Akamai保护的相关网站(IHG,TI)学习记录
之前没怎么看web,就看抖音的时候看过一下web版本,最近接触了下Akamai,主要看了下面2个网站:
https://www.ihg.com/
https://www.ti.com
相比二进制的逆向,这个套路还是有点不同,这里记录下分析过程,技术交流用。
现在回过头来看,主要是两个部分:
1、指纹检测,发起的http请求中的ja3指纹要跟浏览器一致的(还要考虑不同版本的浏览器有特定的header字段,总之就是要伪装成真实浏览器请求)。
2、JS逆向,这个主要就是反混淆调试逻辑了,处理sensor_data数据请求,对于搞过二进制逆向的,这个反混淆感觉也不是必须的,就算是直接硬扛,也比PC的VMP简单,当然能够处理,肯定更加方便调试。
1、弯路部分
刚开始也是网上搜了下,资料不多,不是旧版本就是没怎么细讲的(也有可能是讲得太细,就会被封,之前发过一篇小红书 V7.37 学习记录(https://bbs.pediy.com/thread-272520.htm),感觉也没写很细,被移会员区了,其实就相当于删帖了)。
初始搞的过程中最大问题就是发现请求结果不是预期的时候,不知道是指纹问题,还是 akamai sensor_data数据有问题。
首先直接用node自带的http模块请求,发现也能返回,自己维护cookie,按Chrome请求记录来发送,发现最后也能登录TI,但是看返回头里面有不正常的情况:
'ti_bm=Unknown%20Bot%20(AB5B20DF4B5B288A17DACF5E811F9ED8)%3amonitor%3a%3aRequest%20Anomaly%3a%3a;
path=/; domain=.ti.com.cn'
刚开始发现能登录,也没管这个,后来请求加入购物车的时候,死活不行,发送sensor_data也不行,总是返回一个信息:You don't have permission to access ...
这个时候才又开始检查之前的返回状态,cookie字段太多了,看数据比较复杂,觉得相关的有bm_sv,bm_mi,ak_bmsc,_abck,bm_sz,ti_bm等。
因为也不清楚这些cookie的返回逻辑,跟浏览器请求记录比较中,有时候发现浏览器会多某个字段,就想到会不会是少发了某个请求,毕竟自己协议请求比浏览器实际请求是少很多的,后来补了很多请求,这个过程实际花了不少时间折腾,结果一样,接着就想到跟浏览器实际请求的差异问题了。
首先就是想搞一个带源码的浏览器调试环境,Chrome浏览器本身是不开源的,后来发现了miniblink:
weolar/miniblink49: a lighter, faster browser kernel of blink to integrate HTML UI in your app. 一个小巧、轻量的浏览器内核,用来取代wke和libcef (github.com)
(https://github.com/weolar/miniblink49)
把源码拖下来编译了个版本(新版本没开源了),跑TI网站比较慢,最后屏蔽了一些图片显示相关的,走了下登录流程,发现返回的cookie字段中也有异常情况:
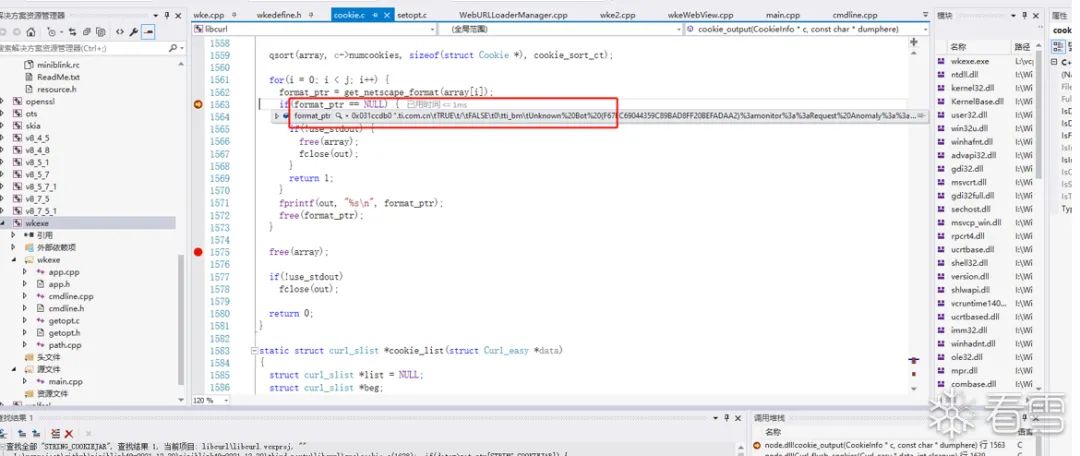
就是ti_bm中也返回了Unknown%20Bot,看起来miniblink请求也是过不了检测的,并且后来比较请求返回的网页内容,其实跟正常浏览器也是有不同的,比如Chrome请求返回页面中会包含下面脚本:
<script >bazadebezolkohpepadr="355903178"script><script type="text/javascript" src="https://www.ti.com.cn/akam/13/1536a743" defer>script>
但是使用miniblink请求,或者node自带http模块请求,就没有这个信息。
当时的想法还是想找一个直接能用的请求库,尝试过mytls等几个号称可以修改指纹的库,实际测试也是不行,一时没找到,后来想到之前搞过抖音的Cronet库,是调通了整个请求流程的,就尝试用抖音的Cronet库来请求TI网站:
Executor executor = Executors.newSingleThreadExecutor();UrlRequest.Builder requestBuilder = cronetEngine.newUrlRequestBuilder(strUrl, new MyUrlRequestCallback(), executor); requestBuilder.addHeader("accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9");requestBuilder.addHeader("cookie",getSendCookieByUrl(strUrl)); UrlRequest request = requestBuilder.build();request.start();
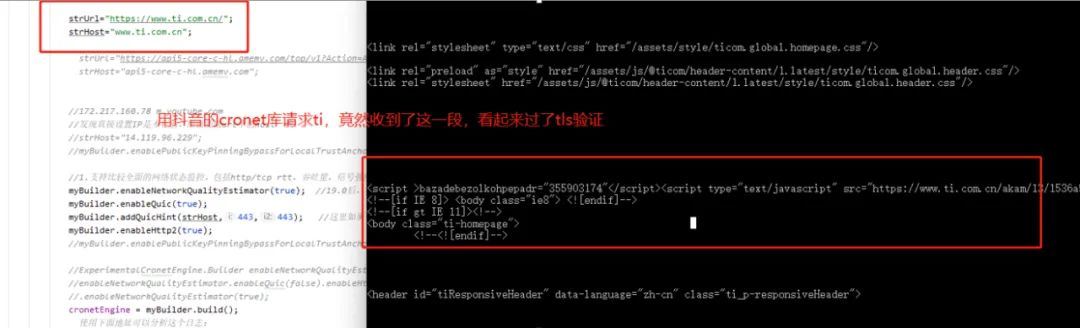
测试后发现,还真能返回上面的script信息了,这部分跟浏览器请求的倒是一样了,但是最后实际请求加入购物车协议的时候,还是失败。
折腾了一圈,各种组合请求还是没搞定,毕竟这个库的请求指纹跟浏览器还是不同的,那还是要从请求上保持跟浏览器的完全一致才行。
2、解决指纹,让请求跟浏览器一致
这个开始也是准备硬杠的,打算按照wireshark记录的浏览器请求算法来修改请求的算法组,查资料的过程中,发现了
lwthiker/curl-impersonate - Docker Image | Docker Hub
(https://hub.docker.com/r/lwthiker/curl-impersonate)
这个号称可以完全模拟器浏览器的请求,按照说明本地部署了下环境,需要安装docker:
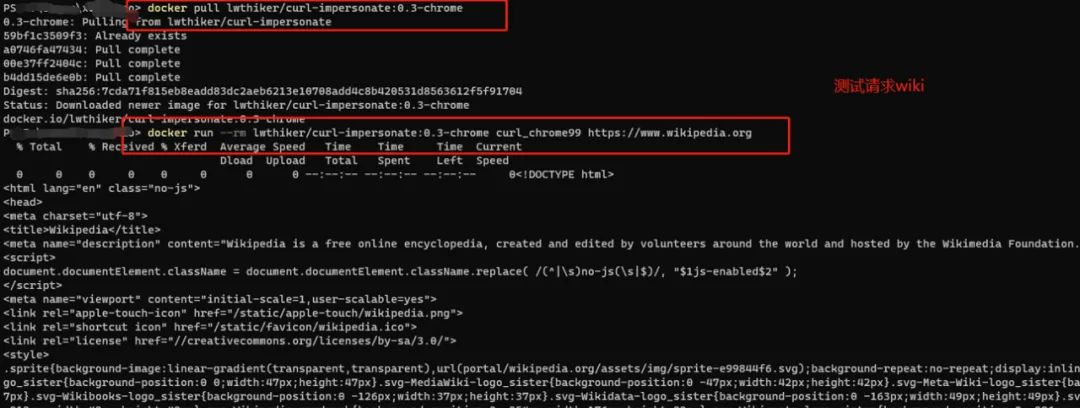
测试了下访问 https://ja3er.com/json

看起来确实跟浏览器的一致了,这里有个容器操作的小坑:从docker拷贝文件出来要注意容器名称,不是ID,之前搞错了一直错误:Error: No such container:path: curl-impersonate-chrome:/build/out/libcurl-impersonate.so.4.7.0

它这整个环境是容器,想直接用还不好用,开始看见有提供so,考虑直接写app调用so来发起http请求,最后折腾了下,发现开发效率是个问题,用的是win系统,还是想搞个win版本的,这就涉及到需要自己编译curl了,直接把上面的curl,还有boringssl,brotli,nghttp2源码都拖下来,改了个win版本,编译后生成了exe。
curl-impersonate的组件信息:

自己编译的curl:

重新加上libz,编译后

用编译的culr请求https://ja3er.com/json测试,发现ja3跟浏览器访问一样了。
这个时候已经有源码了,可以用C开发,实际写协议请求逻辑仍然觉得麻烦,还是要考虑走脚本方式。
首先还是考虑node能够直接调用,准备自己写模块封装插件,发现有很多绑定工作要做,搜了下,找到下面这个:JCMais/node-libcurl: libcurl bindings for Node.js (github.com)(https://github.com/JCMais/node-libcurl)
这个已经做好了curl绑定,node可以直接用的,那现在的思路就是替换这个模块里面的curl为自己编译的了。
直接新建一个node插件工程,导入node-libcurl的绑定相关代码,动态引入自己编译的curl dll:
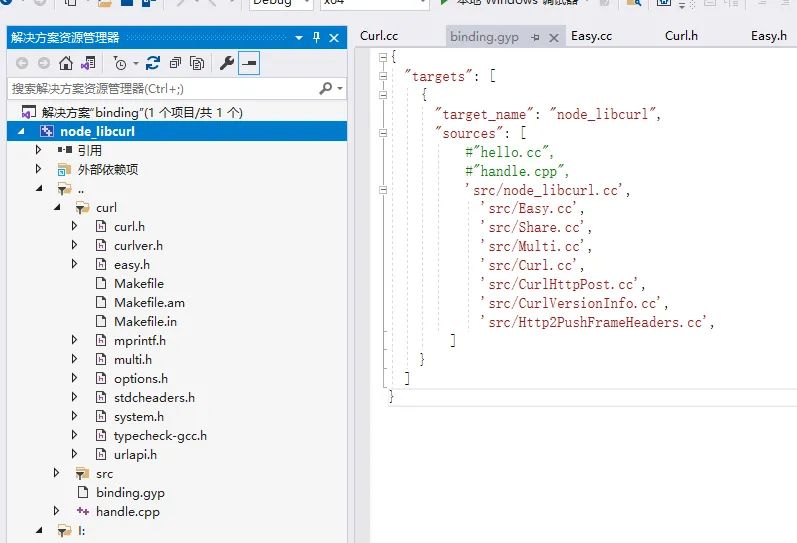
最后编译替换原有的node_libcurl.node,然后node请求测试:
const curl = new Curl(); curl.setOpt('URL', "https://ja3er.com/json"); curl.setOpt('CERTINFO', true) curl.setOpt('FOLLOWLOCATION', true) curl.setOpt('SSL_VERIFYPEER', false) curl.setOpt('SSL_VERIFYHOST', false) curl.enable(CurlFeature.NoDataParsing); curl.setOpt(Curl.option.COOKIEFILE, cookieJarFile) curl.setOpt(Curl.option.COOKIEJAR, cookieJarFile) curl.on('end', function (statusCode, data, headers) { console.info(headers); this.close(); }); curl.on('error', curl.close.bind(curl)); curl.perform();
返回的信息跟浏览器一致的,到这里指纹问题就基本解决了,并且也能够自动维护cookie了。
3、js逆向,处理sensor_data数据请求
在部署了Akamai的网站上,页面返回时候会带上类似下面这种脚本:
<script type="text/javascript" src="/RiyQJ/Gbek/k6cy/do/h9Bat/iw3rGrXz/ejRAYyE8BQU/eCteLm16/SD0">
这个路径,第一次是get,拿到这个js,后续会post数据到这个地址。这个post的触发时机及次数不同版本有点不同,IHG和TI是初始加载的时候都会发送post sensor_data,TI的次数更多(我测试3,4次都遇到过),然后就是点击的时候会触发,TI是每次点击都会触发post,IHG不会,IGH是拿到验证过的_abck后,就不会再触发请求了,这个js里面有判断逻辑,第一个-1如果换成0了:DAA11479B85BD170A757258B40E228AD~0~
就表示验证过了,后面就不需要再post了,当然要是切换页面,还是要再走上面逻辑。
刚开始分析这个js的时候,找了些资料:通过ast初步还原某js - 『脱壳破解区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn(https://www.52pojie.cn/thread-1471146-1-1.html)
JS逆向:AST还原极验混淆JS实战_一生向风的博客-CSDN博客_ast逆向(https://blog.csdn.net/weixin_47202458/article/details/106597220)
对于这个调试,一个就是通过代理替换,定向到本地文件或自己的本地服务器,还一个就是可以自己保存网页,架设一个自己的服务器,这样可以随时改代码来调试了。
本地调试的时候的,这个js路径要保持一致,有代码会检测这个路径格式:
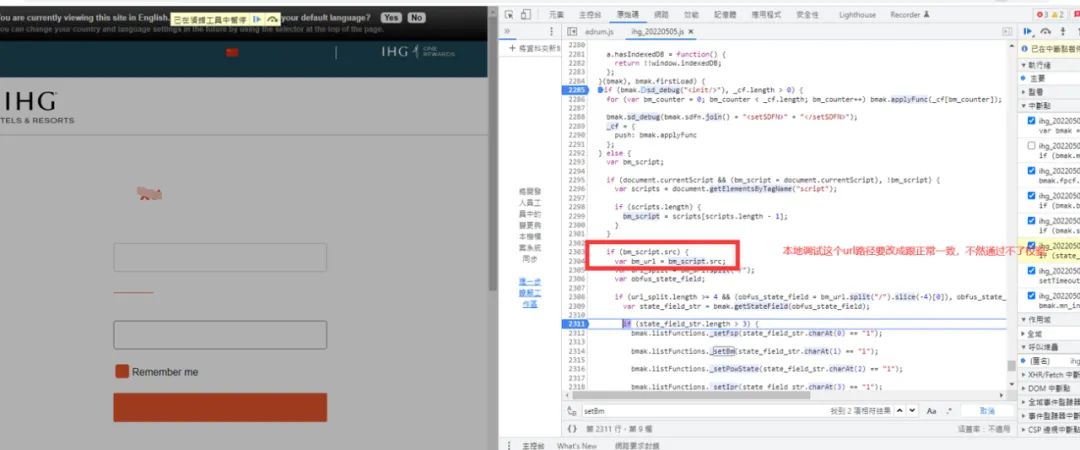
TI的这个js逻辑要比IHG的复杂:
1、post的sensor_data数据的,IT有加密,IHG没有。
2、IHG只用到了cookie中的_abck,TI多了个bm_sz。
我没看过Akamai的低版本,从网上看有提到1.75版本,然后开IGH提交的sensor_data数据头部:key_ver: '7a74G7m23Vrp0o5c9231281.75'
那这么看后面的数字就是版本号了,但是TI的是不同的,解密后,头部是这样的:7a74G7m23Vrp0o5c924489Ac8AWA+tulfQVzVpsCpdMA==
前段时间版本升级了下的,头部变成这样:
7a74G7m23Vrp0o5c924493oWV4VVGxQUElcrjPIc9GQQ==
看起来前面一段是固定的,中间数字是时间相关的,后面一串是版本相关的,这个字符串是js里面的一个变量值。
看起来是个base64串,解了下也没看出个所以然,不管了,这个也不影响。
对于本地调试,修改过的代码要跳过校验,js里面有逻辑会检查函数是否修改过,下面这里是校验几个函数的hash,对修改过的函数,校验不过就会走错误分支:
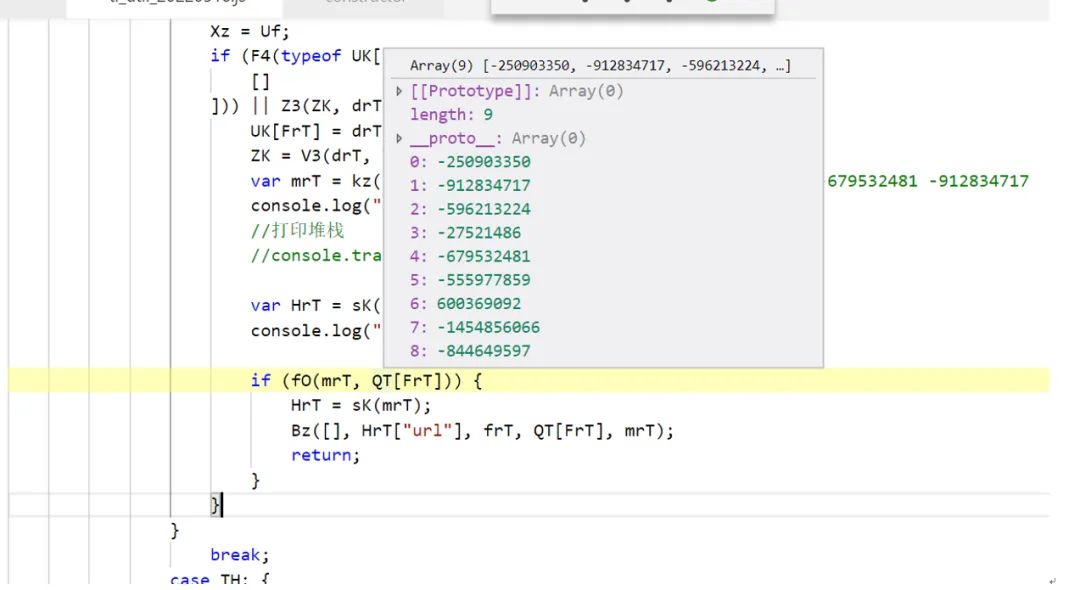
能调试后,单纯的逻辑逆向,相比二进制就简单些了,后面要做的就是用node来构造环境,生成需要发送的sensor_data数据,主要是一些浏览器相关的环境构造,包括webgl信息、语音组件信息等,当然这个也要花点时间,有些需要跟浏览器的数据比较,如果发送的数据不对,就会返回类似这种错误:
'ti_bm=Unknown%20Bot%20(8D4B186BE16BB4B3B59A0C24C27BAE69)%3aslow%3a%3aJavaScript%20Fingerprint%20Not%20Received%20(BETA)%3a%3a; path=/; domain=.ti.com',
这个搞完后测试,发现可以加入购物车了:
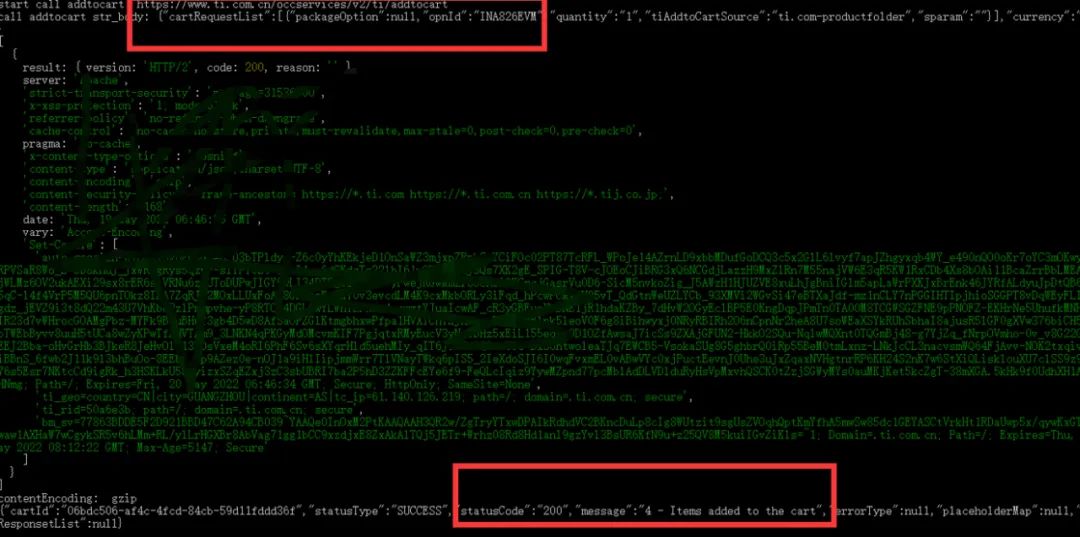
这个sensor_data post要模拟完全,不然可能出现协议成功率问题,持续添加可以后,那就是多账户问题了,这个可以通过差异化不同账号的请求环境来处理,比如模拟不同的浏览器参数。
除了这个js逻辑外,还有个上面提到的头部js,pixel前缀的,这个会用来提交本地的环境参数的,整个网站中,还有些反爬虫的处理,有的页面是直接返回的js:
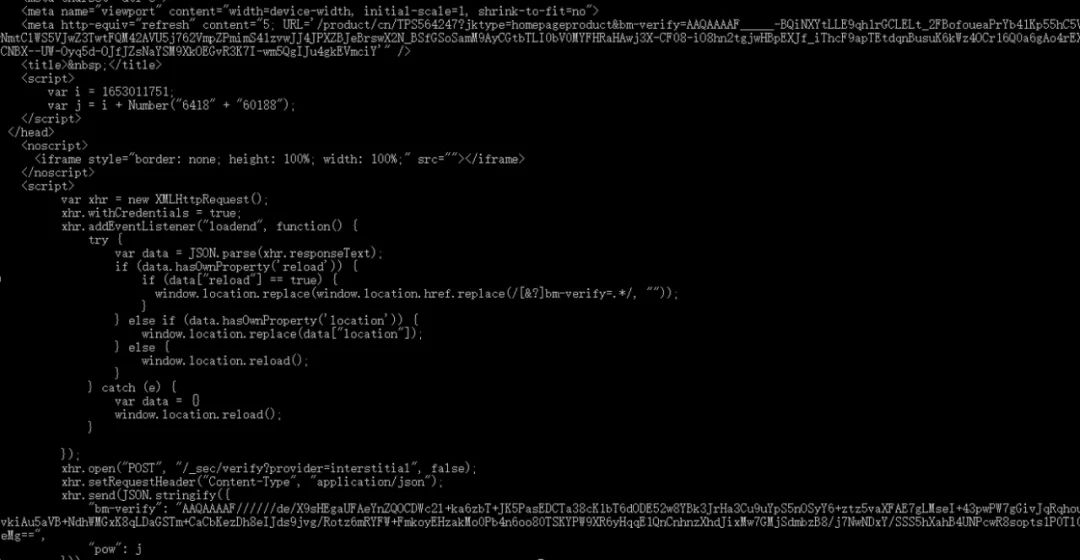
这种就要解析出脚本来执行了。
现在回过头来看,要是替换掉miniblink里面的curl模块,那就是一个带源码的浏览器调试环境了,有个完整的浏览器环境,对于验证还是比较方便的。
