其他的算数指令,可以直接将其映射到llvm的某个指令上去,而对于上面两个稍微复杂的操作,考虑直接用位运算来表示。
这里是一张图,表示了claripy下的某个符号变量:

concat
链接a和b两个变量
concat(a,b)
c = (zext(a, size(a) + size(b)) << size(b)) | (zext(b, size(a) + size(b)))
将两个符号变量扩展到两个符号变量位数之和,然后将前面的变量左移后面变量的位数,然后或上后面的那个变量即可实现两个符号变量的链接。该运算在angr中表示为a..b
extract
提取a变量的第l位到第h位。
extract(a,l,h)
y = (a & bitmask) >> (h - l + 1)
先将变量与上一个bitmask,可以与出对应的数据,然后一位,让数据从低0位开始,最后trunc截取一下长度。该运算在angr中表示为a[l:h]。
这样就可以做到将所有的操作用llvm的ir表示出来,接下来要做的就是遍历获取的expr的ast,然后边遍历边构造llvm的ir。出来又在run一下llvm自带的优化。
直接上代码:
解释一下,lifter是一个visitor,遍历ast,然后在某个节点应用对应的处理函数,cur则代表当前节点对应的值(对应LLVM的Value概念)。所以先visit子节点,调用函数结束的时候cur就是子节点对应的value,然后可以继续构造当前节点的value。
当节点是BVS或者是BVV时停止向下访问,然后分别处理其他未知变量和常量。未知变量设定为llvm的函数参数,常量可以直接提取出来,转化成llvm ir中的常量。
import angrimport claripyfrom llvmlite import irimport llvmlite.binding as llvmunop_llvm = { '__invert__':ir.IRBuilder.not_, '__neg__':ir.IRBuilder.neg}binop_llvm = { '__add__':ir.IRBuilder.add, '__floordiv__':ir.IRBuilder.udiv, 'SDiv':ir.IRBuilder.sdiv, '__mul__':ir.IRBuilder.mul, '__sub__':ir.IRBuilder.sub, '__mod__':ir.IRBuilder.urem, 'SMod':ir.IRBuilder.srem, '__and__':ir.IRBuilder.and_, '__or__':ir.IRBuilder.or_, '__xor__':ir.IRBuilder.xor, '__lshift__':ir.IRBuilder.shl, '__rshift__':ir.IRBuilder.ashr, 'LShR':ir.IRBuilder.lshr}signed_op = ['SDiv','SMod']supported_op = ['Concat','ZeroExt','SignExt','Extract','RotateLeft','RotateRight'] + list(unop_llvm.keys()) + list(binop_llvm.keys())supported_type = ['BVV','BVS']class lifter: def __init__(self): self.expr = None self.cur = None self.count = 0 self.value_array = [] self.builder = None self.func = None self.args = {} self.node_count = 0 def new_value(self, value, expr): assert value.type.width == expr.size() n = self.count self.value_array.append(value) self.count += 1 return n def get_value(self, idx): return self.value_array[idx] def _visit_value(self, expr): if expr.op == 'BVV': self.cur = self.new_value(ir.Constant(ir.IntType(expr.size()), expr.args[0]), expr) else: self.cur = self.new_value(self.func.args[self.args[expr]], expr) pass def _visit_binop(self, expr): left = None for a in expr.args: self._visit_ast(a) if left is None: left = self.cur else: v = self.cur lhs = self.get_value(left) rhs = self.get_value(v) self.cur = self.new_value(binop_llvm[expr.op](self.builder, lhs, rhs, name = "node" + str(self.node_count)), expr) left = self.cur self.node_count += 1 pass def _visit_unop(self, expr): self._visit_ast(expr.args[0]) v0 = self.cur self.cur = self.new_value(unop_llvm[expr.op](self.builder, self.get_value(v0), name = "node" + str(self.node_count)), expr) self.node_count += 1 pass def _visit_concat(self, expr): left = None for a in expr.args: self._visit_ast(a) if left is None: left = self.cur else: v = self.cur lens = self.get_value(left).type.width + self.get_value(v).type.width val0 = self.builder.zext(self.get_value(left), ir.IntType(lens)) val1 = self.builder.zext(self.get_value(v), ir.IntType(lens)) self.cur = self.new_value(self.builder.or_(self.builder.shl(val0, ir.Constant(ir.IntType(lens), self.get_value(v).type.width)), val1, name = "node" + str(self.node_count)), expr) left = self.cur self.node_count += 1 pass def get_bit_mask(self, low, high): mask = 0 for i in range(low, high + 1): mask += 2 ** i return mask def _visit_extract(self, expr): high = expr.args[0] low = expr.args[1] self._visit_ast(expr.args[2]) v0 = self.cur val = self.get_value(v0) mask = self.get_bit_mask(low, high) self.cur = self.new_value(self.builder.trunc(self.builder.lshr(self.builder.and_(val, ir.Constant(val.type, mask)), ir.Constant(val.type, low)), ir.IntType(high - low + 1), name = "node" + str(self.node_count)), expr) self.node_count += 1 pass def _visit_zeroext(self, expr): length = expr.args[0] self._visit_ast(expr.args[1]) v0 = self.cur self.cur = self.new_value(self.builder.zext(self.get_value(v0), ir.IntType(length + expr.args[1].size()), name = "node" + str(self.node_count)), expr) self.node_count += 1 pass def _visit_signext(self, expr): length = expr.args[0] self._visit_ast(expr.args[1]) v0 = self.cur self.cur = self.new_value(self.builder.sext(self.get_value(v0), ir.IntType(length + expr.args[1].size()), name = "node" + str(self.node_count)), expr) self.node_count += 1 pass def _visit_rotateleft(self,expr): bit = expr.args[1] self._visit_ast(expr.args[0]) v0 = self.cur val = self.get_value(v0) width = val.type.width self.cur = self.new_value(self.builder.or_(self.builder.lshr(val, ir.Constant(val.type, width - bit)), self.builder.shl(val.type, ir.Constant(val.type, bit)), name = "node" + str(self.node_count)), expr) self.node_count += 1 pass def _visit_rotateright(self,expr): bit = expr.args[1] self._visit_ast(expr.args[0]) v0 = self.cur val = self.get_value(v0) width = val.type.width self.cur = self.new_value(self.builder.or_(self.builder.shl(val, ir.Constant(val.type, width - bit)), self.builder.lshr(val.type, ir.Constant(val.type, bit)), name = "node" + str(self.node_count)), expr) self.node_count += 1 pass def _visit_op(self, expr): if expr.op in binop_llvm.keys(): self._visit_binop(expr) elif expr.op in unop_llvm.keys(): self._visit_unop(expr) else: func = getattr(self, '_visit_' + expr.op.lower()) func(expr) def _visit_ast(self, expr): assert isinstance(expr, claripy.ast.base.Base) if expr.op in supported_op: self._visit_op(expr) elif expr.op in supported_type: self._visit_value(expr) else: raise Exception("unsupported operation!") def lift(self, expr): self.expr = expr self.count = 0 self.value_array = [] self.args = {} c = 0 for i in expr.leaf_asts(): if i.op == 'BVS': self.args[i] = c c += 1 items = sorted(self.args.items(),key=lambda x:x[1]) print("Function arguments: ") print(items) type_list = [] for i in items: type_list.append(ir.IntType(i[0].size())) fnty = ir.FunctionType(ir.IntType(expr.size()), tuple(type_list)) module = ir.Module(name=__file__) self.func = ir.Function(module, fnty, name="dump") block = self.func.append_basic_block(name="entry") self.builder = ir.IRBuilder(block) self._visit_ast(expr) self.builder.ret(self.get_value(self.cur)) return str(module)
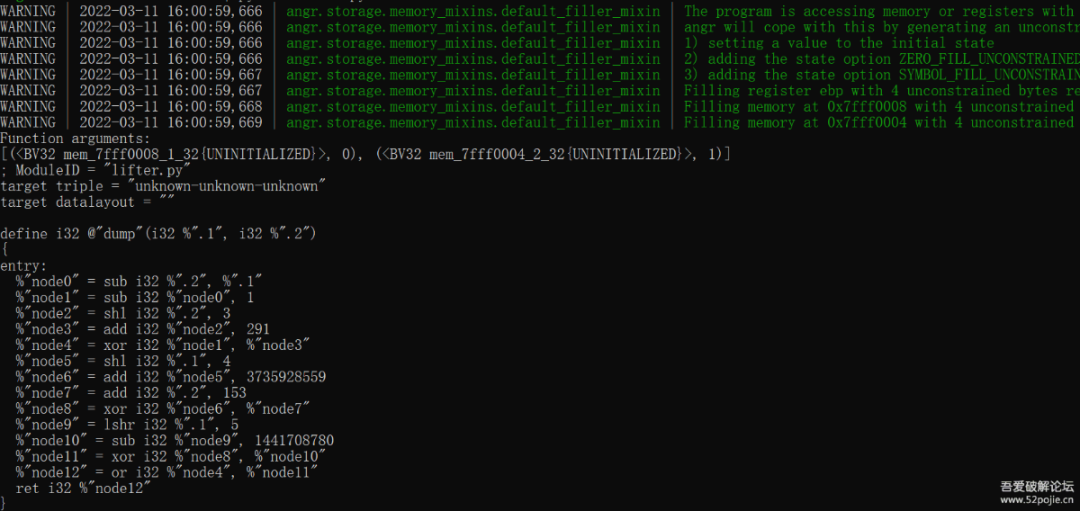
目前并未进行大规模测试,可能存在bug。小测一波。
这是被测试的函数:

测试结果:
小结
这里可以想出一个简单vm的处理方法,首先我们找到虚拟机的内存和上下文,将其设置为符号变量,其他内容则初始化为常量,然后开始符号执行,然后提取并化简上下文中的符号表达式,然后重新编译优化即可重建虚拟机的逻辑。
当然这个虚拟机要足够简单,然而虚拟机往往都有跳转语句,符号执行在遇到跳转的时候将变得极其爆炸。生成的表达式也可能极其复杂,llvm的优化也没有用。所以可以考虑分而治之。
找到虚拟机的跳转语句的handler,然后在angr中hook,根据跳转目的地和当前跳转语句地址(控制流生成算法),能够很好的将虚拟机的opcode构造控制流图,然后针对每一个opcode的basicblock进行符号执行,将上下文全部符号化,然后评估basicblock执行完毕后的上下文的变化,如果发生了改变则可以说明该basicblock干了什么。
然后将这些副作用(表达式)收集起来,则可以代表这个basicblock到底干了什么,最后处理整个控制流图,即可实现程序的重构。这种自动化的虚拟机代码重构,处理能力还比较弱,也只是笔者的一个想法,以后准备细细研究一波。
