内存计算系统系列成果之八:Gengar:基于RDMA的分布式异构内存池
非易失性内存具有存储密度高、低功耗、字节可寻址、接近DRAM的读写性能等优良特性,为数据中心应用构建大型分布式共享内存系统提供了可能。尽管有许多关于在单节点中使用NVM的研究,但在分布式数据中心环境中如何有效利用NVM仍然存在挑战。我们提出了支持RDMA的分布式异构内存池Gengar,使应用程序可通过简单的API对全局内存空间中的远端NVM和DRAM进行高效利用。Gengar在应用端监控单边RDMA原语来识别异构内存池中经常访问的热点数据,并将其缓存在分布式DRAM缓冲区中。我们重新设计了RDMA通信协议和原语,通过代理机制在可靠连接情况下实现了异步RDMA写操作,从而减少写延迟。Gengar支持多个用户之间的内存共享,并且通过租赁机制来减少维护数据一致性的管理开销。实验结果表明,Gengar能显著提分布式共享异构内存池的性能,与已有的分布式异构内存系统相比,其性能提升高达70%。
该成果“Gengar: An RDMA-based Distributed Hybrid Memory Pool” 发表在CCF B类国际学术会议41th IEEE International Conference on Distributed Computing Systems (ICDCS 2021)上。IEEE分布式计算系统国际研讨会(IEEE ICDCS)是计算机分布式计算领域的顶级国际会议,本届会议共收到489篇投稿,共录用97篇论文,录用率约为19.8%。

- 论文链接:
- https://ieeexplore.ieee.org/document/9546450
- 开源链接:
- https://github.com/CGCL-codes/gengar
摘要
非易失性内存(NVM)具有比DRAM更高的存储密度、更低的功耗和成本,已被越来越多地应用于数据中心。尽管以前有许多关于在单机环境中使用NVM的研究,但在分布式数据中心环境中有效利用它仍然存在诸多挑战。我们设计并实现了支持RDMA的分布式共享异构内存(DSHM)池系统Gengar。它具有非常简单的编程API,可以在全局内存地址空间中分配远端NVM和DRAM。为了降低远端NVM访问延迟,我们利用客户端RDMA原语的语义来识别异构内存池中经常访问的热点数据,并将其缓存在分布式的DRAM缓冲区。为了减少RDMA写的高延迟,我们重新设计了RDMA通信协议,通过代理机制把RDMA写从应用执行的关键路径上移除。Gengar还支持多个用户之间的内存共享,并保证数据的一致性。我们在配备了Intel Optane DC Persistent DIMMs的硬件平台上对Gengar进行了测试。实验结果表明,与已有的DSHM系统相比,Gengar显著提高MapReduce和YCSB等公共基准测试集的性能达70%。
背景与动机
目前,远端NVM访问的高延迟是在数据中心环境中使用DSHM的一个主要问题。例如,256字节对象的远端访问延迟约为7.3us,比本地NVM的读取延迟(∼0.7us)高一个数量级,比本地NVM的写入延迟(∼2.3us)也高出很多。因此,如何有效降低远端NVM访问的读/写延迟是设计分布式持久内存池系统需要考虑的一个重要问题。
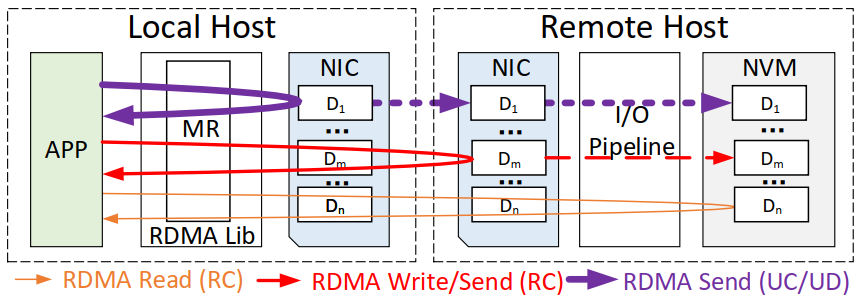
图1 RDMA read/write/send操作的数据流图
图1显示了RDMA read / write / send等操作的数据流图。一个RDMA操作往往涉及多个组件,即本地应用程序、本地内存区域(MR)、本地网络接口卡(NIC)、远端NIC和远端内存(如NVM)。不同的RDMA通信模型都允许这些解耦的组件单独进行数据传输,因此为优化不同组件中的RDMA通信性能提供了广阔的机会。例如,MR重用机制已被广泛用于降低MR注册的成本。FaSST利用合作多任务、网卡doorbell批处理和事件凝聚机制来优化RPC,从而降低RDMA网络延迟。DaRPC通过在服务器端利用完成队列共享/聚合来改善RDMA操作和RPC处理的并行性。我们在支持RDMA的DSHM系统中发现了以下性能优化的机会。
首先,RDMA通信的异步特性有可能被用来改善RDMA写操作。从RDMA网络堆栈的角度来看,所有的RDMA操作(send/recv, read/write等)都在不同的组件中进行异步处理。然而,从应用的角度来看,单个RDMA写操作的延迟仍然相当高,因为RDMA写请求必须等待从远端网卡(NIC)返回的WC事件。一些工作选择放弃可靠连接(RC)模式,以实现RDMA操作的高吞吐量。例如,Herd使用不可靠的连接(UC)模式,FaSST使用不可靠的数据报(UD)模式。它们都通过在本地返回WC事件来隐藏网络RTT,如图1所示。然而,UC和UD模式不能保证在高负载的分布式内存池系统中实现可靠的数据传输,并可能导致严重的性能问题。此外,无信号的RDMA写模式甚至不需要等待WC事件,但这种模式存在的问题是,客户端可以迅速填满QP,并使服务器的接收缓冲区过载,因为它可以在不被同步事件阻断的情况下不断发送WR。在这种情况下,RDMA自我保护机制会中断RDMA连接,大大降低了RDMA通信的性能。总的来说,改进RDMA写操作仍然存在挑战。
其次,DRAM缓存机制已被证明在单机环境下的异构内存系统中可有效减小热点数据的访存延迟。RDMA读操作通常以同步模式处理,因此RDMA读延迟主要由网络RTT和远端NVM读延迟决定。由于NVM的读取延迟比DRAM的读取延迟高2.3倍-4倍,因此通过利用分布式DRAM缓存来加快NVM的读取速度是非常有效的。
设计与实现
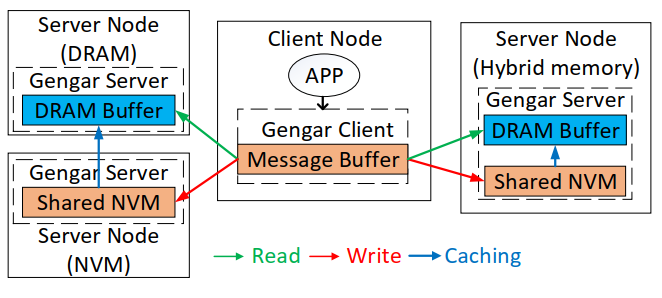
图2 Gengar的去中心化架构
图2显示了Gengar的去中心化系统结构。Gengar实现了基于客户/服务器模型的远端内存共享模式。客户端节点运行应用程序并访问服务器节点中的远端内存,其中Gengar服务器管理共享的NVM和DRAM缓冲区。Gengar系统没有集中的元数据服务器,每个客户端在本地维护一个远端服务器的列表,每个服务器将其可用的DRAM/NVM容量伴随着RDMA操作的ACKs报告给客户端。Gengar将所有服务器中的NVM资源作为一个共享内存池进行管理,并使用少量(本地或远端)DRAM作为分布式缓冲以加快NVM的访问速度。Gengar客户端从共享内存池中为应用程序分配NVM,当一个对象被确定为热(频繁访问)数据时,Gengar客户端会从内存池中请求DRAM来缓存热对象。DRAM缓存可以驻留在任何服务器节点上,因此当热对象的数量增加时,Gengar也具有很好的扩展性。当一个对象被回收时,Gengar服务器会从DRAM缓冲区和共享NVM池中回收其内存。热数据的缓存机制只由Gengar执行,不需要客户端应用程序的参与。DRAM对应用程序完全透明,程序员甚至不需要知道远端内存池的异构性。为了保证存储在DSHM池中的所有数据都是持久的,Gengar中的分布式DRAM缓冲区实现为一个write-through的高速缓存。如果数据已经存在于DRAM缓存中,它将被同时写入DRAM缓存和NVM中。否则,数据将绕过DRAM缓存直接写入NVM。通过这种方式,Gengar只在DRAM中缓存经常读取的对象,以加快RDMA读取操作,同时保证数据的持久性。
此外,由于单边RDMA操作不被远端服务器的CPU和操作系统所感知,因此很难在服务器端监控数据访问。Gengar利用RDMA读操作的语义来识别客户端的热点对象。我们为地址映射表中的每个对象添加读计数器。对于每个RDMA读操作,由于首先需要查询地址映射表以获得远端内存地址,Gengar客户端顺便更新对象的读计数器。在一个固定的时间段内,Gengar客户端能够计算每个对象的RDMA读频率。如果一个对象的读次数超过了一个给定的阈值,那么它就被确定为热对象。每个Gengar客户端单独确定热对象,然后将这些对象的读计数发送到服务器,以便在全局范围内选择热对象。
一般来说,使用可靠连接模式的RDMA写操作包括五个步骤:1)客户端应用程序为RDMA操作注册一个MR;2)客户端将RDMA写工作请求(WR)添加到其发送队列中,应用程序被挂起以等待工作完成(WC)事件;3)RDMA驱动程序处理写WR,数据被传输到服务器;4)服务器创建一个WC事件并放在完成队列(CQ)上;5)应用程序继续运行并取消MR的注册。所有基于RC的RDMA操作都要阻断应用来等待WC事件,这使得客户端和服务器之间的网络RTT的延迟成为应用的关键路径。由于网络RTT占RDMA写延迟的大部分,它对写密集型应用的性能有很大影响。

图3 Gengar的RDMA写模式
在本文中,我们提出了一种新颖的RDMA写模式,将RDMA写操作的网络RTT从应用的关键路径中移除。我们仍然依靠RC模式来保证数据可靠传输和事件的有序交付,同时实现像UC/UD模式一样具有极低延迟的RDMA写操作。为了减少应用程序观察到的RDMA写延迟,我们重新设计了RDMA写原语,一旦客户端NIC收到WR,就向应用程序返回RDMA写操作的完成事件,这样应用程序就可以立即继续执行。如图3所示,此时,RDMA写操作的完成与UC/UD模式类似(步骤1-2-3-4)。因为步骤1-2-3-4是在客户端本地执行的,所以对应用程序来说,传输数据到远端服务器的时间被隐藏了。然而,当数据真正被发送到远端服务器时(步骤5),客户端NIC收到确认(ACK)(步骤6),WC事件仍然被发布在CQ上。这时,RDMA驱动程序会向Gengar客户端发送一个Write Confirm事件,以通知RDMA写入的真正完成(步骤7)。
Gengar实际上是一个基于RDMA的异构内存资源共享的中间件。如果没有足够的应用语义,仅在Gengar中实现远端内存访问的并发控制是非常昂贵的。因此,我们认为共享内存的并发控制应该由应用程序本身来实现,例如使用锁。然而,这仍然存在两个挑战。首先,新的RDMA写模式可能会影响共享对象的并发控制。例如,如果多个客户端同时访问同一个对象,写者应该被通知RDMA写操作真正完成的时间,然后释放写锁。因此,Gengar应该提供API来实现共享对象的并发控制。第二,Gengar中的缓存机制可能会导致元数据不一致的问题。当一个共享对象被释放、被缓存到DRAM缓冲区、或从DRAM缓冲区被驱逐时,地址映射表中的相应条目应该在客户端和服务器中被删除/更新。如果地址更新没有立即传播到其他客户端,就会出现元数据不一致的问题。
为了保证所有客户的元数据一致性,一个简单的方法是在DSHM池中广播地址更新事件。然而,对于大规模的分布式系统来说,网络泛滥的成本往往很高。在元数据同步的过程中,对对象的任何访问都应该被阻止,直到所有客户端达成共识。在Gengar中,我们利用服务器侧的租赁分配策略来减轻元数据同步的开销。Gengar使用一个时间戳为每个对象设置租赁到期时间。对于释放内存和缓存对象的操作,Gengar客户端需要等待当前租约的到期。一旦客户端获得了访问对象的租约,它就可以执行RDMA操作,而不需要在多个客户端之间频繁同步元数据。租约的持续时间对DRAM的使用效率有很大影响,因此,我们根据对象的访问频率通过爬山算法来动态调整它。我们对DRAM和NVM中的热对象和冷对象使用相反的租赁设置。Gengar为NVM中的热对象设置了一个较短的租约,以便更早地将它们取到DRAM缓冲区。相比之下,Gengar为DRAM中的热对象设置了一个长租约以避免过多的租约重新分配。如果Gengar客户端已经有了租约分配,它只需要一个RTT来访问对象的单边RDMA读/写操作。否则,Gengar客户端需要两个RTT来访问一个对象,其中一个RTT用于申请租赁分配,另一个RTT用于数据传输。为了同时保证元数据和数据的一致性,Gengar提供了一个应用层面的API(set lock)来支持共享对象的数据和元数据的并发控制。对于allocation/release/caching/eviction和read/write操作,Gengar使用一个锁和3个RTT来完成这些RPC。
我们在配备了Intel Optane DC Persistent DIMMs的NVM硬件平台上对Gengar进行了性能测试,并与已有的系统memHDFS, Alluxio, NVFS, Crail, Octopus, 及Hotpot进行比较。微程序测试表明,GengarR(Proxy RDMA)和GengarD(DRAM caching)可以分别提高这些微基准测试程序的吞吐量达94%和57%,其中GengarR更适用于写密集型工作负载,而GengarD更适合读取密集型工作负载。对公共基准测试集MapReduce而言,Gengar与Octopus相比,Teragen和Wordcount的执行时间分别减少了64%和56%,读和写的吞吐量分别提高了51%和70%。对键值存储基准测试集而言,Gengar与Octopus和Hotpot相比,应用性能分别提高了48%和40%。对图处理基准测试集而言,在大规模的图数据集上,Gengar与Octopus和Hotpot相比,性能提高了60%和52%。
参考文献:
Zhuohui Duan, Haikun Liu, Haodi Lu, Xiaofei Liao, Hai Jin, Yu Zhang, Bingsheng He. "Gengar: An RDMA-based Distributed Hybrid Memory Pool", Procceding in the 41th IEEE International Conference on Distributed Computing Systems (ICDCS 2021),July 7-10, 2021, pp. 92-103, doi: 10.1109/ICDCS51616.2021.00018.
往期 · 回顾