多源数据技术体系下数据即席查询的探索与实践
近年来,随着大数据技术产品的不断发展和多样化,各个应用系统也会依据不同的业务场景选择多个不同的技术组件,数据也随之散落在各个存储平台之中。这种状况给后续数据分析师在不同数据源之上进行数据的即席关联查询和分析带来了新的难题,本文介绍了在数据不移动的前提下进行多源数据即席访问的具体探索与实践。
数据即席查询的现状及问题
中国光大银行传统数据仓库体系经过十几年的发展建设,在技术平台上也经历了多次迭代升级,现阶段形成了以GuassDB为主的分布式关系型数据库系统。近年来随着Hadoop生态体系大数据技术的成熟稳定,光大银行针对不同的业务场景使用多种新兴技术搭建了多套不同功能用途的技术平台。
从以前单一的传统数据仓库发展到多种数据仓库技术并行后,各类数据势必散落在各个不同的技术平台系统当中。数据分析师想要分析不同数据源的数据时,传统思路是先要将数据搬挪到某一个数据仓库平台中,然后再进行相关业务数据的查询与分析。数据搬挪时的ETL过程任务繁重、费时、费用昂贵,且不能够满足数据分析师对日常业务需求的即时查询服务。
为解决多数据源即席查询的问题,光大银行进行了相关技术产品的探索和实践,基于openLooKeng开源技术实现了行内跨源数据的即时查询和分析。
通过连接器的架构来适配
不同的数据源
光大银行针对即席查询的使用场景对市场中的开源产品进行了对比选择,最终选择了基于Presto计算引擎开源的技术产品openLooKeng。它是一个开源的分布式SQL查询引擎,类似于MPP数据库,用于支持数据探索、即席查询和批处理,而无需移动数据。引擎可以运行简单查询、复杂查询、聚合、连接和窗口函数,并支持跨源查询。在整体技术架构层面,它是由一个协调节点和多个工作节点组成的物理集群,对外提供的是SQL查询服务。
该查询引擎通过基于连接器的架构实现了存储与计算分离,每个连接器将数据源中的数据抽象成一个个的数据表。数据源只要能够表示为表、列和行,就可以创建连接器让查询引擎使用这些数据进行查询处理,目前支持的连接器不仅包括Hive、GaussDB、MySQL关系型数据库,还支持连接非关系型的存储数据源,例如分布式消息队列Kafka、列式存储数据库HBase、全文检索引擎Elasticsearch。对于同一个数据源中的不同数据库的访问,还可以通过配置不同的连接器实例来满足用户对于多实例的支持。
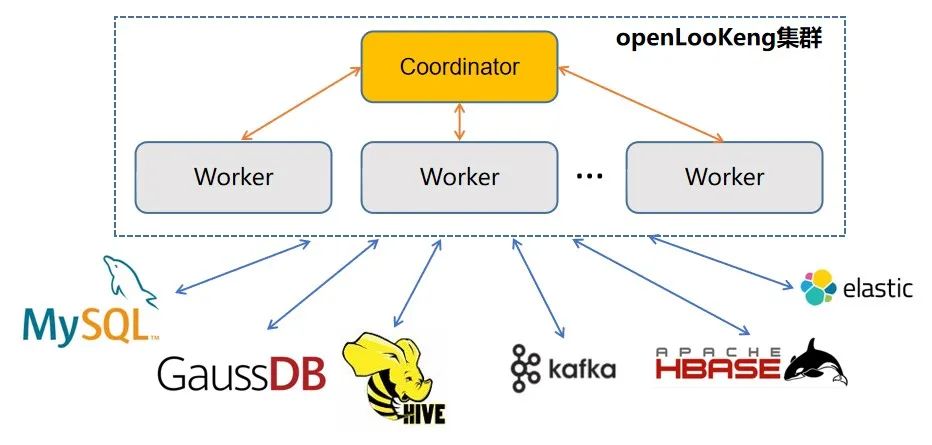
图1 openLooKeng集群整体架构
在服务器端程序启动时,以插件方式加载在Catalog目录下配置好的各个连接器实例。在生产环境中针对大数据平台各个物理集群下的Hive数据库分别配置连接器实例,对GaussDB数据库中的数据仓库和各种不同集市数据库创建不同的连接器实例。终端用户通过SQL客户端工具在进行数据查询时通过完全限定名(catalog-name.schema-name.table-name)来屏蔽数据源的差异性,对不同数据源的表关联、过滤、聚合等操作。例如,针对Hive数据库和GaussDB数据库的跨源关联查询可以使用如下语句进行:
select a.cust_id,a.cust_name,b.account_num
from gaussdb.test_db.customer a, hive.test_db.account b
where a.cust_id = b.cust_id
and a.cust_id = 12345;
针对不同Hive数据库租户
的实现机制
光大银行Hadoop物理集群是以平台的方式进行搭建,用于数据即席查询的有批量主集群和数据科学实验室集群,在每个集群之上启用了基于Kerberos管理的用户认证方式,针对使用平台的不同应用系统会创建独立的应用租户,每个租户有自己独立管理和使用的Hive数据库,在管理和查询的权限上和其他系统租户相互隔离。
在Hive连接器的catalog配置中,如果分别对Hive技术组件下不同租户的数据库进行配置,需要创建不同的catalog文件,并且每个租户需要提供底层Hadoop平台上的Kerberos的keytab秘钥文件,使用这种配置方式在管理上较为繁杂,并且容易出错。另外一种较为方便也是光大银行所使用的配置方式是针对每个Hive数据库集群只配置一个Hive连接器实例,对底层Hadoop平台配置的用户使用的是超级用户和对应的keytab文件,然后超级用户使用代理模拟的方式来对Hive数据库的元数据和HDFS的数据文件进行相关读取和查询操作。
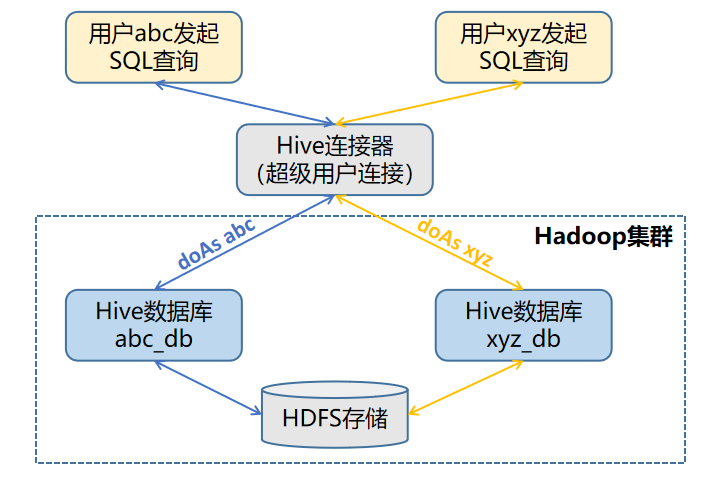
图2 Hive连接器的访问机制
在具体的Hive连接器配置方面,需要配置以下相关参数:
connector.name=hive-hadoop2
hive.metastore.uri=thrift://hive-metastore:9083
hive.metastore.authentication.type=KERBEROS
hive.metastore.thrift.impersonation.enabled=true
hive.metastore.service.principal=hive/_HOST@CEBBANK.COM
hive.metastore.client.principal=hive@CEBBANK.COM
hive.metastore.client.keytab=hive.keytab
hive.metastore.krb5.conf.path=krb5.conf
hive.hdfs.authentication.type=KERBEROS
hive.hdfs.impersonation.enabled=true
hive.hdfs.presto.principal=hive@CEBBANK.COM
hive.hdfs.presto.keytab=hive.keytab
hive.config.resources=core-site.xml,hdfs-site.xml
当底层Hadoop集群使用Kerberos进行身份认证时,在openLooKeng中Hive连接器的Thrift服务和HDFS身份验证服务,都需要配置为使用Kerberos方式进行验证,此外还需要提供对应的Principal用户名和Keytab秘钥文件。对于这两个配置,光大银行使用了Hadoop平台中的超级用户和其对应的Keytab文件。在通过启用元数据和HDFS的Impersonation后,即开始了代理模拟的功能,用户对Hive数据库发起查询执行SQL语句时的用户名会作为该超级用户所要代理模拟的用户,具体对于数据库中表的访问是否具有权限也完全依赖于这个用户名对应的用户在底层Hadoop集群中是否有读写权限,在系统安全上并不会因为Catalog中配置了超级用户而导致用户查询时的越权访问。
对GaussDB数据库的
JDBC访问机制
在传统数据仓库方面,光大银行使用的是GaussDB数据库,它是基于MPP架构,为超大规模的数据管理提供通用的计算平台。在整个物理集群方面,是由管理节点、控制节点和数据节点组成。终端用户在发起SQL查询时,请求会统一发送到Coordinator节点,接收到用户的请求后会分配服务进程,请求全局事务,根据数据的分布信息及系统元数据将具体任务发送到Datanode进行处理,处理完成后的结果也会统一返回到Coordinator节点,再将结果返回给终端查询用户。
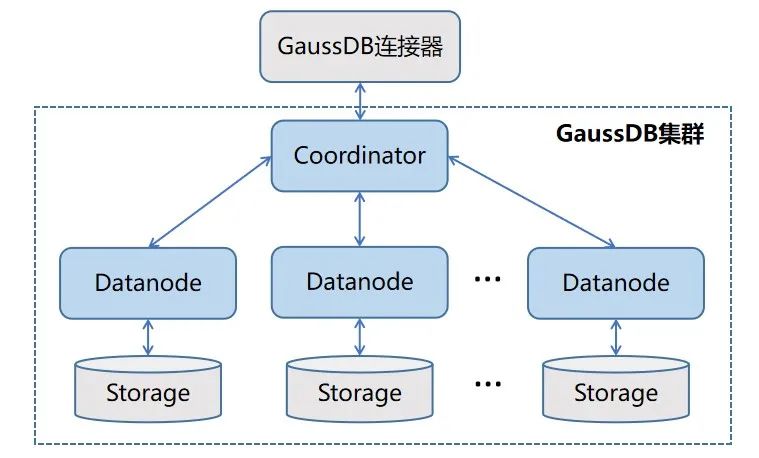
图3 GaussDB连接器访问机制
在openLooKeng连接GaussDB时,使用的是传统关系型数据库的JDBC方式进行连接,具体的Catalog实例参数配置信息如下:
connector.name=opengauss
connection-url=jdbc:postgresql://192.168.1.101:38910/hetu
connection-user=hetu
connection-password=test
在进行底层数据读取操作时,终端查询用户所拥有的权限是依赖于该Catalog配置中的连接用户在GaussDB数据库中的实际权限决定的。受限于JDBC方式访问GaussDB数据库的查询处理机制,查询所要获取的数据必须全部经过Coordinator节点进行传输,在获取数据量比较大的情况下,Coordinator节点可能会成为整个并发查询时的性能瓶颈。
未来的技术优化与展望
通过使用openLooKeng对底层不同数据存储源的集成,基本上解决了数据分析师进行跨源数据关联查询分析的功能性问题。但是对于GaussDB这样的分布式关系型数据库还是存在单点的性能瓶颈,后续将深入探索JDBC多分片管理以及GaussDB的GDS多分片导出技术来进行并行查询上的优化。
同时在终端的查询用户和使用JDBC方式连接器的底层用户之间的权限映射管理上,权限的配置方式还比较简单,后续将和开源社区一起探索更加细粒度的权限控制,能够在终端用户、Catalog连接器、SQL命令、表的各个粒度上都分别能进行各种级别(all,read-only,none)的权限管理和控制。
